 夜雨聆风
夜雨聆风





#AI学习#用6小时手搓了一个软件?




如何用6小时
手搓一个软件




PART 1

前言

对财务人而言很痛苦的一件事,是收到一份几十页的发票文件,或者几十张不同类别的发票,需要逐张审核发票抬头、税号,统计汇总金额等。原始的做法是一张一张的看、一个数一个数的按计算器;稍微进阶一点的做法是审核一张,把数字等信息贴到表格里,以防计算器加错了;难度再高一点的做法,用python写一个代码来批量识别统计;有了AI之后,这件事情在某种程度上,又变得原始并简单,直接把这个文件丢给deepseek,让它统计发票金额、核实发票抬头及税号、是否有重复发票等,它会清晰并详实地向你汇报。不过这么做有个小问题,有些公司可能不允许上传发票至AI,导致这条路行不通。
上周初步了解了一些AI相关的概念,我脑中就开始盘算能不能利用AI搓一个发票识别软件出来,这样即使是没有编程经验的同事,在离线的状态下,也能够完成发票批量自动识别统计。我是这么操作的:
打开与deepseek的对话,把我的想法丢给它:
我想要做一个能够识别和统计发票的软件,基本功能是:上传发票文件(包括PDF、各种图片格式等),文件可以是一张或者多张拼接,软件可以逐一识别发票类别、公司抬头、税号、发票编码是否重复、发票金额等,并且按照发票类别统计张数、金额等。你帮我做一个方案出来。

接下来就是deepseek提供方案和操作步骤,我根据步骤一步一步执行(包括一些必要软件的下载和安装、如何修改并执行它给的代码、把问题反馈给它再修改等等)。因为在发送需求的时候,我就跟它表示,我需要的是傻瓜式的操作手册,所以完全按照它的步骤来执行即可。这个来回拉锯的过程,耗费了两个午休以及下班后的大约4个小时的时间,最终呈现出能满足目前需求的一个软件,我把测试的GIF贴在下面给大家看看。
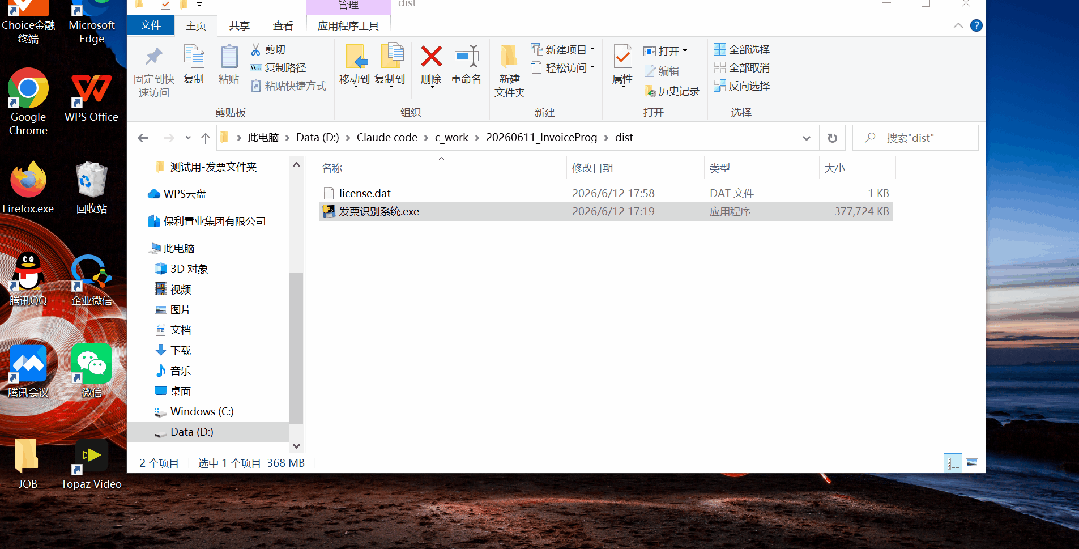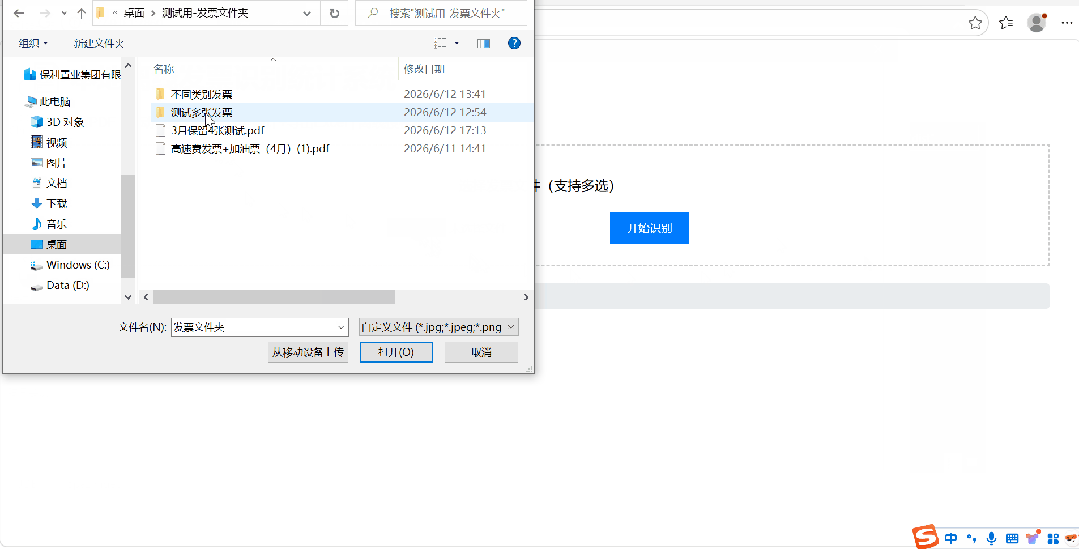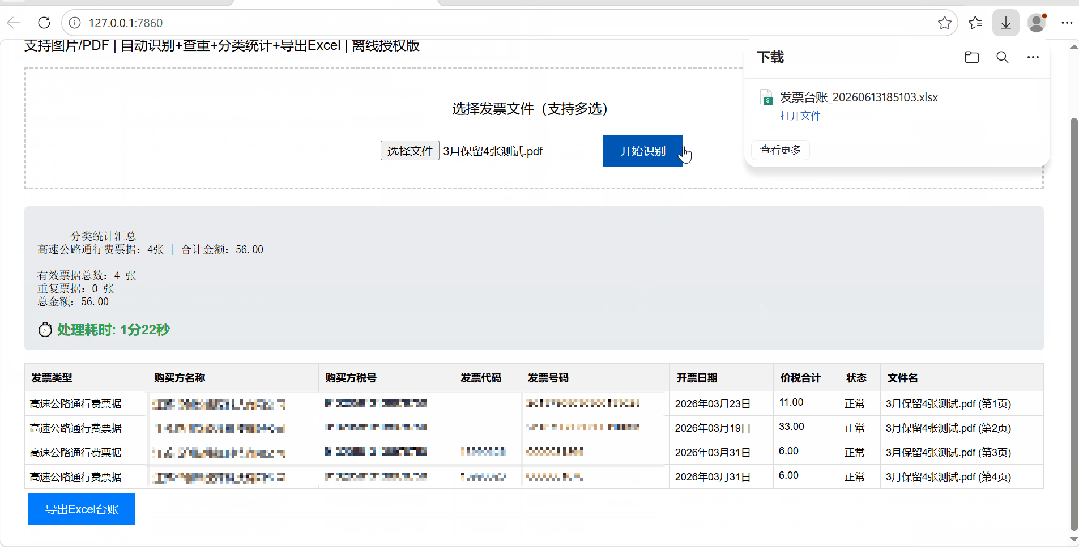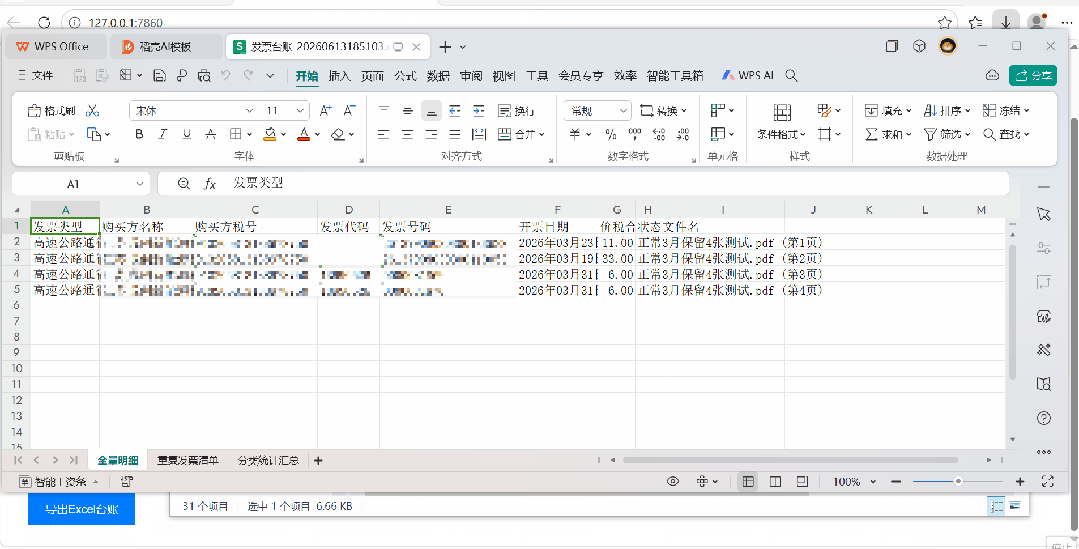

PART 2

发票识别系统项目开发总结

这一部分是在项目完结后,我让deepseek对这两天的所有操作进行的一个开发总结。大家可以把自己带入到项目审核的角色,看看deepseek这个项目经理的汇报怎么样。
01
项目背景与目标

>我们想解决什么问题?
财务人员每天要处理大量发票:核对发票信息、检查是否有重复报销、统计各类发票金额、制作Excel台账……这些工作繁琐且容易出错。
>我们的目标是?
开发一个完全离线的发票识别统计系统,让用户只需上传发票图片或PDF,系统自动完成识别、查重、统计、导出Excel,全程无需联网,数据100%留在本地。
>核心要求
| 要求 | 说明 |
| 完全离线 | 不上传任何发票数据到云端 |
| 一机一码授权 | 防止软件随意扩散 |
| 支持多种格式 | 图片(JPG/PNG等)、PDF、多页PDF |
| 自动识别字段 | 发票类型、购买方名称、税号、发票号码、开票日期、价税合计 |
| 自动查重 | 基于发票号码判断是否重复报销 |
| 自动统计 | 按票种分类汇总金额 |
| 导出Excel | 生成明细表、重复清单、统计汇总三张表 |
02
开发过程回顾

>第一天:从零搭建基础框架
1. 技术选型
我们需要一个能在Windows上运行、支持离线OCR(光学字符识别,即从图片中提取文字)的系统。经过对比,选择了以下技术栈:
| 组件 | 作用 | 选择理由 || Python | 编程语言 | 生态丰富,适合快速开发 || EasyOCR | 文字识别引擎 | 离线可用,中文识别效果好 || Flask | Web界面框架 | 轻量级,用户通过浏览器操作 || PyInstaller | 打包工具 | 将Python代码打包成EXE文件 |
2. 第一个可用版本
我们写了一个简单的程序:用户上传发票图片,程序识别出文字,然后通过正则表达式(一种文本匹配规则)提取发票号码、金额等信息。
**初步成果**:能识别单张图片发票了,但问题很多——换一张发票就识别失败,因为不同发票的格式不一样。
3. 遇到的问题与解决
| 问题 | 原因 | 解决方案 || PDF无法识别 | 缺少poppler工具 | 让用户安装poppler,代码自动查找路径 || 中文文件名乱码 | 命令行不支持中文 | 改用时间戳作为存储文件名,保留原始名用于显示 || 图片识别失败 | 图片太小或模糊 | 自动放大图片、增强对比度 || 日期识别成"2026年06月048" | OCR把"日"识别成"8" | 增加日期容错逻辑,自动修正 |
>第二天:功能完善与打包发布
1. 增加授权机制
为了防止软件被随意复制使用,我们实现了**一机一码离线授权**:
– 每台电脑有唯一的设备ID(基于硬盘序列号生成)
– 管理员用私钥生成授权码(绑定设备ID和有效期)
– 用户输入授权码,程序用公钥验证,激活成功
**优点**:完全离线,激活后无需再次联网。
2. 多页PDF支持
用户反馈:一张PDF可能包含多张发票(每页一张)。
我们修改了代码:PDF逐页识别,每页作为独立发票处理,文件名显示为”原文件名(第X页)”。
3. Excel导出优化
| 优化项 | 效果 || 千分位格式 | 金额显示为1,234.56,更易读 || 自动列宽 | 列宽自动适应内容,无需手动调整 || 重复发票标红 | 重复的发票行自动标红背景 || 文件名列 | 记录每张发票的原始文件名 |
4. 用户体验优化
| 优化项 | 效果 || 自动打开浏览器 | 双击EXE后自动打开操作界面 || 处理时间显示 | 显示本次识别耗时(如"12秒") || 批量上传 | 支持同时上传多个文件 |
5. 打包成EXE
使用PyInstaller将Python代码打包成单个EXE文件(约300-500MB,包含OCR模型),用户无需安装Python环境,双击即可运行。
03
最终产品功能清单

>核心功能
| 功能 | 说明 || 文件上传 | 支持JPG、PNG、BMP、TIFF、PDF,支持多选、拖拽 || 发票识别 | 自动提取:发票类型、购买方名称、税号、发票号码、开票日期、价税合计 || 多页PDF | 每页作为独立发票识别 || 自动查重 | 基于发票号码判断重复,重复发票标红显示 || 分类统计 | 按发票类型统计张数、合计金额 || Excel导出 | 生成3张表:全量明细、重复清单、分类统计汇总 |
>授权与安全
| 功能 | 说明 || 一机一码 | 每台电脑需要独立授权 || 离线运行 | 激活后完全离线,不上传任何数据 || 临时文件清理 | 识别完成后自动删除上传的临时文件 |
>用户体验
| 功能 | 说明 || 自动打开浏览器 | 启动后自动打开操作界面 || 处理时间显示 | 显示识别耗时 || 千分位格式 | Excel金额显示为1,234.56 || 自动列宽 | Excel列宽自动适应 |
04
产品使用流程

>管理员(软件分发者)
1. 运行`generate_keys.py`生成公钥和私钥
2. 将公钥嵌入`main.py`
3. 打包成EXE发给用户
4. 用户提供设备ID后,用`admin_tool.py`生成授权码
>普通用户
1. 双击`发票识别系统.exe`
2. 首次运行显示设备ID,发给管理员获取授权码
3. 输入授权码,激活成功
4. 浏览器自动打开操作界面
5. 上传发票,点击”开始识别”
6. 查看识别结果,导出Excel台账
05
技术亮点

1. 离线OCR
使用EasyOCR,模型文件约200MB,识别准确率约95%,完全离线运行。
2. 智能查重
基于”发票代码+发票号码”作为唯一标识,即使税号识别错误也不影响查重。
3. 容错设计
– 日期中的”日”被识别成”8″时自动修正
– PDF缺少poppler时给出友好提示
– 识别失败的文件标记为”识别失败”,不影响其他文件
4. 打包优化
– 模型文件随EXE打包,用户无需额外下载
– 使用`sys._MEIPASS`解决打包后路径问题
06
遇到的问题与解决记录

| 问题 | 解决方案 || 图片识别失败 | 自动放大图片、增强对比度 || PDF无法识别 | 自动查找poppler路径,用户只需解压到C:\poppler || 多页PDF被合并成一页 | 修改为逐页识别,每页独立处理 || 中文文件名乱码 | 存储用时间戳,显示用原始名 || EXE在其他电脑闪退 | 使用相对路径+sys._MEIPASS解决模型路径问题 || 浏览器不自动打开 | 添加threading延迟打开浏览器的代码 |
07
项目成果

>经过两天的开发与迭代,我们完成了:
| 交付物 | 说明 || 发票识别系统.exe | 主程序,约300-500MB || main.py | Python源码 || admin_tool.py | 授权码生成工具 || generate_keys.py | 密钥对生成工具 || 使用说明 | 用户操作手册 |
>系统特点
– ✅ 完全离线,数据安全
– ✅ 一机一码授权,防扩散
– ✅ 支持图片、PDF、多页PDF
– ✅ 自动识别、查重、统计
– ✅ Excel导出带千分位、自动列宽
– ✅ 双击即用,无需安装Python
PART 3

结尾

这次开发从一个小小的想法开始:让发票处理变得更简单。我们遇到并解决了大量技术问题:OCR识别不准、PDF解析失败、中文路径乱码、打包后闪退、多页PDF处理……每一个问题都花了时间排查和修复。最终成果是一个开箱即用、完全离线、安全可靠的发票识别统计系统。
对于完全不懂技术的人来说,他们只需要:
1. 双击EXE
2. 输入授权码
3. 上传发票
4. 导出Excel
这就是我们这6个小时做的事情。





END


