 夜雨聆风
夜雨聆风





Mistral OCR 4把文档识别卷疯了
AI 圈今天又被一个“看起来不大但很狠”的更新刷屏了:Mistral AI 发了 OCR 4,说白了就是让机器读 PDF、Word、PPT 的新一代识别模型。但重点不是“能读”,而是“读完之后开始理解结构”。
这波OCR 4不是简单的‘识别升级’,而是把文档理解从‘抄文字’推向‘拆结构’。对做知识库、做agent的人来说,后面数据入口会被重新洗一遍。
- 不仅能识别文本,还能判断标题、表格、公式、签名等“页面角色”
- 输出结构化块,而不是一整坨OCR文本
- 支持 170 种语言,小语种也被覆盖
- 盲测超过 600 份文档,72% 情况更受偏好
- 还能输出每个词或页面的置信度
- 价格:每 1000 页 $4,批处理 $2
- 已通过 API、Mistral Studio、Microsoft Foundry 提供
这次OCR 4到底在卷什么
它最“阴险”的地方在于,不只是把字识别出来,而是顺手把页面拆成结构块:哪里是标题、哪里是表格、哪里是公式、哪里是签名,全都分得明明白白。这一步对后面的搜索系统、AI agent 处理流程来说,等于直接把“前处理人工活”部分自动化了。
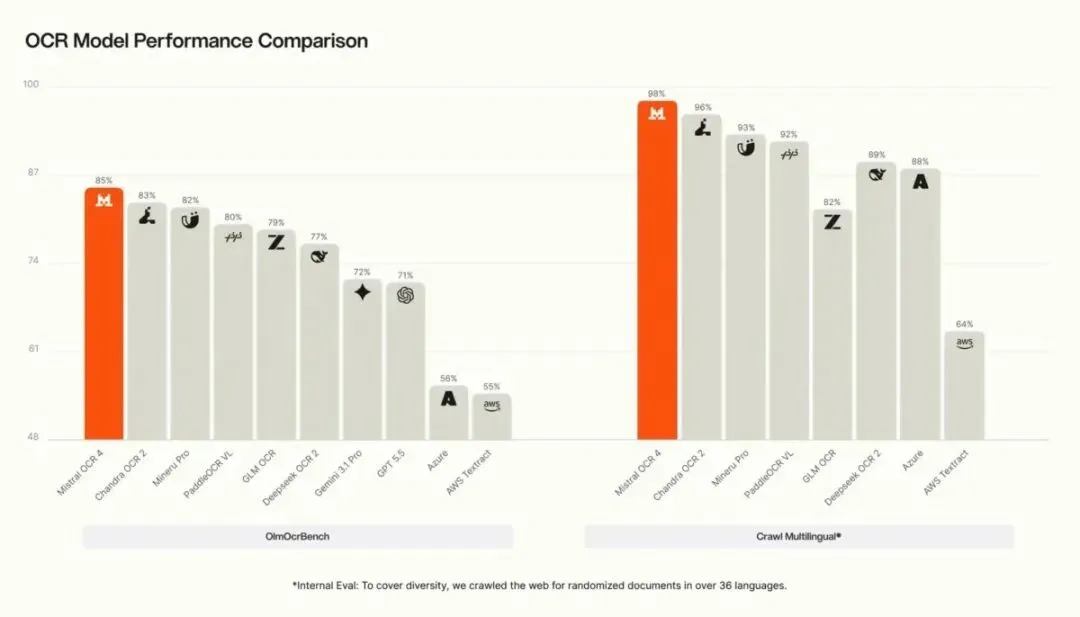
再加上置信度输出,其实已经在往“可控数据输入层”走了——你不再是盲用OCR,而是知道它“哪里不确定”。

如果只看数字,72% 的盲测偏好 + 170 种语言支持 + 每 1000 页 $4 的定价,很容易让人觉得它是“企业级文档入口工具”。但更关键的点其实是它开始做“结构化输出”——标题、表格、公式、签名都被拆开,还带置信度,这对做搜索、RAG、agent 工作流的人影响很直接。以后你喂进去的不再是“一坨文字”,而是带结构的页面块,等于前置清洗能力被模型接管了一部分。不过也别神化,盲测 72% 本质还是特定集合里的偏好胜率,真实业务里脏文档、复杂扫描件才是考验。
看完想聊两句?
你觉得下一步会不会轮到“所有OCR工具都被结构化模型替代”?
— 这些也值得一看 —
- ·Claude Fable 5 被蒸馏成开源模型:Qwable-v1 引爆争议
- ·Claude Fable 5开放了,但Anthropic还是踩着刹车
- ·GPT-5.5月订阅可能降价,OpenAI盯上Anthropic用户
想翻更多?点头像进公众号看历史