 夜雨聆风
夜雨聆风





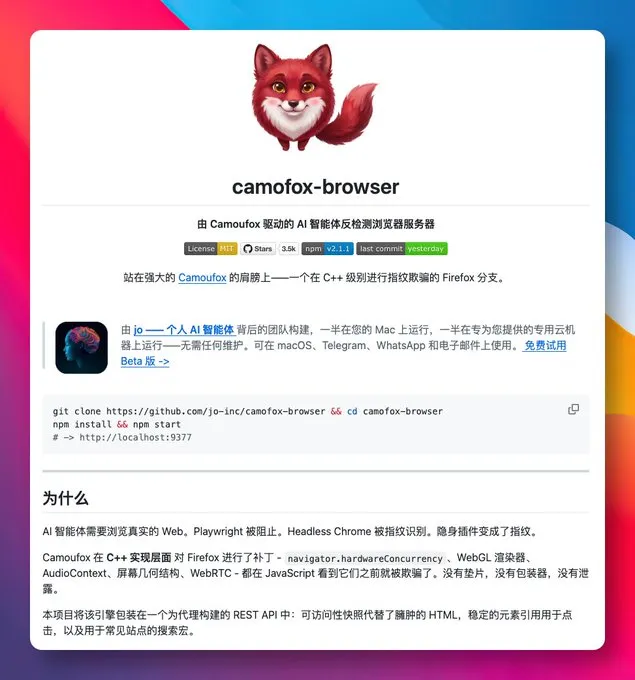
camofox-browser:AI Agent 卡在网页门口时,可以换个底座了
我刚看到 camofox-browser 时,先停在一句话上。
“Stealth plugins become the fingerprint.”
这句话有点扎心。
很多人做网页 Agent,前面流程都搭好了:规划任务、打开页面、点击、输入、抓结果。结果一到真实网站,浏览器刚露头,就被拦在门口。
换 UA,补 navigator,塞 stealth 插件。
补来补去,插件自己也成了特征。
camofox-browser 这次绕开的不是某一个检测点,而是把问题往下压了一层。
它基于 Camoufox。后者是一个 Firefox fork,把一批浏览器指纹相关东西放到 C++ 实现层处理,比如硬件并发数、WebGL、AudioContext、屏幕几何、WebRTC 等,尽量在 JavaScript 看到之前就完成伪装。camofox-browser 再把这个浏览器包装成一套给 Agent 用的 REST API。
我更在意的不是“反检测”这几个字。
真正影响 Agent 使用体感的,是它没有把整页 HTML 直接丢给模型。
它返回的是无障碍快照,里面带稳定的元素引用,比如 e1、e2、e3。Agent 不用在一大坨 DOM 里猜按钮在哪,而是拿着这些 ref 去点、输入、滚动。仓库里说,这种 snapshot 比原始 HTML 小约 90%。
这对做过网页自动化的人很熟。
问题常常不是“模型不会操作网页”,而是网页给它的信息太吵。
导航栏、广告位、脚本生成的节点、隐藏元素,全塞进上下文后,模型开始犯一些很笨的错。camofox-browser 的思路是先把页面压成 Agent 更容易读的形态,再让它操作。
它还内置了一组搜索宏。
Google、YouTube、Amazon、Reddit、Wikipedia、LinkedIn、Instagram、TikTok 等站点都列在里面。Reddit 相关宏甚至可以直接返回 JSON,不一定要再走 HTML 解析那套流程。([GitHub][1])
这类小东西看着不大,但放进 Agent 工作流里,会少很多胶水代码。
比如让 Agent 搜一个商品、看几条 Reddit 讨论、再打开 YouTube 找视频资料。过去你要给它写一堆页面适配逻辑。现在至少常见入口可以先宏化,后面再交给浏览器继续点。
登录态这块也做了。
camofox-browser 支持导入 Netscape 格式的 Cookie 文件,用来恢复已认证会话;默认也会把每个用户的 cookie 和 localStorage 持久化到独立 profile 里。Cookie 导入默认关闭,需要配置 API key 才能启用。
这点比较适合多用户 Agent 服务。
同一个底层浏览器引擎跑着,但不同用户的会话、存储、上下文隔开。代理和 GeoIP 也能配,时区、locale、地理位置会跟代理 IP 走。
还有一个很现实的数字:空闲时内存大约 40MB。
仓库里写它用了 lazy browser launch 和 idle shutdown,目标是能放在树莓派、5 美元 VPS 或共享基础设施上跑。
所以我觉得它不是一个“让爬虫更猛”的玩具。
更准确一点,它是在给网页 Agent 补底盘。
前提当然是用在你有权限访问、也符合站点规则的场景里。内部运营后台、个人知识工作流、授权账号下的信息整理、自动化测试,这些地方才是它最顺手的位置。
GitHub地址:jo-inc/camofox-browser。