 夜雨聆风
夜雨聆风





Ollama 实用案例(二)本地文档 RAG
很多团队第一次做 RAG,会先讨论向量数据库、检索框架、权限系统、知识库后台。结果几天过去,真正的问题还没回答:模型能不能从自己的文档里找到正确证据?
本地 RAG 的第一步不该是搭一套平台,而是做一个最小闭环:把文档切块,转成向量,用相似度找回片段,再让本地模型只基于片段回答。
Ollama 已经把这个闭环里最麻烦的两件事降到很低:本地运行大语言模型,本地生成 embeddings。几百篇 Markdown、会议纪要、项目文档,完全可以先用一个 Python 脚本跑起来。
RAG 的价值不在“接了向量库”,而在能不能把正确上下文送到模型面前,并让模型承认资料里没有答案。
先给结论
个人或小团队做本地文档问答,我建议先不要上复杂架构。
最小版本只需要四步:
- • 读取 .md .txt 文档。
- • 按较小片段切块。
- • 用 Ollama 的 embedding 模型把片段和问题都变成向量。
- • 用余弦相似度取 Top K,再把片段塞进本地聊天模型。
这个版本没有权限管理、没有增量索引、没有 rerank、没有向量数据库。但它足够回答一个更重要的问题:你的文档质量、切块方式和检索信号是否足以支撑问答。
共同底座:Ollama + 一个生成模型 + 一个 embedding 模型
先安装 Ollama,并确认本地 API 可用:
ollama pull qwen3:8bollama run qwen3:8b "用一句话解释 RAG"再拉一个 embedding 模型。Ollama 官方文档说明,embeddings 会把文本变成数值向量,可用于语义搜索、检索和 RAG;/api/embed 支持单条文本,也支持批量输入。
可以直接用官方推荐列表里的模型,例如:
ollama pull embeddinggemmapip install ollama numpy如果你已经习惯 nomic-embed-text,也可以继续使用:
ollama pull nomic-embed-text关键原则只有一个:索引文档和查询问题必须使用同一个 embedding 模型。
最小 RAG 流水线
RAG 不是魔法,它的链路很朴素。
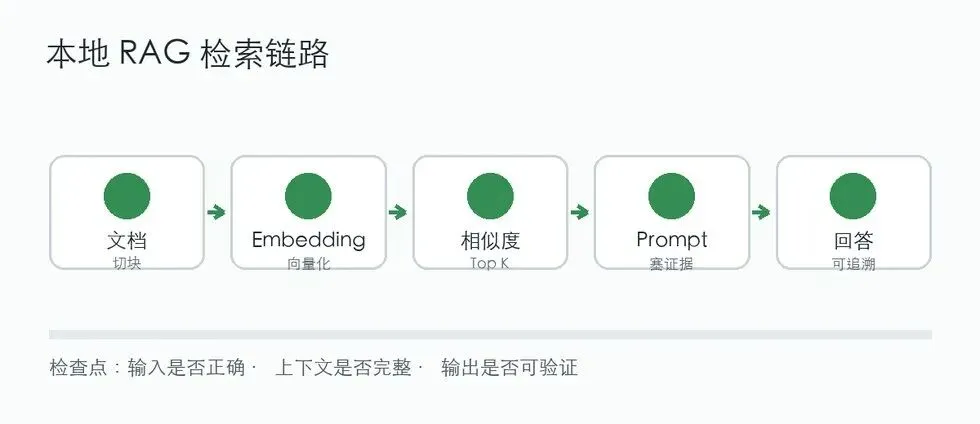
一份文档不会直接整篇塞给模型。你要先把它切成片段,例如每 300 到 500 个词一个 chunk。然后对每个 chunk 生成向量,得到一个矩阵。
用户提问时,也把问题生成向量。接着计算问题向量和每个文档片段向量的相似度,取最接近的几个片段作为上下文。
最后把这些片段放进 prompt,并加上一条硬约束:
只根据下面的上下文回答问题。如果上下文没有答案,请直接说“资料中没有找到答案”。
这条约束很重要。RAG 系统最危险的失败,不是回答慢,而是在没有证据时编一个听起来很像真的答案。
一个可以跑的最小版本
下面这段代码保留了核心逻辑:加载文档、切块、生成向量、相似度检索、调用本地模型回答。
from pathlib import Pathimport sysimport numpy as npimport ollamaEMBED_MODEL = "embeddinggemma"CHAT_MODEL = "qwen3:8b"CHUNK_WORDS = 400TOP_K = 3def load_chunks(folder: str) -> list[str]:chunks = []for path in Path(folder).rglob("*"):if path.suffix not in {".md", ".txt"}:continuewords = path.read_text(encoding="utf-8").split()for i in range(0, len(words), CHUNK_WORDS):chunk = " ".join(words[i:i + CHUNK_WORDS]).strip()if chunk:chunks.append(f"[{path.name}]\n{chunk}")return chunksdef embed(texts: list[str]) -> np.ndarray:resp = ollama.embed(model=EMBED_MODEL, input=texts)return np.array(resp["embeddings"], dtype=np.float32)def top_k(query_vec: np.ndarray, doc_mat: np.ndarray, k: int) -> list[int]:q = query_vec / (np.linalg.norm(query_vec) + 1e-8)d = doc_mat / (np.linalg.norm(doc_mat, axis=1, keepdims=True) + 1e-8)scores = d @ qreturn np.argsort(scores)[::-1][:k].tolist()def answer(query: str, chunks: list[str], doc_mat: np.ndarray) -> str:q_vec = embed([query])[0]picked = top_k(q_vec, doc_mat, TOP_K)context = "\n\n---\n\n".join(chunks[i] for i in picked)prompt = f"""只根据下面的上下文回答问题。如果上下文没有答案,请直接说“资料中没有找到答案”。上下文:{context}问题:{query}"""resp = ollama.chat(model=CHAT_MODEL,messages=[{"role": "user", "content": prompt}],)return resp["message"]["content"]if __name__ == "__main__":folder, query = sys.argv[1], sys.argv[2]chunks = load_chunks(folder)doc_mat = embed(chunks)print(answer(query, chunks, doc_mat))
运行方式:
python rag.py ~/Documents/notes "上次会议对定价策略做了什么决定?"这不是生产级代码,但它把 RAG 的关键部件都放在眼前了。你能清楚看到错误来自哪里:文档没读到、chunk 切坏了、embedding 不准、Top K 取错了,还是模型没有遵守上下文。
为什么先不用向量数据库
向量数据库当然有价值,但它解决的是规模化之后的问题。
当你只有几百个文档、几千个 chunk 时,NumPy 矩阵已经足够快。把所有向量放进内存,一次矩阵乘法就能得到相似度排序。这个阶段更该关注检索质量,而不是系统形态。
什么时候需要换成 sqlite-vec、LanceDB、Qdrant、Milvus 这类方案?
- • 文档量已经大到每次启动重新 embedding 很慢。
- • 需要持久化索引,而不是每次运行都重建。
- • 需要按项目、用户、权限、时间过滤。
- • 需要增量更新和删除。
- • 需要并发查询和服务化 API。
在那之前,一个脚本更适合学习和验证。
真正容易踩坑的地方
第一个坑是切块太粗。整篇文档一个向量,会把主题压成平均值;模型检索到的是“像这篇文档”,不是“回答这个问题的那几句话”。
第二个坑是切块太碎。每句话一个向量,语义上下文会断掉,模型拿到片段后不知道前因后果。
第三个坑是 prompt 不约束。没有“只根据上下文回答”的约束,本地模型很容易把训练知识和检索内容混在一起。
第四个坑是只看回答,不看证据。更好的做法是把命中的 chunk 文件名和片段一起打印出来。先检查检索对不对,再检查生成好不好。
如何评估效果
本地 RAG 的验收不需要复杂指标,先准备 20 个真实问题。
其中 10 个问题答案确实存在于文档里,5 个需要跨两个片段合并,5 个文档里没有答案。然后看三类结果:
- • 有答案的问题,是否命中正确片段。
- • 跨片段问题,是否能合并而不乱编。
- • 无答案问题,是否敢说找不到。
如果“无答案问题”经常被模型编出来,优先修 prompt 和检索展示;如果“有答案问题”经常找不到,优先修切块、embedding 模型和 Top K。
总结
本地 RAG 最值得学习的不是某个框架,而是检索增强的基本闭环。
Ollama 提供本地生成模型和 embedding 接口,NumPy 负责最小相似度检索,一个严格 prompt 负责把模型限制在证据范围内。这个组合不华丽,但足够让你理解 RAG 在真实项目中到底会坏在哪里。
先用最小脚本把自己的文档跑起来。等你能稳定回答真实问题,再决定要不要升级向量数据库、rerank、权限过滤和服务化架构。