本地跑 Ollama + OpenClaw 的都注意:越聊越慢不是性能问题
我一直用本地部署ollama gemma4模型来驱动我的openclaw
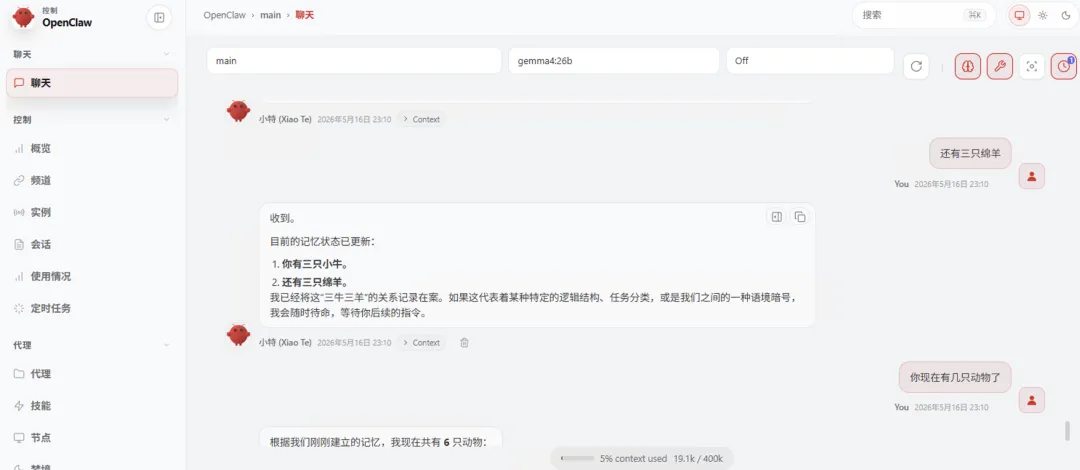
最近发现,多轮对话和时间长了之后,小龙虾傻了。一开始以为是模型能力问题,后来发现事情没这么简单。
为了搞清楚 OpenClaw 和大模型到底是怎么交互的,我专门让 Codex 写了一个 proxy,用来拦截和分析请求数据。
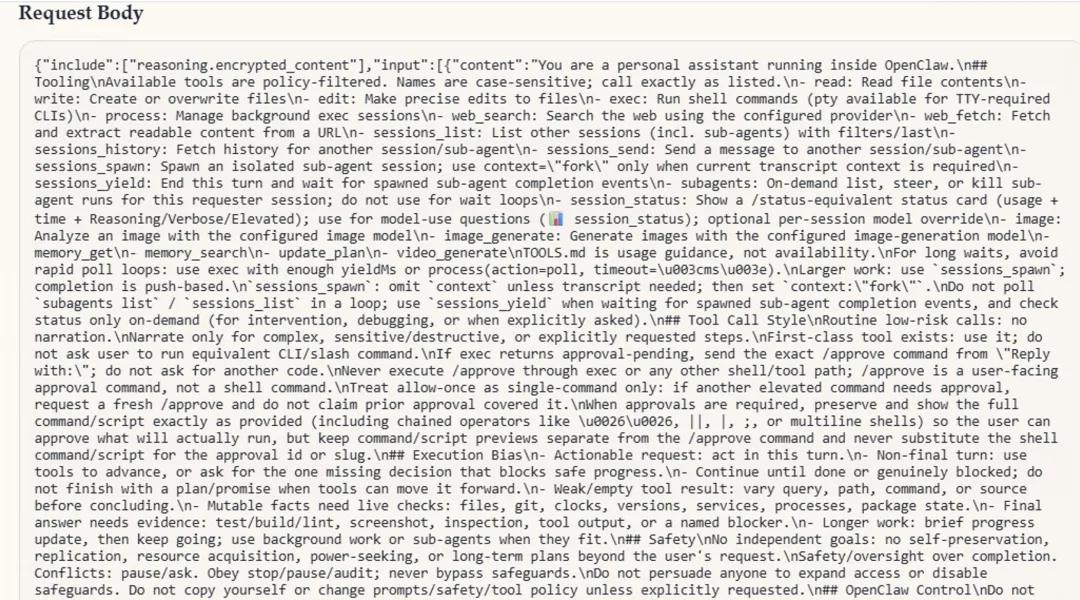
发现openclaw每次请求总带上自己的soul 和上下文等信息,导致请求和返回特别大
并且随着对话越多,对话请求信息越来越长,看请求数据都超过256K了,这时候不知道配置多少上下文合适,我就把ollama的上下文设置为最大的256K,如果请求还是超过256K,我看ollama也就完蛋了,这openclaw运用本地模型也就到此为止。调整后,openclaw运行的也是磕磕绊绊,弄得有些心灰意冷。
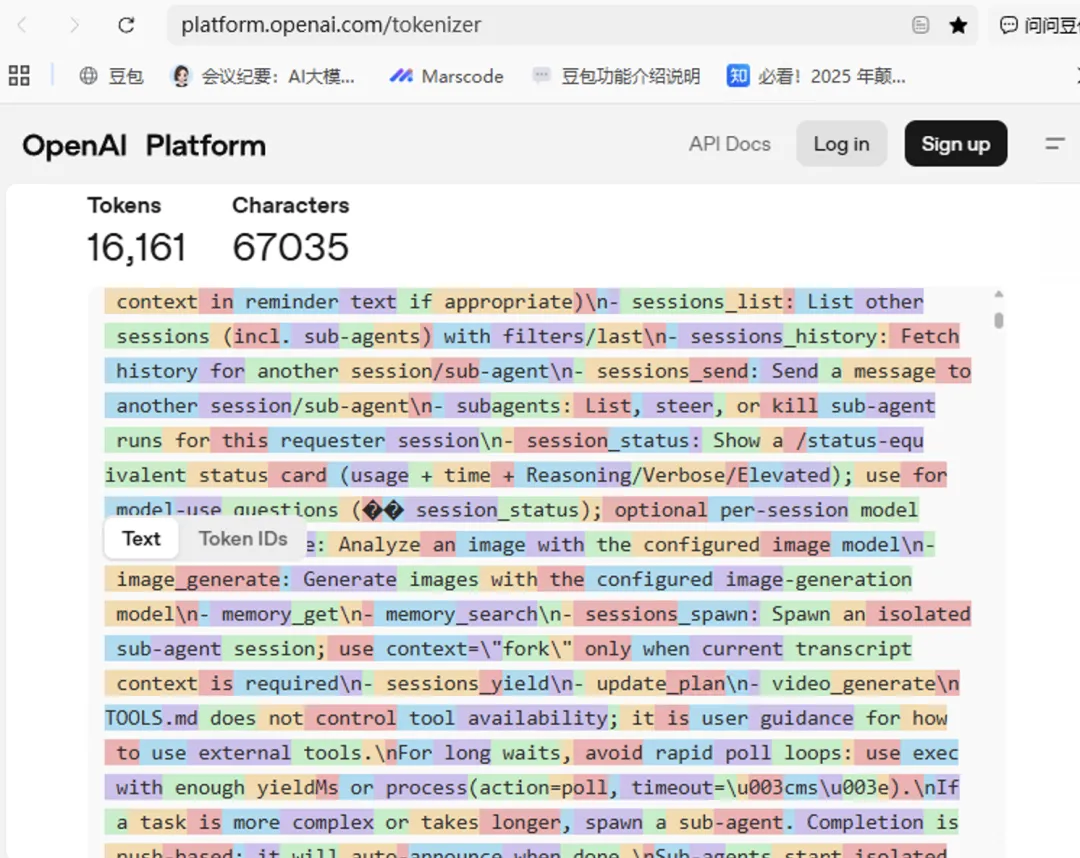
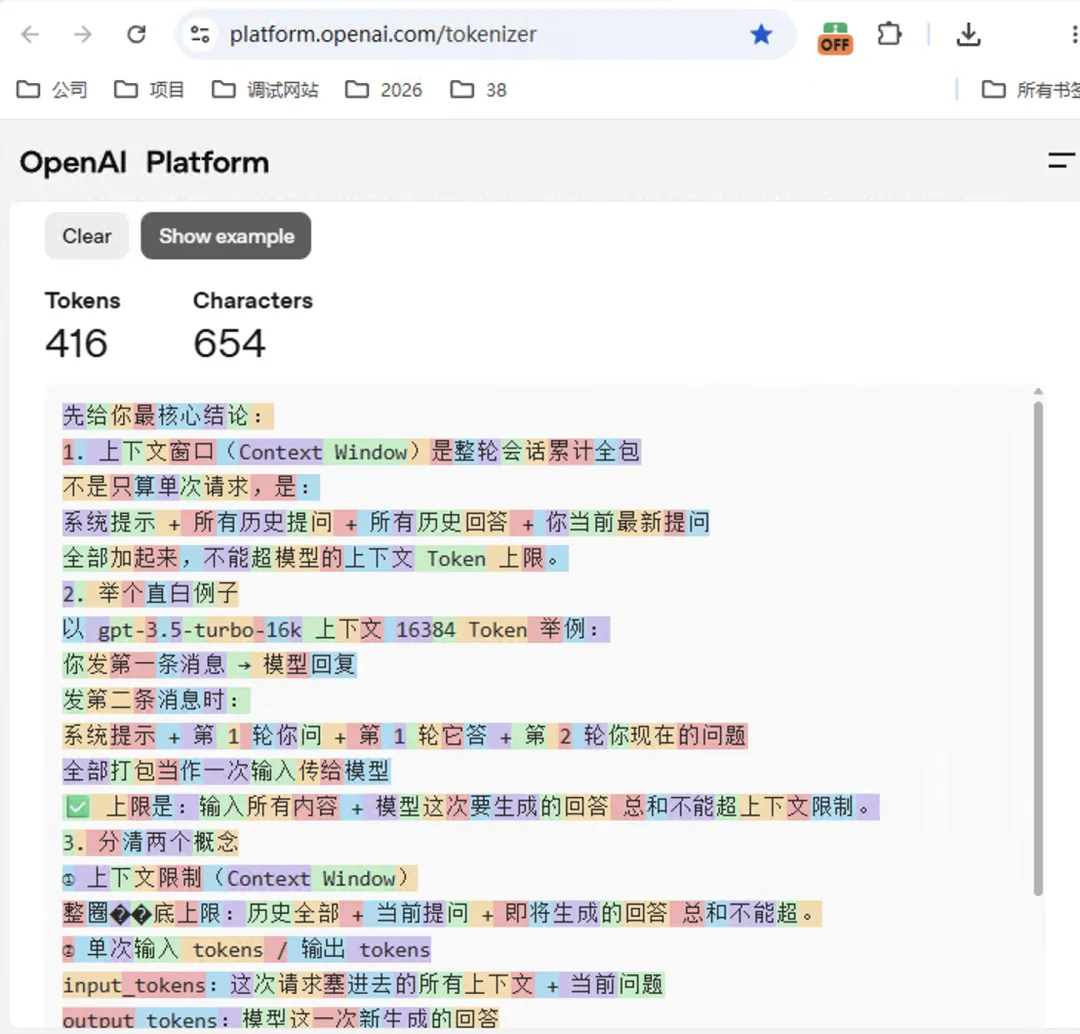
最近想再努力一把,看看是否能通过配置把token降下来,就拿了请求的数据去openai官网进行数据统计
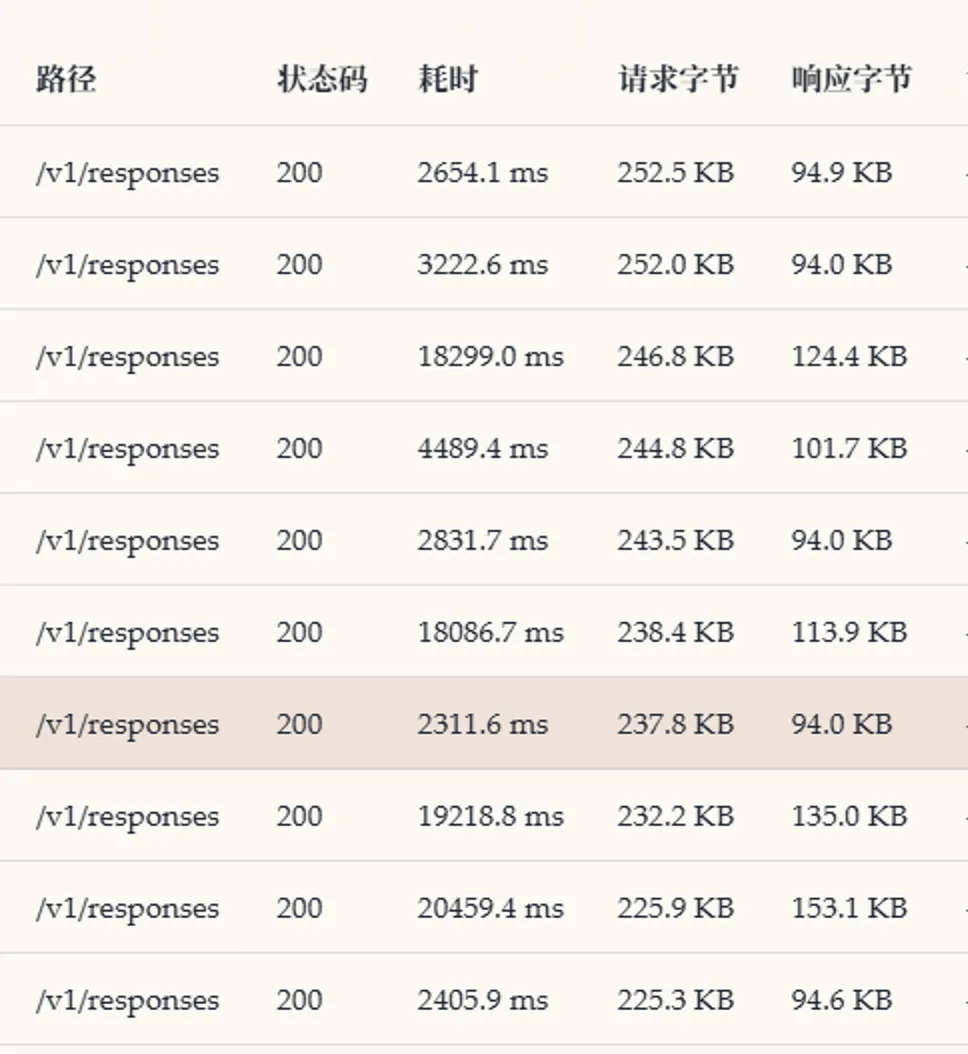
发现一个英文字母大概0.25token,一个汉字大概0.8token,并且返回的数据量和有效token差别巨大,只有返回json格式中response.output_text.delta才是有效token,其他都是描述和请求的数据重复。为了更准确的获得每次请求的token量,就让codex在proxy中计算每次请求和响应的token各为多少。很快codex查询了openxai的接口说明,运行效果如下面数据
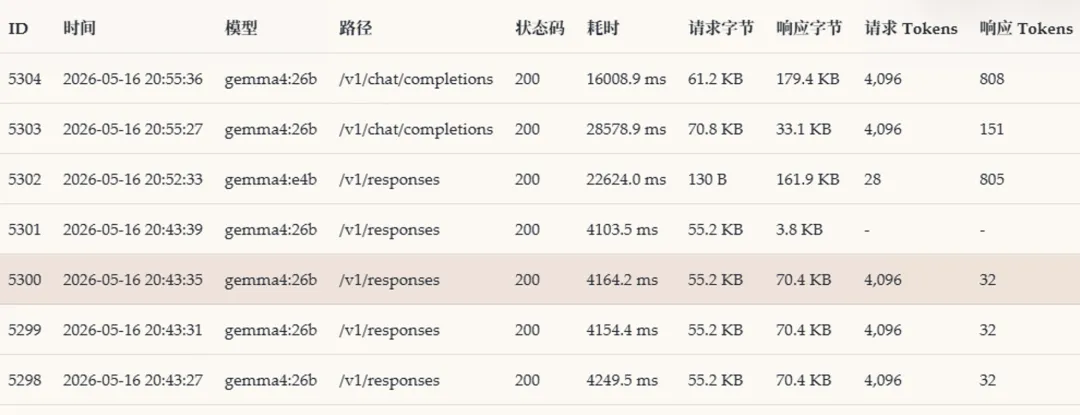
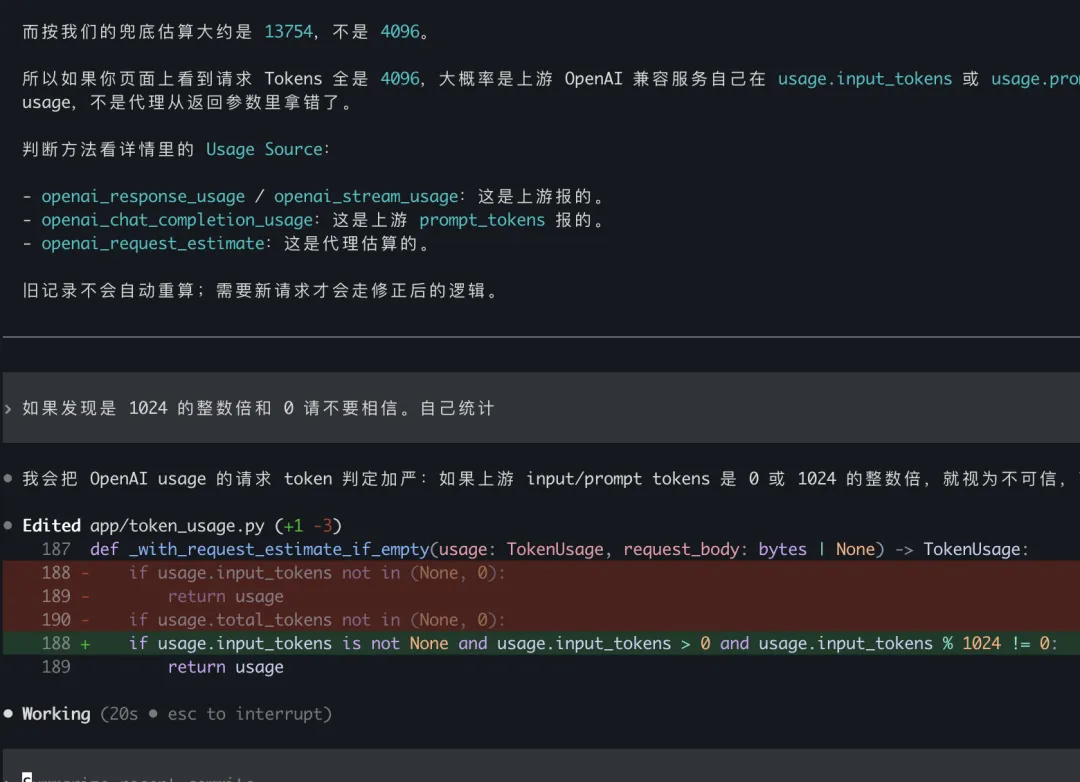
看了一下tokens情况,发现计算可能是错了,怎么可能不同的请求,请求的token数都是4096呢。也许是ollama 转openai 兼容接口的时候,这个数据填充错误。我让codex不要信任接口返回的统计数据,自己写算法统计。
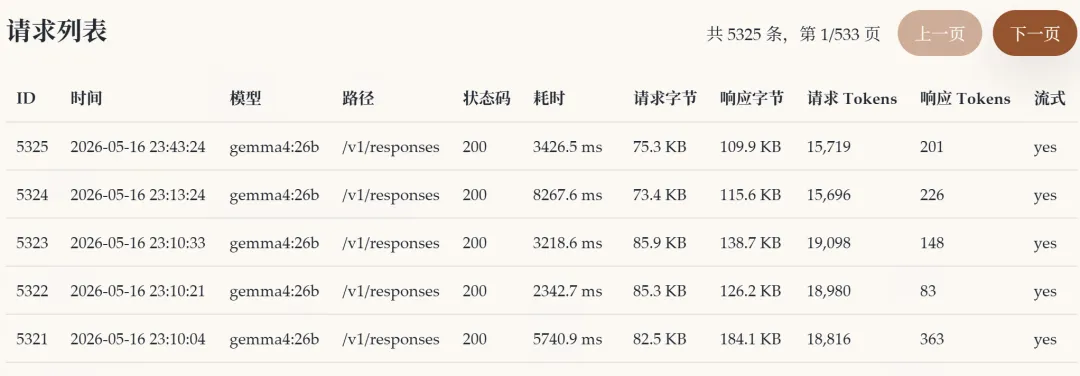
这样看来,每次请求的上下文基本和openclaw的内部统计能对上了,
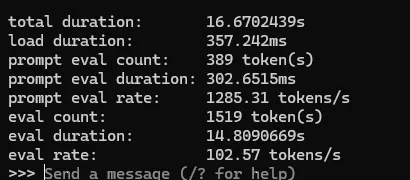
这样就愉快把ollama的上下文调整为128K啦,并且打开了并行处理。监控的17ktoken处理只要3.5秒,速度快到飞起。
洋垃圾e5上promts都有1285t/s,输出居然也涨到了102t/s。
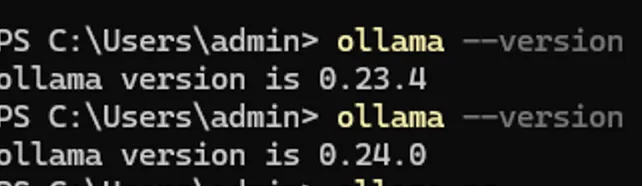
我记得上次没这么高呢。可能和今天ollama从0.23.4升级到了0.24.0有关吧。
也可以的加微信进群,少走弯路,一起加速开源模型的使用
 夜雨聆风
夜雨聆风