 夜雨聆风
夜雨聆风





EDA 文档问答,答案错在哪该怎么评
读 MAEDA: An LLM-Powered Multi-Agent Evaluation Framework for EDA Tool Documentation QA
基于 DATE 2026 论文整理
芯片设计工程师问一个 EDA 工具问题,模型给出一段看似熟练的命令说明。真正危险的地方不在它答得像不像人,而在它可能把一个不存在的参数写得很自然,把检索不到的知识说成确定事实,或者在文档明明有答案时直接拒答。
这类错误很难靠 BLEU、ROUGE、BERTScore 这样的文本相似度指标发现。MAEDA 这篇 DATE 2026 论文把问题拆得更细:评测系统不只给一个分数,而是判断错在检索、拒答、矛盾、遗漏,还是幻觉。对正在把 LLM 接入 EDA 工具文档和流程助手的团队来说,这比一个笼统分数更接近工程调试所需的信息。
一、EDA 文档问答最怕答得像真的
现代 EDA 工具覆盖从系统级规格到物理验证的完整设计流程,文档数量庞大,命令、选项、约束和流程步骤互相牵连。工程师查文档的成本很高,LLM 加 RAG 自然成了一个有吸引力的方向:先从工具文档里检索相关片段,再让模型根据这些片段回答问题。
问题也随之出现。EDA 问答不是普通百科问答,答案经常落在一个命令名、一个参数名、一段脚本示例或一个工具行为边界上。一个参数多一个下划线,脚本可能直接不能跑;一个拒答判断错了,工程师会错过文档里已经存在的解决办法;一个检索片段缺了关键说明,生成器可能把半截证据扩写成完整结论。
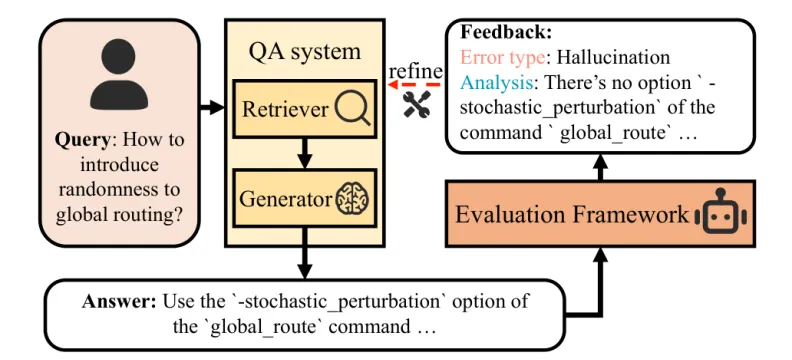
图1:EDA 文档问答评测应形成反馈闭环,错误类型会反过来指导检索器和生成器改进。
来源:原论文 Fig. 1,裁剪自第 1 页。
论文开篇给出的例子很典型。用户询问如何给 global routing 引入随机性,系统回答里出现了 global_route 命令的 -stochastic_perturbation 选项。评测器如果只看文本是否流畅,很可能漏掉问题;真正要做的是回到文档证据,判断这个选项是否存在,错误属于幻觉还是检索不足。
MAEDA 的目标就是给 EDA 文档 QA 建一个更像诊断工具的评测框架。它不把回答压缩成一个总分,而是输出可解释的错误标签和分析反馈,让开发者知道该改检索器、改生成提示词,还是补充训练数据。
这也是 EDA 场景和普通开放域问答的一个明显差别。普通问答里,答案略微不完整也许还能被读者自行补足;工具文档问答里,用户往往是带着操作任务来的。评测系统如果只能说这段回答相似度较高,工程师仍然不知道它能不能拿去写脚本。MAEDA 试图把评测粒度拉到可操作层面,让错误报告能进入后续调试流程。
二、论文把错误拆成五类
MAEDA 先定义输入。评测器接收用户问题 Q、模型生成答案 Agen、检索文档 D、专家标注的标准答案 Agt。系统要输出一组错误类型,而不是只判断答案好坏。这个设定很工程化,因为 RAG 系统出错时,检索器和生成器往往都有可能负责。
论文把错误分成两个层级。检索层错误关注 D 是否足以支持标准答案,生成层错误关注 Agen 是否在语义上忠实、完整、可落地。五类错误分别是 retrieval error、inappropriate refusal、contradiction、missing 和 hallucination。
检索错误指文档 D 没有足够证据支持某个标准答案要点。比如标准答案里需要说明 -st 选项的用途,检索文档只列出了命令用法,却没有解释这个选项能做什么,评测器就应判断该要点没有被文档支持。
不恰当拒答分成两种。第一种是 false refusal,文档中有证据,模型却拒绝回答。第二种是 false non-refusal,文档与问题无关,模型仍然硬答。前者浪费已有知识,后者放大不可靠输出,在工具问答场景里都很麻烦。
生成层的三类错误更贴近日常使用体验。contradiction 是生成答案与标准答案要点冲突,missing 是标准答案里的关键信息没有被覆盖,hallucination 则被拆成命令参数幻觉和示例幻觉。EDA 场景下这样拆很必要,因为命令、参数和脚本例子本身就是工程操作入口。
五类错误之间并不是简单的好坏等级,而是对应 RAG 系统里的不同失效位置。检索错误通常说明上游召回没有拿到足够证据;遗漏说明生成器拿到了部分信息却没有组织完整;矛盾说明生成答案和证据之间发生语义冲突;幻觉说明模型越过了文档边界;拒答错误则说明系统没有掌握什么时候该回答、什么时候该停下。这样的标签设计让评测结果更容易转化成修复任务。
三、MAEDA 的核心思路是多 Agent 分工
直接让一个通用 LLM 判断所有错误,论文认为效果并不稳定。原因不难理解:同一个回答里可能既有检索不足,又有遗漏,还可能夹着一个不存在的参数。评测器必须知道哪些标准答案要点已经被文档支持,哪些生成要点能对齐,哪些命令和例子应该逐项核验。
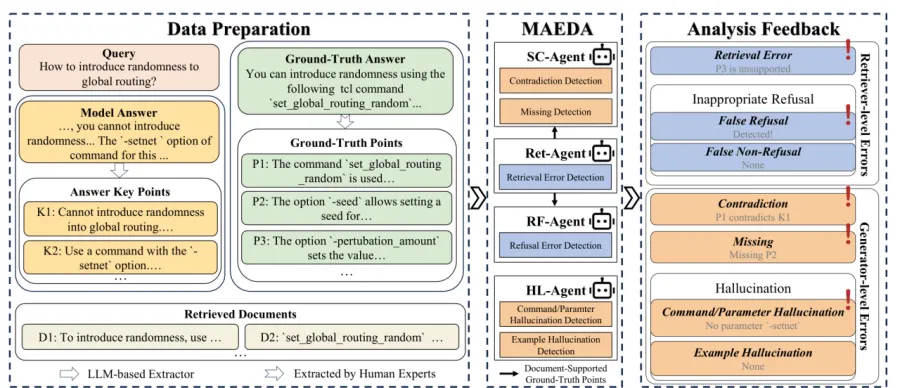
图2:MAEDA 总体框架。数据准备阶段拆出标准答案要点和生成答案要点,随后由多个 Agent 协作判断不同错误类型。
来源:原论文 Fig. 2,裁剪自第 2 页。
MAEDA 因此采用多 Agent 结构。Ret-Agent 负责检索错误,RF-Agent 负责拒答错误,SC-Agent 负责矛盾和遗漏,HL-Agent 负责幻觉。它们不是四个孤立分类器,而是有信息传递关系。Ret-Agent 先判断哪些标准答案要点有文档支持,这些被支持的要点再交给 SC-Agent 和 RF-Agent 使用。
这个设计的关键在点对点对齐。专家答案会被拆成 ground-truth points,模型答案会被拆成 answer key points。评测不再只比较两段长文本的整体相似度,而是检查每个标准要点是否有文档证据、是否被生成答案覆盖、是否与生成答案冲突。
论文还给 Agent 设计了结构化 CoT 推理策略。这里的重点不是让模型写更长的推理过程,而是把判断步骤固定下来。例如先找相关文档片段,再检查覆盖是否完整,再输出结构化标签。这样的流程更适合微调,也更容易做人工审查。
数据准备阶段同样重要。论文没有直接把专家答案和模型答案扔给评测器,而是先拆成标准答案要点和生成答案要点。这样做会增加标注和处理成本,却换来了更清楚的责任边界。一个标准要点如果连检索文档都不支持,后面判断生成器遗漏时就要更加谨慎;一个生成要点如果包含文档中找不到的命令,则可以进入幻觉检测路径。
四、先把检索证据理清楚
Ret-Agent 是整个框架的起点。RAG 系统的生成答案是否可靠,很大程度取决于检索结果是否提供了足够证据。论文发现,单纯提示 LLM 去映射文档和标准答案要点并不可靠,所以 Ret-Agent 采用更细的语义匹配流程。
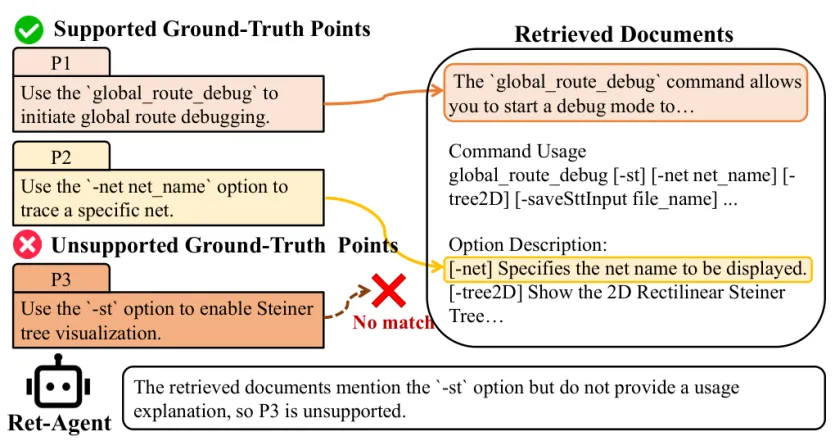
图3:Ret-Agent 会逐个检查标准答案要点是否被检索文档完整支持,并输出可供后续 Agent 使用的文档支持要点。
来源:原论文 Fig. 3,裁剪自第 3 页。
图3中的 global_route_debug 例子说明了这种细粒度判断。文档支持 P1 和 P2,但对 P3 只出现了 -st 选项,没有提供使用解释。Ret-Agent 因此把 P3 标为 unsupported。这个结果非常重要,因为后续评测生成答案时,不能把检索器没有提供的要点强行算到生成器头上。
这一步看似只是预处理,实际决定了评测是否公平。RAG 系统的答案质量通常由检索器和生成器共同决定。如果检索器没拿到文档证据,生成器即使没有覆盖某个标准要点,也不一定应该被判为生成错误。Ret-Agent 给出的 document-supported points 像一层证据过滤器,先把可用证据范围定下来,再让后续 Agent 在这个范围内评估。
RF-Agent 处理另一类常见问题:该答不答。它先用模式匹配识别 Agen 和 Agt 是否为拒答,再根据分支逻辑判断错误类型。如果模型拒答但标准答案可回答,它会询问 Ret-Agent 是否存在文档支持的标准要点;只要存在,拒答就不合理。如果模型和标准答案都在回答,但文档和问题语义无关,系统会判为 false non-refusal。
拒答判断在企业内部知识库里尤其敏感。过度拒答会让助手看起来保守无用,过度回答又会让系统输出没有依据的操作建议。MAEDA 把拒答拆成 false refusal 和 false non-refusal,等于把安全性和可用性都纳入评测,而不是只奖励模型多回答或少回答。
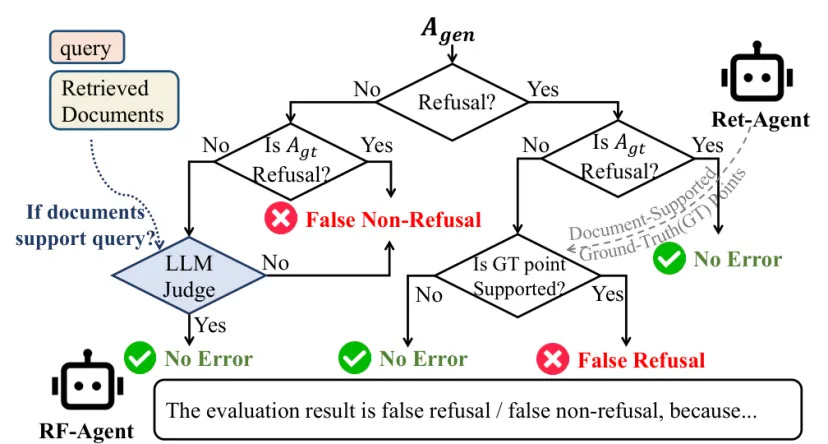
图4:RF-Agent 用分支逻辑判断拒答是否合理,并在关键节点借助 Ret-Agent 或 LLM 判断文档是否支持问题。
来源:原论文 Fig. 4,裁剪自第 3 页。
五、再检查答案是否对齐、是否编造
SC-Agent 面向生成层的矛盾和遗漏。它把 Agen 先切成若干 key points,再拿这些点与 Ret-Agent 给出的 document-supported points 做对齐。每个标准要点都会经历两类检查:有没有生成要点与它冲突,有没有生成要点覆盖它。
这种做法能避免长答案比较里的粗糙判断。一个 EDA 回答可能先解释 h_layers,又介绍 -min_distance,再补一段示例。如果整段文本拿去打分,评测器很难指出到底错在哪个命令、哪个选项。点对点对齐让错误定位更接近代码审查,能明确指出 P1 contradicts K2 或 Missing P2。
矛盾和遗漏也常常同时出现。模型可能先给出一个错误解释,又漏掉另一个必要选项。若只做单标签判断,评测报告会掩盖问题的复合性。SC-Agent 输出的是结构化多标签结果,能把同一回答中的多个问题并列呈现,这对后续样本分析和错误归因更有价值。
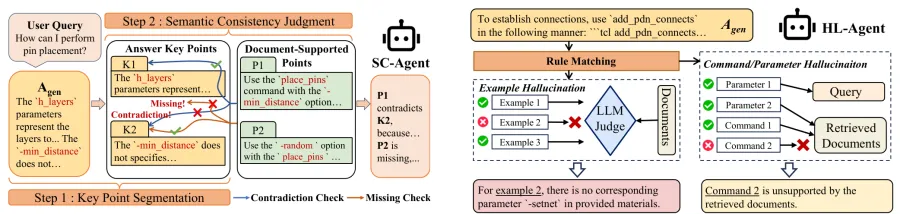
图5:SC-Agent 用点对点对齐判断矛盾与遗漏,HL-Agent 将命令参数核验和示例核验分开处理。
来源:原论文 Fig. 5 与 Fig. 6,裁剪自第 4 页。
HL-Agent 则把幻觉拆得更贴近 EDA 文档格式。命令参数幻觉主要靠规则抽取与匹配:从生成答案里抽出格式良好的命令和参数,再与用户问题和检索文档中的合法来源比对。只要某个命令或参数在两边都找不到,就会被标成幻觉。
示例幻觉更复杂。脚本片段可能看起来格式正确,却用了文档没有定义的参数,或者违反参数取值约束。MAEDA 先用正则和格式约束抽取示例,再让 LLM 按结构化提示与文档中的用法说明比对。规则负责稳定抽取,LLM 负责语义判断,两者结合减少了单靠通用模型带来的不确定性。
这种规则加 LLM 的组合很适合 EDA 文档。EDA 命令通常有相对固定的书写形式,参数也带有明显的前缀和取值结构,规则抽取能抓住这些低层模式。LLM 的优势则在于理解用法说明、约束条件和自然语言描述。MAEDA 没有把所有任务都交给模型自由判断,而是让规则处理确定性部分,让模型处理语义部分。
六、benchmark 不是随手拼的问答集
评测框架要站得住,必须有能覆盖领域错误的 benchmark。论文基于 ORD-QA 构建数据集,ORD-QA 来自 OpenROAD 文档,覆盖功能、VLSI 流程、GUI、安装与测试四类场景。OpenROAD 是开源 RTL-to-GDSII 数字设计流程系统,因此数据集具有较强的 EDA 工具代表性。
数据构造分两路。一路来自真实 RAG 工作流中的案例,能保留实际检索和生成行为。另一路参考 OmniEval 的思路,用 GPT-4o 按特定错误类型生成负样本。标准答案要点由领域专家人工识别,所有生成样本还经过人工审核。最终 benchmark 包含 300 个 QA 实例,覆盖论文定义的全部错误类型。
300 个 QA 实例听起来不算大,但它的价值在于错误类型覆盖和人工质量控制。评测数据如果只是随机收集问答,很容易堆出大量简单正确样本,真正困难的矛盾、拒答和幻觉案例反而不足。论文按错误类型构造负样本,再让专家参与要点识别和过滤,目的就是让 benchmark 能够考到评测框架真正需要处理的边界情况。
微调数据也单独构造。论文为 Ret-Agent 和 SC-Agent 各训练模型,基础模型是 Qwen3-14B,训练方法采用 QLoRA。训练时设置 2 个 epoch,学习率 1e-4,batch size 为 16,LoRA rank 为 32,alpha 为 16,dropout 为 0.05,硬件为 40GB A100。
样本规模方面,构造流程先得到 3197 个正样本,再为不同错误类型生成负样本,并用 DeepSeek-R1 生成监督信号。人工过滤后,检索错误评测数据为 2094 条,矛盾和遗漏评测数据为 2670 条。这些数字说明 MAEDA 并不是只靠提示词完成任务,论文也在尝试把结构化推理过程固化到模型能力里。
从工程角度看,这种做法给了一个可复制的路线:先定义错误 taxonomy,再围绕每类错误构造样本,最后把评测器的推理路径变成训练监督。对于其他 EDA 工具,最难的可能不是复用 MAEDA 的框架,而是把本工具的文档结构、命令语法和真实故障案例整理成同样细粒度的数据。
七、实验结果说明了什么
论文把 MAEDA 与 RAGChecker、RAGEval、G-Eval 做比较,并分别报告五类错误的 recall 和 precision。OpenROAD 数据集上,MAEDA with Fine-tuned models 在 retrieval error 上达到 0.973 recall 和 0.936 precision,在 contradiction 上达到 0.941 recall 和 0.800 precision,在 missing 上达到 0.928 recall 和 0.726 precision。
拒答错误上,MAEDA 多个设置的 recall 都达到 0.987,明显高于 G-Eval 的 0.267。幻觉检测上,MAEDA with Qwen3-14B 的 recall 为 0.935,GPT-4o 版本的 precision 为 0.769。论文给出的解读是,规则匹配和结构化推理能有效覆盖 EDA 这种命令参数密集的场景。
这些结果还反映出一个细节:不同错误类型对模型能力的要求并不相同。检索错误更依赖文档和标准答案的证据匹配,矛盾与遗漏更依赖细粒度语义对齐,幻觉检测则需要命令参数层面的精确核验。MAEDA 把任务拆开后,可以为不同 Agent 选择不同策略,而不是强迫一个统一指标同时承担所有判断。
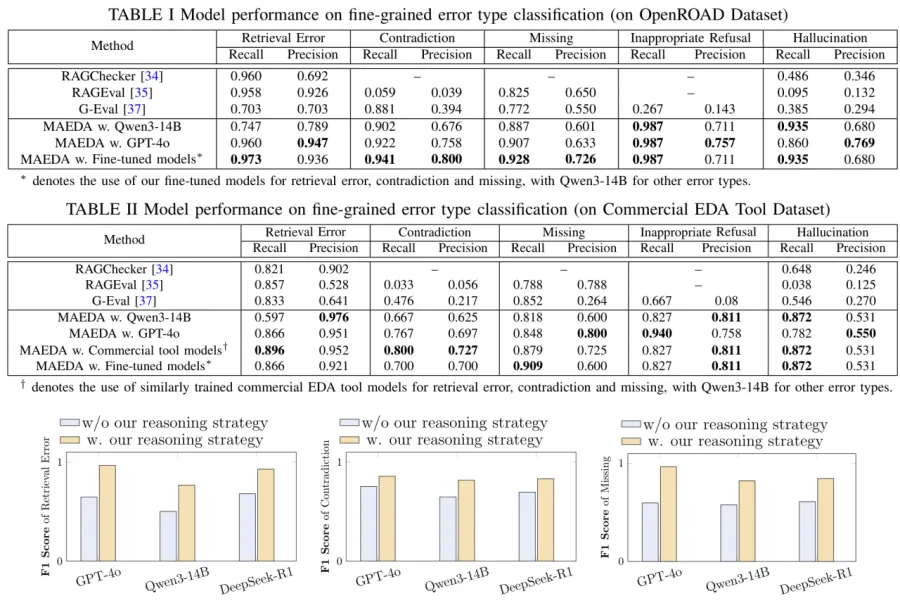
图6:OpenROAD 与商业 EDA 工具数据集上的评测结果,以及结构化推理策略的消融实验。
来源:原论文 Table I、Table II 与 Fig. 7,裁剪自第 6 页。
论文还用一个商业 EDA 工具数据集检验迁移性,该数据集面向 timing ECO 平台,包含 205 个 QA 实例。结果显示,MAEDA 在多数错误类型上仍优于基线。比如商业工具专门训练模型在 retrieval error 上达到 0.896 recall 和 0.952 precision,在 contradiction 上达到 0.800 recall 和 0.727 precision。
消融实验更能说明结构化推理的价值。论文比较 GPT-4o、Qwen3-14B、DeepSeek-R1 在使用和不使用 MAEDA 推理策略时的 F1。以 GPT-4o 的 retrieval error 为例,F1 从 0.6462 提升到 0.9535。这说明即使是强商业模型,在 EDA 文档问答评测这类专业任务中,也需要明确的判断路径和细粒度语义对齐。
也要看到,表格里的 precision 和 recall 并非每一项都同时达到极高水平。例如幻觉检测在不同模型设置下会出现 recall 和 precision 的取舍,商业工具数据集上的迁移结果也存在波动。论文没有把 MAEDA 包装成一次性解决所有评测问题的方案,而是展示了领域化错误定义和结构化推理能带来稳定增益。
八、对 EDA QA 系统建设的启发
MAEDA 最有价值的地方,不只是性能表格里的数字,而是它把评测结果变成了可行动反馈。retrieval error 指向文档切分、索引、召回和重排问题;missing 指向生成答案覆盖不全;contradiction 指向语义忠实性;hallucination 指向命令参数和示例校验;inappropriate refusal 则暴露系统对可答边界的判断能力。
这对 EDA 工具助手尤其重要。工具文档往往更新快、版本差异大,错误答案不只是体验问题,还可能影响设计流程。评测框架如果只输出一个综合分,工程团队很难决定下一步该补文档、调检索,还是改生成器。MAEDA 的多标签诊断能把问题落到模块上。
论文也有边界。benchmark 主要围绕 OpenROAD 和一个商业 timing ECO 平台展开,虽然覆盖了两类场景,但不同 EDA 工具在命令语法、文档组织和使用习惯上差异很大。MAEDA 的 Agent 设计具备迁移思路,真正落到更多工具时,仍需要补充领域样本、调整规则抽取器,并持续审核负样本质量。
另一个现实问题是成本。多 Agent 评测比单次 LLM 打分更复杂,尤其在大规模回归测试中,推理成本、延迟和日志管理都要考虑。论文选择对 Ret-Agent 和 SC-Agent 做 Qwen3-14B 微调,某种程度上也是在寻找成本和质量之间的平衡。
如果把 MAEDA 的思想放进实际系统,可以从两个层次落地。离线阶段,用它评估一批标注问答,定位检索召回、答案覆盖和幻觉问题,作为版本迭代指标。上线阶段,可以选择性地对高风险回答运行部分 Agent,例如只对包含命令和脚本的回答启用 HL-Agent,对拒答类回答启用 RF-Agent。这样能在评测质量和运行成本之间留出调度空间。
对团队协作来说,MAEDA 也改变了评测报告的阅读方式。检索工程师可以优先看 retrieval error 和 unsupported points,模型工程师可以看 contradiction、missing 和 hallucination,产品负责人则可以关注 refusal 行为是否影响可用性。错误类型一旦稳定下来,就能成为跨角色沟通的共同语言。
这篇论文没有回避一个基本事实:领域 QA 的可靠性不是靠更会说话的模型自然长出来的。文档证据、标准答案要点、生成答案要点和错误标签都要被明确建模。MAEDA 的方法论价值正在这里,它把评测从主观印象拉回到可检查的证据链。
后续如果要把这类框架用在更复杂的设计流程里,还可以继续往任务级评测扩展。例如一个回答是否只给对了单条命令,还是能覆盖前置条件、参数约束、失败处理和版本差异。MAEDA 没有解决所有层次的问题,但它先把最基础也最关键的答案可靠性评测做细了。
结语
EDA 文档问答的难点,不只是让模型答出一段看起来合理的文本,而是让回答经得起工具文档、命令参数和操作示例的逐项核验。MAEDA 把这个问题拆成五类错误,再用多个 Agent 分别处理检索证据、拒答边界、语义对齐和幻觉核验,让评测更接近工程诊断。
从论文结果看,结构化推理和点对点对齐确实能提升专业领域评测的可靠性。对正在建设 EDA Copilot、工具文档助手或内部知识问答系统的团队来说,MAEDA 的启发很直接:先把错因分清,再谈模型优化。只有评测能指出问题落在哪个环节,RAG 系统才有机会稳定变好。
参考资料
本文图 1 至图 6 均裁剪或整理自原论文 MAEDA: An LLM-Powered Multi-Agent Evaluation Framework for EDA Tool Documentation QA,仅用于论文解读与学术交流。论文基准代码地址为 https://github.com/Rayzzz14/MAEDA-DATE26/。