Anthropic 旗下的 Claude Code 近期被完整拆解了源码。55 个目录、331 个模块,这套目前经过最充分实战检验的智能体架构,通过.map 文件完整暴露在公众视野中。 独立开发者 Rohit 耗费大量精力逐文件研读,梳理出每一个架构决策、重试路径、压缩策略和权限管道,最终写成一篇万字长文 —— 这不是简单的代码拆解,而是一份可直接复用的生产级智能体蓝图。 Rohit 的原文标题:Building Harness——从 Claude Code 源码中提取 Agent 架构蓝图 读完之后我最大的感受是:当大多数人还在讨论 “怎么用好模型” 的时候,Anthropic 已经在解决一个完全不同的问题:如何让一个智能体在生产环境中连续运行数百轮而不崩溃。答案从来不在模型本身,而在模型周围那一圈精密的工程系统。我将原文中最核心的设计决策提炼出来,逐一拆解清楚。
01 不是三层,是四层 :::
行业内普遍认为智能体由三层构成:冻结的模型权重(固化的智能)、运行时上下文(提示词 + 对话历史)、外围外壳(工具、循环、错误处理)。 几乎所有教程和框架文档都沿用这个划分,普林斯顿 NLP 团队的 SWE-agent 论文也验证了这一方向的正确性:同一个 GPT-4,仅通过优化交互界面设计,SWE-bench 测试成绩就提升了 64%。模型和任务都没变,只是运行环境变了,性能提升完全来自第二和第三层。 但当你翻开 Claude Code 的源码会发现,Anthropic 的布局远不止这三层。 里面藏着大量超出 “外壳” 范畴的设计:四级 CLAUDE.md 层级结构支持企业管理员通过 MDM 下发全局策略;基于磁盘的任务列表配合文件锁,确保并行子智能体不会互相覆盖数据;Git worktree 隔离机制让五个智能体在同一个仓库的五个分支上同时工作零冲突;从企业级到项目级、用户级再到会话级的权限管道,层层传递拒绝规则。 这些都不是简单的 “外壳功能”,而是真正的生产级基础设施:多租户管理、角色权限控制、资源隔离、状态持久化、分布式协调。Rohit 因此提出了智能体的第四层架构: 大多数团队只讨论前三层,因为前三层有趣、好讲、容易出论文。第四层几乎没人讨论,因为它全是繁琐且枯燥的基础工作 —— 你需要想清楚权限怎么分层、状态跨会话怎么存储、多个智能体同时写同一个文件怎么避免冲突。 但恰恰是这第四层,决定了你的智能体是一个只能演示的酷炫 Demo,还是一个每天有上万人在用的成熟产品。 02 核心循环 :::
Claude Code 的核心心脏位于query.ts文件,这 1729 行 TypeScript 代码藏着最关键的架构决策:它没有用行业通用的 while 循环来驱动智能体,而是采用了async generator(异步生成器)。 这个看似微小的选择,却从根本上解决了生产环境中智能体运行的五大痛点。绝大多数教程教你的while (needsMoreWork) { result = await callModel(); }循环,在 Demo 里跑得通,但放到生产环境会同时爆发五个问题: 没有流式输出:用户盯着空白屏幕等 10-30 秒,体验极差。Claude Code 的生成器一边运行一边 yield StreamEvent,用户能逐字看到智能体的工作过程。能看到过程的用户会更信任智能体,而信任正是智能体获得更高自主执行权限的关键。 没有原生取消机制:while 循环里按 Ctrl+C 需要从外部接入复杂的中止逻辑。生成器天然支持取消 —— 调用方停止调用.next(),finally 块会自动运行,完成所有资源清理。 没有背压控制:当模型生成速度快于终端渲染速度时,while 循环会把所有内容缓存在内存里,长会话会直接导致进程崩溃。生成器在消费者停止拉取时会自动暂停生产,内存占用始终保持稳定。 Claude Code 的每一轮迭代都会经过五个标准阶段:Setup(准备阶段:分配 token 预算、加载压缩策略)→ Model Invocation(模型调用:流式执行,工具边生成边运行)→ Error Recovery(错误恢复:提示词过长就压缩重试,输出 token 不足就自动从 32K 升级到 64K)→ Tool Execution(工具执行:运行所有未完成的工具调用)→ Continuation Decision(继续判断:还有工具要调用吗?达到最大轮数了吗?)。 错误恢复逻辑完全内嵌在循环内部,而不是在外面包一层简单的 try-catch。每个阶段都清楚什么地方可能出错,并且有专门的恢复路径。这就是 “智能体遇到速率限制就直接崩溃” 和 “智能体自动退避、重试、切换模型、继续工作” 之间的本质差距。 03 工具并发 :::
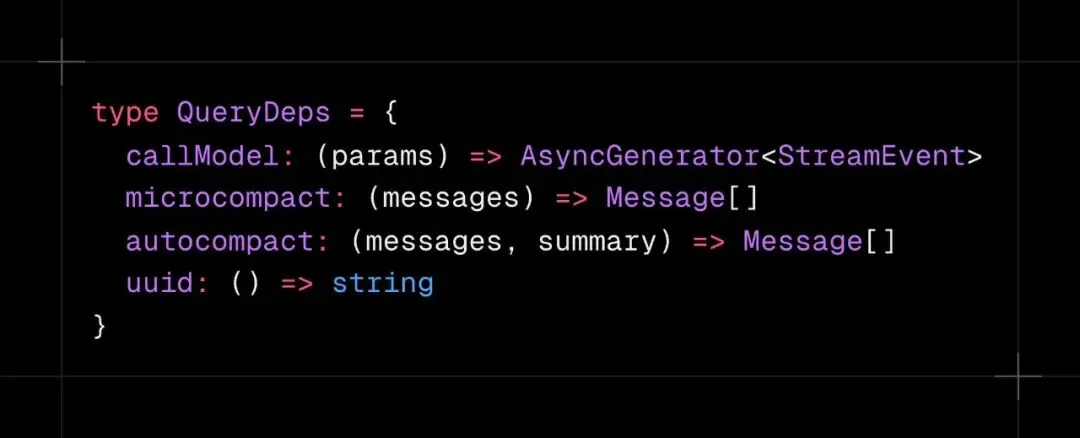
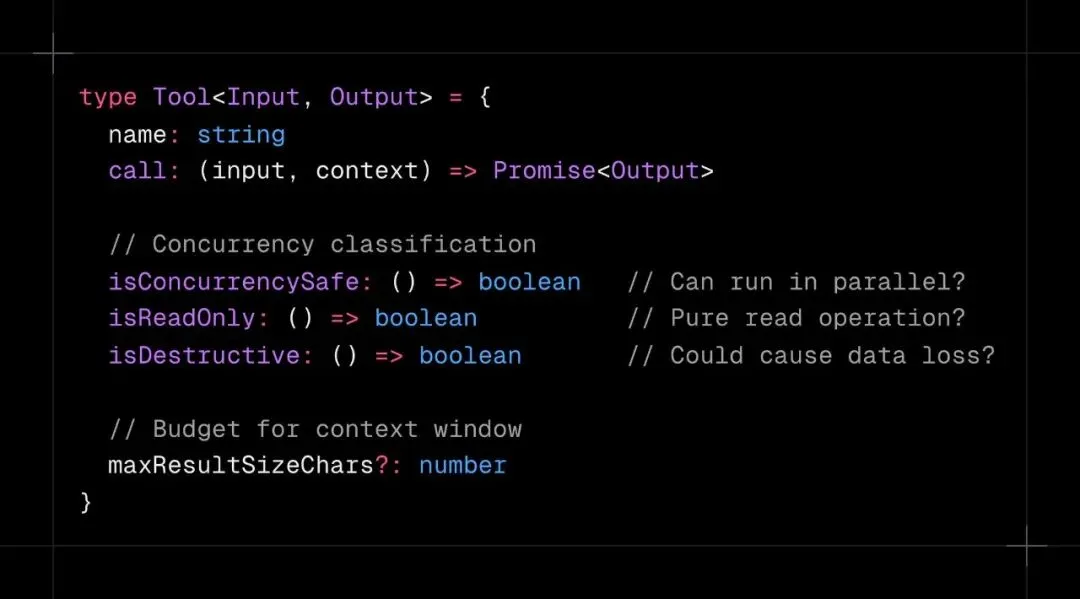
Claude Code 内置了超过 45 个工具,但真正决定体验的不是工具数量,而是执行方式。 绝大多数智能体框架要么采用顺序执行(安全但效率低下),要么全部并行(速度快但存在数据损坏风险)。Claude Code 的解决方案是在工具定义阶段就按并发行为打上标签,由编排层统一调度。 工具并发分类代码:QueryDeps 接口定义了依赖注入的模型调用和压缩方法 编排层toolOrchestration.ts会将工具调用分批执行:Glob、Grep、Read、WebFetch 等只读工具最多允许 10 个并行运行;Bash 写入、Edit、Write 等写操作工具则严格串行执行。搜索五个文件可以并行跑,编辑同一个文件必须一个一个来。 这种设计同时兼顾了并行的速度和串行的安全性,能让多工具回合的执行速度提升 2-5 倍,累积到整个会话就是分钟级别的时间节省。最关键的是,分类是在工具定义时就完成的,不需要运行时动态分析,整个调度逻辑简洁、可靠且极易扩展。 04 流式工具执行 :::
StreamingToolExecutor:模型还在生成下一步描述时,第一个工具已经在跑了 这是 Claude Code 中最精妙的设计之一。绝大多数框架会等模型完整生成所有工具调用后再开始执行,而 Claude Code 在流式传输过程中就启动了工具运行 —— 只要一个工具调用的输入 JSON 完整接收,立刻开始执行,无需等待后续内容。 对于一轮包含三个工具调用的操作,这种设计能隐藏 2-5 秒的延迟。当模型还在描述下一步操作的时候,第一个工具的执行结果可能已经返回了。 真正难的是各种边界情况的处理:如果并行批次中某个工具执行失败,per-tool 的siblingAbortController会终止同批次的其他兄弟进程,但父级查询控制器不受影响,对话可以正常继续;如果流式传输失败回退到非流式模式,执行器会丢弃所有排队的工具,为正在运行中的工具生成合成错误响应;无论工具执行的先后顺序如何,最终结果都会按照模型生成的原始顺序返回给用户。 每一个细节都是被真实的生产故障打磨出来的。这些看似 “性能优化” 的代码,本质上是一份用户在真实场景中踩过的所有坑的清单,最终以代码的形式变成了标准化的解决方案。 05 提示词即缓存 :::
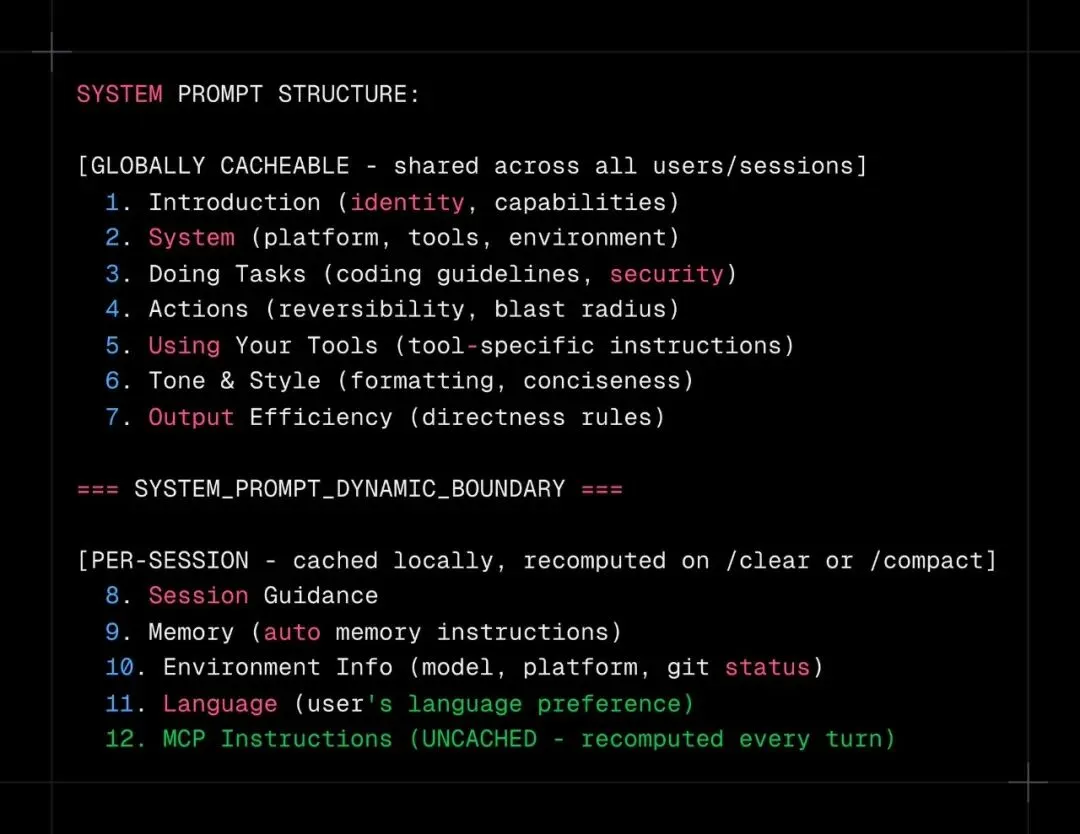
系统提示词结构:SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记把提示词分为全局缓存区和动态区 Claude Code 的系统提示词不是一个简单的字符串,而是一个带有缓存元数据的结构化数组。 一个名为SYSTEM_PROMPT_DYNAMIC_BOUNDARY的标记,将提示词清晰地划分为两个区域。标记以上的部分:身份介绍、系统规则、工具说明、安全准则等,对所有用户、所有会话完全相同,能够命中 API 层面的全局提示词缓存。这部分内容占整个系统提示词的约 80%,意味着你不需要每次 API 调用都重新 tokenize 这 577 多行内容。 标记以下的部分则按更新频率划分:按会话缓存(每会话计算一次)或易失性(每轮重新计算)。易失性部分被尽可能压缩到最小,因为任何一点变更都会导致后面所有内容的缓存失效。 还有一个极其精妙的设计:git 状态、CLAUDE.md 内容、当前日期等用户上下文,被注入为第一条用户消息(用<system-reminder>标签包裹),而不是放在系统提示词里。原因非常实际:这些内容每轮都会变化,放在系统提示词里会从变更点开始让后面所有内容的缓存失效。放到用户消息里,系统提示词的缓存就能逐轮保持稳定 —— 相当于免费获得了 80% 的提示词 tokenization 成本优化。 在规模化运营时,这个设计决定了你的智能体每次对话花 0.02 美元还是 0.20 美元。 没有任何一个智能体教程、框架文档或技术大会讨论过按缓存效率设计提示词,但这可能是整个代码库里杠杆最高的优化。 06 四级压缩 :::
绝大多数智能体框架在遇到上下文窗口限制时,要么粗暴截断旧消息,要么直接崩溃。而 Claude Code 支持无限长度的对话,依靠的是一套从低成本到高成本的四级压缩策略。 Microcompact(微压缩) :每轮对话自动运行。如果一个工具上次调用后的结果没有变化,就用缓存引用替换完整结果。比如反复读取同一个文件,能省下数千 token。成本:几乎为零。Snip Compact(裁剪压缩) :接近 token 上限时触发。删除对话开头的旧消息,但保留最近几轮的 “受保护尾部”。不需要调用模型,速度极快,属于有损压缩。Auto Compact(自动压缩) :当裁剪压缩不够用时触发。用一次单独的模型调用总结之前的对话,用摘要替换原始消息。系统会追踪压缩状态,避免出现 “总结的总结的总结” 这种恶性循环。Context Collapse(上下文折叠) :超长会话的最后手段。采用多阶段分步压缩:先压缩工具结果,再压缩思考块,最后压缩整段内容。成本最高,只在连续运行数小时的会话中使用。核心原则非常清晰:最便宜的策略先跑,最贵的策略最后才用。大多数带压缩功能的框架会直接跳到模型总结,而总结会在压缩调用和总结本身两个地方都消耗 token。Microcompact 和 Snip 能以零模型调用处理绝大多数压缩场景。 而 “受保护尾部” 这个概念尤为关键:无论怎么压缩,最近几轮的消息永远不会被总结。模型始终对刚做过的事情保持完整记忆,哪怕更早的上下文已经被压缩了。这样模型就不会在执行计划的过程中忽然忘了自己刚才在干什么。 07 七级权限 :::
七阶段权限管道:从工具调用请求到最终执行,每一步都有审批或拒绝的机会 绝大多数智能体框架的权限控制只是一个简单的二元开关:允许或拒绝。而 Claude Code 采用了一套七阶段的权限审批管道,为每一次工具调用提供精细化的控制。 从工具调用请求发出到最终执行,会依次经过七个关卡:输入验证(Zod schema 校验)→ 全局拒绝规则(企业、项目、用户、会话四级)→ 允许规则(模式匹配)→ 工具专属检查 → 自定义钩子(外部脚本)→ 分类器(可选 ML 模型)→ 用户提示(交互式对话)。每一步都有批准或拒绝的权力。 规则采用类似 glob 的模式匹配工具名和输入:“允许所有 bash” 太粗放 —— 没人想让智能体跑rm -rf /;“禁止所有 bash” 又让智能体变成废物。“允许 git 命令和 npm test,其他操作都需要我确认”—— 这才是权限控制的最佳平衡点。 这种设计构建了渐进式的信任体系:新用户从默认模式开始,每个操作都需要批准;熟悉之后可以切换到 acceptEdits 或 bypassPermissions 模式。这不是安全和速度之间的二选一,而是一个可以平滑调节的光谱。 自定义钩子是最后的逃生口:你可以编写自己的脚本接收工具调用详情,返回批准或阻止。企业可以借此搭建专属护栏:阻止破坏性操作、任务完成后发 Slack 通知、每次文件写入后自动跑 linter,不需要修改一行 Claude Code 的源码。 这个权限设计最聪明的地方在于:它把 “信任” 变成了一个可以被量化和调节的参数,而不是一个要么全给要么全不给的二元选择。这对企业落地 AI 编程助手来说至关重要 —— 安全团队能接受的底线和开发者想要的自由度之间,终于有了一个合理的折中方案。 08 823 行重试 :::
withRetry.ts 有 823 行。每一行的存在都因为一次生产事故。
429(速率限制) :检查 Retry-After 响应头。低于 20 秒?立即重试,保持快速模式。超过 20 秒?进入 30 分钟冷却。检测到 overage-disabled 头?永久禁用快速模式,并向用户解释原因。
529(服务器过载):追踪连续 529 错误的计数。连续三次且有备选模型可用?自动切换模型。后台任务?直接放弃防止级联故障。前台任务?采用指数退避重试。
400(上下文溢出) :解析错误消息提取实际 token 数和限制值。重新计算可用 token:限制值 – 输入 token – 1000 安全缓冲,并设置 3000 的最低输出下限。调整预算后自动重试。
退避公式: delay = min(500ms × 2^attempt, 32s) + random(0, 0.25 × baseDelay)
对于无人值守会话(比如 CI/CD 流水线、后台智能体),系统会进入持久重试模式:429 和 529 错误无限重试,最大退避 5 分钟,设置 6 小时硬重置上限,每 30 秒发一次心跳防止被进程管理器杀死。 流式传输层还有自己独立的可靠性机制:90 秒无数据超时看门狗(45 秒时发出预警)、连续两个数据块间隔超过 30 秒的停顿检测、流式失败自动回退非流式且保持连续 529 计数不被重复统计。 在 fetch 外面套三次重试不是生产级可靠性。一个理解每种错误语义、并为每种错误提供专门恢复路径的状态机,才是。 09 子 Agent 隔离 :::
子 Agent 获得独立上下文:appState 设置器变为空操作,文件状态缓存被克隆 Claude Code 能生成子 Agent——独立的 Agent 循环实例,各自有自己的上下文、工具和工作目录。终止父 Agent 会级联终止所有子 Agent。但子 Agent 不能修改父 Agent 的状态: appState 的 setter 变成了空操作,文件状态缓存是克隆的。
修改代码的子 Agent 还会获得自己的 Git worktree ——一个 Agent 一个工作树,各自在自己的分支上操作。并行 Agent 共享工作区会制造冲突,worktree 隔离让每个 Agent 独立工作,验证通过后再合并。 node_modules 做符号链接防止磁盘膨胀——五个并行 Agent 不需要五份依赖副本。
任务协调用的是基于磁盘的任务列表 + 文件锁(指数退避,30 次重试,5-100ms 间隔)。高水位标记防止 reset 后任务 ID 重复。三种执行后端可选:进程内(最快,共享内存)、tmux 面板(终端隔离,每个 Agent 有自己的标签页)、远程(完全机器隔离)。
这些不是什么 AI 黑科技。这就是正经的分布式系统工程——锁、协调、隔离、状态管理、访问控制、资源共享。以前是后端架构师的工作,现在变成了 Agent 开发者的必修课。
10 对我们意味着什么 :::
Rohit 这篇文章给我的最大冲击不是某个具体技巧,而是一个认知升级: 模型是商品,环境决定成败 。
同一个模型,更好的环境,64% 的性能提升。大部分行业在优化第一层:更大的模型、更高的基准分数。赢家在投资第三层和第四层。
1. Agent 循环用 async generator,不是 while。 流式输出、取消、可组合性、背压控制——全部内置于抽象本身。While 循环留了四个缺口。
2. 工具按并发行为分类。 只读并行、写入串行。定义时打标签,编排层自动处理分批。2-5 倍提速,零竞态条件。
3. 系统提示词按缓存边界设计。 静态内容在前,动态内容在后,边界显式标记。规模化运营时最高杠杆的成本优化。
4. 压缩用层级策略,不是单一方案。 便宜的先跑,贵的最后用。只在便宜策略全部失败时才花 token 做总结。
5. 第一天就设计第四层。 状态跨会话怎么存?权限怎么扩展到团队?加了并行之后协调怎么做?事后补基础设施比一开始就设计难十倍。
Claude Code 就是证据——一个 55 个目录、331 个模块的 TypeScript 应用,把同一个驱动聊天界面的 Claude 模型变成了一个能无人值守运行数小时、从 API 故障中自动恢复、在千轮会话中管理自身上下文、并协调多个并行子 Agent 在同一个代码库上工作的编程 Agent。
源码就在那里。模式已经被记录。决策清晰可读。
如果你正在搭自己的 Agent 系统,不要从”哪个模型好”开始想。从”我的循环会在第几轮崩”、”我的上下文窗口在第几百条消息时溢出”、”两个 Agent 同时写同一个文件怎么办”这些问题开始想。先搭外壳,再搭基础设施。这才是 Claude Code 真正教会我们的事。
◇ ◆ ◇
 夜雨聆风
夜雨聆风