 夜雨聆风
夜雨聆风





OpenClaw、Claude Code、Hermes:到底该信谁的协调哲学?
三个 AI Agent 同时改代码,最后 merge 时冲突堆成山——你花在解决冲突上的时间,比 Agent 写代码的时间还长。
或者更糟: Agent A 做前端, Agent B 做后端,结果两人对接口的理解完全不一样,最后你手动重写了一遍。
这不是 Agent 不够聪明,是协调哲学出了问题。
我同时深度使用 OpenClaw 、 Claude Code 、 Hermes 三个月后,发现一个反直觉的事实:
工作,做完合并,冲突自然隔离。
这句话是我在用 Claude Code Agent Teams 时突然悟到的。恰好是三种框架最核心的分歧点——多 Agent 协作,到底是该控制、信任工具链、还是信任 Agent 本身?
OpenClaw 、 Claude Code 、 Hermes 给出了三个完全不同的答案。
一、先搞清楚:它们到底在解决什么问题?
很多人把这三个放在一起比,其实它们的出发点完全不同。
| OpenClaw | Claude Code | Hermes Agent | |
|---|---|---|---|
| 核心定位 | 多渠道 AI 网关 + 运营中枢 | IDE 内编码副驾驶 | 自进化个人 Agent |
| 典型场景 | Telegram/Discord 多平台 Bot 、客服、自动化运营 | 写代码、修 Bug 、跑测试 | 长期个人助理、跨会话任务、自我学习 |
| 运行方式 | 常驻进程,多 Agent 隔离运行 | 终端交互,按需启动 | 后台持久运行, 7×24 小时 |
| 记忆策略 | 全量持久化(向量数据库) | 无跨会话记忆(每次重置) | 有限记忆 + 主动压缩(~1300 tokens 上限) |
定位不同,协作哲学自然不同。

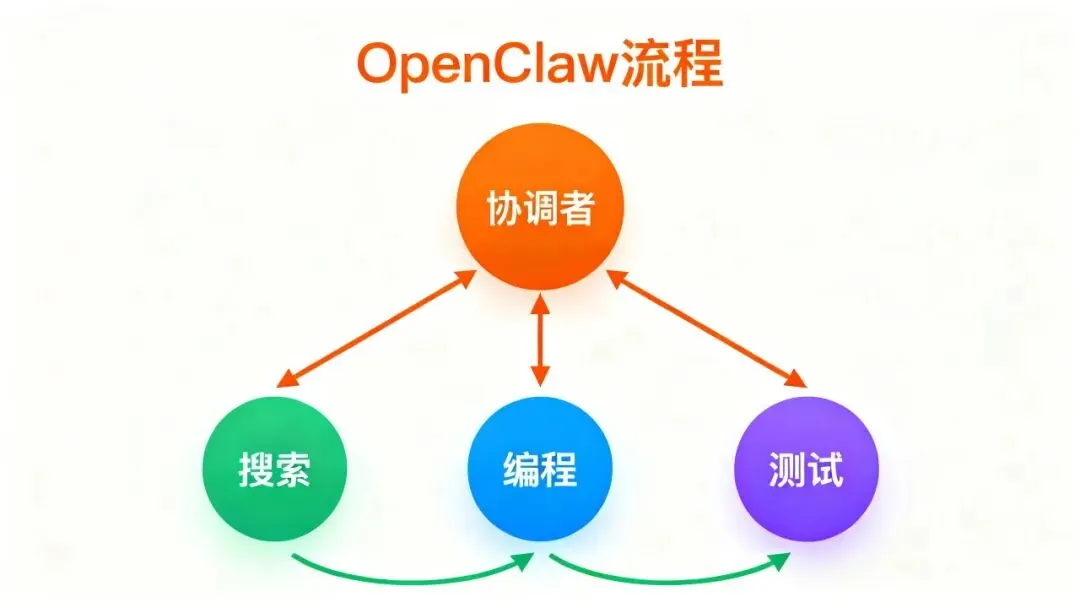
二、 OpenClaw :编排哲学——”我来分配,你们执行”
OpenClaw 的协调哲学是中心化编排。
核心思路:有一个协调者( coordinator / PM Agent ),它负责:
1. 接收任务
2. 拆解为子任务
3. 派发给专门的 Sub-Agent
4. 等结果回报,汇总输出
关键设计决策:
allowAgents 白名单)冲突处理方式:
OpenClaw 处理冲突的方式是预防性隔离——
它的哲学是:冲突不是被解决的,而是被设计掉的。
但问题也很明显:全量记忆持久化, token 消耗随使用时长线性增长;配置复杂,学习曲线高。
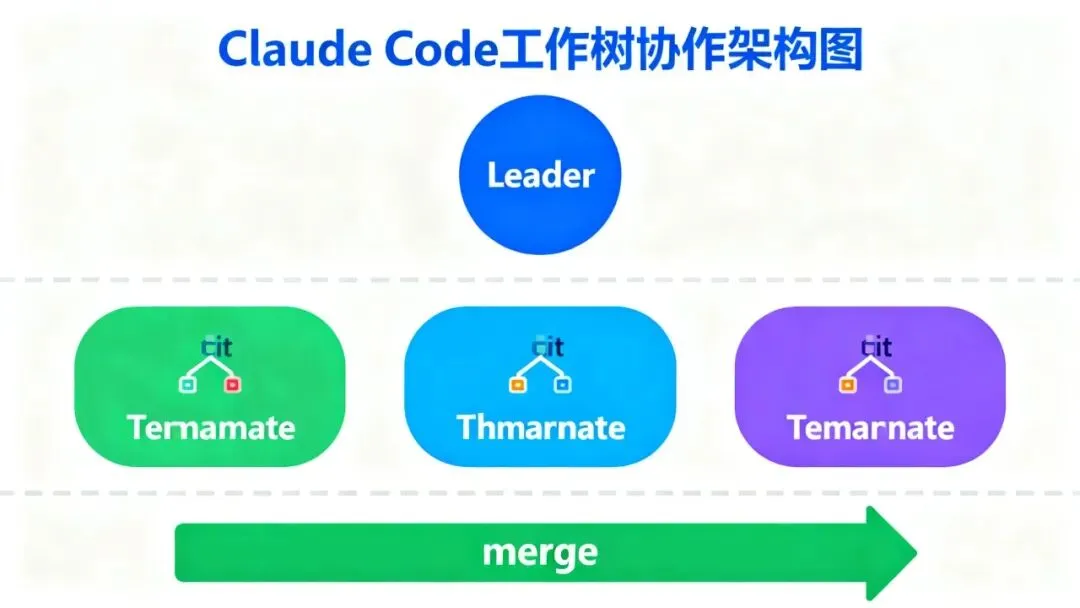
三、 Claude Code :工作树哲学——”工作,做完合并,冲突自然隔离”
Claude Code 的 Agent Teams ( Swarm Mode )采用的是完全不同的哲学:Git Worktree 隔离 + 共享任务列表。
这是我在实际使用中理解最深刻的一点。
关键设计决策:
claimTask 认领任务——半去中心化这正是用户说的:”工作,做完合并,冲突自然隔离”——
Claude Code 的哲学是:不要在框架层解决冲突,让 Git 去处理。 每个 Agent 在独立 worktree 工作,做完之后 merge ,冲突由 Git 的合并机制自然处理。框架只负责任务分配和通信,不负责冲突仲裁。
这是最”信任工具链”的一种哲学——相信 Git 已经解决了分布式协作的问题, Agent 协作完全可以复用同一套机制。
代价:
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 启用)四、 Hermes Agent :进化哲学——”我不是被编程的,我是被训练的”
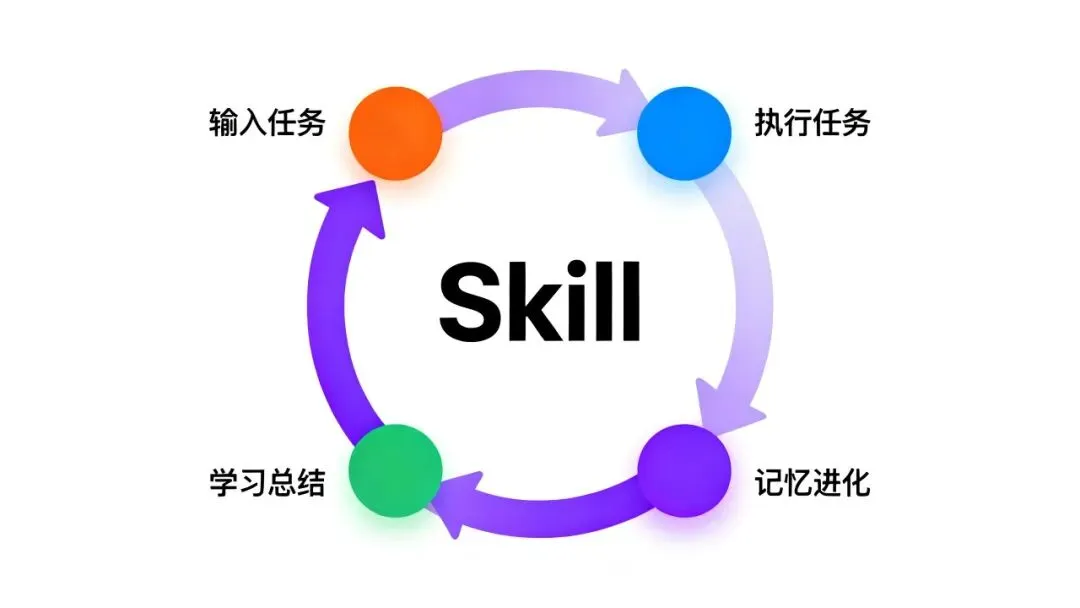
Hermes Agent 的协调哲学和前两者有本质不同:它不是被”编排”的,它是自己学会协作的。
核心机制是闭环学习( Closed Learning Loop ):
关键设计决策:
hermes model 命令切换Hermes 没有传统意义上的”多 Agent 协作”——
它的设计哲学是:不需要多个 Agent 协作,因为一个会自我进化的 Agent 可以持续提升单兵作战能力。 它通过 Skill 积累经验,通过记忆保持上下文,通过自学习优化执行策略。
如果非要类比多 Agent ,它的模式是:当前 Hermes 实例 + 过去的 Skill 版本(经验)+ 长期记忆(上下文),三者协作完成复杂任务。
代价:
五、三种哲学,三种选择
回到根本问题:你相信哪种协调方式?
| OpenClaw | Claude Code | Hermes Agent | |
|---|---|---|---|
| 协调哲学 | 中心化编排 | 工作树隔离 + 共享任务 | 自进化 + Skill 积累 |
| 冲突处理 | 预防性隔离(设计掉冲突) | Git Worktree 自然隔离(让工具链解决) | 无多 Agent 冲突(单兵进化路线) |
| 信任模型 | 协调者可信,执行者受限 | 每个 Teammate 可信, Git 处理合并 | Agent 自我可信, Skill 可审计 |
| 适合人群 | 需要多渠道运营、多任务并行的团队 | 需要高质量代码产出的开发团队 | 需要长期个人助理、隐私敏感的用户 |
| 核心优势 | 生态最大( 13000+技能库) | 代码质量最高( SWE-bench 顶级) | 越用越顺手(自学习能力) |
| 核心劣势 | Token 消耗随使用时间线性增长 | Token 成本高, Teams 模式仍实验性 | 生态不成熟,初期使用成本高 |
六、我的实际使用建议
不需要三选一,它们解决的是不同问题。
我现在的实际使用方式:
如果你要选一个开始:
写在最后
多 Agent 协作的争论,本质上是在争论:智能体应该被控制,还是被信任?
OpenClaw 选择控制:中心化编排,显式授权,隔离优先。
Claude Code 选择信任工具链: Git 已经解决了分布式协作, Agent 协作可以复用同一套哲学。
Hermes 选择信任 Agent 本身:它不是被编程的,它是被训练的, Skill 就是它的”经验”,记忆就是它的”上下文”。
三种哲学没有对错,只有适合与否。
但有一件事是确定的: 2026 年, AI Agent 已经从”能不能用”进化到了”怎么用更好”的阶段。
而”怎么用更好”的答案,就藏在这些底层设计哲学里。