 夜雨聆风
夜雨聆风





超越 OpenClaw, 越用越强的 Agent:15万Star,Hermes Agent 架构拆解
你用过的每一个 AI Agent 都有同一个问题:会话结束,一切归零。
你的编码习惯、你纠正过三次的项目规范、它昨天花 10 分钟才摸索出来的解法——全部丢失。下次对话,从头再来。
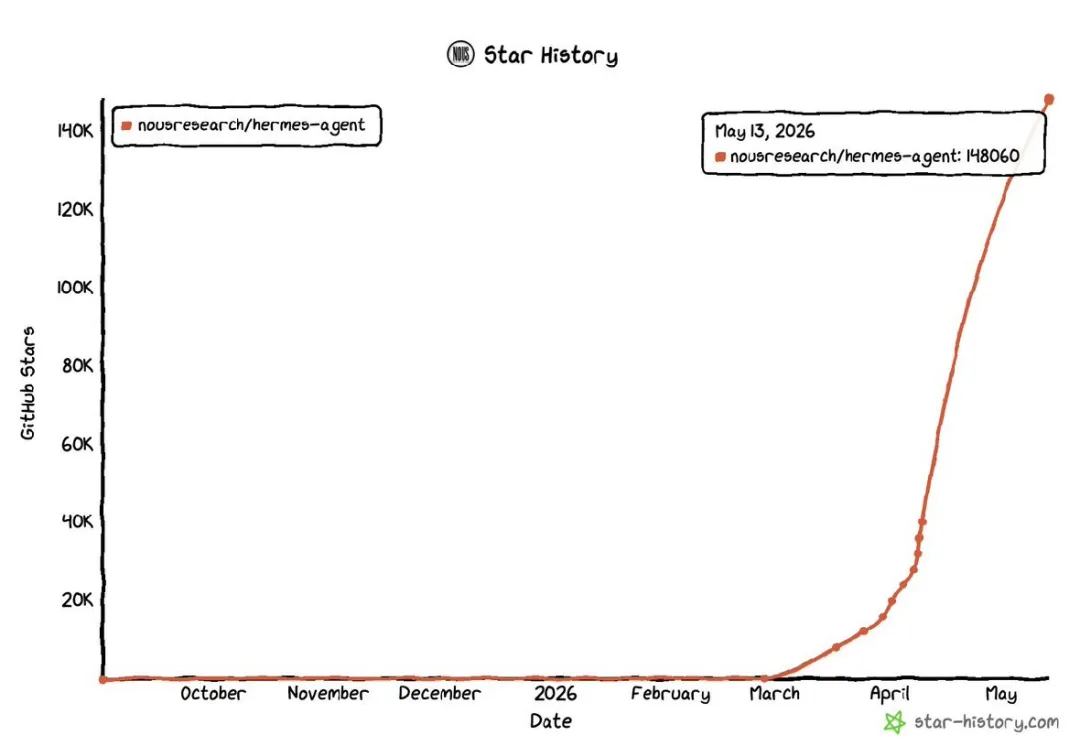
Hermes Agent(Nous Research 开源)走了一条完全不同的路。两个月,GitHub Star 突破 90,000,今天 152k star:
它内置了一套学习闭环:
-
• 跨会话记忆——三层分级,关键事实永远在场 -
• 自生成 Skills——Agent 自己把成功路径写成可复用流程 -
• Curator 修剪——后台自动清理过时技能,防止垃圾堆积 -
• GEPA 离线优化——用进化算法打磨 Skills 和 Prompt,不碰模型权重
没有其他开源 Agent 同时做到这三件事。
这篇拆它的设计思想。如果你在自研 Agent 框架,或者想理解”会成长的 Agent”到底怎么做,往下看。
它和 Claude Code、OpenClaw 有什么不同?
为了快速理解 Hermes 的定位,我用三个你可能已经熟悉的工具做对比:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果再把 OpenClaw 和 Hermes 拉出来做更细粒度的对比,差异会更明显:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
• Claude Code 是最强的编程 Agent,但它不记得你,也不会自己变强。 -
• OpenClaw 是最灵活的个人 AI 助手入口,但它的 Skills 靠社区贡献,不是 Agent 自己沉淀的。 -
• Hermes 不是最好用的产品,但它在架构层面回答了一个更底层的问题:Agent 怎么从”一次性工具调用器”进化成”长期协作伙伴”?
如果你的目标是”用一个好用的 AI 助手”,Claude Code 和 OpenClaw 已经很好了。
如果你的目标是”自研一个 Agent 底层框架”,Hermes 的设计思想更值得拆。
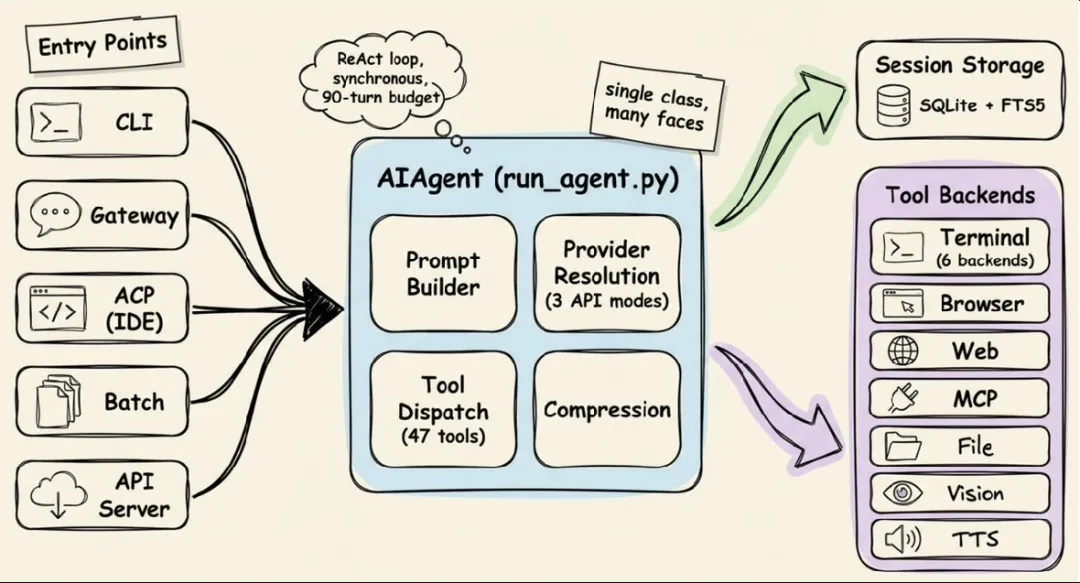
Hermes 最值得学的 5 个设计
设计一:Agent Core 平台无关
很多自研 Agent 一开始会写成这样:
CLI Agent 一套逻辑Web Agent 一套逻辑微信 Bot 一套逻辑飞书 Bot 一套逻辑三个月后代码库变成 if-else 地狱,修一个 bug 要改四个地方。
Hermes 的做法是:入口可以很多,但 Agent Core 只有一个。
CLI / TUI / Gateway / ACP / Batch / API ↓ AIAgent(唯一内核) ↓Prompt Builder / Provider Router / Tool Dispatcher ↓SQLite / Memory / Skills / Tools / MCP / Cron官方架构文档里有一句话值得抄到你的设计文档里:
One AIAgent class serves CLI, gateway, ACP, batch, and API server. Platform differences live in the entry point, not the agent.
我的判断:这是自研框架第一天就该定下的原则。我见过太多项目因为”先做个微信 bot 再说”,最后被入口层绑架了整个架构。先写一个干净的 Agent Core,再接入口,永远不会错。
设计二:Prompt 不是字符串,是可组合资产
Hermes 的系统 Prompt 不是一大坨写死的文本,而是由多种上下文资产拼出来:
SOUL.md(它是谁)+ MEMORY.md(它知道什么)+ USER.md(它了解你什么)+ Skills index(它会什么)+ Context files+ Tool guidance+ Model-specific instructions其中 SOUL.md 定义 Agent 的身份——语气、边界、禁区。这比”你是一个 XX 专家”高级得多。
原文有一句话很精辟:SOUL.md 是固定框架,记忆和技能是框架内的移动部件。 身份不变,能力在长。这才是多 Agent 人格隔离的正确基础。
我的判断:Claude Code 的 CLAUDE.md 其实是这个方向的简化版——一个静态的项目级 Prompt 资产。但 Hermes 把它拆成了身份层、记忆层、技能层三个独立维度,每个维度可以独立演化。如果你要做多个 Agent(程序员、研究员、运营),这种分层比”换一句系统提示词”强太多。
设计三:记忆分层,不要把一切都塞进 Prompt
很多 Agent 做记忆时会犯一个错误:把所有历史都塞进上下文。结果就是贵、慢、乱,还容易污染当前任务。
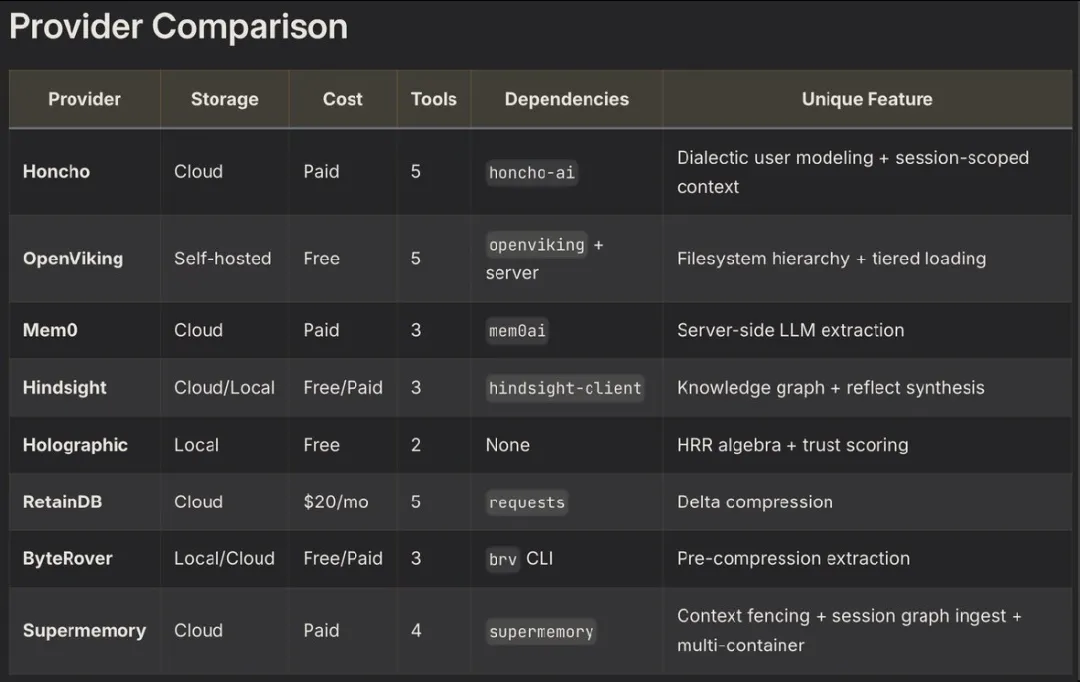
Hermes 的记忆是分层的:
|
|
|
|
|---|---|---|
|
|
MEMORY.md
USER.md(≤2200 字符) |
|
|
|
|
|
|
|
|
|
核心原则:
关键事实永远在场,普通历史按需搜索,深层记忆交给外部插件。
我的判断:这个设计很克制,也很正确。我之前试过”无限记忆”方案(把所有对话存向量库,每次 RAG 召回),效果很差——召回的内容经常和当前任务无关,反而干扰模型判断。Hermes 的”少量关键事实 + 按需搜索”是更务实的路线。
设计四:Skills 是 Agent 的”肌肉记忆”
这是 Hermes 最有特色的部分。
Memory 记的是事实,Skills 记的是流程。
比如:怎么给 Python 项目做测试、怎么写 GitHub PR、怎么调研一个开源项目、怎么发布 Docker 服务。
这些东西如果每次都让 Agent 重新摸索,就很浪费。Hermes 把它们沉淀成结构化的 Skill:
skill-name/├── SKILL.md # 流程描述├── references/ # 参考资料├── templates/ # 模板├── scripts/ # 脚本└── assets/ # 素材更关键的是:Agent 可以自己创建和修改 Skill。
典型触发场景:
-
• 完成了一个复杂任务 -
• 中途踩坑后找到了正确路径 -
• 用户纠正了它的做法 -
• 发现了一个非平凡工作流
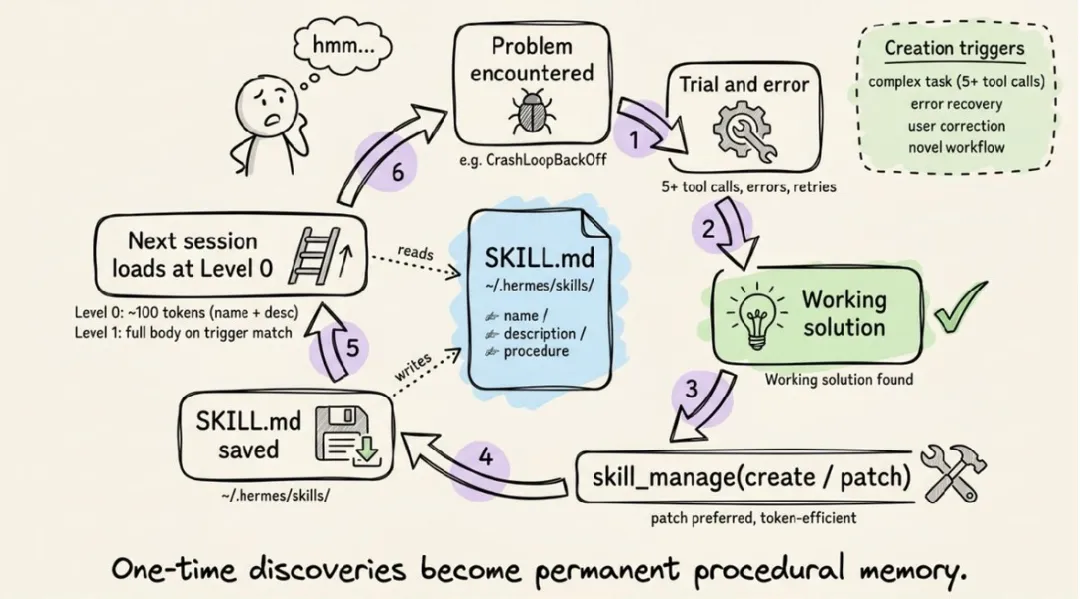
闭环是这样的:
遇到问题 → 尝试解决 → 找到成功路径 → 写成 Skill → 下次复用我的判断:这是 Hermes 和其他所有 Agent 框架拉开差距的地方。Claude Code 每次都在重新摸索你的项目规范;OpenClaw 的 Skills 靠社区写好给你用。只有 Hermes 让 Agent 自己从实践中沉淀能力。这才像一个真正会成长的系统。
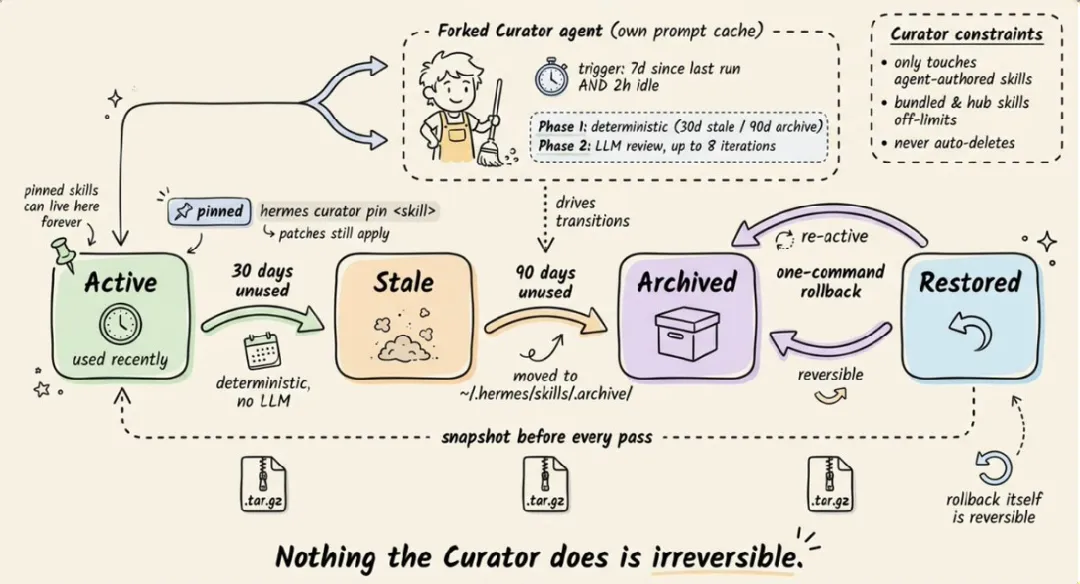
当然,自生成 Skills 会越来越多,所以 Hermes 还配了 Curator——一个后台垃圾回收机制。核心规则:
-
• 30 天未使用 → 标记为 stale -
• 90 天未使用 → 自动归档到 .archive/ -
• 永不自动删除,最坏情况只是归档,一条命令可恢复 -
• 每次 Curator 运行前,自动对整个 skills 目录做 tar.gz 快照 -
• 关键 Skill 可以 hermes curator pin锁定,防止被归档
否则”会学习”很快变成”会堆垃圾”。Curator 让自演化有了安全网。
设计五:Gateway 让 Agent 真正 24/7 在线
如果一个 Agent 只能在终端里用,它更像开发工具。
如果它能在 Telegram、Discord、Slack、API 里常驻,还能定时执行任务、主动推送结果,它才开始像”个人 AI 操作系统”。
Hermes Gateway 做了这些事:
-
• 接收不同平台消息 -
• 鉴权和 allowlist -
• 路由到对应 session -
• 调用 AIAgent -
• 把结果发回平台 -
• 运行 Cron scheduler(定时任务) -
• 处理后台任务 -
• 主动推送进度
我的判断:Gateway + Cron 是让 Agent 从”等你提问”变成”到点主动工作”的关键。我个人最想要的场景是:每天早上 Agent 自动帮我看 GitHub notifications、总结 PR review 状态、推送到 Telegram。这在 Claude Code 里做不到,但在 Hermes 架构里是原生支持的。
额外加分项:GEPA——不训练模型,优化”操作手册”
Hermes 还有一个 companion repo 做离线优化。
为什么需要它?因为 Agent 的运行时学习闭环有一个已知弱点:Agent 倾向于”自我表扬”——它几乎总是觉得自己做得不错,即使实际翻车了。让它自己评估自己,不靠谱。
GEPA 的思路是:不问 Agent “你做得好不好”,而是读取执行轨迹,从外部分析失败原因,再用进化搜索生成更好的版本。不微调模型权重,只打磨 Agent 的”操作手册”(Skill / Prompt / 工具描述)。

流程:读取执行轨迹 → 分析失败原因 → 生成候选版本 → LLM-as-judge 评估 → 最优版本提交。
我的判断:对个人开发者来说,这个方向比微调模型现实得多——不用 GPU、不碰权重,先把 Agent 的操作手册打磨好。这也是为什么我觉得 Skills 设计是 Hermes 最核心的资产:它不仅是运行时能力,还是可被离线优化的对象。
如果你要自研 Agent 框架,按什么优先级抄?
我的建议排序:
第一,抄分层架构。 入口可以变,核心不能乱。
Entry Points → Agent Core → Provider Router → Tool Registry → Memory / Skills / Session Store → Sandbox / Gateway / Cron第二,抄工具注册表。 每个工具要有 name、schema、handler、risk_level、timeout、approval_policy。不要把工具写成散落各处的函数。
第三,抄记忆分层。 少量关键事实永远注入,历史会话按需搜索,深层语义记忆插件化。
第四,抄 Skills。 Agent 真正的成长不是”记住你喜欢喝咖啡”,而是”记住遇到这类任务该按什么流程做”。
第五,抄 Gateway + Cron。 Agent 要从聊天工具变成工作伙伴,必须能常驻、接消息、定时执行、主动推送。
一个适合自研的最小架构蓝图
如果我从零做一个 Agent 底层框架,第一版只需要跑通:
一个 Agent Core + 一个 Provider + 一个 Tool Registry + 一个 Session Store + 一个 Memory Store + 一个 Skill Loader + 一个 CLI然后再叠加 Gateway、Cron、Profiles、MCP。
完整骨架参考:
agent-framework/├── core/ # agent_loop, prompt_builder, provider_router, tool_dispatcher├── tools/ # registry, terminal, file, web, browser, mcp├── memory/ # memory_store, session_search, providers/├── skills/ # loader, manager, auditor, curator├── gateway/ # router, auth, platforms/, delivery├── cron/├── profiles/├── storage/└── cli/最大的风险:能力越强,安全边界越要提前做
一个能读写文件、跑命令、联网、长期在线、接消息平台、自我修改 Skills 的 Agent,风险也是成比例的。
自研框架必须一开始就设计:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.env
|
|
|
|
最后
Hermes Agent 给我最大的启发不是”这个工具我能不能日常用”,而是:
一个真正可持续的 Agent 框架,必须把执行、记忆、技能、入口、安全、评估都设计成系统。
如果只做 tool call,它只是一个会调用函数的聊天机器人。
加上长期记忆,它开始认识你。
加上 Skills,它开始记住做事方法。
加上 Gateway,它开始常驻工作。
加上 Curator 和 GEPA,它开始有机会持续变强。
这才是自研 Agent 底层框架应该瞄准的方向。
下一篇我会写 Hermes Agent 的完整实操:macOS 安装、模型配置、接 Telegram、玩转 Skills 和 Profiles。先把理论吃透,再动手不迟。
参考资料
-
• Hermes Agent GitHub:https://github.com/NousResearch/hermes-agent -
• 官方文档:https://hermes-agent.nousresearch.com/docs/ -
• 架构文档:https://hermes-agent.nousresearch.com/docs/developer-guide/architecture -
• Skills 文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/skills -
• Memory 文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/memory -
• GEPA 论文:https://arxiv.org/abs/2507.19457 -
• Hermes Agent Self-Evolution:https://github.com/NousResearch/hermes-agent-self-evolution