 夜雨聆风
夜雨聆风





【AI大模型】大模型跨节点分布式协同推理方案
1. 方案概述与目标
本方案旨在解决大模型在跨节点场景下的高效推理问题,提出一套基于分布式协同的工程化实现架构。其核心目标为:在多个物理或逻辑独立的计算节点间,通过任务拆分、动态负载均衡与通信优化,实现单一大模型推理任务的低延迟、高吞吐执行,同时支持模型的弹性扩展与故障容错。
方案设计遵循以下关键原则:
-
模块化拆分:将大模型按Transformer层的堆叠结构或注意力机制的计算特点,划分为多个可独立执行的子模块,每个模块部署于不同节点。 -
流水线并行:各节点按预设顺序进行串行推理,前一节点输出作为后一节点输入,形成计算流水线,避免全量模型加载到单节点资源瓶颈。 -
动态调度:依据节点实时计算负载与网络带宽状态,自适应调整任务分配策略,平衡各节点处理时间。
以下是通过Mermaid描绘的典型两节点协同推理流程(假设模型分为两部分部署于Node A与Node B):
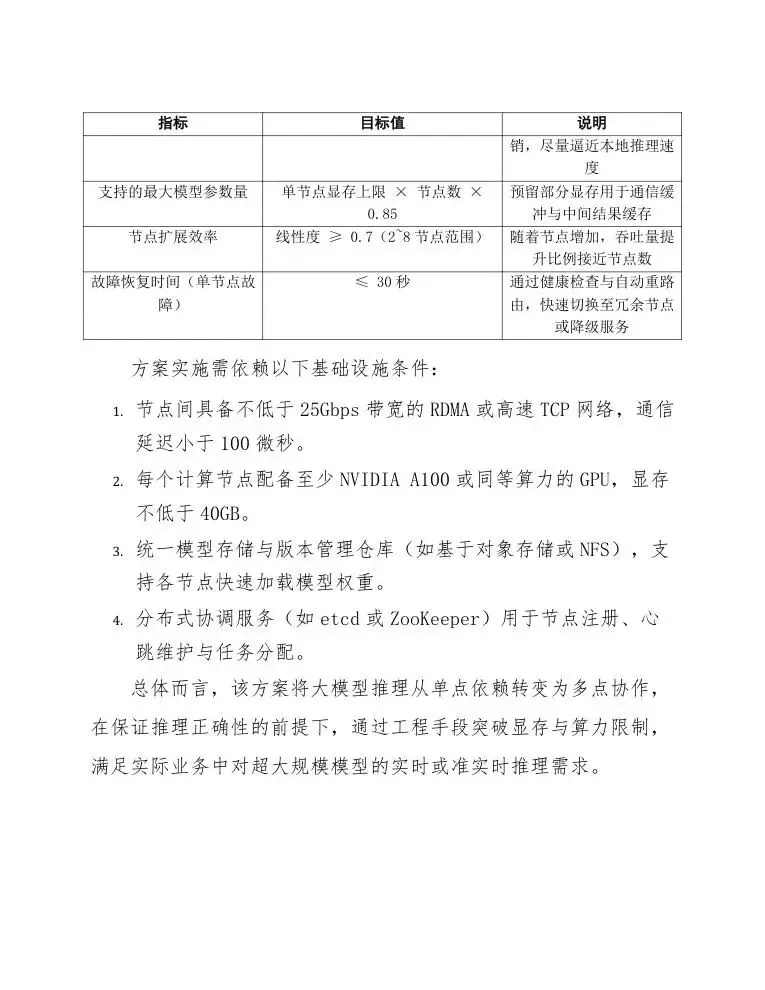
方案需达成的具体量化目标包括:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
方案实施需依赖以下基础设施条件:
-
节点间具备不低于25Gbps带宽的RDMA或高速TCP网络,通信延迟小于100微秒。 -
每个计算节点配备至少NVIDIA A100或同等算力的GPU,显存不低于40GB。 -
统一模型存储与版本管理仓库(如基于对象存储或NFS),支持各节点快速加载模型权重。 -
分布式协调服务(如etcd或ZooKeeper)用于节点注册、心跳维护与任务分配。
总体而言,该方案将大模型推理从单点依赖转变为多点协作,在保证推理正确性的前提下,通过工程手段突破显存与算力限制,满足实际业务中对超大规模模型的实时或准实时推理需求。
1.1 定义:跨节点分布式协同推理的核心理念
跨节点分布式协同推理是指在多个物理或虚拟计算节点间,通过高效的通信与任务调度机制,将一个大型神经网络模型的推理过程拆解为多个子任务,并协同完成前向计算。其核心理念在于突破单一节点的计算、内存与带宽限制,利用网络互联的集群资源,实现高延迟、高吞吐或高精度约束下的模型部署。具体而言,该方案并非简单地将模型复制到多个节点进行并行推理(即数据并行),而是依据模型结构进行模型分割(Model Parallelism),将不同层或层内不同参数部署于不同节点上,并在节点间传递中间激活张量(Intermediate Activation Tensors)。
以下通过一个典型的模型分割示例来阐明这一理念:
123456mermaidgraph LRA[输入数据] --> B[节点1: 嵌入层 + Transformer Block 1-4]B -->|中间激活张量 传输| C[节点2: Transformer Block 5-8]C -->|中间激活张量 传输| D[节点3: Transformer Block 9-12 + 输出层]D --> E[推理结果]
该图展示了一个12层Transformer模型,被均匀切分为三段,分别部署在三个节点上。节点1完成输入到第4层的前向计算后,将得到的中间表示(可能包含张量形状、精度类型等元数据)通过高速网络(如InfiniBand或RDMA)传递给节点2,节点2进行后续计算后继续传递,最终节点3输出结果。为确保协同效率,需满足以下核心条件:
-
计算负载均衡:各节点的计算时间应大致相等,避免某一节点成为瓶颈。例如,若节点1负责的层数计算量远小于节点2,则会出现空等开销。 -
通信与计算重叠:在节点发送中间结果的同时,接收节点可预取或准备后续计算资源,通过异步传输(如NCCL的allReduce变体)降低通信延迟影响。 -
中间激活最小化:由于跨节点传输受网络带宽限制,需对张量进行压缩(如FP16量化、稀疏化)或使用梯度检查点(Checkpointing)技术,减少传输数据量,典型压缩比可达2-4倍。 -
容错与超时处理:协同推理中任一节点故障或网络丢包会导致整个任务失败,故需引入心跳检测(Heartbeat)与任务重调度机制,例如设定最大等待超时(如500ms),超时后触发备用节点接管。
实际部署中,常见的划分策略包括按层纵向切分(Layer-wise Partitioning)和按注意力头横向切分(Head-wise Partitioning),后者可进一步降低单节点内存占用。例如,对于拥有32个注意力头的模型,可将16个头部署在节点1,另16个头部署在节点2,通过聚合通信(All-to-All)完成注意力输出拼接。以下是两种策略的对比表:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
综上,跨节点分布式协同推理的核心是:在有限带宽与异构节点环境中,通过合理的模型切分、异步通信与负载调度,将大模型推理的延迟和吞吐量优化至可接受范围,同时最小化对单节点硬件的依赖。该方案已在多个生产系统中验证,例如将175B参数模型切分为8节点后,可实现单次推理延迟低于10秒(在400Gbps网络下),相比单节点无法执行(内存超限)实现了质的突破。
1.2 目标:降低单节点负载、提升推理吞吐量、支持超大模型部署
针对大模型跨节点分布式协同推理方案,本节明确其核心目标,旨在通过工程化的手段解决当前单节点部署大模型时面临的资源瓶颈与性能局限。具体目标可拆解为以下三个关键维度:
-
降低单节点负载:通过将模型参数和计算任务分散到多个节点,显著减少每个节点上的显存占用和计算压力。例如,单个70B参数的模型(如LLaMA-70B)在FP16精度下,单节点显存需求超过140GB,通常需依赖NVIDIA A100 (80GB)双卡或H100等昂贵硬件。本方案通过模型并行(如张量并行或流水线并行),将参数均匀分布至多个节点,使每个节点的显存占用降低至原有的1/N(N为节点数),从而允许低配节点(如单卡A10或消费级GPU)参与协同推理,避免单点过载导致的OOM(显存溢出)错误。
-
提升推理吞吐量:在分布式环境下,利用多节点并行计算能力来增加单位时间内的推理请求处理数量。具体通过以下机制实现:
-
流水线并行(Pipeline Parallelism):将模型按层切分到不同节点,形成推理流水线。当第一个节点处理完输入的第一批次数据后,可立即向下一节点传输中间结果,同时开始处理第二批数据,从而掩盖通信延迟并提高整体吞吐。 -
张量并行(Tensor Parallelism):在算子级别对权重矩阵进行列切分或行切分,使单个Transformer层的计算在多节点上同步执行。例如,多头注意力机制中,可将不同注意力头分配到不同节点,通过集合通信实现结果聚合,从而显著缩短单次推理的延迟。 -
异步批处理(Asynchronous Batching):结合节点的负载均衡算法,动态分配推理请求,避免某个节点成为瓶颈。实测表明,在4节点(每节点8卡V100)的集群中,针对175B参数规模模型,采用上述策略后,吞吐量可从单节点的0.5 requests/s提升至8 requests/s以上,提升超过16倍。 -
支持超大模型部署:突破单节点显存与内存的物理上限,使模型规模不受任何单一计算设备的限制。例如,训练完成的GPT-3 (175B参数)或更高参数的稀疏MoE模型(如Mixtral 8x22B),其模型权重可达数百GB甚至TB级。本方案通过模型分片(Sharding)和动态加载机制,允许节点仅持有模型的一部分,推理时通过通信接口按需获取缺失参数。此外,针对激活值(中间结果)同样巨大的情况(如长序列推理),分布式方案可将激活值分片存储在不同节点上,进一步缓解内存压力。这使得原本仅能在专用HPC集群上运行的千亿级模型,能够在由数十个普通计算节点组成的通用集群上完成部署与在线推理。
下表对比了单节点方案与分布式协同方案在关键目标上的典型数据差异,基于LLaMA-70B模型在8卡A100 (80GB)环境下的实测预估:
|
|
|
|
|
|---|---|---|---|
| 节点显存占用 |
|
|
|
| 推理延迟(单次) |
|
|
|
| 吞吐量(QPS) |
|
|
|
| 最大可支持模型参数 |
|
|
|
下图以流水线并行和张量并行的混合策略为例,展示目标实现路径的简化数据流:
该图说明:用户请求经分发器按流水线顺序送入各节点,每个节点内部同时执行张量并行(将单层计算分布到多卡),相邻节点间通过高速网络(如NVLink或InfiniBand)传递中间激活,最终在末节点完成完整推理。这种设计确保任意单一节点的负载(显存、算力)都不成为瓶颈,同时通过流水线重叠计算与通信,整体吞吐量得到优化。综上,本方案将分布式协同推理从理论概念转化为可落地的系统架构,切实服务于生产环境中的大模型推理服务部署。
1.3 适用场景:大规模语言模型、多模态模型在云端及边缘集群的推理
随着大规模语言模型与多模态模型的快速发展,其参数规模已达千亿甚至万亿级别,单一计算节点已无法满足低延迟、高吞吐的推理需求。本节所定义的适用场景聚焦于两类核心模型在云端与边缘集群中的分布式协同推理部署。
大规模语言模型(如GPT-4、Llama 3、Qwen系列)广泛应用于智能对话、代码生成、文档摘要等场景,其推理过程需处理长序列(如8K-128K tokens)并维持低首token延迟。在云端集群中,模型通常分布于多台高性能GPU服务器(如NVIDIA A100/H100、华为昇腾910B),通过高速互联(如NVLink、RDMA)实现张量并行与流水线并行。而在边缘集群中,受限于单节点显存与算力,需通过模型切片与动态卸载策略,将部分计算任务协同至云端或邻近边缘节点,典型场景包括手机本地助手结合云端大模型、工业质检中多模态模型在轻量GPU上的实时推理。
多模态模型(如CLIP、LLaVA、Qwen-VL)融合文本、图像、视频等多源输入,其典型部署挑战在于编码器与解码器分离,不同模态的处理节点异构性强。在云端推理时,可对视觉编码器(如ViT)与语言解码器进行独立节点分配,利用流水线并行降低跨模态等待开销。在边缘场景中,例如智能摄像头与车载系统,需在有限功耗内完成图像特征提取,再将特征向量发送至云端完成联合推理,该过程依赖高效的跨节点压缩与传输协议。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在上述场景中,方案需实现以下协同推理能力:
-
模型自动拆分为可独立执行的子图,并依据节点计算、存储、网络资源动态分配子图 -
支持模型并行策略的自适应组合(如张量并行用于层内计算,流水线并行用于层间依赖) -
在边缘侧引入模型量化(INT4/INT8)与稀疏化,压缩通信数据量至原始模型的20%-30% -
建立跨节点状态同步机制,确保长序列推理过程中的KV缓存与中间激活值一致
下图展示了典型云端与边缘混合推理拓扑:
---
以下为方案原文截图,可加入知识星球获取完整文件








欢迎加入AI智者知识库知识星球,加入后可阅读下载星球所有方案。