夜雨聆风
夜雨聆风

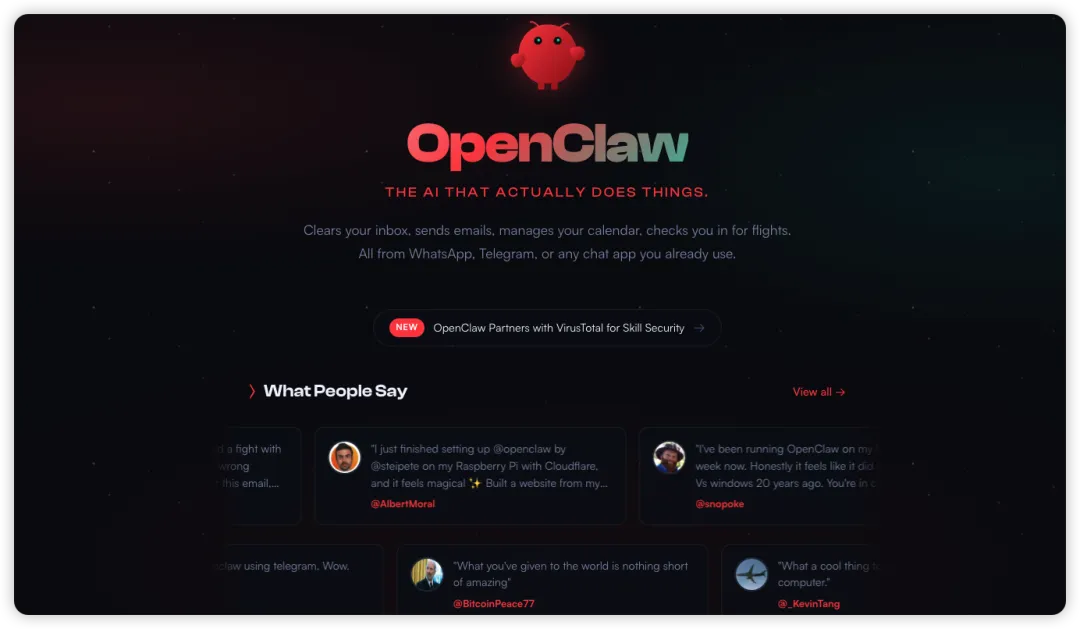
最近一段时间,OpenClaw 在技术圈热度很高。它被描述为“真正会做事的 AI 助手”——不只是聊天,而是可以接入消息平台、日历、文件、终端与各种技能系统,像一个 24 小时在线的个人代理,替你处理实际任务。官方当前推荐的安装方式,就是在本地设备上通过 CLI 完成安装与引导配置,并以常驻服务形式运行。
一旦一个 AI 代理真的开始“做事”,它所获得的权限、接触的数据和可能造成的后果,就不再是普通聊天机器人那一层级了。
把文献筛选、摘要提取、研究笔记归档串起来;
把科研日程、开会提醒、任务分发整合到一个消息入口;
把知识库、常用提示词、项目模版、写作工作流做成长期可调用的技能;
在不打开电脑界面的情况下,通过消息渠道调用本地助手完成某些重复性任务。


>大多数医学/护理科研工作者,并没有“立刻在个人主力电脑本地部署 OpenClaw”的必要。
稳定的文本生成与整理;
可验证的文献支持;
对结构化任务的批处理;
对科研流程的轻度自动化。
未发表数据;
患者相关资料或脱敏前原始表;
审稿意见与回复草稿;
基金申请书;
通讯作者往来邮件;
统计脚本、项目文件、账号凭证。
本身有较强技术背景,能理解网络、权限、隔离和日志;
愿意把它放在单独设备、单独账号或容器环境中;
需求确实是“长期、多步骤、跨工具”的自动化,而不是偶尔问几个科研问题。
读错文件;
调错命令;
访问了不该访问的账号;
把不该发送的内容发了出去;
在不该自动化的地方自动化。


能访问患者相关资料;
能读取邮件、日历和文档;
能连接多个平台账号;
能调用命令和技能;
能把处理结果再发送出去;


>对于医学/护理科研工作者,OpenClaw 值得关注,但不建议轻率地在主力科研电脑上直接本地部署。
构建个人知识工作流实验环境;
搭建与消息平台联动的科研任务助手;
做科研团队内部自动化原型验证;
在严格隔离条件下测试“AI 代理如何接管部分重复任务”。
不要装在主力科研环境把它部署在单独机器、单独用户账户,或最少也要在隔离容器/虚拟环境中运行。微软公开建议也是“仅在隔离环境中使用”。 不要给它接触真实敏感数据未发表数据库、患者原始资料、带身份信息的文件、真实邮箱主账户、核心项目盘,同一阶段都不应开放给它。 不要把私人常用账号直接接进去优先使用专用测试账号、专用 API key、专用消息通道。微软特别提到不要让其接触“非专用凭证”。 版本必须保持最新至少应确认已升级到修复近期高危问题的版本。公开报道提到,ClawJacked 相关修复要求升级到 2026.2.25 或更高。 只使用官方安装路径与可信来源官方文档推荐通过官方安装脚本或官方 npm 包安装;同时应警惕第三方镜像、所谓“一键整合版”、伪 GitHub 仓库和假安装包。 把它当“高风险自动化系统”,不是“普通科研软件”
你缺的是不是代理,而是流程设计。 很多低效并不是因为没有 AI,而是因为检索、提取、统计、写作、归档这些环节本来就没被设计清楚。 你需要的是可审计、可验证、可回退的自动化。 科研不是短视频剪辑,也不是娱乐化试玩。它对正确性、可追溯性和边界控制有更高要求。 在数据敏感的科研环境里,权限往往比能力更重要。 一个“能做很多事”的系统,并不必然适合“应该做什么都要留下依据”的医学科研场景。


>把 OpenClaw 当作值得观察和小范围试验的前沿工具,而不是当前阶段医学/护理科研者的默认基础设施。 对于绝大多数人,真正更优先的仍然是: 构建稳定的文献检索—数据整理—统计分析—论文写作工作流,再在明确边界的前提下,引入局部、可控的 AI 自动化。