 夜雨聆风
夜雨聆风





AI 时代,代码当量依然具备长期价值 | AI软件质量大家谈·DevInsight


“大模型编码这么快,我们还需要度量代码吗?”
这是当下很多技术管理者的困惑。随着大模型辅助编程的普及,代码生成效率迎来指数级提升,研发模式从传统人工编码快速迈向人机协同的新阶段。有人认为,AI 时代代码当量不再重要,传统研发度量已然失效,事实真的如此吗?
我们先来看看前智能体时代,代码当量为什么能超越“代码行数”成为企业度量软件开发的重要标尺:
与代码行相比,当量能更准确地度量代码复杂度规模;
当量能够与相关指标结合度量人效、质量等;
当量能够作为基础指标校准需求交付相关统计。
在 AI 原生软件开发时代,代码当量在上述维度的价值依然成立,并且更加彰显。
AI 原生时代新的挑战
AI 工具的普及让代码生产从 “慢工细作” 转向 “高速批量”,开发者借助大模型可以快速生成大量代码,研发周期显著缩短。但在 AI 大幅降低编码门槛、提升产出速度的同时,研发管理的多重挑战也被进一步放大。
前段时间,Claude Code 源码泄漏,51 万行代码全公开,大家惊讶地发现,这些由 AI 生成的代码质量并不高、甚至非常差。业界专家指出,AI 编程流行后,代码泄露、供应链攻击、乱七八糟的生产代码,会成为新常态。若缺乏科学统一的度量体系,整个研发过程将陷入 “看不清、算不准、管不住” 的困境。

(文末下载PDF,解锁代码当量新价值)
我们反复提过多次,度量不是为了束缚效率,恰恰相反,它是让 AI 带来的效率提升可复制、可放大、可持续的关键,也是推动 AI 研发从 “盲目堆砌代码” 向 “规范交付价值” 转型、实现规范化管理的核心抓手。
当然,有效度量的前提,是企业必须搭建可靠的度量底座,避免被片面数据误导。唯有如此,才能在充分释放 AI 效率红利的同时,牢牢把握研发主导权,让技术投入真正转化为可衡量的业务成果。
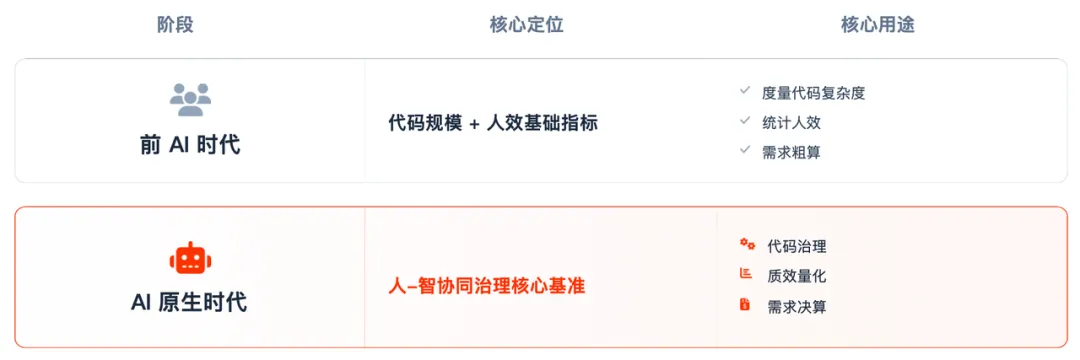
代码当量的定位变迁
在前智能体时代,代码当量主要作为传统研发的基础度量指标,用于统计代码复杂度规模、评估研发人效、把控交付质量、核算需求开发体量等功能,是衡量开发者工作量、优化研发流程的重要参考,核心围绕 “人工编码行为” 体现度量价值。
进入 AI 原生软件开发时代后,研发主体从单一人力转变为 “人 + AI” 协同模式,代码当量原有的度量价值不仅依然成立,而且更加关键。只是它不再局限于衡量 “人写了多少代码”,而是转变为适配人智协同场景的研发治理标尺,既能全面统计 AI 生成代码、人工修改代码等全量产出规模,又能突破传统代码行数统计的片面性,结合多维度指标客观反映真实的人 – 智协作的投入与产出,成为连接 AI 工具、研发人员与业务需求的核心量化纽带。
(文末下载PDF,解锁代码当量新价值)
代码当量之所以能在当下承担这一全新角色,源于其三大关键属性:
01
看清代码生产过程的“压舱石”
首先我们要问一个问题,是不是代码都靠 AI 产生之后,度量代码规模就变得不重要了呢?
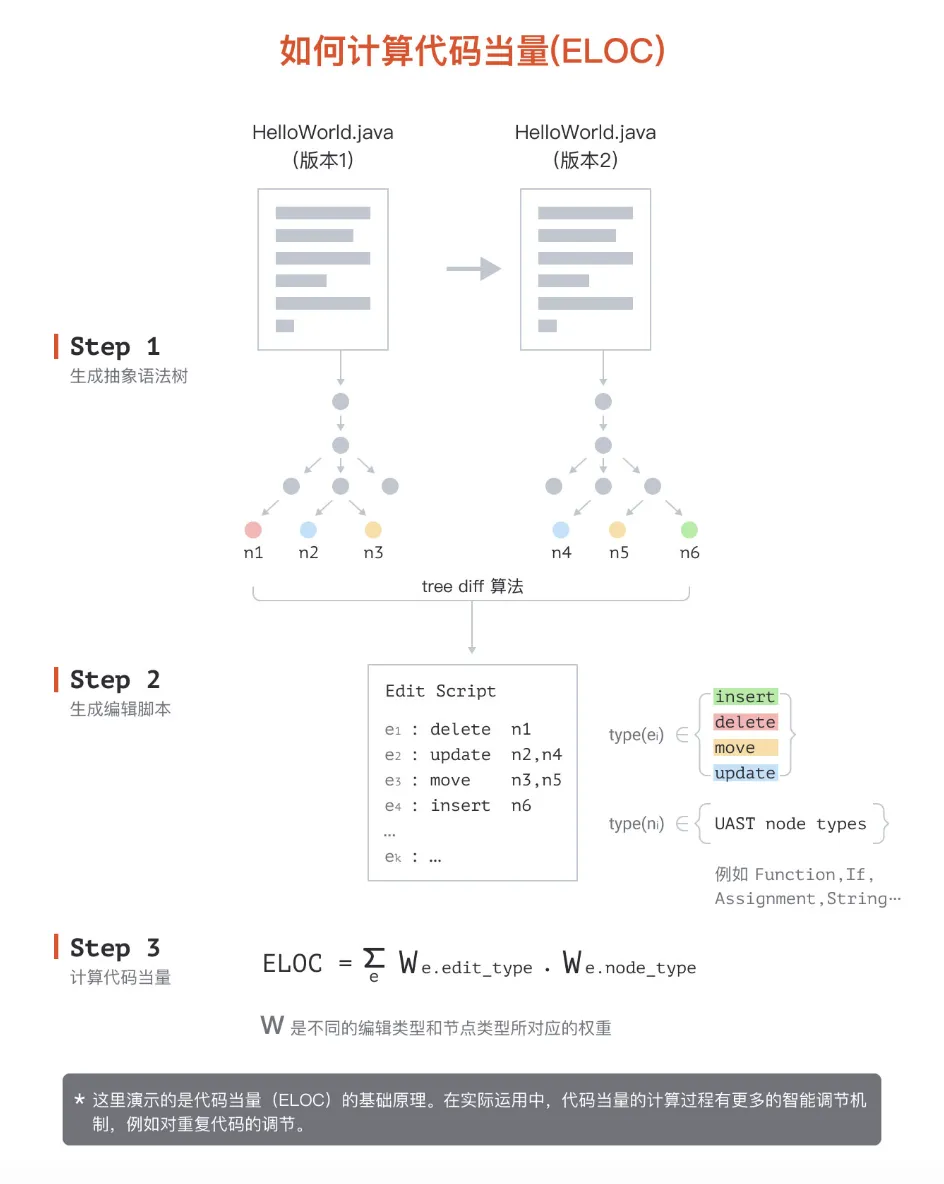
如果是“日抛”或者“月抛”的项目,的确无所谓;但如果是要投入运营的长期项目,则恰恰相反。我们面临的现状是 AI 的 “创造性” 可能导致代码的快速增删和重构,产生大量 “代码噪音”。
而代码当量能够对 AI 短时间内大幅度增删代码(code churn)的行为做额外处理,有效过滤噪音,计算出真实有效的变更规模,避免数据统计的失真。同时也可借助在提交上打标签的方式对 AI 生成/用户手写代码做区分,计算 AI 地真实贡献度(如采纳/入库率)。
(文末下载PDF,解锁代码当量新价值)
02
衡量人-智协同质效的 “计算器”
代码当量也是量化人 – 智协同质效的关键。它支撑三大核心数值:
代码词元比:代码当量 ÷ 投入 Token 量。这个比率可以直接量化 AI 的产出 ROI,帮助团队评估不同 AI 工具或策略的有效性。代码词元比越高,代表 ROI 更高、智能体更具自主性、人-智交流协作更高效,这些真金白银的投入就没有浪费。
规约代码比:需求规约项数 ÷ 代码当量。这个比率可以衡量需求的清晰度以及人 – 智协作的成熟度。
千当量缺陷 / 事故率:AI 可能生成大量冗余代码,让传统的 “千行 bug 率” 在 AI 时代更容易失真,而千当量缺陷 / 事故率剔除了这些干扰,能够更公平、更可信地实现跨版本、跨项目、跨人员的质量对比。
AI 转型过程中,规约代码比应逐步提高,但过高会让规约代码一致性保证面临挑战,项目维护成本增高。研发团队需同步监控规约代码比与千当量缺陷率变化趋势,避免出现效率提升但质量下行的失衡问题,研发团队可着眼项目自身情况,从时间等维度进行观察、对比和调整。
03
管理交付价值的 “决算单位”
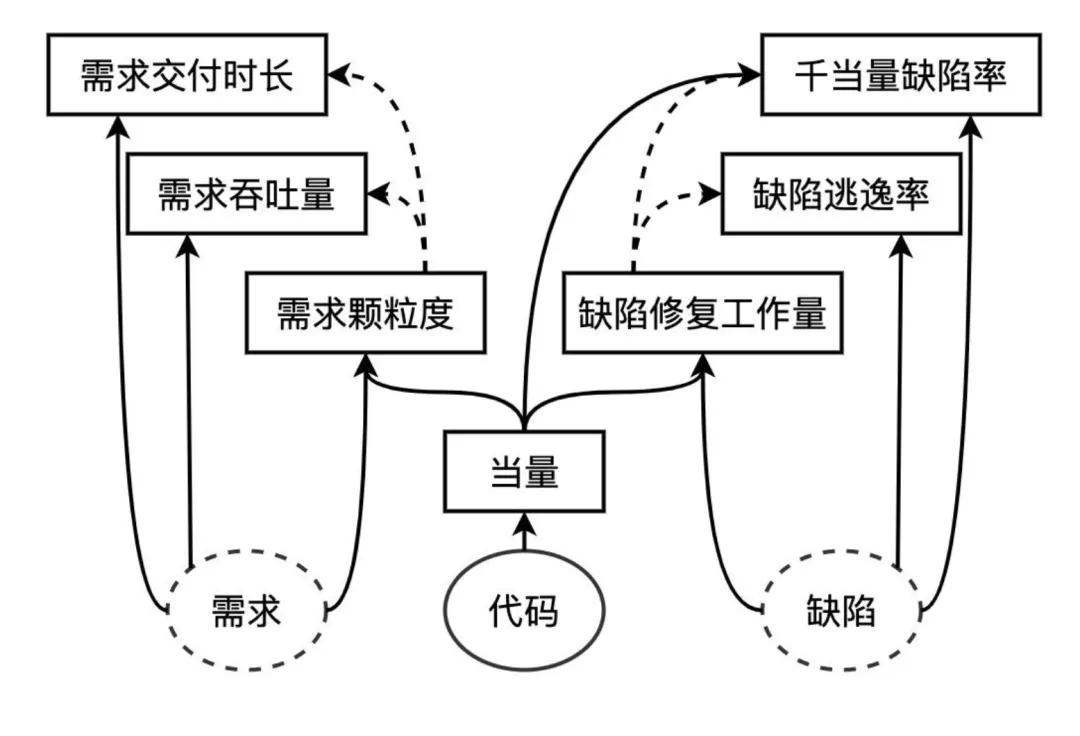
无论企业是否落地智能体、是否全面转型 AI 原生架构,软件工程的终极目标始终是以需求交付兑现业务价值。业务侧的核心诉求永远是提升排队需求的交付数量与效率,因此需求价值流的统计与管理,始终是研发效能运营中最核心的结果度量。
(文末下载PDF,解锁代码当量新价值)
基于此,代码当量作为事后决算式的度量依据,依然是现阶段最经济、最客观、最可靠的需求规模校准方式。在 AI 时代结合规约驱动开发实践,以「需求规约条目数 + 落地后代码当量」作为需求颗粒度 / 复杂度的核心评估指标,可在零额外人力投入、零额外 Token 消耗的前提下,实现高精度的需求度量。
当团队需通过需求吞吐率、交付周期等核心价值流指标管控交付价值时,需同步对需求颗粒度(规模 / 复杂度)进行动态校准与优化,为价值流指标的精准统计筑牢基础。具体校准策略分两大场景落地:
1、颗粒度校准(未规范化规约场景):在传统开发模式下,若需求未形成条目化规约,可将历史对标代码当量作为需求颗粒度的基础指标,与 AI 根据需求描述生成的智能评分融合计算,大幅提升颗粒度预估的可靠性与准确性。
2、复杂度校准(已条目化规约场景):若需求已按类 EARS/GEARS 模式完成条目化规范化(注:规约条目化梳理过程可由 AI 高效辅助完成),可直接以规约条目数作为需求颗粒度的核心指标;再结合需求落地后的实际代码当量,通过加权平均计算需求复杂度,进一步提升复杂度评估的精准度。
结语
AI 这团火,并没有浇灭业界对度量的关注,反倒是 AI 带来的不确定性再一次让从业者们意识到了度量的价值。代码越是指数级增长,管理者越是要看清过程、及时干预、控制风险。而代码当量,则以其全新的定位和价值,成为了新时代度量体系的 “核心底座”。
放弃度量,就等于放弃了对 AI 研发的可控性与可持续性。拥抱度量,特别是以代码当量为核心的新一代度量体系,是研发团队从 “能用 AI” 的初级阶段,迈向 “用好 AI、管好 AI” 成熟阶段的必经之路。
“
扫码下载PDF
玩转AI时代的代码当量
”

往期回顾 | AI软件质量大家谈·Devlnsight
【第一期】2026年领导者的AI决策矩阵:从“机长”到“空管”的权力跃迁