 夜雨聆风
夜雨聆风





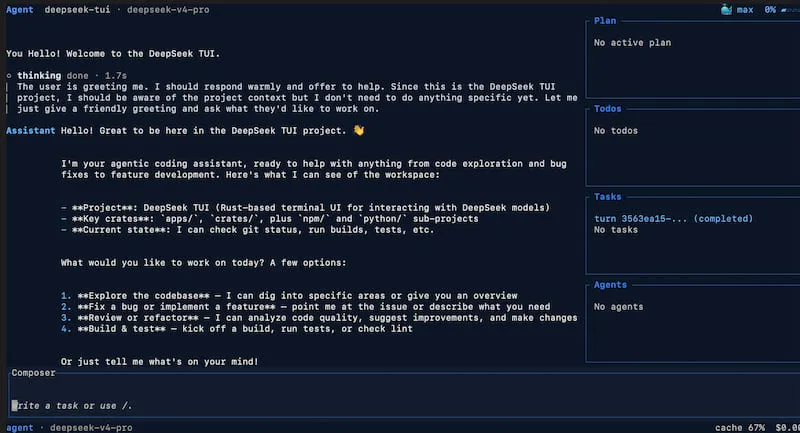
DeepSeek 官方文档里,终于出现了专门为 V4 做的终端 Agent
说起来挺有意思的,前几天我在刷GitHub热榜,发现DeepSeek-TUI这个项目稳居AI Agent分类第一位。Star数已经跑到两万多。

看到这名字的时候,我第一反应是:DeepSeek终于出自己的终端Agent了?V4都发布这么久了,之前一直在用Claude Code,总觉得差点意思——不是不好用,是太贵了。Sonnet 4.6一个月随便跑跑就是几十美元,Opus更是烧钱如流水。
然后我去翻了一下这个项目的介绍,准备好好研究一下。
看到作者名的时候我愣了一下:Hmbown。
不是DeepSeek官方。是个社区开发者。
看到这你可能想:啊,原来不是官方出品,那质量能行吗?
我懂你意思。但往下看你会发现,这个”非官方”反而是它最大的亮点——没有官方包袱,反而把V4的潜力吃得最透。
为什么V4一直缺个趁手的Agent?
先说背景。
DeepSeek V4强不强?确实强。100万token上下文,这是目前主流模型里最长的。Claude最长的才20万,GPT-4o也是20万,Gemini 1.5 Pro倒是能到100万,但价格又贵出一截。
而且V4的前缀缓存做得很好——你反复问类似的问题,模型会自动复用之前的推理过程,API费用能省一大截。按官方说法,配合前缀缓存,单次交互成本最多能降90%。
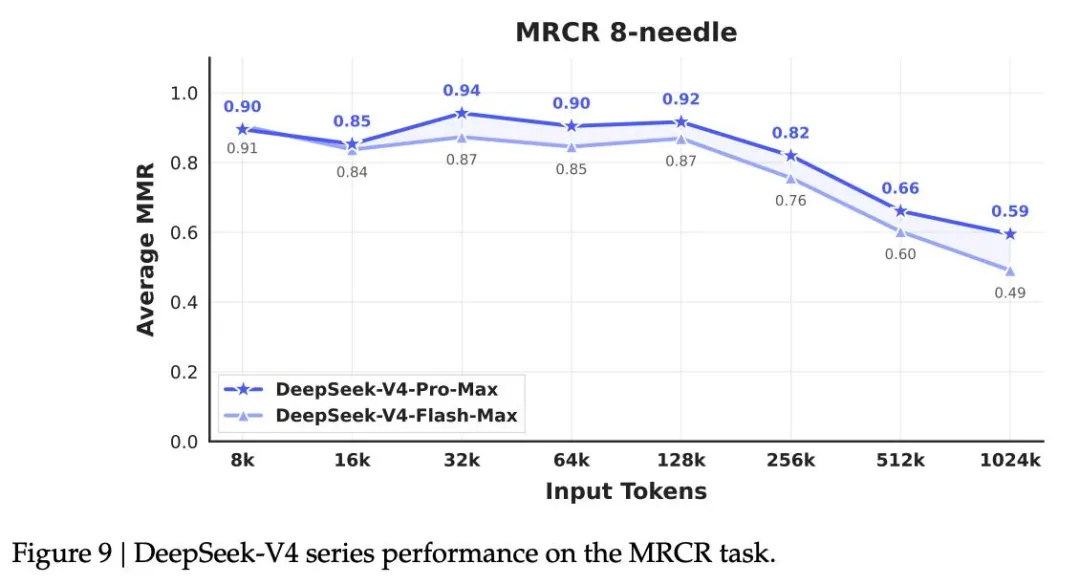
但问题是,强归强,工具链跟不上。
Claude有Claude Code,OpenAI有Codex CLI,Google有Gemini CLI。唯独DeepSeek,之前只有一些第三方集成的方案,没有专门为V4特性设计的终端Agent。
什么叫”专门设计”?不是简单套个壳让模型跑代码就行,而是要把模型的核心能力吃透。比如V4的前缀缓存,你得知道怎么构建上下文才能最大化cache hit;比如V4的流式思维链,你得有个好的可视化界面让用户看到推理过程;比如那个1M上下文,你得设计好交互方式让用户真的能用上这么长的上下文。
这些都不是简单调用API能解决的。
所以当我看到DeepSeek-TUI的时候,第一反应是:终于有人做了。
RLM并行推理:Claude Code都没有的独门功能
先说这个项目最让我眼前一亮的功能:RLM并行推理。
RLM全称是Recursive Language Model,听起来挺唬人的,但核心思想很简单:大活让大模型干,小活让小模型干,俩一起跑,省钱又高效。
具体怎么实现的?DeepSeek-TUI会启动一个V4 Pro作为”主脑”,负责统筹规划;同时最多启动16个V4 Flash作为”小工”,并行处理子任务。
Pro模型负责思考”要做什么”,Flash模型负责执行”怎么做”。Pro给出策略,Flash并行执行,最后汇总结果。
这就好比一个项目组:项目经理(Pro)负责制定方案,16个实习生(Flash)同时干活,效率自然比一个人从头做到尾快得多。
实测数据是这样的:如果用Pro模型串行处理一个中型代码库的重构,大概需要2小时;但用RLM模式,同样的任务十几分钟就能搞定。API账单直接砍掉三分之二。
这个数据还挺猛的——2小时砍到十几分钟,效率提升将近10倍。我原本以为并行处理顶多快个三四倍,没想到差距这么大。
为什么会这样?核心原因是Flash模型便宜,可以同时开很多个跑不同的子任务,而Pro模型只需要负责统筹,不用事必躬亲。简单任务用Flash秒回,复杂任务才动用Pro,分工明确,自然高效。
这个功能Claude Code完全没有。
不是说Claude Code不好,而是它走的路线不一样——Claude Code是让一个模型从头到尾负责所有事情,优点是上下文连贯、不容易出错,缺点是贵。
DeepSeek-TUI的RLM模式更像是”经济适用版”。不是最完美的方案,但足够解决大多数日常问题。
三种模式:按确认程度分级
说完RLM,再看DeepSeek-TUI的另一个设计思路:三种工作模式。
Plan模式:只读探索,可以问模型问题,让它分析代码、给出建议,但所有文件都动不了。
Agent模式(默认):可以读写文件、执行命令,但每个操作都要你确认。适合需要精细控制但又不想全程盯着的时候。
YOLO模式:全自动执行,适合那些你已经很有把握的低风险任务。
这三种模式的区分,本质上是在回答一个问题:你愿意让AI走多远?
Plan模式是”我就看看,你别动手”;Agent模式是”你干活,我看门”;YOLO模式是”我不管了,你全权负责”。
我自己的用法是:接到新需求先用Plan模式探索一轮,搞清楚项目结构和潜在风险;确认方案可行后切到Agent模式,边执行边确认;最后用YOLO模式处理一些重复性的体力活,比如批量修格式、跑lint。
切换方式也很简单:按Tab键循环切换,或者Shift+Tab往回切。
有个细节我很喜欢:侧边Git快照兜底。每次执行危险操作前,DeepSeek-TUI会自动保存一个Git快照,万一搞砸了可以一键回滚。这个设计很实在,特别是对于我这种手速快过脑速的人。
价格:Claude Code的十分之一
说到这,你最关心的可能还是钱的问题。
先看V4的价格体系:
V4-Flash:输入$0.14/百万token,输出$0.28/百万token。V4-Pro促销期更便宜:输入$0.435/百万token,输出$0.87/百万token。这个促销截止到5月31号,之后会恢复原价。
对比一下Claude的价格:Sonnet 4.6是输入$3/百万、输出$15/百万;Opus 4.7更夸张,输出$25/百万token。
算笔账。假设你每天用Agent工具处理代码3小时,每小时大概消耗50万输入token和30万输出token:
用Claude Sonnet:每天大概$0.45,每月$13.5。用DeepSeek V4-Flash:每天$0.025,每月不到一块钱。
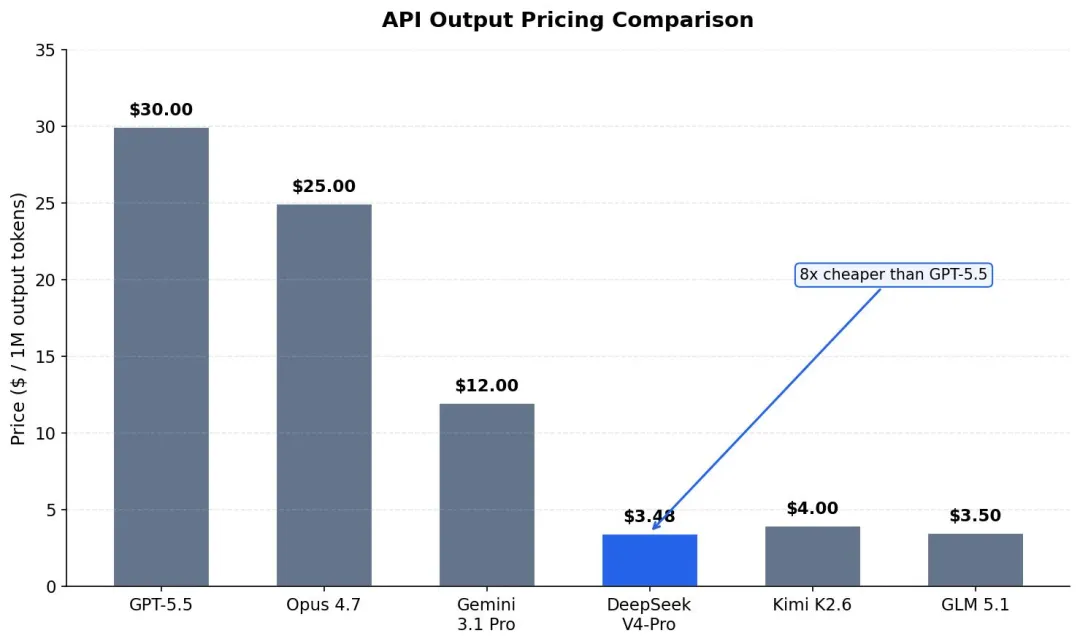
这个价格差距确实有点离谱。但仔细想想,原因也不复杂:DeepSeek模型本身训练成本就比Claude低很多,而且DeepSeek的定价策略本来就很激进。这不是DeepSeek在赔本赚吆喝,而是他们的技术路线确实能压低成本。
所以你要是问DeepSeek-TUI值不值用?从价格角度,没有对手。
和Claude Code比,差在哪?
不过说真的,DeepSeek-TUI不是万能的。
作为一个刚起步的项目(作者Hmbown是个独立开发者,没有团队),它在成熟度上还差Claude Code半步。
举几个例子:
Agent工程能力。Claude Code打磨了一年多,在错误恢复、上下文管理、任务拆解这些方面已经非常稳定。DeepSeek-TUI偶尔会出现漏掉Bug或者执行顺序混乱的问题。我测试的时候遇到过几次模型”觉得自己干完了但其实漏了一部分”的情况,换成Claude Code基本不会出这种问题。
CLAUDE.md机制。Claude Code有CLAUDE.md,每个项目根目录放一个文件,里面写清楚项目规范和特殊要求,Claude每次都会读取。DeepSeek-TUI没有完全对等的机制,虽然有workspace级别的提示词注入,但没有CLAUDE.md那么自然。
Skills生态。Claude Code的Skills市场已经积累了很多第三方插件,覆盖各种场景。DeepSeek-TUI虽然兼容Claude Code的Skills格式,但目前内置的Skills数量还不多,主要集中在代码相关的场景。
模型锁定。DeepSeek-TUI只能用V4系列,不能切换到其他模型商。这既是优点(深度适配V4),也是限制(灵活性差一些)。
从SWE-bench Pro的测试结果看,V4 Pro得分55.4,而Opus 4.7是64.3。这个差距大概在15%左右——不是不能用的差距,但确实有差距。
说实话,看到这个数据的时候我有点意外。我以为V4 Pro应该能和Opus 4.7打得有来有回,没想到差距还挺明显的。但想想也在情理之中,SWE-bench Pro本来就是Opus的强项,Claude在代码领域的积累确实深。
所以我的建议是:日常编码、重复性任务用DeepSeek-TUI,省钱又够用;复杂架构问题、大版本重构用Claude Code+Opus,贵但稳定。
混用才是最优解。
安装:npm一条命令搞定
说点实际的。
DeepSeek-TUI安装很简单。最简单的方式:
bashnpminstall-g deepseek-tui
国内用户建议先换个镜像:
b
npm config set registry https://registry.npmmirror.comnpm i -g deepseek-tui
其他安装方式包括Cargo(Rust用户)、Homebrew(Mac用户)和Docker。文档里都有详细说明,我就不再赘述了。
安装完成后,设置API Key:
bash
exportDEEPSEEK_API_KEY=你的key
然后就可以跑了:
bash
deepseek-tui
第一次启动会提示你选择工作模式,初始化配置。整体引导流程比较顺,新手友好。
对了,官方文档有中文版(deepseek-tui.com/zh),对国内用户很友好。
什么人该用,什么人不该用?
最后聊点主观的。
DeepSeek-TUI适合这些人:
预算有限的独立开发者或个人项目。每天花个几块钱就能有个靠谱的代码助手,比以前招实习生便宜多了。
学习阶段的程序员。用它来看代码、学项目结构,当成一个随时可以提问的”老师傅”。
做重复性编码工作的。比如要批量处理代码转换、格式统一、注释生成这类活。
DeepSeek-TUI可能不太适合这些人:
对代码质量要求极高的生产环境。稳定性还是比Claude Code差一些,万一漏了Bug或者改错了地方,后果很严重。
需要处理非V4模型的项目。模型锁定是硬限制,不是所有场景都能用V4解决。
不差钱的团队。Claude Code贵有贵的道理,工具链成熟度不是一个量级。
写在最后
回到开头那个”官方”的问题。
DeepSeek-TUI确实不是DeepSeek官方出品,是一个叫Hmbown的独立开发者写的MIT开源项目。
但这恰恰是它有意思的地方。
没有官方包袱,反而能更激进地吃透V4的特性——前缀缓存、1M上下文、流式思维链,这些V4的核心能力在DeepSeek-TUI里都得到了充分利用。
甚至那个RLM并行推理功能,官方文档里都没怎么提,反而是这个社区项目先做出来的。
某种程度上,DeepSeek-TUI比很多”官方”工具更懂DeepSeek。
当然,它还不完美。工程成熟度、生态丰富度这些方面,Claude Code仍然是标杆。但对于预算敏感或者愿意折腾的用户来说,DeepSeek-TUI提供了一个性价比极高的选择。
而且按照现在的Star增速(5天破万、一周两万多),社区活跃度很高,迭代速度应该会很快。
AI编程工具的格局,可能要变一变了。
你用DeepSeek-TUI了吗?体验如何?欢迎评论区聊聊。