 夜雨聆风
夜雨聆风公众号:AIGC 生活实验室
简介:探索 AI 如何改变工作与生活
作者:皮皮鲁呀鲁西西

2026 年 3 月 5 日,OpenAI 发布了 GPT-5.4。
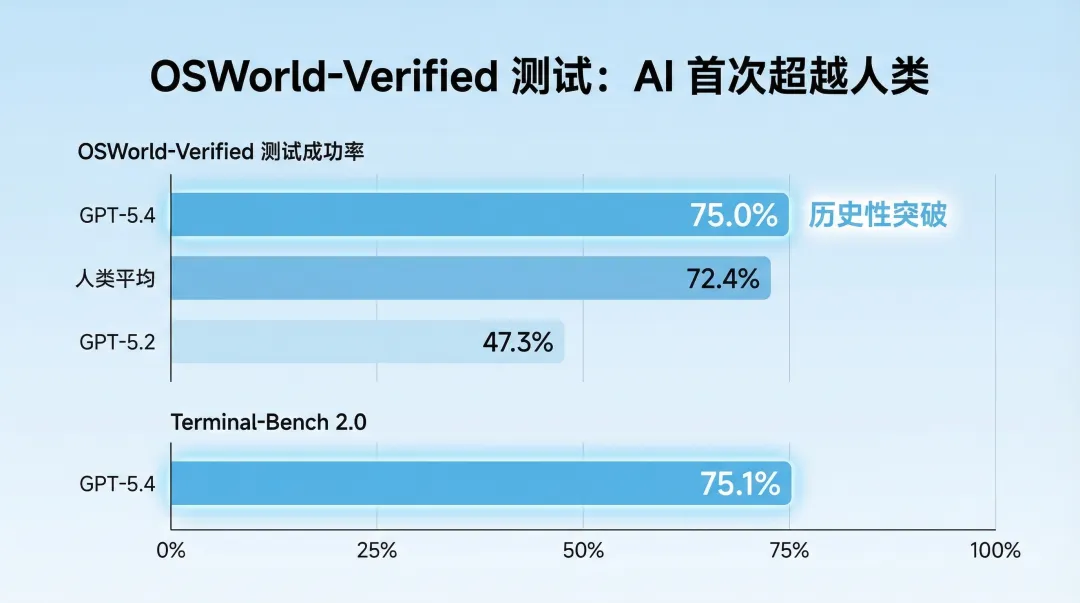
这次发布有个数据挺意外的:在 OSWorld-Verified 基准测试里,GPT-5.4 操作电脑的成功率达到 75%,而人类平均水平是 72.4%。这是 AI 首次在真实桌面环境操作中超越人类。
但翻了一圈社区反馈,发现实际使用中的问题远比官方数据复杂。
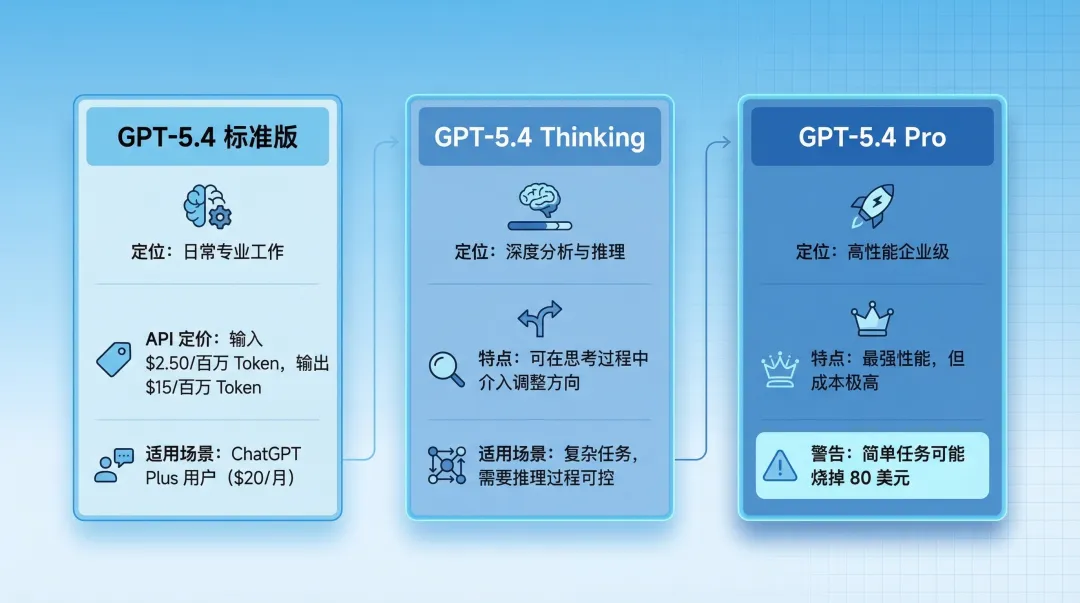
1. 三个版本
GPT-5.4 这次发布了三个版本,定位完全不同。
GPT-5.4 标准版:面向日常专业工作,API 定价是输入 $2.50/百万 Token,输出 $15/百万 Token。这个价格大约是 Claude Opus 4.6($5/$25)的一半,性价比不错。ChatGPT Plus 用户($20/月)可以直接用。
GPT-5.4 Thinking:深度分析与推理版本,最大的亮点是可以在模型思考过程中介入调整方向。Medium 上有用户评价说:不用等它跑完再重新来,可以在思考过程中直接纠正方向。这对复杂任务的效率提升很明显。
GPT-5.4 Pro:高性能企业级版本,适合复杂任务。但这个版本有个坑 - 凤凰网上有用户吐槽:我只是发了一句 Hi,它就认真推理了 5 分钟,直接烧掉 80 美元。日常轻量任务根本不敢用 Pro 版。
说实话,选哪个版本得看具体场景。日常任务用标准版就够了,复杂任务再切换 Pro 版,不然成本会失控。
2. Computer Use:首次超越人类的 AI
GPT-5.4 最大的技术突破是原生计算机使用能力(Computer Use)。
这不是简单的聊天升级,而是首个能直接操控电脑、跨软件执行工作流的 AI Agent。技术原理是通过屏幕截图理解界面,生成鼠标点击和键盘输入指令。它有两种操作方式:一种是通过 Playwright 等库编写代码操作计算机,另一种是直接从屏幕截图发出鼠标和键盘命令。
性能数据确实亮眼:
有用户实测后评价:GPT-5.4 在 OSWorld-Verified 基准测试里,它操作电脑的成功率达到 75%,连人类平均水平的 72.4% 都被它超了。
但实际使用中问题不少。
NiceKate AI 的实测视频里提到:Computer Use 功能在实际使用中还不够稳定,UI 自适应有问题,有时会把不该出现的提示语直接写进页面。图像理解能力还需要追赶 Gemini。
跨软件操作时 UI 自适应不稳定,可能生成错误指令。所以在关键任务中,还是得增加人工验证环节,不要完全依赖自动化。
3. 百万上下文的真相
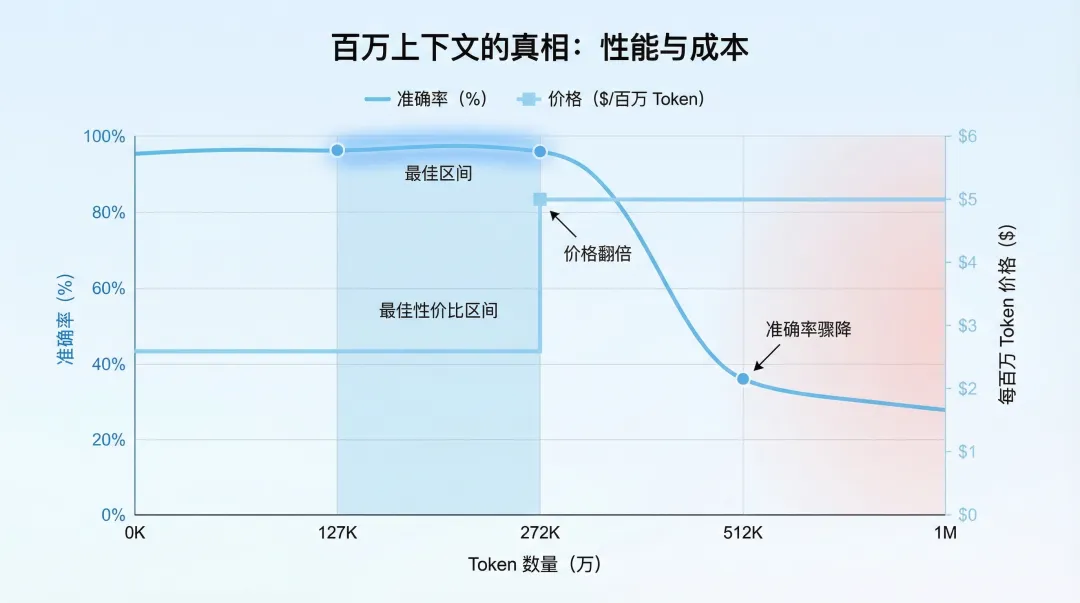
GPT-5.4 支持 105 万 Token 的上下文窗口,这是 OpenAI 迄今最大的。
听起来很美,但有个关键细节:272K tokens 是定价分界点。
更关键的是性能问题。API 易技术博客的测试数据显示:
知乎上有用户评价:百万上下文听起来很美,但超过 272K 后价格翻倍,而且准确率在 512K 以上会骤降至 36%。能用不等于好用,实际最佳区间只有 127K-272K。
所以实际使用时,控制在 127K-272K 区间是性价比最优的选择。超过这个范围,要么价格翻倍,要么准确率骤降,都不划算。
4. 社区反馈汇总
基于社区反馈和实测数据,整理了几个典型场景的使用感受。
代码重构和大型项目分析
百万上下文窗口让开发者可以一次性处理整个代码库,不再需要分段处理。知乎上有开发者评价:GPT-5.4 的百万上下文窗口让我可以一次性处理整个代码库,不再需要分段处理。这对大型项目的重构和分析太有用了。
在电子表格建模任务中,GPT-5.4 的得分从 68.4% 提升至 87.3%。爱范儿的评测数据显示:GPT-5.4 在 GDPval 测试中取得 83% 的胜率,意味着十次对比中有八次以上,行业专业人士认为 AI 的产出达到或超过了人类同行水准。
这个提升是质的飞跃。
跨软件自动化工作流
从 Excel 提取数据、生成 PPT、发送邮件,GPT-5.4 通过 Computer Use 可以跨软件执行完整流程。官方演示的 OSWorld-Verified 测试成功率是 75%,超越人类 72.4%。
但实际使用中,UI 自适应问题会导致操作失败。所以在关键任务中,还是得增加人工验证环节。
Tool Search 功能的成本优势
Tool Search 功能让 Token 使用减少了 47%。DEV Community 上有开发者评价:Tool Search 功能让 Token 使用减少了 47%,这对我们这种高频调用 API 的团队来说,成本直接降了一半。
这个功能的技术原理是:模型接收轻量级工具列表,按需查找完整工具定义,避免在每次请求中加载所有工具定义。在工具密集型工作流中,效率提升很明显。
推理能力的过度思考问题
GPT-5.4 的推理能力确实更强了,但有时候会过度思考。DEV Community 上有用户反馈:GPT-5.4 的推理能力确实更强了,但有时候会过度思考。简单任务也要推理很久,反而降低了效率。需要手动调整 reasoning effort。
GPT-5.4 提供了四种推理模式:
简单任务用 none 或 low 模式就够了,不然会浪费时间和成本。
5. 三个必须知道的坑
坑 1:GPT-5.4 Pro 的成本失控
Pro 版会对简单任务进行深度推理,导致成本暴涨。凤凰网上有用户反馈:GPT-5.4 Pro 太贵了!我只是发了一句 Hi,它就认真推理了 5 分钟,直接烧掉 80 美元。
解决方案:日常任务使用标准版,只在复杂任务时切换 Pro 版。
坑 2:百万上下文的性能陷阱
超过 272K 后价格翻倍,512K 以上准确率骤降至 36%。API 易技术博客的测试数据显示:虽然支持 105 万 Token,但超过 272K 后价格翻倍,512K 以上准确率骤降至 36%。
解决方案:控制在 127K-272K 区间使用,这是性价比最优区间。
坑 3:Computer Use 的 UI 适配问题
跨软件操作时 UI 自适应不稳定,可能生成错误指令。NiceKate AI 的实测视频里提到:Computer Use 功能在实际使用中还不够稳定,UI 自适应有问题,有时会把不该出现的提示语直接写进页面。
解决方案:在关键任务中增加人工验证环节,不要完全依赖自动化。
6. 值得关注的争议
OpenAI 与美国国防部的合作引发了不少争议。
Gizmodo 的报道指出:OpenAI 和美国国防部的合作让很多用户流失,Anthropic 拒绝了国防部合同反而被列为供应链风险。这种政治因素影响了用户对 GPT-5.4 的信任。
另一个争议是:GPT-5.4 是否真的超越了人类专家?
正方观点:OSWorld-Verified 测试中 GPT-5.4 达到 75%,超越人类 72.4%,这是客观数据。
反方观点:基准测试不等于真实工作场景,83% 的 GDPval 胜率是在特定任务下的表现,不代表全面超越。DEV Community 上有用户质疑:基准测试不等于真实工作场景,83% 的 GDPval 胜率是在特定任务下的表现,不代表全面超越。
说实话,这个争议短期内不会有定论。但从实际使用来看,GPT-5.4 在专业工作能力上确实有质的提升。
7. 适合谁?不适合谁?
强烈推荐:
谨慎使用:
写在最后
GPT-5.4 的发布标志着 AI 从辅助工具到数字员工的转变。
首次在计算机操作任务上超越人类,这个突破的意义不仅仅是数字上的领先,而是 AI 开始具备真正的执行能力。但实际使用中的成本陷阱、性能边界、UI 适配问题,远比官方数据复杂。
如果这篇文章帮到了你,点个在看👀吧,下次再见
AIGC 生活实验室
📮 投稿/合作:egretss.bai.it@gmail.com
💬 交流群:回复加群
✍️ 作者:皮皮鲁呀鲁西西
🚀 关注我,一起探索技术的更多可能
