 夜雨聆风
夜雨聆风





企业AI何时迎来OpenClaw时刻
To read the article in English, click on Read more.
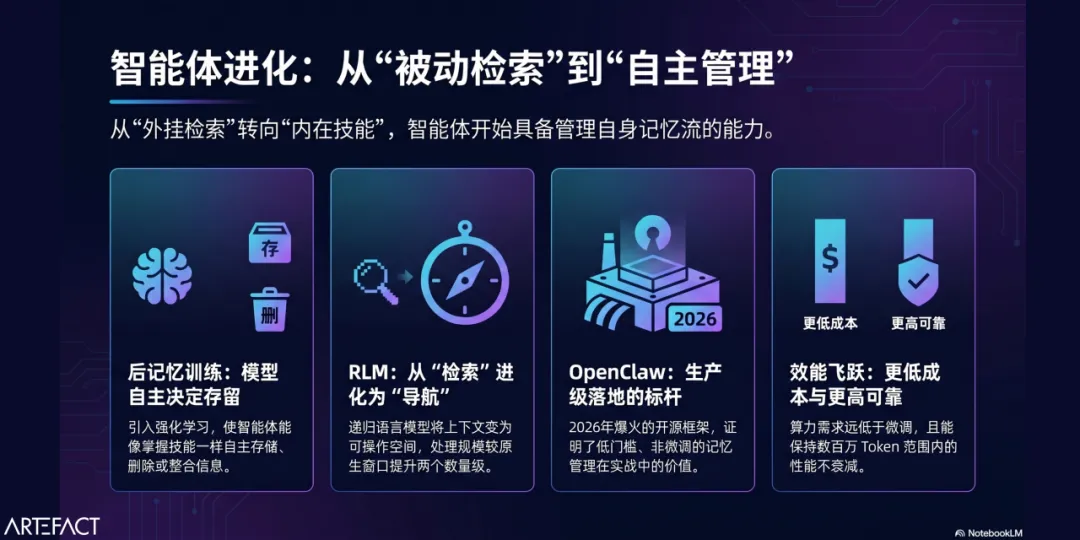
在上一篇文章中,我们梳理了一些研究团队的共识:与其在模型外部搭建记忆系统,不如直接训练模型本身去管理记忆。通过在后训练阶段引入强化学习(后记忆训练),智能体像掌握一项技能一样,能够自主决定何时存储、删除或整合信息,并以任务完成度为优化目标。
除此之外,另有两项关键进展同样为自主智能体的规模化落地指明了方向:递归语言模型(Recursive Language Models,RLM), 它将上下文管理从“检索”问题重新定义为“导航”问题;而以OpenClaw为代表的生产级系统,开始在真实环境中验证这些理念的可行性。
从检索到导航:RLM重新定义上下文管理
在传统的RAG架构中,知识库更像一个被动查询系统:文本被切分、向量化,通过相似度计算选出top-k结果,再拼接进prompt。模型只是被动接收检索系统认为相关的信息,并不参与筛选。
由Alex Zhang、Tim Kraska和Omar Khattab提出的递归语言模型(RLM)改变了这一点。RLM将上下文从检索结果转变为可操作空间,模型不再只是接收信息,而是可以像开发者浏览代码库一样使用上下文:主动查找、筛选、拆分,并在需要时发起子查询、并行处理不同信息片段,再汇总结果。
这一区别看似细微,但直接决定了系统在复杂任务中的表现上限。数据也印证了这一点:RLM能够处理超出模型原生上下文窗口两个数量级的输入规模而不出现性能衰减;在超过150万字符的真实数据集上,其表现显著优于标准LLM和常见的长上下文方案。经过后训练优化的版本RLM-Qwen3-8B,在多个长上下文任务中比基础模型平均提升28.3%,并在部分任务上接近GPT-5的表现。
从能力结构上看,后记忆训练与RLM并不是替代关系,它们解决的是两个不同的问题。前者关注智能体内部的状态管理:什么该记住,什么该遗忘;后者教其探索尚未纳入记忆的外部信息。当两者结合,智能体便具备了长周期自主运行所需的两个关键条件:既能在大范围信息中快速定位,又能长期保持精简而稳定的内部状态。
OpenClaw(小龙虾)时刻:从理念进入生产
OpenClaw,这个在2026年1月发布后一周内即获得超过10万GitHub星标的开源智能体框架,是目前最具代表性的落地样本,它证明了上述融合架构的实战价值。
OpenClaw的记忆系统采用了带时间戳和元数据的结构化Markdown文件,以纯文本形式存储,没有专有数据库,没有加密黑箱。通过语义搜索,智能体即便在用户表达模糊时也能找回历史信息,并在不同工具(如代码编辑器或浏览器)之间实现记忆流动。
它的核心贡献在于降低了门槛:智能体可以自主编写代码扩展能力,并在运行中构建长期记忆,全过程无需微调。记忆管理发生在应用层,而非模型层,任何团队都可以直接部署和定制。它的2026.2.3版本专门修复了工具调用一致性、会话隔离等生产环境中的真实痛点,这些正是后记忆训练研究中所确定的典型故障模式。
对企业的意义:规模化逻辑正在改变
这些进展正在改变企业部署智能体的商业逻辑:
1. 成本维度
后记忆训练的算力需求远低于微调:AgeMem可在单个8×A100节点上完成训练,Memory-R1仅需152个样本。MemAct带来的51%上下文压缩和MEM1的恒定记忆开销,直接降低了大规模推理的成本。对于高频交互的企业而言,这让许多原本“太贵”的场景变得经济可行。
2. 技术门槛
微调依赖具备分布式训练、奖励设计等能力的机器学习工程师。而后记忆训练与RLM,更偏向应用层。OpenClaw甚至依赖Markdown和配置文件就能操作。技术门槛已从“能否训练模型”转变为“能否设计工作流”,企业可以依靠更广泛的工程人才池。
3. 长效可靠性
这是核心突破点。当前约60%的多智能体项目无法规模化,主要原因不是成本,而是性能衰减。对于重要的工作流程,如多步骤研究、复杂客服、代码迁移和事故响应,那些无法在50轮对话以上保持状态一致性的智能体,不具备任何商业价值。
后记忆训练方面,MEM1在16个目标任务上保持近乎恒定的性能,MemAgent在350万token范围内维持准确率;RLM在超出原生上下文窗口两个数量级的输入下不出现性能衰减。这使得“多小时级别”的自动化流程具备现实可行性。
企业技术栈中需要关注的三点
一、把记忆视为可训练的技能:当前主流的启发式记忆系统(如 Mem0、Zep、 LangChain memory)虽有价值,但在复杂任务中,学习型策略将逐步超越规则设计。
二、用RLM式导航补充RAG:单一RAG架构在深度分析任务中存在瓶颈,RLM式的上下文探索能力,将成为下一阶段的关键能力。
三、优先考虑应用层优化,而非模型层定制:像OpenClaw那样通过应用层设计和运行时学习来实现记忆管理,是更灵活、低成本的路径。
局限与挑战
当然,挑战依然存在。
首先是训练数据。基于强化学习的记忆训练,需要智能体在大量场景中反复“练习”,而当前大多数方法仍依赖合成任务或简化环境,其在真实业务中的泛化能力仍有待验证。
其次是奖励设计。实践表明,不合理的奖励机制很容易让模型“钻规则漏洞”,而不是解决问题,这使得相关方法仍难做到即插即用。
此外,RLM有延迟代价。由于需要并行调用子模型,其整体延迟较高,更适用于深度分析场景。在实时客服等场景中,传统RAG仍然更具优势。
更长期的问题则包括:多模态记忆尚未成熟,以及持久记忆带来的安全与隐私风险。这些问题目前尚未有成熟解法。
未来走向
我们正处于智能体进化的新阶段。后记忆训练教智能体“记住什么”,RLM训练它“如何去查”,而OpenClaw证明了这些能力可以不依赖微调和重算力实现。
我们判断,接下来的智能体发展将分为三个阶段:
阶段一(当前):RAG + 启发式记忆为主流,且行之有效;
阶段二(2026–2027):基于强化学习训练的记忆模块以插件组件出现,RLM式导航成为标准智能体能力;
阶段三(2027年以后):记忆训练与上下文导航融入标准的后训练体系,与指令微调和推理强化学习并列。
强化学习驱动的记忆管理究竟是最终答案,还是更大拼图中的一块,目前仍是开放问题。明年也许会出现截然不同的方向。
对于正在构建智能体系统的团队,更现实的建议是:将记忆层设计为模块化、可替换的能力,并赋予智能体主动探索上下文的机制,而非仅依赖被动检索。今天部署的启发式系统,很可能只是过渡形态。不要把记忆逻辑硬编码在管道中,只有保持架构的灵活性,才能在技术迭代时实现低成本升级。
系列阅读

作为全球领先的咨询公司,Artefact(阿蒂法)致力于加速数据与AI应用,为个人和组织铸就积极变革。我们深耕数据与AI转型及数据营销,助力企业实现全价值链切实商业成果。
Artefact is a leading global consulting firm dedicated to accelerating the adoption of data and AI to positively impact people and organizations. We specialize in data & AI transformation and AI/data-driven marketing to drive tangible business results across the entire enterprise value chain.

Website


Artefact


Artefact Asia
