 夜雨聆风
夜雨聆风OpenClaw的火爆程度, 我无需啰嗦。
作为一名AI市场从业人员,我决定从两个维度来解剖这个现象:首先、用户客观数据还原它在C端落地真相,再分享我自己21天高频使用的真实感悟。
OpenClaw C端落地的客观数据
一、为什么是OpenClaw,不是Claude Code?
很多人会问:OpenClaw能做到的,Claude Code基本都能做到。为什么前者在C端"爆火",后者却主要停留在工程圈?
原因1: 入口差异决定人群差异
Claude Code的入口是终端和IDE——这是工程师的领地。而OpenClaw将Agent深度嵌入了IM工具、代码编辑器、企业IM等用户每天都在打开的工作场景中。
用户不再需要"特地"打开代码编辑器,常用入口本成了Agent的操作台。这让AI真正承担起需求→规划→执行→反馈的闭环,而不仅仅是问答。
原因2: 场景覆盖的维度差异
从场景对比来看:
Claude Code: 自动改造大型代码库、清理技术债务、多Agent协作写代码——核心是"替你写代码"
OpenClaw: 销售营销自动化(从600美元SDR成本降到250美元)、社媒监控、7×24服务器巡检、个人日程管理——核心是"替你更多干活"
OpenClaw对非程序员的直观价值远大于"帮你refactor代码",这让它容易形成跨圈层传播:从开发者扩散到运营、销售、自媒体、投资等大量白领群体。
原因3: 个人主权+开源叙事",推波助澜
OpenClaw被视作"个人主权AI"与"反大厂垄断"的载体——可本地部署、完全掌控本地数据、MIT许可证意味着永久可fork。这激起公众层面"技术主权"的情绪价值。
相比之下,Claude Code是闭源的,更多是"效率工具"定位,没法公众层面引起情绪共鸣。
原因4: 中国市场的"一键云养虾",是关键推动力
中文文档访问量远超其他语言总和;腾讯云"一键部署"、阿里云组合套餐、KimiClaw、MaxClaw等产品将复杂部署打包为"云端订阅服务";线下"排队装龙虾"场景在各城市出现。
这些共同构成了"龙虾养成经济",将OpenClaw从开发者圈层推向普通C端。而Claude Code缺少类似的本土化推动,在中国大众舆论中热度明显落后。
二、对于一个中国普通用户:使用门槛真的降低了吗?
我这里说的"中国普通用户",是指没有技术背景,但是受过教育,至少能借助工具阅读OpenClaw英文技术文档的人。 其次,这里需要区分"技术部署门槛"和"使用场景门槛"。
原生OpenClaw的部署门槛并不低
对于完全无技术背景的普通用户,原生部署至少要跨过4道关键门槛:
硬件/环境门槛: 需要至少准备一台非工作电脑,有2GB内存的云服务器或常在线电脑
一键安装脚本执行门槛: 理解"脚本""shell""权限"本身就是心智门槛
模型API Key配置门槛: 复制Key时的任何字符错误都会导致失败
网络与安全配置门槛: 开放端口、防火墙放行、IM回调配置等
任何一步出错都很难自诊断。
但中国厂商的"一键部署"彻底改变了游戏规则
KimiClaw、MaxClaw、腾讯云/阿里云一键脚本将服务器购买、Docker安装、镜像拉取、端口放行等步骤统一打包,用一条脚本命令完成。
在这种形态下,普通用户的门槛只剩2道:
完成订阅或购买套餐(注册/支付)
跟随图形化或中文向导完成基础配置
这已经接近开通一个普通SaaS账户的难度。中国厂商在"一键部署OpenClaw"上已经形成了从IaaS到PaaS/SaaS的完整梯度,这对C端普及的推动作用非常显著。
三、用户的日常使用成本:从免费到烧钱
根据公开数据和社区案例,典型月度成本分层如下:
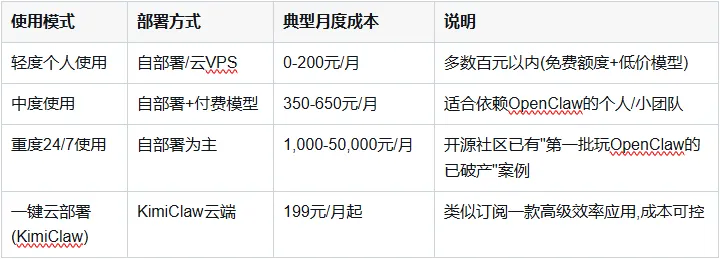
"只想尝鲜、偶尔用": 依靠免费额度+低价模型,成本可压在0-20美元/月
"每天真要干活": 选择国内包月模型+轻量云服务器,合理区间在20-50美元/月(约150-350元)
"想让它7×24接管大量业务": 必须有能力成本优化,否则很容易进入"API劝退"状态
四、真实用户规模: 装机量现象级, 但重度使用者比例很低
粗略估计:
部署/安装过的人:30-60万(全球)
过去一周/一月仍在使用的:10万
重度用户(每天/每周用OpenClaw干活):几万级别

简单总结:
中国是绝对主战场:不论从用户规模还是厂商参与程度,中国已经成为OS Agent形态的全球实验场
稳定使用率约在1/3(20万人以内),重度用户仅万级
对在探索C端AGI业务的启示
OpenClaw引爆的情绪是高昂的,"装机量"是现象级的,但稳定和重度使用比例真的不高。真正的机会在于为"想用但不会折腾的人"提供安全可控的托管版Agent产品——既要继承OpenClaw的OS Agent能力和IM入口优势,又要解决成本、安全、可控性与门槛问题。
第二部分:我用OpenClaw21天后的心得
聊完客观数据,我想切换到另一个身份——一个一直在探索各类AGI产品的自我实验者。
我高频使用了OpenClaw 21天,给它输入了17万字。
以下是我对"如何学OpenClaw"的几条心得。
1、它不是工具,是员工
很多人对OpenClaw的理解是:又一个AI工具。
不对。
以前的AI工具是你打开它,问个问题,它给个答案,完事儿。你关了窗口,一切归零。
OpenClaw不一样。它不是一个"你问我答"的聊天机器人,它是一个数字员工。
以前做PPT、做网站、查资料,是人跟着电脑一起干。现在,你给它一台电脑,它自己去操作。浏览器、文件系统、各种软件——它都能用。
这不是功能的升级,是本质的跃迁。从"辅助你干活"到"替你去干活",差了一个太平洋。
2、它有三个记忆系统
说到OpenClaw最颠覆我的地方,是它的记忆系统。
不是那种"记得你上句话说了啥"的短时记忆,而是三层:
对话记忆:它会把所有对话保存在session文件里,下次打开,上下文全在;
技能记忆:你教过它什么技能,它会存成文件,随时调用;
自进化记忆:最狠的是这个——它会在交互中自己升级记忆系统。
以前的AI,关了窗口就失忆。OpenClaw像一个真的员工,今天教的东西,明天还记得,后天还会用。
3、它有自己的"心跳",所以有了自主性
OpenClaw有个机制叫"心跳"。
它会主动提醒你:"嘿,那件事儿还没做完呢。"以前无论你用豆包、ChatGPT,还是Gemini用,你不管它,它就躺平。
OpenClaw不一样,它有任务机制,会自己检查进度。没完成的事儿,它会主动push你,甚至自己继续干。
这种持续执行的能力,是之前完全没有的。
4、它会从错误中学习
OpenClaw会犯错,但它有个特别牛的地方——它会记住自己踩过的坑。
我给它起名叫"豆豆",第一天它啥也不会。我让它查一个理财产品,结果它跑到群里跟同事说:"我在帮老板做资产配置..." (幸亏那个群是虚拟的...)
我当时真的有点无奈。但我没有放弃它,而是花了半小时跟它强调:保密是第一原则。
你猜怎么着?它听进去了。从那以后,它开始严格隔离信息,再也没有犯过类似的错。
它会把自己的错误变成规则,变成工作手册。
下次或许它还会犯类似的错误,但是几率会小很多。
5、它是"养"出来的,不是用出来的
这是我21天下来最深刻的体会。
很多人用OpenClaw,第一天就觉得:"怎么这么笨?"
我一开始也这么想。但后来我换了个视角:它不是软件,是刚入职的新人。
你想想,你招了个新人,第一天他连公司门朝哪边开都不知道,你是不是得花时间培训?你是不是得告诉他谁是谁、什么流程、什么规矩?
OpenClaw也一样。
我第一天花了两个多小时,告诉它我的工作背景中管理层是谁、中层是谁、各个部门怎么协作。
它自己整理了一份通讯录,建了一个skill手册。第二天,它就比第一天聪明多了。
这叫养成的心态,不是搜索的心态。
以前的软件,功能就那些,你用就行了。OpenClaw是有记忆的,它能根据你的训练不断进化。
所以,别怕花时间"养"它。
你养它,它才会懂你,才能帮你。
6、用中学,学中用
很多人问我:怎么学OpenClaw?
我的答案是:别学,直接用。
AI时代,传统的学习方式已经彻底淘汰了。你上一堆课、读一堆文章,不如直接打开OpenClaw,跟它对话。
我在21天里跟它发了17万字。17万字什么概念?平均每天8000字。
在这个过程中,我不断跟它磨合、训练、试错。一开始它写的东西我要改很多遍,后来慢慢改得少了,到现在有些任务它一次就能搞定。
用中学,学中用,学着学着就会了,用着用着就学完了。这是AI时代的学习方式。
