 夜雨聆风
夜雨聆风





【实验室成果Vol.03】获OpenClaw官方采纳!1.3万个Skill超半数“带毒”,人工抽检连斩17个0-day!
AGENTSEY
AI观察
源于学术,归于生活。
理解 AI,不止于技术。
—— Agentsey Team
大家好,我是 Hongbo,UCSB 的在读博士。
今天想和大家分享一下我们团队刚刚发表的论文《Semia: Auditing Agent Skills via Constraint-Guided Representation Synthesis》。
在这项研究中,我们开发了专门针对智能体技能的静态审计工具 Semia。利用它,我们对公开市场上的 1.3 万个真实 Skill 进行了审计,震惊地发现超过一半的智能体技能都存在潜在的语义安全漏洞!而在我们人工抽检的 541 个核心样本中,更是直接锁定了 17 个一直正常使用却从未被报告的高危 0-day 漏洞。
目前,这些漏洞已被顶级开源生态 OpenClaw 全数确认,官方还将 Semia 的底层安全检测逻辑直接采纳并整合到了其静态扫描器中。
今天,我就跟同样关心 Agent Skills 的伙伴们,深度分享一下我们这项研究的成果与背后的技术思考。
-
Semia: Auditing Agent Skills via Constraint-Guided Representation Synthesis
https://arxiv.org/abs/2605.00314
-
OpenClaw采纳我们检测逻辑 (Issue #1912):
https://github.com/openclaw/clawhub/issues/1912
01
到底什么是 Agent Skill ?
在深入探讨之前,先给关心 Agent 底层架构的伙伴们简单梳理一下概念。在如今的 AI 生态中,Agent Skill 就像是给大模型配置的“能力扩展包”,让原本只能聊天的模型具备了执行现实任务的能力,比如读取邮件、执行 Shell 命令,或者签署区块链交易。
有趣且致命的是,每一个 Skill 都是一种“混合产物”(Hybrid artifact)。它由两部分组成:
-
结构化代码(比如 YAML 或 JSON):它定义了智能体“在技术上能做什么”,比如提供了一个可以执行转账的 API 接口。
2. 自然语言描述(Prose):它规定了智能体“在什么时候、以什么方式”去调用这些接口。
02
为什么“用自然语言写安全规则”不堪一击?
我们观察到,在如今的 AI 生态中,Agent Skill往往是一种混合产物。开发者一方面用结构化的代码(比如 YAML)定义了它可以执行哪些操作,比如读取邮件、执行 Shell 命令或者进行区块链转账;另一方面,却用‘自然语言(Prose)’来规定这些操作的触发条件,比如写上一句“在跨账户转账前,必须获得人类操作员的同意”。
但这其实是非常危险的。实验结果显示,由于大模型在每次调用时都会重新以概率化的方式去理解这些自然语言,攻击者完全可以通过“间接提示词注入(Indirect Prompt Injection)”来扭曲大模型的认知。只要在给大模型阅读的邮件或网页里塞入巧妙的恶意指令,大模型就会毫不犹豫地绕过那个所谓的“人类同意”规则,直接把钱转走。在这个过程中,没有任何传统的代码漏洞被触发,仅仅是因为大模型按照攻击者的意愿重新解释了那句英文。
03
现有防御的困境与 Semia 的破局
面对这种安全盲区,现有的手段往往显得很无力。传统的静态分析工具只看得懂结构化代码,完全看不懂自然语言里的安全规则。而如果你直接把这段技能描述丢给大模型让它去审计,它的判定结果又极不稳定,不仅每次运行的结论都在变,而且它根本无法在数学上证明“某个危险操作绝对不会被触发”。
为了解决这个问题,我们开发了 Semia——一个专门针对 Agent Skills 的静态审计工具。
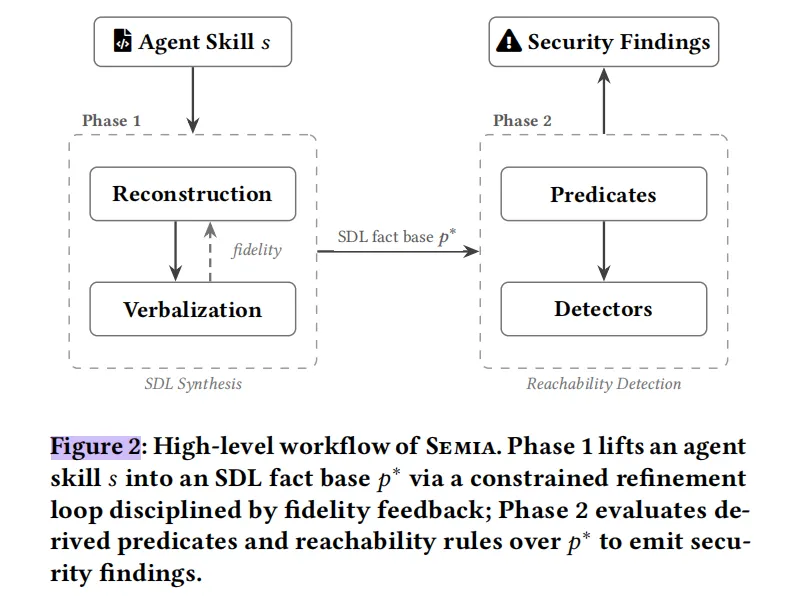
我们的核心设计理念是:不让大模型直接做裁判,而是让它做“翻译”。Semia 包含两个阶段:
-
约束引导表征合成(CGRS):
我们并没有指望大模型一次性翻译对,而是设计了一个“提出-验证-评估(propose-verify-evaluate)”的闭环约束引擎。我们让大模型把自然语言规则翻译成严格的关系型事实库(我们称之为 Skill Description Language, SDL)。如果大模型出现了幻觉或引用错误,我们的结构化验证器会精准捕获并把错误信息喂给它,引导它不断修正,直到输出的图谱既在结构上完美,又在语义上忠实于开发者的原始意图。
-
确定性的可达性分析(Reachability Detection):
一旦拿到了严谨的 SDL 事实库,剩下的工作就不再依赖大模型了。我们通过编写 Datalog 规则,直接在图谱上运行确定性的路径可达性查询,精准抓取诸如“缺少人类审批网关”、“敏感本地资源越权”等致命漏洞。
04
龙虾社区实测:1.3 万海量审计与 17 个 0-Day 的确认
为了验证 Semia 的实战能力,我们对公开市场上的 13,728 个真实的 Agent Skills 进行了大规模测试。结果令人担忧:超过半数的skills在 Semia 的扫描下暴露出了潜在的安全隐患。
在此基础上,我们抽取了 541 个样本进行专家级的人工标注和深入测试,并在“龙虾”(Clawhub/OpenClaw)的 skillhub 里精准抓出了 17 个以前从来没人报告过、一直正常使用却存在致命漏洞的 skill。
举两个我们抓到的真实案例:
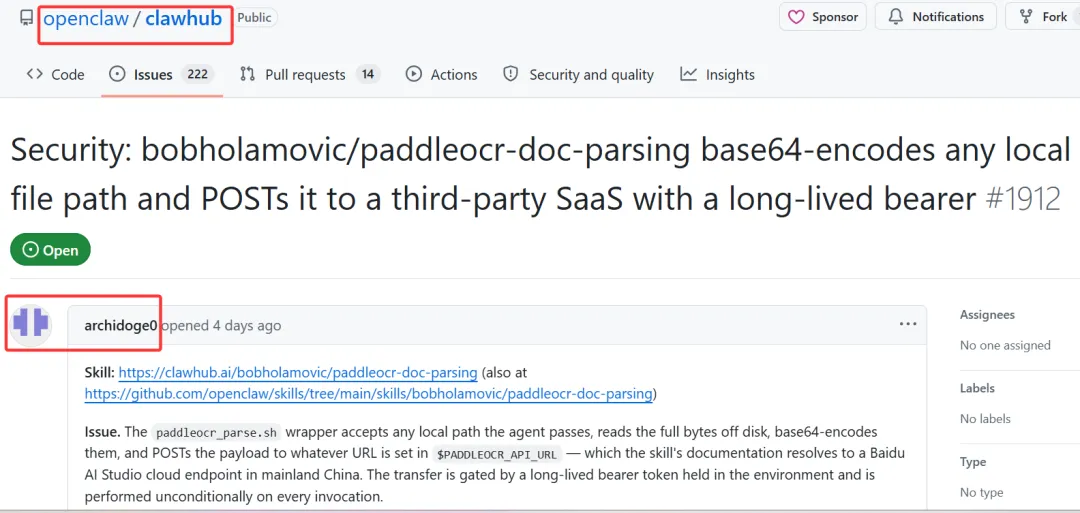
⏩隐蔽的数据外传(Issue #1912):一个名为 paddleocr-doc-parsing 的常用技能,在文档里看起来只是个普通 OCR 工具,但实际上它会把本地文件的完整内容全部 base64 编码,然后带着一个长期的鉴权 token,悄无声息地 POST 发送给第三方的 SaaS 服务商,造成极大的机密外传风险。
⏩虚假的安全承诺(Issue #1901):一个密码管理插件号称“绝不会在聊天中暴露密码”,结果却在后台的进程环境变量和内存里留了不受保护的后门。
05
官方认可:从发现漏洞到被官方基础设施采纳
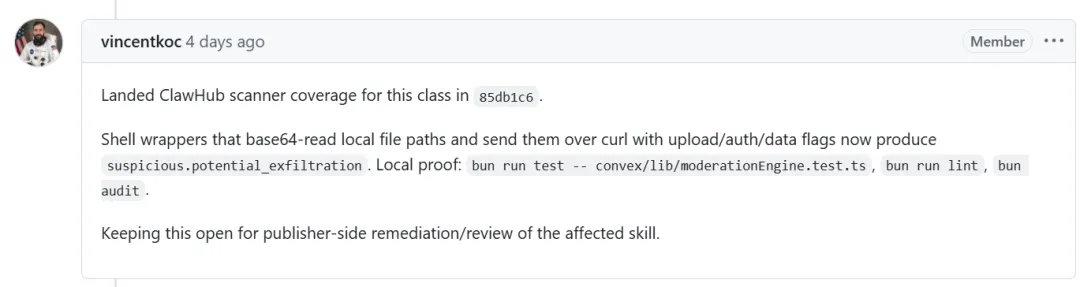
这 17 个高危 0-day 漏洞不仅被“龙虾”社区的 maintainer 团队全数确认并协助修复,更让我们团队感到振奋的是——我们被官方开源社区盖章认可了。
针对我们在实测中揭露的这些底层逻辑漏洞(如 #1912 中的隐蔽外传),OpenClaw 官方 Maintainer 团队(如 vincentkoc)不仅确认了漏洞,还直接将这种静态分析检测逻辑融合到了 Clawhub 官方自带的静态扫描器(ClawHub scanner)中。这意味着,Semia 论文里发现的安全盲区,现在已经实打实地变成了保护整个智能体生态圈的基础设施。
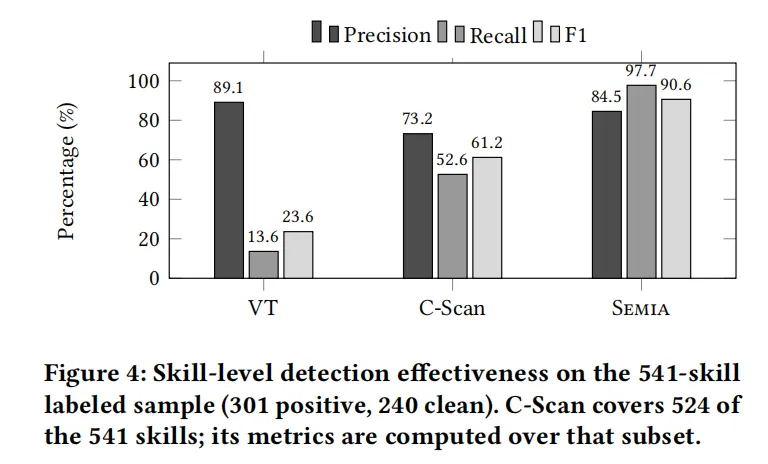
而在我们构建的专家标注核心样本库中,Semia 达到了 97.7% 的召回率和 90.6% 的 F1 分数。相比之下,看不懂自然语言的 VirusTotal 只找出了 13.6% 的漏洞,而社区此前自带的扫描器 F1 只有 61.2%。
写在最后:一点个人观察
完成这项研究后,我最大的体会是:在智能体时代,永远不要试图仅用一段自然语言去约束 AI 的危险行为。自然语言的边界太模糊,太容易被恶意 Prompt 渗透了。
真正坚固的安全底线,必须将这些自然语言策略“降维”并沉淀为可被静态分析器严谨检验的结构化约束。发现漏洞只是第一步,希望 Semia 能为下一代大模型智能体的安全审计提供一种更加务实、工程化的解法。
完整论文和底层设计细节已经公布。如果你对这 17 个具体的漏洞实战案例感兴趣,也欢迎去我的个人 GitHub 主页(@archidoge0)查看所有公开的 Issue 记录。
欢迎交流!

源于学术,归于生活。
理解 AI,不止于技术。
欢迎关注,与我们交流
