 夜雨聆风
夜雨聆风





【MATLAB源码-第428期】基于MATLAB的四用户NOMA功率分配对比FPA、FTPA、GRPA、PSO和DQN.
MATLAB 2024a
1、算法描述
摘要
功率域非正交多址接入技术通过在同一时频资源内叠加多个用户信号,可以提升无线通信系统的频谱利用率和多用户接入能力。针对四用户下行NOMA系统中功率分配策略对系统吞吐量、用户公平性和传输可靠性的影响,本文建立了包含路径损耗、Rayleigh衰落、加性高斯白噪声、QPSK调制和串行干扰消除接收的系统仿真模型。系统采用强弱用户配对方式,将四个用户划分为两个NOMA用户簇,并分别对OMA、FPA、FTPA、GRPA、PSO-PA和DQN-PA六种接入与功率分配方案进行对比分析。NOMA能够在同一资源块中服务多个用户,相关综述也指出该机制与传统正交多址相比,在频谱效率、连接能力和用户公平性方面具有研究价值。 本文进一步将粒子群优化和深度强化学习引入功率分配过程,使功率系数能够根据用户信道状态和系统信噪比进行自适应调整。仿真结果表明,固定功率分配方法结构简单,但对动态信道适应能力有限;基于信道增益的启发式算法能够改善远近用户功率配置,但整体性能仍受参数选择影响;PSO-PA和DQN-PA能够在系统和速率、误码率和用户公平性之间取得更均衡的性能表现。其中,DQN-PA在训练完成后能够快速给出功率分配动作,适合用于动态无线环境下的小规模NOMA资源分配研究。
关键词: 功率域NOMA;四用户下行系统;功率分配;串行干扰消除;粒子群优化;深度Q网络;误码率;用户公平性
一、引言
随着移动通信系统持续向高频谱效率、大连接规模和低时延业务方向发展,传统正交多址接入方式逐渐暴露出资源利用率受限的问题。正交多址接入通常通过时间、频率或码字区分不同用户,该机制可以降低用户间干扰,也便于接收机实现。但在用户数量增加、边缘用户服务质量要求提高以及频谱资源紧张的情况下,单纯依靠正交资源划分难以继续提升系统容量。
非正交多址接入技术为多用户传输提供了另一种思路。功率域NOMA允许多个用户在同一时频资源内同时传输,通过不同功率等级区分用户信号,并在接收端借助串行干扰消除技术恢复各用户信息。该机制的核心思想不是简单地给某个用户分配更多资源,而是利用用户信道条件差异实现功率域复用。通常情况下,远用户或弱信道用户分配较高功率,近用户或强信道用户分配较低功率。强信道用户先检测并抵消弱用户信号,然后再恢复自身信息。Vaezi等学者对NOMA中常见误解进行了讨论,并指出NOMA性能与功率分配、用户配对、接收复杂度和实际系统约束密切相关。
功率分配是功率域NOMA系统中的关键问题。若远用户功率分配不足,远用户可能无法满足基本解调需求;若远用户功率分配过高,近用户自身信号功率被压缩,同时SIC后的残余干扰也可能增加。由此可见,NOMA系统不能只追求系统总速率,还需要兼顾弱用户服务质量、近用户解调可靠性和用户间公平性。固定功率分配方法实现简单,但难以适应随机衰落信道;FTPA和GRPA等启发式方法能够根据信道增益调整功率比例,但其性能受经验参数影响较大;智能优化算法和深度强化学习方法能够从系统目标出发学习或搜索功率分配策略,因而适合用于复杂无线资源分配问题。已有研究也表明,深度强化学习可以用于NOMA功率分配和信道分配等资源优化问题。
本文围绕四用户下行功率域NOMA系统开展仿真研究。系统设置两个NOMA用户簇,每个簇包含一个近用户和一个远用户。本文对OMA、FPA、FTPA、GRPA、PSO-PA和DQN-PA六种方案进行统一建模和对比,重点分析不同方法在功率系数分配、系统和速率、误码率、用户公平性、星座图表现以及优化收敛特性方面的差异。研究目的不是单纯展示某一种算法的性能优势,而是从通信系统建模角度说明功率分配策略对NOMA系统性能的影响,并为后续多用户、多载波和多天线NOMA资源优化提供参考。
二、四用户下行NOMA系统模型
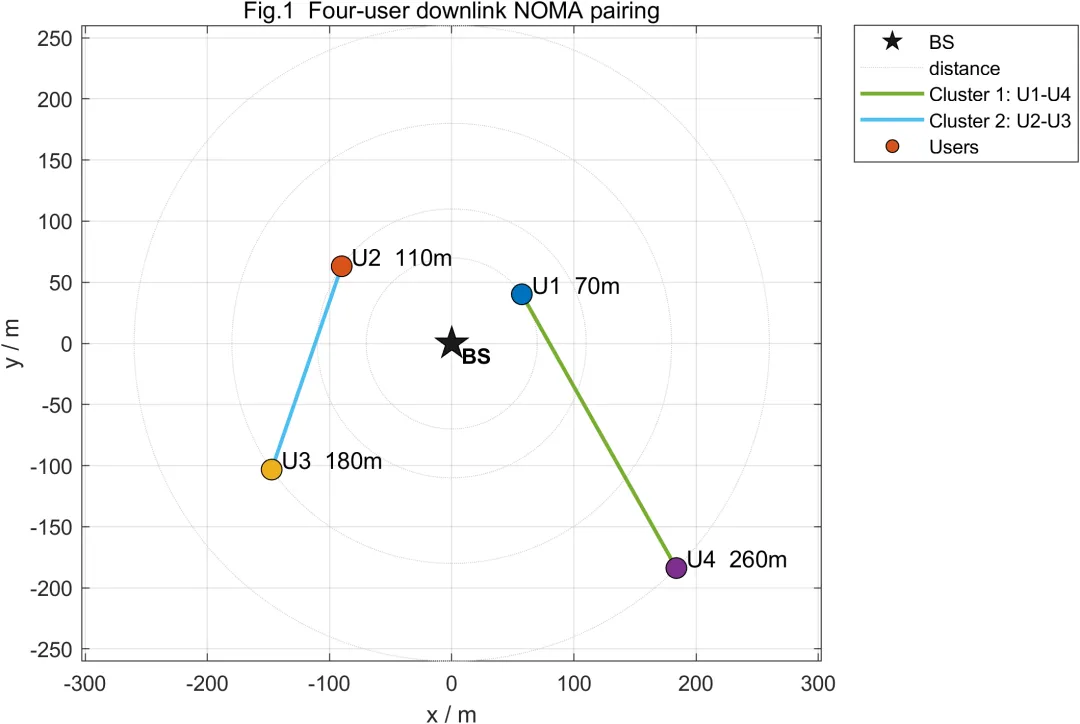
本文考虑单小区下行传输场景。基站同时服务四个用户,四个用户与基站之间的距离不同,因此具有不同的平均信道条件。系统按照强弱用户配对原则,将四个用户划分为两个NOMA簇。近用户通常具有较低路径损耗和较高信道增益,远用户通常具有较高路径损耗和较低信道增益。强弱用户配对能够扩大簇内用户信道差异,从而提高功率域复用和SIC检测的有效性。
在信道建模方面,系统同时考虑大尺度路径损耗和小尺度Rayleigh衰落。路径损耗用于描述信号随传播距离增加而产生的平均衰减,Rayleigh衰落用于描述多径传播环境下信道幅度的随机变化。接收端噪声采用加性高斯白噪声模型。该类模型虽然不能覆盖所有真实无线环境,但能够较清晰地反映NOMA系统中功率分配、信道差异和接收干扰之间的基本关系。
在每个NOMA簇内,基站将近用户和远用户的调制符号按照不同功率系数进行叠加发送。远用户由于信道条件较弱,通常获得较高功率。近用户由于信道条件较强,通常获得较低功率。远用户接收信号后直接解调自身信息,并将近用户信号视为干扰。近用户接收信号后先检测远用户信息,再通过串行干扰消除去除远用户信号成分,最后解调自身信息。
理想SIC假设接收端能够完全抵消已检测用户的干扰,但实际系统中会受到信道估计误差、判决错误、噪声扰动和硬件非理想因素影响。因此,本文在建模时考虑残余干扰,使近用户解调结果更接近实际通信系统。该处理可以避免仿真结果过于理想,也能更真实地体现功率分配对误码性能的影响。
系统采用QPSK调制。QPSK具有结构简单、抗噪声能力较强、频谱效率适中的特点,适合作为NOMA功率分配仿真的基础调制方式。误码率通过符号级蒙特卡洛统计得到,而不是由速率公式直接换算。该处理能够同时体现噪声、信道衰落、功率叠加和SIC残余干扰对实际判决结果的影响。
三、功率分配方法设计
OMA方案作为传统正交多址基准。该方案将资源正交划分给不同用户,因此用户之间不存在同一资源块内的非正交干扰。OMA接收机结构简单,干扰处理压力较小,但每个用户只能占用部分资源。在相同带宽和发射功率约束下,OMA系统容量通常受资源划分比例限制。因此,本文将OMA作为参考对象,用于说明NOMA在资源复用方面的潜在增益。
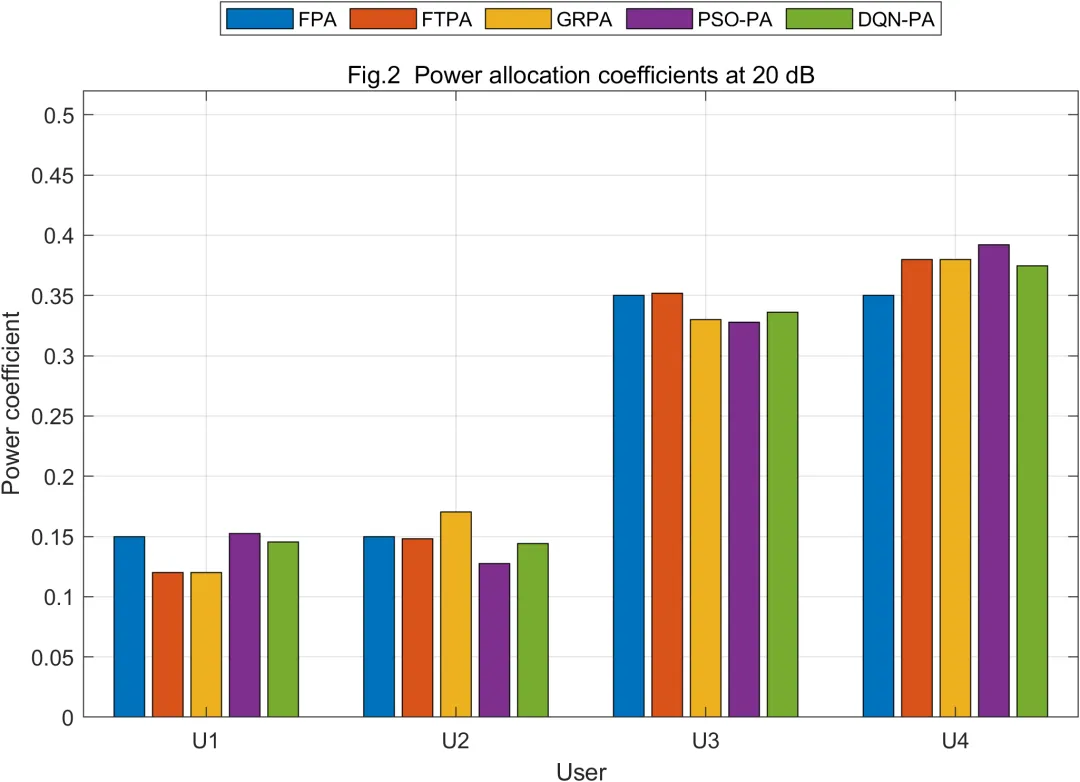
FPA方案采用固定功率分配系数。该方法不依赖瞬时信道状态,直接按照预先设定的比例为近用户和远用户分配功率。FPA的优点是实现简单、计算量小、工程部署方便。其不足也较明显。当无线信道发生随机波动时,固定功率系数无法及时适应用户间信道条件变化,可能导致远用户功率不足,也可能导致近用户速率受限。FPA适合作为低复杂度基线方法,但不适合作为动态信道下的最优功率控制策略。
FTPA方案根据用户信道增益进行分数阶功率分配。该方法的基本思想是根据信道强弱动态调整功率比例,使弱信道用户获得更多功率,使强信道用户获得较少功率。与FPA相比,FTPA能够体现瞬时信道差异,因此具有一定自适应能力。但FTPA依赖分数阶参数,参数选择会直接影响近远用户之间的功率倾斜程度。若参数设置偏保守,系统吞吐量提升有限;若参数设置过激,则可能影响强用户自身速率和SIC稳定性。
GRPA方案根据信道增益比例进行功率配置。该方法更关注簇内强弱用户之间的相对信道差异。当强弱用户信道差距较大时,NOMA能够更充分地发挥功率域复用优势;当强弱用户信道差距较小时,SIC解调难度增加,系统收益可能下降。GRPA相比FPA更灵活,相比FTPA更强调簇内用户信道比例关系,但本质上仍属于启发式方法,不能保证在多目标约束下达到全局最优。
PSO-PA方案将功率分配问题转化为群智能搜索问题。粒子群优化中的每个粒子代表一组候选功率分配参数。算法通过个体最优位置和群体最优位置引导粒子更新,使适应度逐步提升。本文中的适应度不只关注系统和速率,还考虑用户公平性、弱用户服务质量和可靠性因素。因此,PSO-PA能够在多个目标之间寻找折中方案,而不是简单地将功率集中分配给强信道用户。PSO-PA的主要优势是搜索能力较强,不需要训练数据;主要不足是每次信道状态变化后都需要重新迭代,在线计算复杂度相对较高。
DQN-PA方案将功率分配建模为深度强化学习问题。系统状态由用户信道状态和当前信噪比信息构成,动作由离散功率分配组合构成,奖励函数综合考虑系统和速率、公平性、可靠性和服务质量约束。DQN通过神经网络近似不同状态下各功率分配动作的价值,并在训练过程中逐步学习较优动作选择策略。深度强化学习已经被用于NOMA资源分配研究,相关工作将其用于联合功率分配、信道分配或用户配对问题,说明该方向具有明确的研究基础。
与PSO-PA相比,DQN-PA需要训练过程,但训练完成后在线决策速度较快。该特性适合信道状态频繁变化的场景。对于四用户小规模NOMA系统,离散动作空间能够降低训练复杂度,也能避免网络输出不满足功率约束的无效结果。但离散动作也会限制功率分配精度,后续可以进一步扩展到连续动作强化学习方法,以获得更灵活的功率控制能力。
四、仿真参数与评价指标
本文仿真系统采用四用户下行功率域NOMA结构。四个用户按照信道条件划分为两个NOMA簇,每个簇包含一个近用户和一个远用户。基站端采用功率域叠加编码,接收端采用SIC检测。信道模型包含路径损耗、Rayleigh衰落和加性高斯白噪声。调制方式采用QPSK。不同算法在相同信道环境、相同信噪比范围和相同功率约束下进行比较,以保证仿真对比具有一致性。
系统和速率用于评价整体吞吐量。该指标能够反映系统在单位资源内承载多用户数据的能力。NOMA方案由于允许多个用户共享同一资源块,理论上具有高于OMA的频谱复用潜力。但系统和速率不能单独作为唯一评价标准,因为过度追求总吞吐量可能造成远用户速率过低,进而削弱系统公平性。
用户公平性用于评价不同用户之间的服务均衡程度。NOMA系统中近用户通常具有更好的信道条件,因此容易获得更高速率。远用户虽然分配较高功率,但仍会受到路径损耗和干扰影响。合理的功率分配算法应在提升系统吞吐量的同时,保证远用户具备基本可用速率。公平性指标能够避免算法只服务强信道用户。
误码率用于评价实际链路可靠性。本文采用符号级仿真统计误码率,因此该指标能够体现调制、噪声、衰落、干扰叠加和SIC残余误差的综合影响。与速率指标相比,误码率更接近实际接收判决结果。对于NOMA系统而言,功率分配既会影响远用户解调,也会影响近用户SIC处理。因此,误码率是判断功率分配策略是否可靠的重要依据。
星座图用于观察接收符号分布特性。理想情况下,QPSK星座点应围绕四个标准判决区域聚集。若噪声较大、功率配置不合理或SIC残余干扰明显,星座点会出现扩散、偏移或重叠。通过星座图可以直观看出不同功率分配方案对接收端判决质量的影响。
PSO收敛曲线和DQN训练奖励曲线用于分析智能优化过程。PSO收敛曲线能够反映粒子群搜索是否逐步接近较优解。DQN奖励曲线能够反映网络在训练过程中是否逐渐学习到有效策略。两类曲线不是最终通信性能指标,但能够说明算法自身优化过程是否稳定。
五、仿真结果分析
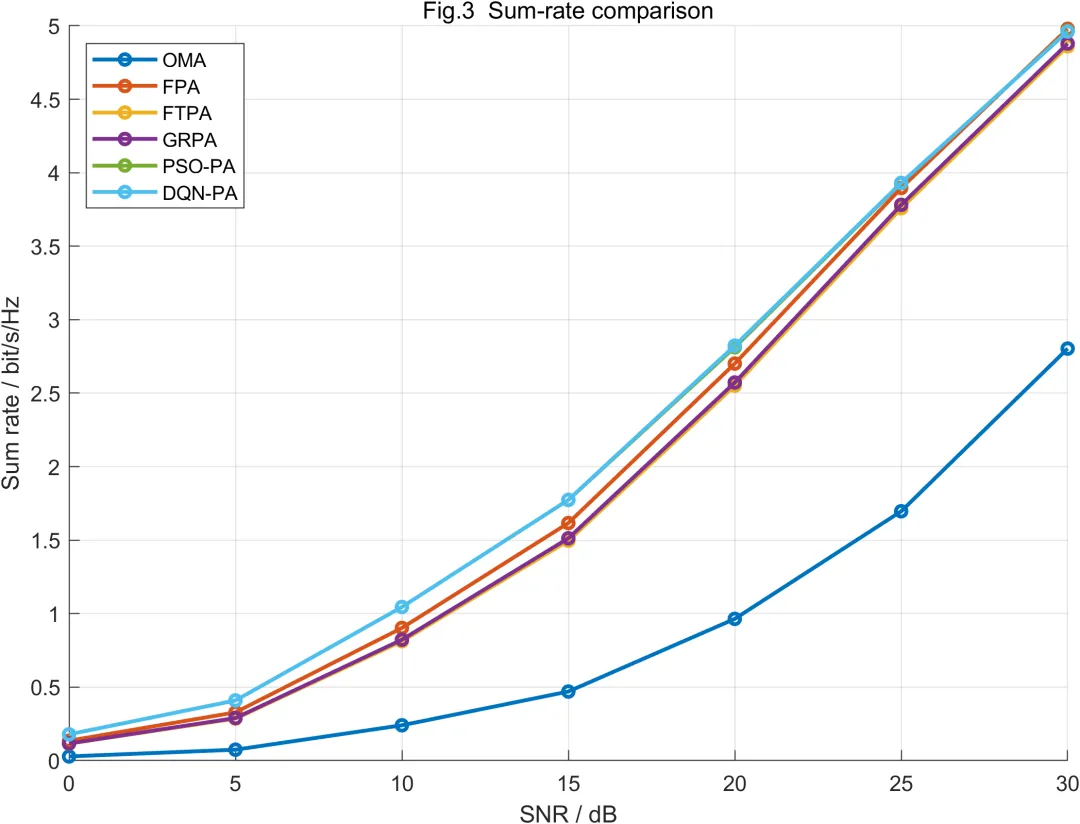
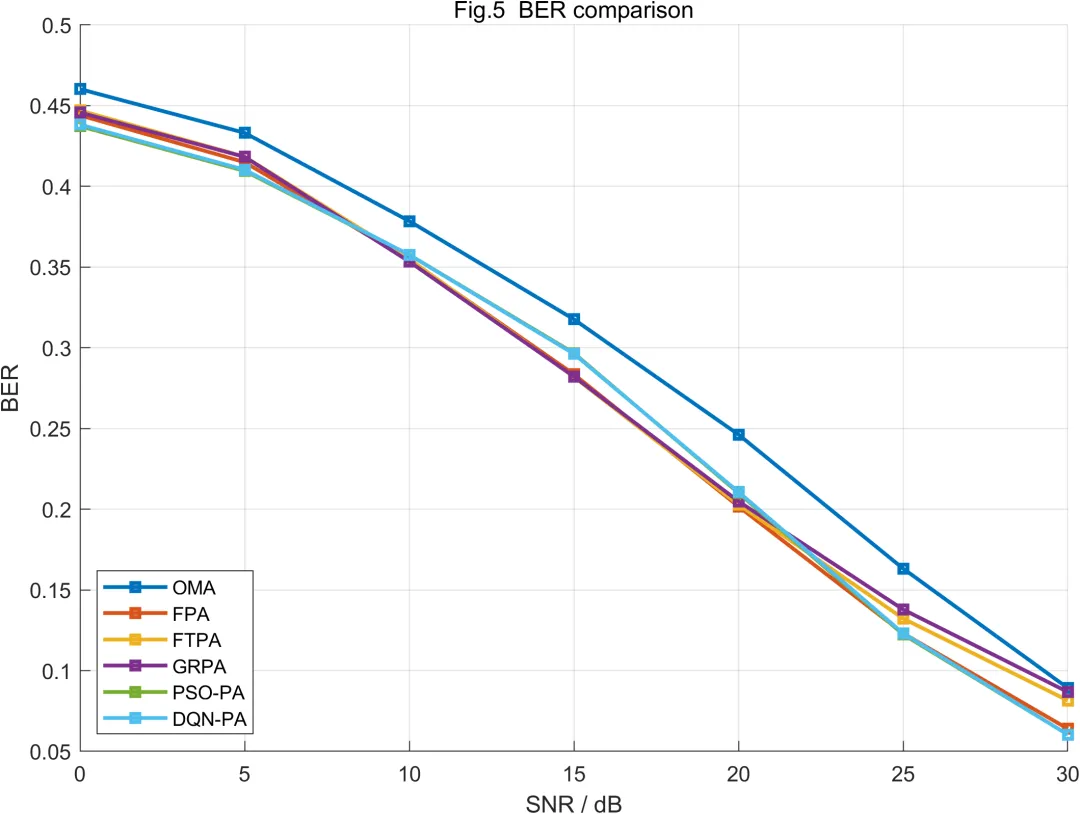
从系统和速率结果来看,OMA方案由于采用正交资源划分,每个用户只能使用部分资源,因此整体吞吐量受到明显限制。NOMA方案通过同一资源块承载多个用户,在功率分配合理且SIC有效的情况下,能够获得更高系统和速率。这一结果符合功率域NOMA的基本特征,也说明四用户两簇配对结构能够体现非正交复用带来的容量增益。
FPA方案在不同信噪比下表现较平稳。由于其功率系数固定,算法不会因为瞬时信道波动而产生剧烈变化。但这也意味着FPA无法充分利用信道较好时的传输机会,也无法在弱用户信道恶化时主动增加保护。FTPA和GRPA相比FPA具有更明显的信道自适应能力。它们能够根据信道增益或信道比例调整功率分配,使远用户获得更合理的功率保护。因此,在部分信噪比区间内,FTPA和GRPA可以获得优于FPA的性能表现。
PSO-PA在系统和速率方面通常具有更好的优化效果。原因在于PSO不是直接套用固定规则,而是在给定约束范围内搜索适应度较高的功率配置。该搜索过程能够同时考虑近用户速率、远用户速率、服务质量约束和系统整体性能。因此,PSO-PA更容易获得均衡结果。但PSO的计算代价也更高,尤其是在信道状态快速变化时,若每个时隙都重新搜索,实时实现压力会明显增加。
DQN-PA的优势体现在训练后的快速决策能力。DQN在训练阶段通过大量状态样本学习信道状态与功率动作之间的映射关系。测试阶段只需输入当前状态,就能够输出较优功率分配动作。He等学者的研究也将深度强化学习用于NOMA联合功率分配和信道分配问题,说明该类方法适合处理NOMA中的动态资源优化任务。 对于本文四用户系统而言,DQN-PA能够在较低在线复杂度下获得接近优化搜索的性能,因此具有较好的工程研究价值。
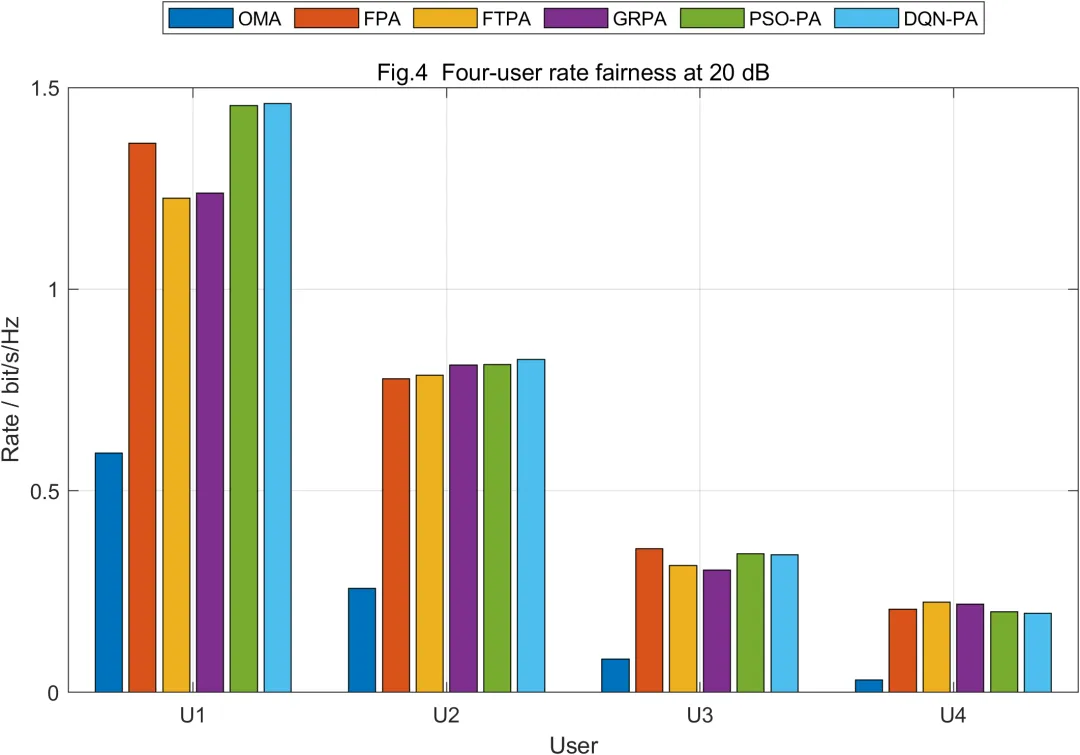
从用户速率结果来看,近用户通常具有更高数据速率,远用户速率相对较低。这一现象来自信道条件差异和接收机制差异。近用户信道较强,并且可以通过SIC抵消部分干扰;远用户信道较弱,只能将近用户信号视为干扰,因此速率提升受到限制。合理的功率分配不应只让近用户获得高吞吐量,还应保证远用户满足基本服务质量。PSO-PA和DQN-PA在奖励函数或适应度函数中加入公平性和QoS因素,因此能够减少强用户过度占优的问题。
从误码率结果来看,随着信噪比提高,各方案误码率整体下降。该趋势符合数字通信系统的基本规律。NOMA方案的误码率不仅受噪声影响,还受功率分配和SIC残余干扰影响。若远用户功率过低,远用户符号判决边界会变得不清晰,误码率上升;若远用户功率过高,近用户在SIC之后仍可能受到残余干扰影响。由此可见,NOMA误码性能并不只由总发射功率决定,还与功率比例、用户信道差异和接收端干扰消除能力密切相关。
DQN-PA和PSO-PA在误码率方面表现较好,主要原因是这两类方法能够根据系统状态自适应调整功率分配。PSO通过迭代搜索寻找较优功率比例,DQN通过训练学习不同状态下的动作选择规则。两者相比,PSO更适合作为离线搜索参考,DQN更适合在线快速决策。若系统对实时性要求不高,PSO可以获得较稳定的优化结果;若系统需要快速响应信道变化,DQN具有更明显优势。
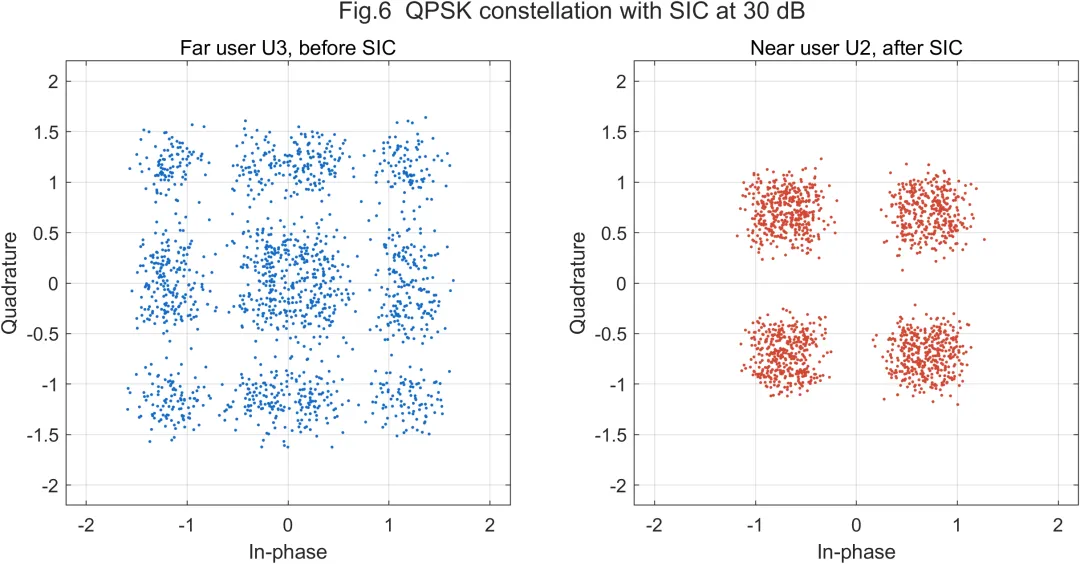
从星座图观察,远用户星座点通常比近用户更分散。这是因为远用户受路径损耗、噪声和叠加干扰影响更明显。近用户经过SIC处理后,星座点聚集程度有所改善,但仍可能受到非理想SIC残余干扰影响。该现象说明本文模型没有把SIC设置成完全理想状态,而是保留了实际接收机中可能存在的误差影响。这样的仿真处理更有利于评价不同功率分配方法在可靠性方面的差异。
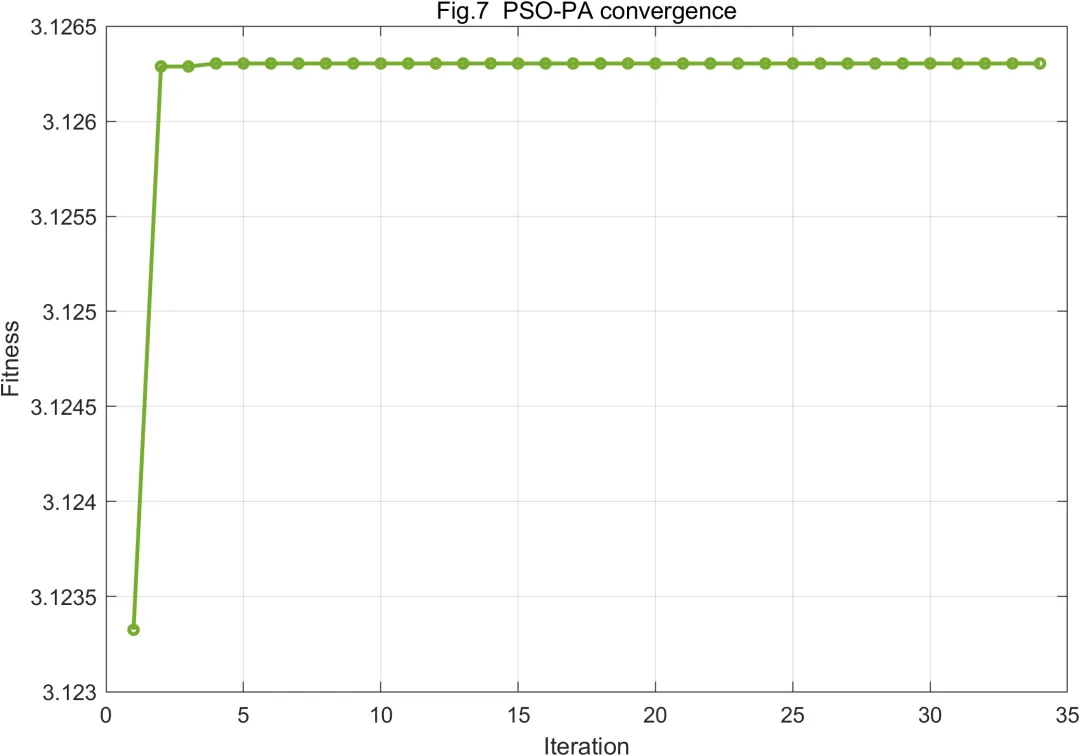
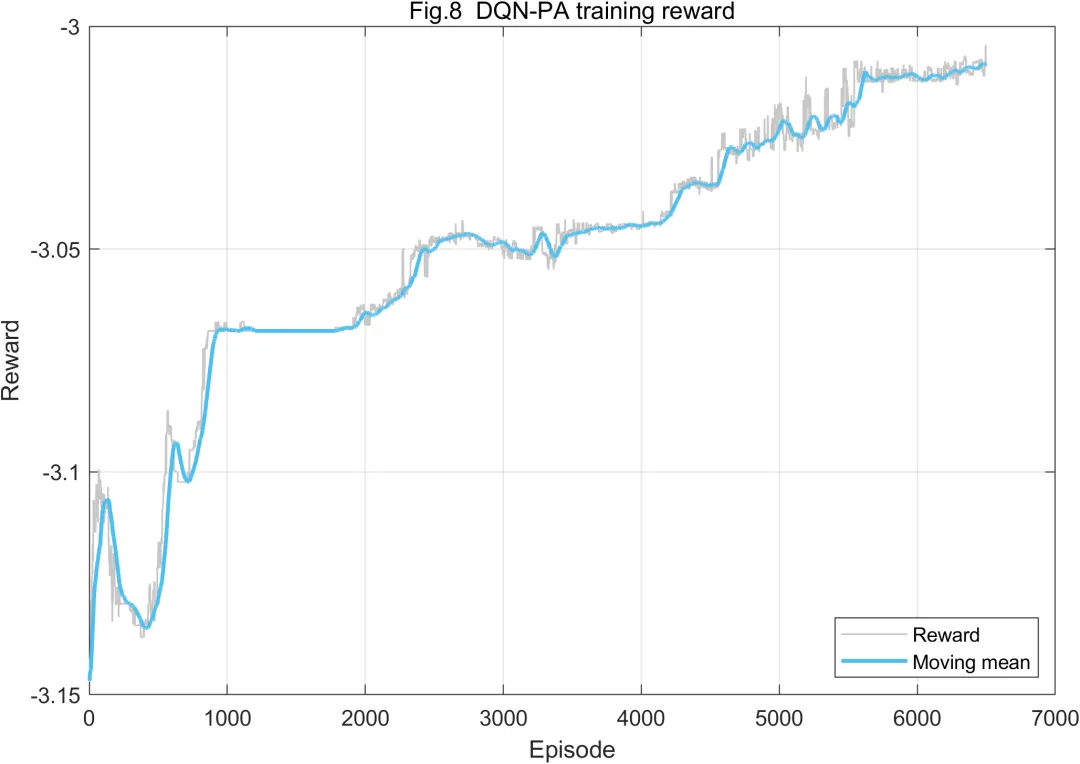
从收敛过程看,PSO适应度随迭代次数增加逐步改善,并最终趋于稳定,说明粒子群能够在有限搜索空间内找到较优功率配置。DQN训练奖励整体呈上升趋势时,说明网络正在逐渐形成有效的动作选择能力。若训练奖励存在波动,也属于强化学习训练中的常见现象,因为探索策略、随机信道样本和奖励函数权重都会影响训练轨迹。对于DQN-PA而言,奖励函数设计非常关键。若奖励过度偏向系统和速率,算法可能牺牲远用户;若奖励过度偏向公平性,系统吞吐量可能下降。因此,多目标权衡是DQN功率分配设计中的核心环节。
六、工程意义与方法比较
从工程应用角度看,FPA最容易实现,适合计算资源有限、用户分布较稳定的场景。但FPA无法充分适应信道变化,因此在移动环境或衰落较强的场景中性能受限。FTPA和GRPA在复杂度和性能之间取得一定折中,适合作为传统自适应功率分配方案。它们不需要训练,也不需要复杂迭代,便于工程部署,但性能上限受经验规则限制。
PSO-PA更适合用于离线优化、系统性能评估或小规模实时优化。其优点是目标函数设计灵活,可以把系统和速率、公平性、误码率和QoS约束同时纳入优化框架。其缺点是迭代开销较大,且搜索结果依赖粒子数量、迭代次数和参数设置。
DQN-PA更适合用于具有重复决策特征的动态资源分配问题。DQN在训练阶段需要消耗计算资源,但训练完成后具有较快推理速度。相关研究已经将强化学习用于NOMA用户配对和功率分配任务,说明该方法具有较明确的学术基础。 对本文四用户系统而言,DQN-PA能够体现智能优化算法在小规模NOMA功率控制中的应用价值,也为后续扩展到更多用户和多载波场景提供了基础。
综合来看,NOMA功率分配不是单一速率最大化问题,而是多目标约束优化问题。一个合理的功率分配方案需要同时考虑频谱效率、弱用户保护、接收端SIC可靠性和算法复杂度。本文所比较的六种方案覆盖了传统正交接入、固定功率分配、启发式信道自适应分配、群智能优化和深度强化学习优化,能够较全面地展示四用户下行NOMA系统中不同功率分配思想的性能差异。
七、结论
本文针对四用户下行功率域NOMA系统建立了完整的仿真分析模型,并围绕功率分配问题比较了OMA、FPA、FTPA、GRPA、PSO-PA和DQN-PA六种方案。系统模型包含路径损耗、Rayleigh衰落、AWGN噪声、QPSK调制和非理想SIC接收,能够较全面地反映下行NOMA链路中的主要影响因素。
仿真结果表明,NOMA方案在同一资源块内服务多个用户,因此在系统和速率方面整体优于OMA。固定功率分配方法实现简单,但无法充分适应随机信道变化。FTPA和GRPA能够根据信道条件调整功率比例,性能优于固定分配,但仍受经验参数限制。PSO-PA通过迭代搜索获得较优功率配置,适合作为离线优化参考。DQN-PA通过训练学习状态到动作的映射关系,在动态信道环境下具备较好的在线决策潜力。
本文结果说明,四用户下行NOMA系统中的功率分配应同时关注吞吐量、误码率、用户公平性和弱用户服务质量。智能优化方法能够改善传统固定分配和启发式分配的不足,但其性能仍依赖奖励函数设计、动作空间构造和训练样本覆盖范围。后续研究可以进一步考虑多载波NOMA、多天线NOMA、连续动作强化学习、信道估计误差、移动用户场景以及实际信道编码机制,从而提升模型的工程适用性和系统推广价值。
参考文献
Vaezi, Mojtaba, et al. “Non-Orthogonal Multiple Access: Common Myths and Critical Questions.” IEEE Wireless Communications, vol. 26, no. 5, 2019, pp. 174–180. DOI: 10.1109/MWC.2019.1800598.
He, Chaofan, et al. “Joint Power Allocation and Channel Assignment for NOMA With Deep Reinforcement Learning.” IEEE Journal on Selected Areas in Communications, vol. 37, no. 10, 2019, pp. 2200–2210. DOI: 10.1109/JSAC.2019.2933762.
Doan, Khai Nguyen, et al. “Power Allocation in Cache-Aided NOMA Systems: Optimization and Deep Reinforcement Learning Approaches.” IEEE Transactions on Communications, vol. 68, no. 1, 2020, pp. 630–644. DOI: 10.1109/TCOMM.2019.2947418.
Lee, Jihyun, and Jaesung So. “Reinforcement Learning-Based Joint User Pairing and Power Allocation in MIMO-NOMA Systems.” Sensors, vol. 20, no. 24, 2020, article 7094. DOI: 10.3390/s20247094.
Anwar, Adnan, et al. “A Survey on Application of Non-Orthogonal Multiple Access to Different Wireless Networks.” Electronics, vol. 8, no. 11, 2019, article 1355. DOI: 10.3390/electronics8111355.
Vaezi, Mojtaba, et al. “Interplay Between NOMA and Other Emerging Technologies: A Survey.” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 4, 2019, pp. 900–919. DOI: 10.1109/TCCN.2019.2933835.
Luo, Jian, et al. “A Deep Learning-Based Approach to Power Minimization in Multi-Carrier NOMA With SWIPT.” IEEE Access, vol. 7, 2019, pp. 17450–17460. DOI: 10.1109/ACCESS.2019.2895201.
Xu, Zhenyu, et al. “Efficient Allocation for Downlink Multi-Channel NOMA Systems Considering Complex Constraints.” Sensors, vol. 21, no. 5, 2021, article 1833. DOI: 10.3390/s21051833.
Liu, Zhenyu, et al. “Resource Allocation Based on User Pairing and Subcarrier Matching for Downlink Non-Orthogonal Multiple Access Networks.” IEEE/CAA Journal of Automatica Sinica, vol. 8, no. 3, 2021, pp. 679–689. DOI: 10.1109/JAS.2021.1003886.
Xiao, Liang, et al. “Reinforcement Learning-Based NOMA Power Allocation in the Presence of Smart Jamming.” IEEE Transactions on Vehicular Technology, vol. 67, no. 4, 2018, pp. 3377–3389. DOI: 10.1109/TVT.2017.2780536.
2、仿真结果演示
3、关键代码展示
略
当下时代学习怎么用AI是每个人已经之路,给大家推荐几本书:学习AI相关使用技巧!!! 抓住时代红利!!!
4、MATLAB 源码获取
途径一:点击文章中蓝色字体阅读原文
途径二:复制以下网址到浏览器中打开麦完单品
https://www.maiwan8.com/#/dynamicDetail/0/d67a1fb63914add0d16913ea3a047464/index?yqm=5FCPU
途径三:复制网址打开麦完店铺搜索该篇文章标题即可
https://www.maiwan8.com/#/packageA/userDynamicCenter/userDynamicCenter?user_id=1261511
途径四:如果以上方式均失效请通过QQ,邮箱或者微信公众号联系我
(点击上方↑↑↑↑↑蓝色字体跳转)