 夜雨聆风
夜雨聆风Agent 操作桌面系统的技术实现原理
概述
“让大模型操作整个桌面系统”并不是指模型直接接管鼠标、键盘或操作系统内核,而是通过一个由多个模块组成的代理系统完成:
感知当前桌面状态
理解用户目标并规划下一步动作
调用执行器将动作落到真实系统
再次观察执行结果
在反馈闭环中持续修正,直到任务完成、失败或被中止
本质上,这是一套 观察 -> 推理 -> 执行 -> 校验 的循环系统。
一、整体架构
一个完整的桌面操作 Agent,通常由以下几个层次组成:
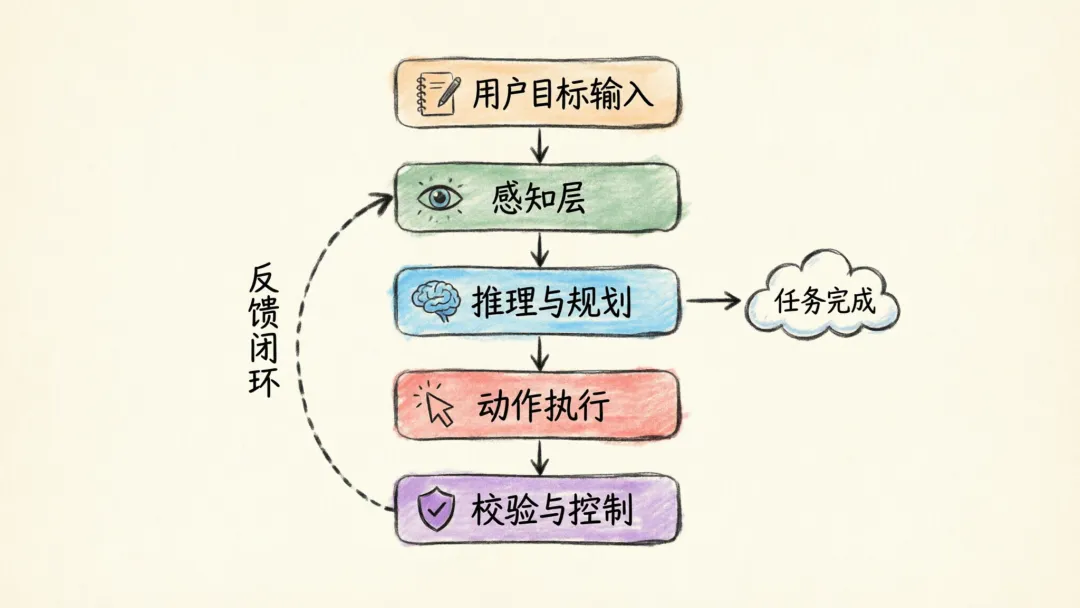
1. 用户目标输入层
负责接收用户任务,例如:
打开浏览器并访问某个网站
在系统设置中关闭 Wi-Fi
整理某个目录下的文件
打开 Excel 或表格软件并录入数据
输入可以是:
自然语言指令
结构化任务描述
带约束的执行策略
例如:
请打开系统设置,关闭 Wi-Fi,然后回到桌面。2. 感知层
负责收集当前桌面环境信息,让模型知道“电脑现在处于什么状态”。
3. 推理与规划层
负责把用户目标和当前状态结合起来,决定下一步应该做什么。
4. 动作执行层
负责把模型输出的动作转换成实际的系统操作。
5. 校验与控制层
负责检测动作是否成功、是否进入异常状态,以及是否需要重试、回滚或请求人工确认。
二、感知层:模型如何“看到”桌面
桌面 Agent 首先要解决的问题不是“怎么点”,而是“怎么知道当前桌面上有什么”。
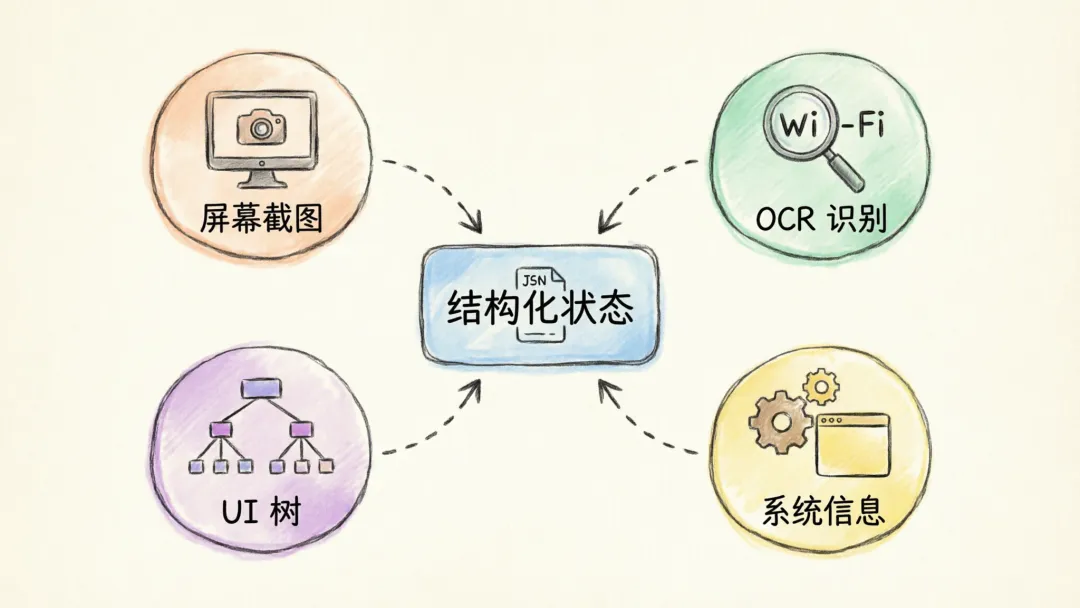
1. 屏幕截图
最基础的方式是周期性或按需获取屏幕截图,包括:
当前屏幕截图
多显示器截图
当前活动窗口截图
指定区域截图
截图是视觉模型的重要输入。模型可以通过图像理解识别:
按钮
输入框
菜单
对话框
图标
文本位置
优点:
通用性强
不依赖具体应用实现
缺点:
对分辨率、缩放、主题、语言敏感
有时只能“看见”,但无法直接知道控件的语义
2. OCR 文本识别
OCR 用于从截图中提取文字,例如:
“保存”
“继续”
“用户名”
“Wi-Fi”
OCR 的作用包括:
帮助模型定位界面文字
在没有 UI 树的情况下完成按钮匹配
将视觉内容补充为结构化文本
典型做法是将 OCR 结果表示为:
[ {"text": "Wi-Fi", "bbox": [720, 400, 80, 24]}, {"text": "关闭", "bbox": [810, 435, 52, 24]}]
3. Accessibility / UI Automation 树
工业级实现通常不会只依赖截图,而会优先读取系统和应用暴露的可访问性结构。
典型接口包括:
macOS: Accessibility API
Windows: UI Automation
Linux: AT-SPI
这些接口能够直接提供:
控件类型
控件名称
可编辑状态
是否可点击
窗口层级
元素坐标和边界框
例如:
{"role": "button","name": "Continue","enabled": true,"bounds": [540, 620, 120, 40]}
相对截图而言,UI 树有几个明显优势:
语义更强
定位更稳定
不容易被视觉样式变化干扰
但它也有限制:
某些应用暴露信息不完整
自绘控件可能不可访问
游戏、远程桌面、视频画面等场景很难读取
4. 系统上下文信息
除了图像和 UI 树,Agent 往往还会收集其他辅助状态,例如:
当前活动应用
当前窗口标题
打开的窗口列表
当前鼠标位置
剪贴板内容
当前输入法
文件系统状态
系统通知
这类信息可以降低模型推理难度,提高动作的可解释性和稳定性。
三、状态表示:如何把桌面转换成模型可理解的上下文
模型并不是直接面对“原始桌面”,而是面对一份整理后的环境描述。
常见状态对象包括以下内容:
{"goal": "关闭系统 Wi-Fi","active_app": "System Settings","window_title": "Wi-Fi","elements": [ {"role": "switch", "name": "Wi-Fi", "state": "on", "bounds": [790, 430, 44, 28]}, {"role": "button", "name": "Details", "bounds": [840, 430, 72, 28]} ],"ocr_blocks": [ {"text": "Wi-Fi", "bbox": [706, 432, 68, 22]} ],"history": ["opened System Settings","navigated to Network" ]}
一个好的状态表示通常满足几个目标:
对模型足够简洁,避免上下文过载
包含可操作元素,而不是只有原始像素
保留最近动作历史,便于判断是否卡住
保留任务目标与约束,便于决策
四、推理与规划层:模型如何决定下一步动作
1. 任务分解
当用户给出一个目标时,模型通常不会一次性规划全部步骤再机械执行,而是做短步推理。
例如任务:
打开系统设置,把 Wi-Fi 关掉。可能被拆成:
打开系统设置
找到 Wi-Fi 或网络页面
定位 Wi-Fi 开关
点击开关
验证当前状态是否为关闭
2. 单步决策
桌面环境变化大,因此实践中常见策略是“每轮只决定下一步或下一小段动作”。
也就是说,模型的核心职责通常是:
判断当前界面处于哪个阶段
推断下一步最合适的动作
说明动作依据
指出成功判据
例如输出:
{"thought": "当前已在系统设置的 Wi-Fi 页面,且开关状态为开启,下一步应点击开关关闭 Wi-Fi。","action": {"type": "click","target": "Wi-Fi toggle","x": 812,"y": 436 },"success_check": "点击后开关状态应变为 off,或页面出现 disconnected 状态"}
3. 为什么不用“长计划一次执行到底”
因为桌面系统具有强不确定性:
窗口可能被遮挡
应用响应可能变慢
弹窗可能临时出现
控件位置可能改变
不同设备的布局不同
因此更常见的工程方案是:
长目标由模型持有
短动作逐轮生成
每一步都重新观察和修正
这种方式更像闭环控制,而不是静态脚本。
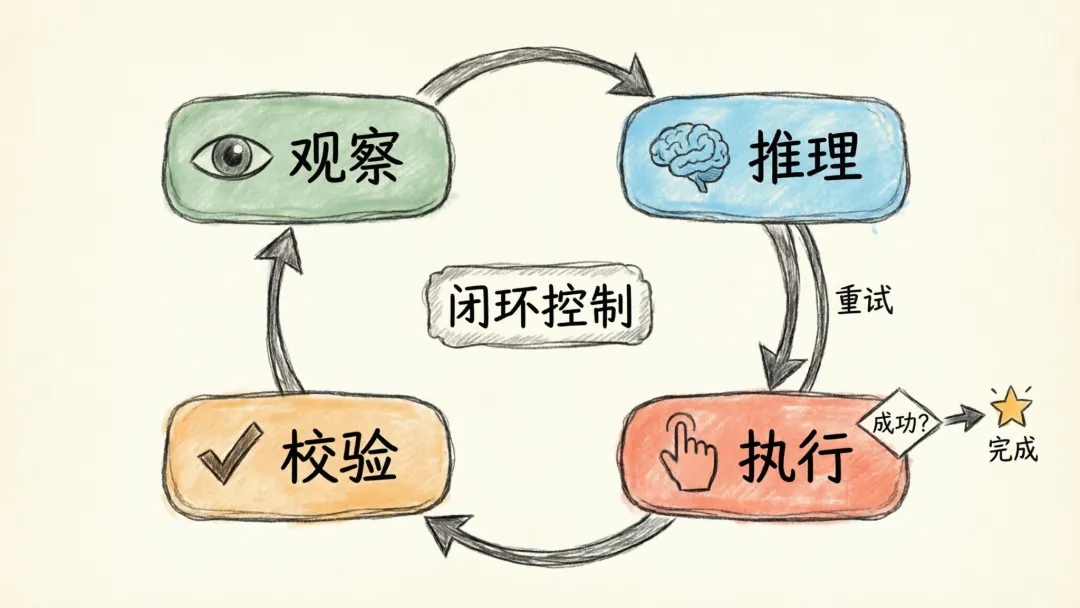
五、动作执行层:模型如何真正“操作”电脑
模型不会直接调用系统底层,而是输出结构化动作,由外部执行器负责落地。
1. 常见动作类型
执行器一般会提供一组标准原子动作:
move_mouse(x, y)click(x, y)double_click(x, y)right_click(x, y)drag(from_x, from_y, to_x, to_y)scroll(dx, dy)type_text(text)press_key(key)hotkey(keys[])wait(ms)launch_app(name)focus_window(title)
这些动作可以组合成复杂操作。
2. 结构化动作格式
模型输出通常不是自然语言,而是机器可执行的结构化结果,例如:
{"action": "hotkey","keys": ["cmd", "space"]}
或:
{"action": "type_text","text": "System Settings"}
或:
{"action": "click","x": 812,"y": 436,"reason": "toggle Wi-Fi switch"}
3. 坐标点击与语义点击
动作执行有两条主要路径:
路径 A:坐标驱动
直接点击某个屏幕坐标。
优点:
通用
几乎任何画面都能尝试操作
缺点:
对分辨率和布局敏感
容易点偏
遮挡时失效
路径 B:语义驱动
先通过 UI 树找到元素,再调用系统接口执行:
点击名为
Continue的按钮聚焦名为
Search的输入框读取名为
Wi-Fi的开关状态
优点:
更稳
更可解释
不依赖像素级定位
缺点:
依赖应用暴露 UI 自动化信息
工业系统通常采用混合策略:
优先 UI Automation / Accessibility
失败时回退到视觉定位和坐标点击
六、底层系统接口:不同操作系统如何支持自动化
1. macOS
常见底层能力包括:
Quartz Event Services: 注入鼠标和键盘事件
Accessibility API: 读取和操作 UI 元素
AppleScript / Shortcuts: 与部分应用进行高级交互
常见用途:
模拟鼠标点击和按键
获取当前窗口和控件信息
点击按钮、读取文本框内容
启动应用和切换窗口
2. Windows
常见底层能力包括:
SendInput: 注入键盘和鼠标事件
UI Automation: 读取和控制桌面应用控件
Win32 API / COM / PowerShell: 进行系统级和应用级操作
常见用途:
模拟输入与快捷键
查找窗口和控件
调用应用自动化接口
执行系统命令
3. Linux
常见底层能力包括:
X11 自动化接口
Wayland 相关自动化能力
AT-SPI: 可访问性树
桌面自动化工具,例如
xdotool(常见于 X11 环境)
Linux 的挑战在于桌面环境和显示协议较多,实现稳定性依赖具体发行版和窗口系统。
七、反馈闭环:为什么 Agent 不会只执行一次
桌面操作系统最关键的工程特征是闭环执行。
标准循环通常如下:
观察当前屏幕和环境
推理下一步动作
执行动作
再次观察
判断是否成功
成功则继续,失败则重试、改策或中止
例如点击“保存”后,系统可能出现几种结果:
保存成功并关闭弹窗
按钮未点中,界面无变化
出现权限确认框
网络异常导致失败提示
如果没有反馈闭环,系统无法区分”已完成”和”动作失效”。
因此成熟 Agent 通常具备:
执行后等待策略
成功条件检测
失败原因判断
自动重试
多路径备选方案
八、为什么现实系统往往不是“纯视觉点击”
很多演示看起来像“模型看着屏幕点鼠标”,但真正可用的系统通常会混合多种能力。
1. 视觉通道
用于处理:
无结构界面
截图可见但无 UI 树的内容
自绘控件
图标和复杂布局
2. UI 自动化通道
用于处理:
常规桌面应用
表单输入
按钮点击
开关读取
窗口和菜单控制
3. 系统工具 / 命令通道
用于处理:
直接打开应用
文件读写
执行 shell 命令
调用系统设置接口
获取更精确的状态信息
因此更准确的描述是:
桌面 Agent 通常是“视觉理解 + UI 自动化 + 系统工具调用”的组合系统。
这比纯 RPA 更灵活,也比纯视觉点击更稳定。
九、典型执行流程示例
以下以“关闭 Wi-Fi”为例,展示一个简化执行流程。
1. 用户输入
打开系统设置,把 Wi-Fi 关掉。2. 初始感知
系统获取:
当前桌面截图
活动应用列表
UI 元素树
3. 模型第一轮决策
若未打开系统设置,则输出:
{"action": "launch_app", "name": "System Settings"}4. 再次观察
系统检测到系统设置已打开,但页面还未切到 Wi-Fi。
5. 模型第二轮决策
输出:
{"action": "click", "target": "Wi-Fi sidebar item"}或回退为坐标点击:
{"action": "click", "x": 126, "y": 244}6. 第三轮决策
识别出 Wi-Fi 开关状态为 on,执行:
{"action": "click", "target": "Wi-Fi toggle"}7. 校验
系统再次读取 UI 状态,确认开关变为 off。
8. 任务完成
记录执行日志并结束。
十、关键工程难点
1. 界面变化和泛化问题
不同应用、系统版本、语言环境、缩放比例都会导致:
元素位置不同
文本不同
图标不同
流程不同
这使得基于固定脚本或固定坐标的方案非常脆弱。
2. UI 语义缺失
有些控件视觉上明显,但系统无法通过 UI Automation 获取它们的语义信息。
例如:
自绘按钮
Canvas 渲染区域
游戏界面
远程桌面画面
这类场景必须退回视觉识别。
3. 多步骤误差累积
桌面任务往往跨多个页面和应用,一旦某一步失败,后面的动作都可能失效。
因此系统必须有:
阶段识别
卡住检测
路径纠偏
超时机制
4. 弹窗和系统级遮挡
系统权限弹窗、错误弹窗、通知、自动更新提示都可能打断原流程。
Agent 必须能够:
识别异常弹窗
暂停原计划
进入异常处理分支
5. 高风险动作不可完全自动放行
以下动作通常具有高风险:
删除文件
转账支付
发送邮件或消息
修改系统权限
安装软件
这要求系统具备显式风险分级和人工确认机制。
十一、安全设计
一个能操作桌面的 Agent,如果没有安全约束,风险会非常高。成熟实现通常会加入以下机制。
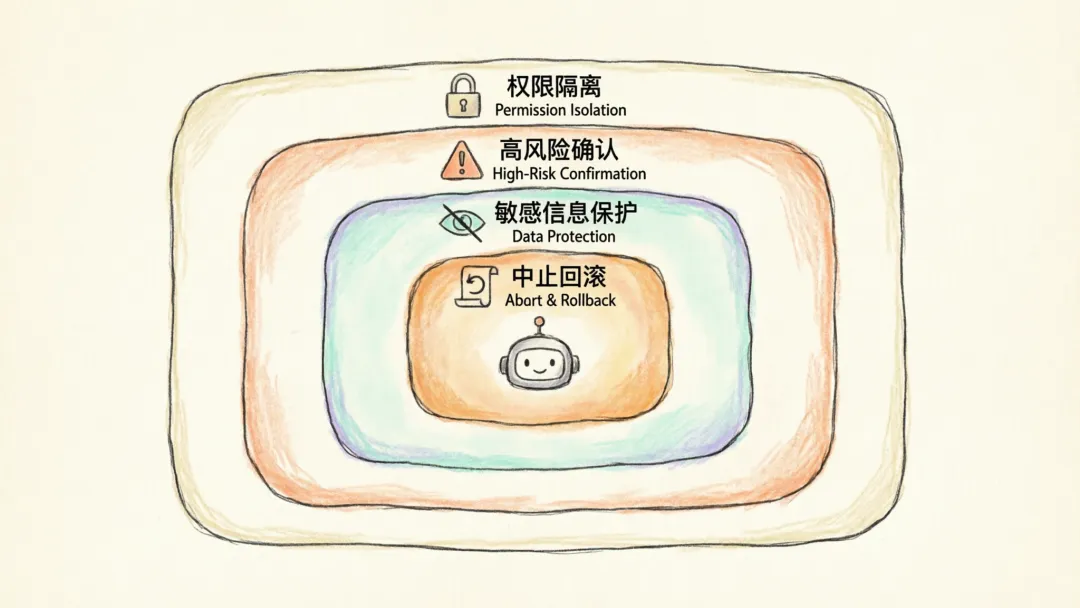
1. 权限隔离
限制可访问的目录
限制可启动的应用
限制可访问的网站
将执行环境放入沙箱或虚拟机
2. 高风险确认
在以下动作前要求人工确认:
付款
删除
发送
安装
修改账户信息
3. 敏感信息保护
对敏感区域进行:
打码
不截图
不送入模型
不记录日志
例如:
密码框
验证码
私钥
金融账号信息
4. 审计与回放
记录:
每一步观察结果
每一步动作
每次模型决策
每次错误和重试
这样便于:
排查故障
事后审计
复现实验
5. 中止与回滚
系统应支持:
一键停止
超时自动停止
连续失败自动中止
对可逆操作进行回滚
十二、最小可用实现方案
如果要做一个简化版桌面 Agent,通常至少包括以下组件:
1. 状态采集器
负责:
截图
OCR
读取活动窗口
读取可访问性树
2. 决策器
负责将:
用户目标
当前状态
历史动作
送入模型,获得下一步动作。
3. 执行器
负责:
点击
输入
快捷键
启动应用
滚动
4. 校验器
负责判断:
动作是否生效
是否进入错误状态
是否需要重试
5. 日志系统
负责保存:
截图
动作
推理摘要
错误信息
6. 安全网关
负责阻止高风险动作直接执行。
十三、与传统 RPA 的区别
桌面 Agent 与传统 RPA 相似,但并不相同。
传统 RPA 的特点
依赖固定流程
依赖固定坐标或固定选择器
对环境变化敏感
适合高重复、低变化任务
大模型驱动 Agent 的特点
能理解自然语言目标
能在一定程度上适应界面变化
能根据观察结果临时调整策略
更适合半结构化、变化较多的任务
但这并不意味着大模型系统完全取代 RPA。现实中常见的是二者融合:
稳定流程仍用规则和脚本
不确定环节交给模型决策
十四、一个简化的伪代码示例
goal = "打开系统设置,关闭 Wi-Fi"history = []whileTrue:state = observe_desktop()decision = model_decide(goal=goal, state=state, history=history)ifdecision["type"] == "finish":breakifis_high_risk(decision):require_human_confirmation(decision)result = execute_action(decision)history.append({"decision": decision,"result": result })ifshould_abort(history):break
这个伪代码反映了桌面 Agent 的核心结构:
观察
决策
执行
记录
判断是否继续
十五、总结
操作整个桌面系统的技术实现原理,可以概括为以下几点:
通过截图、OCR、可访问性树和系统状态感知当前桌面环境
将环境整理成模型可理解的结构化上下文
由大模型根据任务目标做短步推理和动作规划
通过系统自动化接口或工具执行真实操作
在反馈闭环中不断校验、修正和重试
通过权限控制、人工确认和日志审计保证安全性
因此,桌面操作 Agent 不是“模型直接操控电脑”,而是一个以大模型为决策核心、以系统自动化能力为执行基础、以反馈闭环为稳定机制的复合系统。
如果进一步抽象成一句话:
桌面 Agent 的本质,是把“看懂界面、理解目标、生成动作、执行操作、验证结果”连接成一个持续闭环的系统。
