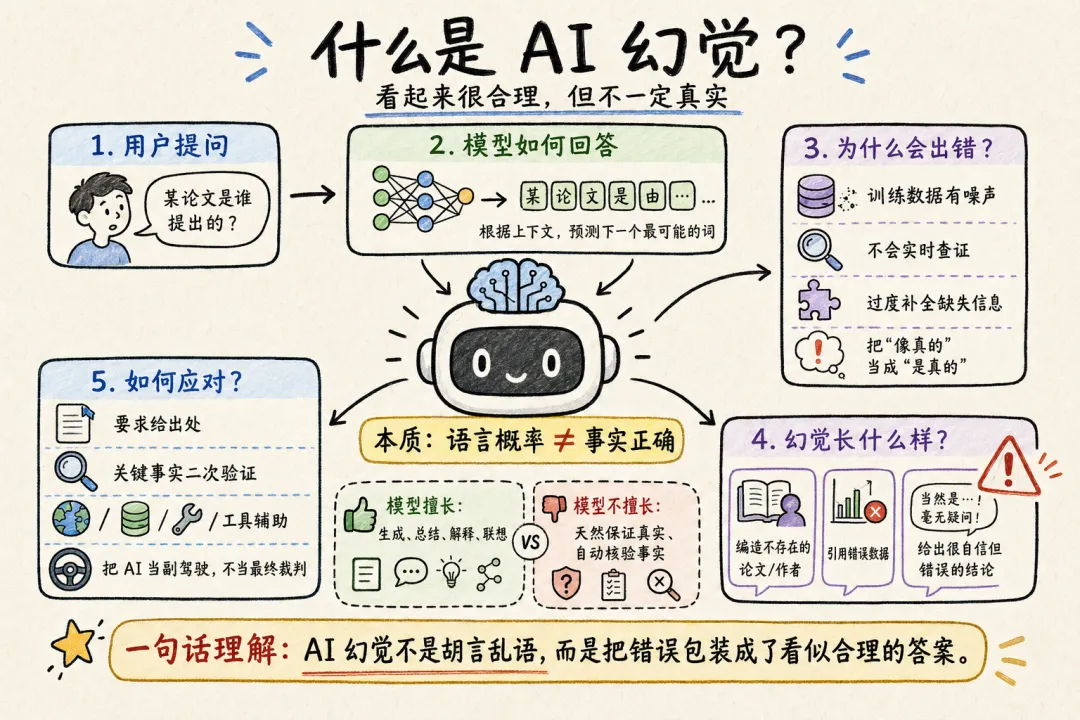
大模型最迷人的地方,是它什么都能说。你问它历史,它能讲;你问它代码,它能写;你问它商业,它能分析;你让它写文章、做总结、改方案,它几乎都能给出一套看起来完整、顺滑、专业的答案。但大模型最危险的地方,也恰恰是它什么都敢说。它可能编一个不存在的论文,引用一个不存在的作者,给出一个看似合理但实际错误的结论,甚至在你追问时,还会继续用非常坚定的语气补充细节。这就是我们常说的:AI 幻觉。很多人以为幻觉是大模型偶尔出 bug。但更准确地说,幻觉不是偶发现象,而是大模型训练机制里天然埋下的问题。要理解 AI 为什么会一本正经地胡说八道,就要先理解一件事:大模型不是数据库,它的底层任务也不是“查事实”,而是“预测下一个 token”。
一、大模型不是在查答案,而是在续写答案
人类使用 AI 时,很容易把它想象成一个超级搜索引擎。你问一个问题,它给你一个回答。于是你会自然认为:它一定是在某个地方查到了答案,然后整理出来告诉你。但大模型不是这样工作的。大模型的训练目标,本质上很简单:根据前面的文本,预测后面最可能出现的 token。所谓 token,可以粗略理解成模型眼中的语言单位。它可能是一个字、一个词,也可能是一个词的一部分。比如你输入:
很多人以为 AI 幻觉来自模型能力不足。这当然有一部分原因。模型能力越弱,越容易犯低级错误。但更深一层看,幻觉也和大模型的强项有关:它太擅长补全。你给它一个问题,它会尽力补出一个完整答案。你给它一个不完整信息,它会自动推断缺失部分。你给它一个模糊需求,它会根据常见模式生成一个看似合理的结构。在很多场景里,这种补全能力非常有用。写文章、改文案、生成代码、梳理方案,都需要模型根据上下文进行延展。但在事实型问题上,这种能力就可能变成风险。比如你让它总结一篇不存在的论文,它可能不会直接拒绝,而是根据论文标题的关键词,编出一个摘要。你让它列举某个领域的专家观点,它可能会生成几个听起来像真的名字。你让它解释某个不存在的概念,它可能会按照相似概念的结构,写出一套完整解释。为什么?因为从模型角度看,它不是在判断“这个东西是否存在”。它是在判断“如果有人这样提问,后面最可能出现什么样的回答”。这就是幻觉的本质:模型把语言上的合理性,误当成了现实中的真实性。
对普通用户来说,理解 AI 幻觉不是为了害怕 AI,而是为了更聪明地使用 AI。最重要的原则只有一句话:不要把 AI 当成答案机器,而要把它当成思路助手。AI 很擅长帮你打开思路、搭建结构、归纳信息、生成初稿、解释概念、提出可能性。但只要涉及事实、数据、来源、法律、医疗、金融、投资、代码安全,就不能只看它说得是否流畅,而要看它能不能被验证。第一,遇到事实型问题,要让 AI 给出处。不要只问:“这个结论对吗?”更好的问法是:
这个结论依据是什么?请列出可核验来源。哪些是事实,哪些是推测?这个数据来自哪里?有没有可能过时?
一旦 AI 给不出明确来源,或者来源模糊,就要把它当成“待验证信息”,不能直接使用。第二,遇到重要决策,要让 AI 拆分不确定性。比如你问 AI 一个投资判断、商业判断、职业选择,不要只让它给结论,而要让它列出:
这一步非常关键。AI 第一次回答时,往往倾向于顺着问题往下生成;反向追问,可以让它从“生成模式”切换到“审查模式”。第五,不要让 AI 单独承担最后判断AI 可以帮你整理材料、生成方案、比较利弊、模拟推演,但最后涉及真实行动,尤其是花钱、签约、用药、发代码、做投资,都必须经过人类复核。更成熟的用法是:让 AI 负责提高思考效率,让证据负责保证事实可靠,让人负责最终决策。这才是普通用户应对 AI 幻觉的最佳实践。不是不用 AI,也不是盲信 AI,而是把 AI 放在正确的位置上:它是一个很强的副驾驶,但方向盘不能完全交给它。
 夜雨聆风
夜雨聆风