 夜雨聆风
夜雨聆风





百度Unlimited-OCR长文档解析突破

百度 Unlimited-OCR
解决长文档解析的三大痛点
3B参数/500M激活 · 32K上下文一次推理数十页 · OmniDocBench SOTA 93.23%
2026年6月22日,百度开源了Unlimited-OCR。这个总参数仅3B、激活参数500M的模型,在标准32K上下文长度下,以单次前向传播完成了数十页文档的连续解析。它不是逐页处理再拼接,而是真正的一次推理从头读到尾。本文聚焦它解决了哪些实际痛点,以及这些痛点背后技术瓶颈被突破的方式。
痛点一:逐页解析割裂语义连贯性
传统OCR的”失忆式”工作模式
过去处理一份50页的PDF,标准流程是:模型识别第1页,结束,清空状态;识别第2页,结束,清空状态……如此循环50次。每一页都像一次重新开始,上一页的排版上下文、术语用法、段落衔接被完全丢弃。
这种For-loop范式依赖外部调度器把碎片结果拼接成完整文档。问题在于:跨页表格会被截断,页眉页脚重复出现却无法去重,脚注与正文关联丢失,多页图表的连续编号被打断。对于学术论文、法律合同、财务报告这类强结构化文档,这些缺陷直接影响解析质量。
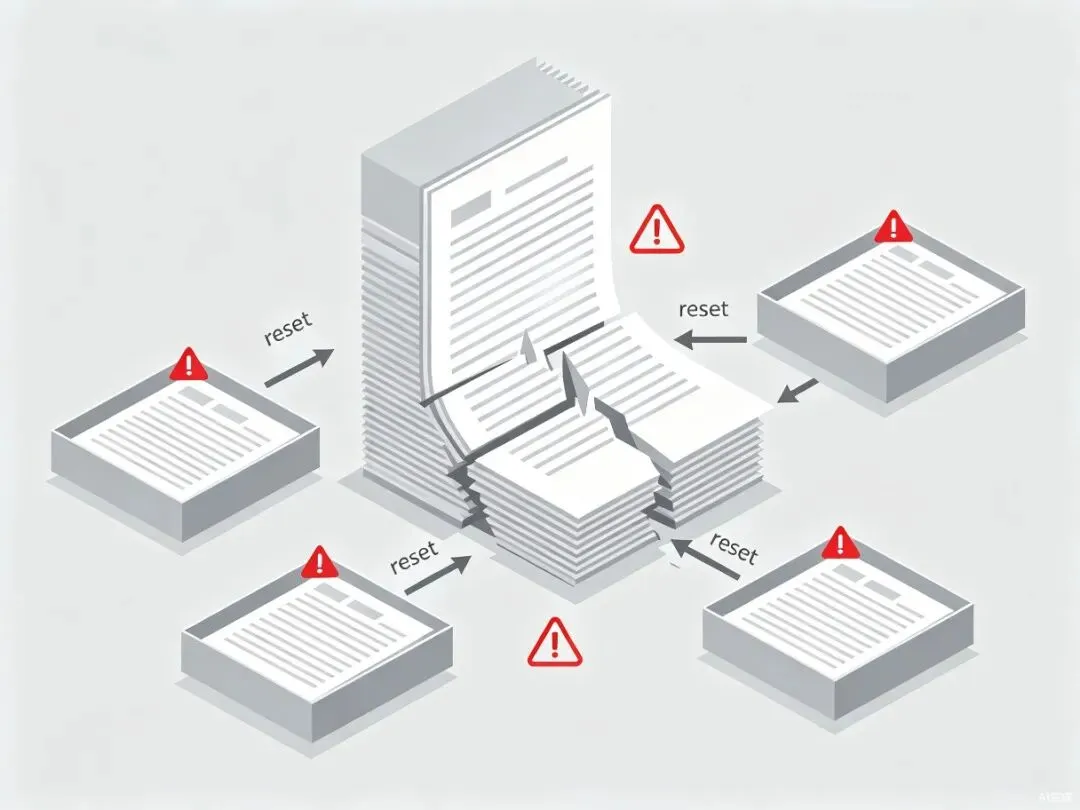
图1:传统OCR逐页处理模式——每页独立识别,上下文在页面间断裂
Unlimited-OCR的解法:单次前向传播
Unlimited OCR在32K上下文限制下,将数十页文档的视觉token一次性送入模型,通过单次前向传播完成全部页面的连续转录。模型在第1页建立的排版理解、术语记忆会自然延续到第40页,不存在页面间的状态重置。
在内部长文档测试集中,40页以上场景的编辑距离仍低于0.11,Distinct-35达到96.90%——这意味着模型在长程生成中没有陷入循环重复,文本多样性保持稳定。
痛点二:KV Cache无限膨胀吃满显存
输出越长,显存越爆
端到端OCR模型用LLM作解码器,每生成一个token都要把它的Key和Value存入KV Cache。假设视觉token与文本token压缩比为1:10,那么1万个视觉token(约20-30页文档)完整解码需要输出超过10万个token。KV Cache随输出长度线性增长,显存占用没有上限。
这不是优化问题,是架构层面的根本限制。在标准多头注意力(MHA)下,输出10万个token意味着每一步解码都要回看全部历史,注意力计算量随序列长度平方级增长。实际表现就是:处理到第10页时显存溢出,程序崩溃。

图2:KV Cache随输出长度线性增长——传统MHA的显存爆炸问题
R-SWA:将无限增长变成有界常数
百度提出的Reference Sliding Window Attention(R-SWA)将注意力分为两段。参考段包含视觉token和prompt,全局可见但不参与状态转移——视觉特征只编码一次,此后静止不变。解码滑动窗口宽度固定为128,每生成一个新token就驱逐最早的KV。
结果:解码侧KV Cache规模始终限定在固定容量内,不随输出长度增加。无论解析5页还是40页,显存占用恒定。这和人抄书时的认知状态一致——原书始终在眼前,但只记得最近写下的几个字。
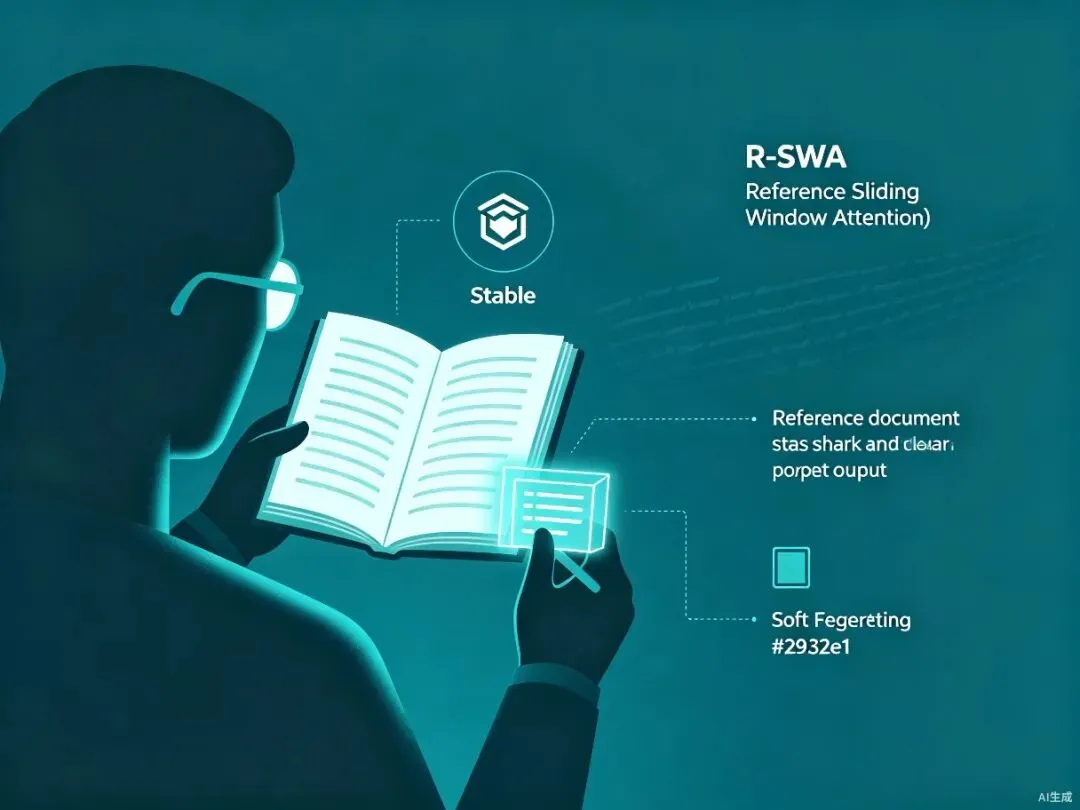
图3:R-SWA机制——参考段保持全局可见,解码窗口固定滑动,模拟人类抄书的软遗忘
痛点三:解码越深速度越慢
越往后越卡,长文档解析不可用
即使显存够用,速度问题依然致命。标准MHA下,每一步Flash Attention kernel的调用延迟随解码步数线性增加。处理到第20页时,单步延迟可能是第1页的数倍。更糟的是,当KV Cache长度跨越GPU内存对齐边界时,会出现延迟骤降的”悬崖效应”。
这意味着:长文档解析不仅慢,而且越往后越慢。对于需要批量处理数百份文档的企业场景,这种速度退化直接导致处理时间不可预测。
恒定延迟:从头到尾一样快
R-SWA将解码侧KV Cache限制在固定窗口内,每一步注意力计算量恒定。Flash Attention v3 kernel的调用延迟在整个解码过程中保持平稳,不存在随长度增长的趋势,也不会出现对齐边界的悬崖效应。
实测数据:输出6000个token时,DeepSeek OCR的吞吐量降至5822.87 TPS,Unlimited OCR维持在7847.71 TPS,领先35%。在单页场景下也快12.7%(5580 vs 4951 TPS)。
性能对比数据
93.23%
OmniDocBench v1.5
端到端SOTA
+35%
长序列推理
吞吐量提升
40+
单次推理
可解析页数
交互图表:Unlimited OCR吞吐量在6000 token时领先DeepSeek OCR 35%,且全程保持恒定
交互图表:Unlimited OCR在9类文档编辑距离上全面优于DeepSeek OCR
传统方案 vs Unlimited-OCR全景对比
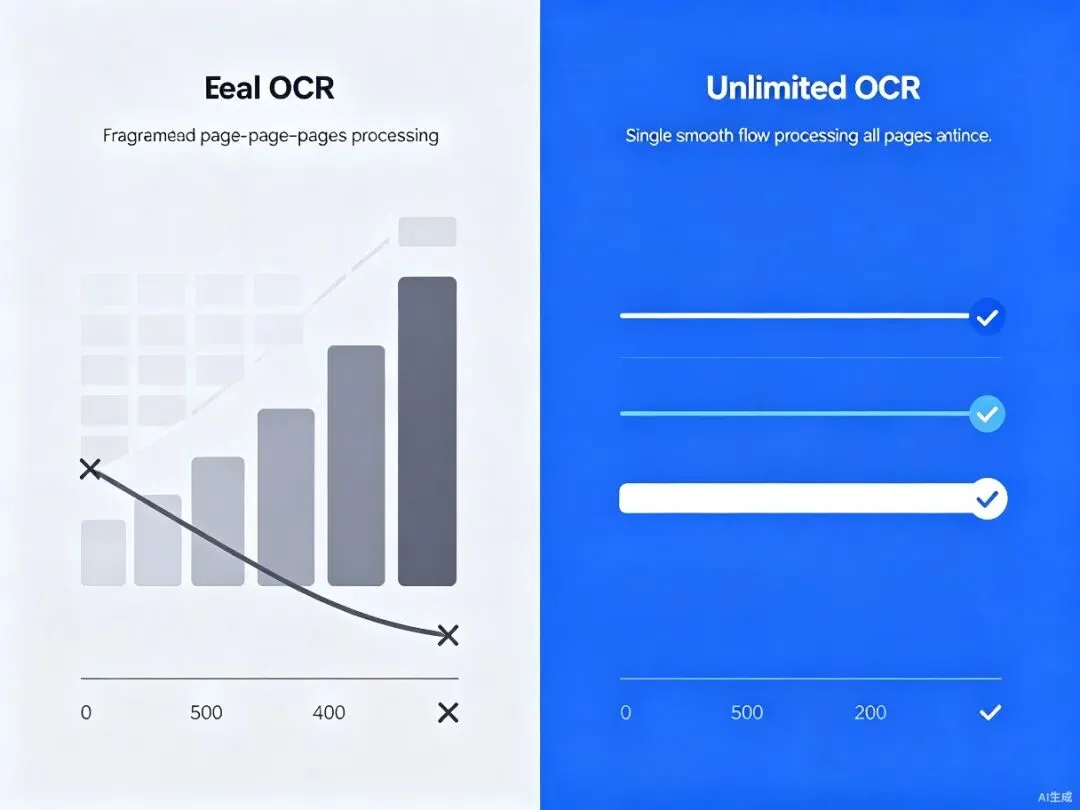
图6:传统逐页OCR(左)与Unlimited-OCR单次推理(右)的全景对比
| 维度 | 传统逐页OCR | Unlimited-OCR |
|---|---|---|
| 处理方式 | 逐页识别,外部拼接 | 单次前向传播,连续转录 |
| 跨页上下文 | 完全丢失 | 全程保持 |
| KV Cache | 随输出长度线性增长 | 恒定有界常数 |
| 解码延迟 | 随步数线性增加 | 全程恒定平稳 |
| 显存占用 | 持续增长,易溢出 | 固定不变 |
| 模型规模 | 视方案而定 | 3B总参数/500M激活 |
| OmniDocBench | DeepSeek OCR: 87.01% | 93.23%(+6.22) |
这些痛点解决后,能做什么

图7:长文档解析的典型应用场景
学术文献数字化
一篇博士论文动辄100-200页,包含大量公式、图表、参考文献。传统逐页解析会打断公式跨页续行、参考文献与正文的引用关系。Unlimited-OCR可以一次性处理数十页,保持全文结构完整。
法律合同批量处理
合同中的定义条款往往在第1页,而引用定义的条款可能在第30页。逐页解析无法建立这种远距离引用关系。单次推理模式下,模型在第30页生成文本时,第1页的定义条款仍在参考段中全局可见。
财务报告结构化提取
年报中的合并报表跨多页,附注与主表分属不同页面。连续解析能保持表格行列的对应关系,避免跨页表格被截断后无法还原的问题。
历史档案与古籍转录
古籍扫描件通常为连续卷轴或多页线装书,页面间存在内容衔接。逐页解析会丢失这种衔接关系,而单次推理可以保持文本流的连续性。
尚未解决的瓶颈
此外,40页以上场景的误识别主要来自PDF图像中小字体在1024×1024分辨率下难以辨认——这是输入分辨率的瓶颈,而非注意力机制的问题。R-SWA本身在长程推理中没有出现方向丢失或重复生成的退化。
值得关注的扩展方向:R-SWA是一种通用的解析注意力机制,论文明确指出它同样适用于ASR(自动语音识别)和翻译等具有参考输入的长程任务。将KV Cache从随解码长度无限增长转变为有界常数,这一思路的影响可能远超OCR领域。
快速上手
环境要求Python 3.12 + CUDA 12.9,模型已发布至HuggingFace和ModelScope:
import torch
model = AutoModel.from_pretrained(
‘baidu/Unlimited-OCR’,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
).eval().cuda()
# 多页文档一次性解析
model.infer_multi(tokenizer,
prompt='<image>Multi page parsing.’,
image_files=[‘page1.png’,’page2.png’,’page3.png’],
image_size=1024, max_length=32768)
GitHub: github.com/baidu/Unlimited-OCR
HuggingFace: huggingface.co/baidu/Unlimited-OCR
ModelScope: modelscope.cn/models/PaddlePaddle/Unlimited-OCR
论文: arxiv.org/abs/2606.23050
许可证: MIT