 夜雨聆风
夜雨聆风





Inworld AI 发布 Realtime TTS-2:能听懂你“语气”的闭环语音模型,让 聊天不再像朗读
网址:https://platform.inworld.ai/
哈喽,大家好,我是 01墨客。
在 AI 语音领域,一直隐藏着一个“公开的秘密”:大多数语音合成模型其实并不会“聊天”。
传统的 TTS(从文本到语音)逻辑非常简单粗暴:输入一段文字,吐出一段音频。这种模式更像是电台播音员在朗读,而不是两个人在对话。它不知道你刚才是在开玩笑还是在生气,更不知道你说话的语速快慢。
Inworld AI 最近发布的 Realtime TTS-2 研究预览版,正是要打破这种“单向朗读”的僵局。它不仅能合成声音,更重要的是,它能“听”懂你的语气。
今天,我们就来聊聊这个让 AI 具备“察言观色”能力的闭环语音模型。
一、核心突破:从“开环”到“闭环”的进化
TTS-2 与传统模型最大的区别在于其闭环架构(Closed-Loop System)。
以往的模型只接收转录后的文本。比如你无奈地回一句“行吧”,AI 看到的只是这两个字,它不知道你是释然、委屈还是讽刺。
而 TTS-2 会直接接收你上一轮对话的原始音频输入。它能听到你声音里的疲惫、愤怒或喜悦。这种“听觉反馈”让 AI 能够自动调整下一句的语气、语速和情感状态,实现真正的上下文连贯。
二、四大硬核能力:让 AI 像真人一样社交
Inworld AI 为 TTS-2 配备了四项关键武器,每一项都直指当前 AI 语音的痛点。
1. 语音引导(Voice Direction):用大白话调教语气
开发者不再需要去选什么“悲伤”或“兴奋”的标签,而是可以直接用自然语言给 AI 下指令。
-
• 操作方式:在文本中加入类似 [speak sadly, as if something bad just happened]的标签。 -
• 非语言互动:支持在文本中插入 [laugh]、[sigh]、[clear_throat]等指令,AI 会自然地笑出声或清嗓子,而不是把这些词念出来。
2. 对话感知(Conversational Awareness)
得益于闭环架构,情感和语气会自动在对话轮次间流动。你不需要额外写代码告诉 AI“刚才用户很生气”,它自己能听出来。
3. 跨语言一致性:一个音色走天下
TTS-2 支持超过 100 种语言。最厉害的是,它能在同一句话中自动切换语言,且保持音色、音调和角色性格完全一致。这对跨国业务和游戏 NPC 来说简直是神器。
4. 语音设计(Voice Design):凭空捏造声音
你不需要任何参考音频,只需要用文字描述一个人的声音特征(比如:一位略带沙哑、富有磁性的中年男性),TTS-2 就能生成一个全新的、可重复使用的音色。
三、细节控的胜利:那些“嗯、啊、这”的魔力
为了让声音更有“人味”,TTS-2 引入了**非流畅性(Disfluencies)**生成。
它会根据说话人的性格,自然地产生 uh、um、自我修正或中途停顿。这种“思考感”让对话显得温暖且真实,而不是像机器在执行任务。
此外,TTS-2 还支持快速克隆。只需一段 5-15 秒的高质量参考音频,就能瞬间复刻一个人的声音。
四、战力排位:登顶 Speech Arena 榜单
数据说话。根据 Artificial Analysis 的最新数据(截至 2026 年 5 月 5 日),Inworld 的 Realtime TTS 系列已经位居 Speech Arena 排行榜首位,力压谷歌和 ElevenLabs。
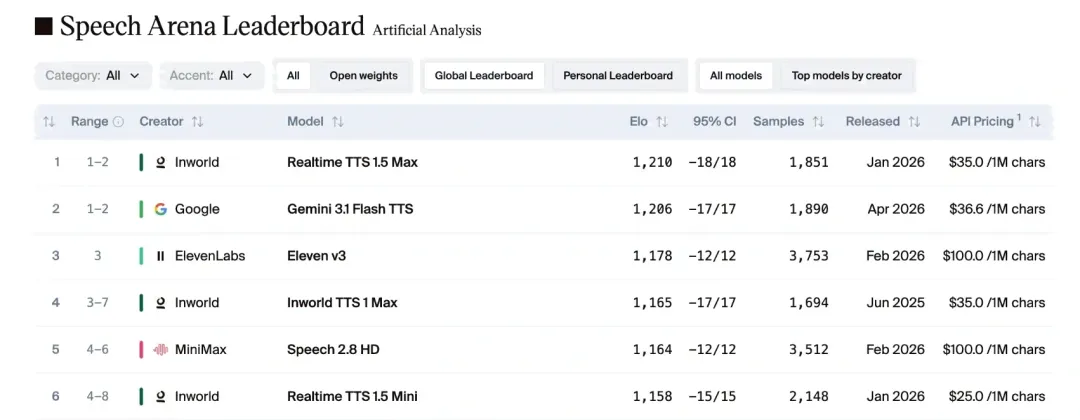
|
|
|
|
| #1 | Inworld AI | 闭环架构、情绪感知、极致低延迟 |
|
|
|
|
|
|
|
|
以下是 Inworld AI 官方提供的 Realtime TTS-2 与同类产品的详细对比:
|
|
|
|
|
| 核心技术 |
|
|
|
| 情感感知 |
|
|
|
| 语音引导 |
|
|
|
| 跨语言一致性 |
|
|
|
| 语音设计 |
|
|
|
| 非流畅性 |
uh, um, 自我修正 |
|
|
| 延迟 |
|
|
|
| 适用场景 |
|
|
|
五、开发者视角:极速响应与闭环生态
TTS-2 并不是孤立存在的,它是 Inworld 实时 API 管线的一部分:
-
• 低延迟:通过 WebSocket 长连接,首包音频返回时间(TTFB)中位数低于 200ms。 -
• 全链路:配合 Realtime STT(识别用户年龄、口音、情感)和 Realtime Router,构建了一个完整的“感知-决策-表达”闭环。
六、总结
Inworld AI TTS-2 的出现,标志着 AI 语音正在从“朗读时代”跨入“社交时代”。
当 AI 不再只是机械地复述文字,而是能听懂你的叹息、感知你的犹豫时,人机交互的温度就真的上来了。对于游戏开发者、虚拟主播和智能客服行业来说,这无疑是一次巨大的生产力跨越。
没有永远的王者,只有在特定赛道上跑得最快的选手。 在追求“人味”这条路上,Inworld 显然已经跑在了最前面。
你觉得 AI 语音具备“情绪感知”后,最实用的场景是什么?是安慰失眠的深夜电台,还是不再让人想挂断的智能客服?欢迎在评论区留言分享!
参考资料
[1] MarkTechPost. Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to How You Actually Talk. 2026-05-05. https://www.marktechpost.com/2026/05/05/inworld-ai-launches-realtime-tts-2-a-closed-loop-voice-model-that-adapts-to-how-you-actually-talk/