 夜雨聆风
夜雨聆风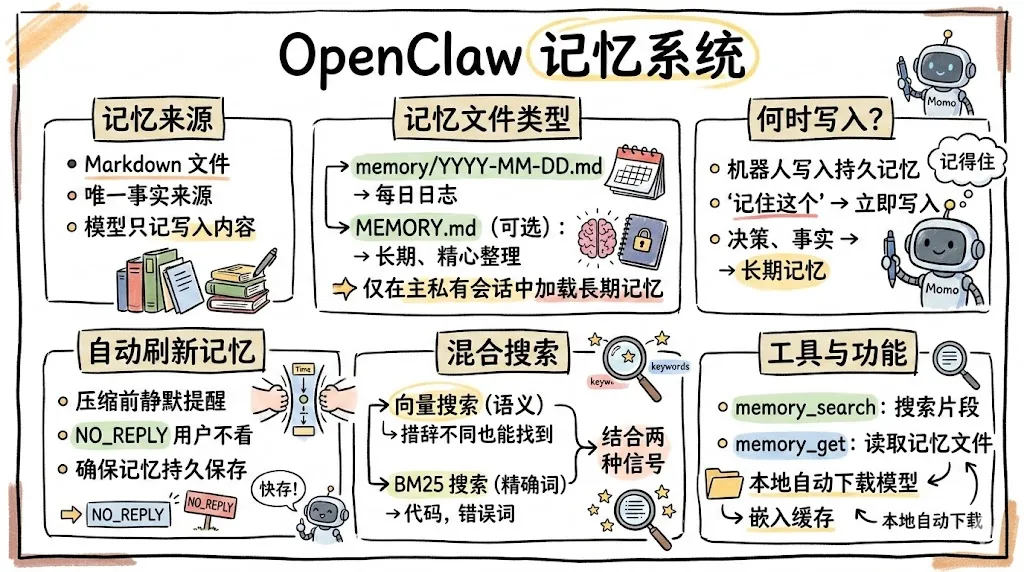
记忆文件体系
文件组织架构
OpenClaw 采用简洁直观的文件系统结构来组织记忆内容。所有记忆文件都存放在 Agent 工作区内,默认路径为 ~/.openclaw/workspace,可以通过配置项 agents.defaults.workspace 进行自定义。这种设计遵循了"约定优于配置"的原则,使得用户和 Agent 都能轻松定位和管理记忆文件。
如果你还没有养虾,建议赶紧养一个,有任何问题文末扫码联系作者
记忆文件分为两个层级,形成长期记忆和短期记忆的层次结构。长期记忆存储在 MEMORY.md 文件中,这是一个可选的、精心维护的持久化记忆库。用户和 Agent 应该将重要的决策、偏好设置、关键事实等写入这个文件。由于它会被持续加载到 Agent 的上下文中,内容应该经过筛选和整理,只保留最有价值的长期信息。短期记忆采用每日日志的形式,存储在 memory/YYYY-MM-DD.md 文件中。这些文件是append-only的追加模式,适合记录日常工作笔记、会议要点、临时决策等时效性强的内容。
记忆文件命名规范
日期格式采用 ISO 8601 标准(YYYY-MM-DD),确保跨平台兼容性并且便于排序和检索。每个日期文件是独立的,不会在不同日期之间产生混淆。这种设计借鉴了日志系统的最佳实践,通过时间维度自然地将记忆内容分区,便于管理和追溯。系统会在会话开始时自动读取今天和昨天的日期文件,将它们的内容加载到上下文中。这种设计平衡了记忆的连贯性和上下文窗口的占用——近期的记忆被优先保留,而较早的日期文件则可以通过 memory_search 工具按需检索。
记忆写入时机
何时向记忆文件写入内容是一个需要判断力的操作。根据系统设计指南,应该写入记忆的情况包括:用户明确说"记住这个"或类似表达时;做出可能影响未来交互的重要决策时;发现或确认用户的某个偏好时;需要保留某个有价值的信息片段以供将来参考时。不需要写入记忆的情况包括:纯粹的一次性临时信息;可以通过即时工具调用获取的事实性信息;对话中自然产生的过渡性内容。
系统还提供了自动记忆刷新机制(Memory Flush),这是一个智能功能,会在会话即将触发自动压缩(compaction)之前,悄无声息地提醒 Agent 将重要信息写入记忆文件。这个机制通过配置项 agents.defaults.compaction.memoryFlush 控制,默认处于启用状态。当会话接近上下文窗口上限时,系统会自动插入一个silent turn,让 Agent 有机会保存长期记忆,避免在上下文压缩过程中丢失重要信息。这种设计体现了"预防胜于治疗"的工程哲学。
记忆文件示例
以下是两种记忆文件的典型内容结构示例。
MEMORY.md长期记忆 的内容应该精炼、有组织:
ubuntu@openclaw:~/.openclaw/workspace$ ll MEMORY.md-rw-rw-r-- 1 ubuntu ubuntu 412 Mar 12 16:22 MEMORY.mdubuntu@openclaw:~/.openclaw/workspace$# MEMORY.md - 长久记忆## 关于用户- **称呼**: 待确认- **时区**: Asia/Shanghai (GMT+8)- **创建时间**: 2026-03-12# 用户偏好- 偏好使用 TypeScript 而非 JavaScript- 代码风格:严格类型检查,不使用 any- 通信风格:简洁直接,避免过多寒暄# 项目规范- 提交信息格式:使用 Conventional Commits- 测试要求:所有新功能必须有测试覆盖- 代码审查:所有 PR 需要至少一人审批# 重要联系人- 后端负责人:张三 (zhangsan@example.com)- 产品经理:李四memory/2026-03-12.md每日日志(仅追加)。会话启动时读取今天和昨天的日志的内容可以更加随意,适合每日记录:
# 2026-03-09 工作待办| 时间 | 任务 | 状态 ||------|------|------|| 10:30前 | 展会信息汇总分析 | ⬜ || 10:30 | ⏰ 联系S客户约下午会面时间 | ⬜ || 12:00 | ⏰ 帮老板安装OpenClaw接入微信 | ⬜ || 17:00-19:00 | ⏰ 汇总展会价值客户信息 | ⬜ |---创建时间:2026-03-09 10:01自动记忆刷新(压缩前提醒)
当会话接近自动压缩时,OpenClaw 会触发一个静默的代理轮次,提醒模型在上下文被压缩之前写入持久记忆。默认提示词明确表示模型可以回复,但通常 NO_REPLY 是正确的响应,这样用户永远不会看到这个轮次。
通过 agents.defaults.compaction.memoryFlush 控制:
{ agents: { defaults: { compaction: { reserveTokensFloor: 20000, memoryFlush: { enabled: true, softThresholdTokens: 4000, systemPrompt: "Session nearing compaction. Store durable memories now.", prompt: "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store." }, }, }, },}详细说明:
软阈值:当会话 token 估计值超过 contextWindow - reserveTokensFloor - softThresholdTokens 时触发刷新。
默认静默:提示词包含 NO_REPLY,因此不会向用户发送任何内容。
两个提示词:一个用户提示词加一个系统提示词附加提醒。
每个压缩周期仅刷新一次(在 sessions.json 中跟踪)。
工作区必须可写:如果会话以沙箱模式运行且 workspaceAccess: "ro" 或 "none",则跳过刷新。
完整的压缩生命周期请参阅 Session management + compaction。
向量记忆搜索OpenClaw 可以在 MEMORY.md 和 memory/*.md 上构建小型向量索引,使语义查询即使在措辞不同时也能找到相关笔记。默认设置:
默认启用。
监视记忆文件的变化(防抖处理)。
在 agents.defaults.memorySearch 下配置记忆搜索(不是顶层的 memorySearch)。
默认使用远程嵌入。如果未设置 memorySearch.provider,OpenClaw 自动选择:
如果配置了 memorySearch.local.modelPath 且文件存在,则使用 local。
如果可以解析 OpenAI 密钥,则使用 openai。
如果可以解析 Gemini 密钥,则使用 gemini。
如果可以解析 Voyage 密钥,则使用 voyage。
否则记忆搜索保持禁用状态直到配置完成。
本地模式使用 node-llama-cpp,可能需要 pnpm approve-builds。
可用时使用 sqlite-vec 加速 SQLite 中的向量搜索。
远程嵌入需要嵌入提供商的 API 密钥 。OpenClaw 从认证配置文件、models.providers.*.apiKey 或环境变量中解析密钥。Codex OAuth 仅覆盖 chat/completions,不满足记忆搜索的嵌入需求。对于 Gemini,使用 GEMINI_API_KEY 或 models.providers.google.apiKey。对于 Voyage,使用 VOYAGE_API_KEY 或 models.providers.voyage.apiKey。使用自定义 OpenAI 兼容端点时,设置 memorySearch.remote.apiKey(以及可选的 memorySearch.remote.headers)。
记忆工具的工作原理
memory_search 对来自 MEMORY.md + memory/**/*.md 的 Markdown 块(约 400 token 目标,80 token 重叠)进行语义搜索。返回片段文本(上限约 700 字符)、文件路径、行范围、分数、提供商/模型,以及是否从本地回退到远程嵌入。不返回完整文件内容。
memory_get 读取特定的记忆 Markdown 文件(工作区相对路径),可选从起始行读取 N 行。MEMORY.md / memory/ 之外的路径会被拒绝。
两个工具仅在 memorySearch.enabled 对代理解析为 true 时启用。
索引内容(及时机)
文件类型:仅 Markdown(MEMORY.md、memory/**/*.md)。
索引存储:每个代理的 SQLite 位于 ~/.openclaw/memory/<agentId>.sqlite(可通过 agents.defaults.memorySearch.store.path 配置,支持 {agentId} 令牌)。
新鲜度:MEMORY.md + memory/ 上的监视器标记索引为脏(防抖 1.5 秒)。同步在会话启动时、搜索时或按间隔调度,异步运行。会话记录使用增量阈值触发后台同步。
重新索引触发器:索引存储嵌入的 provider/model + 端点指纹 + 分块参数。如果其中任何一个发生变化,OpenClaw 自动重置并重新索引整个存储。
混合搜索(BM25 + 向量)
启用后,OpenClaw 结合:
向量相似度(语义匹配,措辞可以不同)
BM25 关键词相关性(精确 token,如 ID、环境变量、代码符号)
如果你的平台上全文搜索不可用,OpenClaw 回退到仅向量搜索。
为什么使用混合搜索?
向量搜索擅长"这意味着同一件事":
“Mac Studio 网关主机” vs “运行网关的机器”
“防抖文件更新” vs “避免每次写入都索引”
但对于精确的高信号 token 可能较弱:
ID(a828e60、b3b9895a…)
代码符号(memorySearch.query.hybrid)
错误字符串(“sqlite-vec unavailable”)
BM25(全文)则相反:擅长精确 token,弱于释义。混合搜索是务实的折中方案:同时使用两种检索信号,使"自然语言"查询和"大海捞针"查询都能获得良好结果。
结果合并方式(当前设计)
实现概要:
1、从两侧检索候选池:
向量:按余弦相似度取前 maxResults * candidateMultiplier 个。
BM25:按 FTS5 BM25 排名取前 maxResults * candidateMultiplier 个(越低越好)。
2、将 BM25 排名转换为 0…1 范围的分数:
textScore = 1 / (1 + max(0, bm25Rank))
3、按 chunk id 合并候选并计算加权分数:
finalScore = vectorWeight * vectorScore + textWeight * textScore
说明:
vectorWeight + textWeight 在配置解析中归一化为 1.0,因此权重表现为百分比。
如果嵌入不可用(或提供商返回零向量),仍运行 BM25 并返回关键词匹配。
如果无法创建 FTS5,保持仅向量搜索(不会硬失败)。
配置:
agents: { defaults: { memorySearch: { query: { hybrid: { enabled: true, vectorWeight: 0.7, textWeight: 0.3, candidateMultiplier: 4 } } } }}嵌入缓存OpenClaw 可以在 SQLite 中缓存块嵌入,这样重新索引和频繁更新(尤其是会话记录)不会重新嵌入未更改的文本。
配置:
agents: { defaults: { memorySearch: { cache: { enabled: true, maxEntries: 50000 } } }}会话记忆搜索(实验性)
你可以选择索引会话记录并通过 memory_search 呈现它们。此功能受实验性标志控制。
agents: { defaults: { memorySearch: { experimental: { sessionMemory: true }, sources: ["memory", "sessions"] } }}说明:会话索引是可选加入的(默认关闭)。
会话更新经过防抖处理,在超过增量阈值后异步索引(尽力而为)。
memory_search 永远不会阻塞索引;在后台同步完成之前结果可能略有延迟。
结果仍然只包含片段;memory_get 仍限于记忆文件。
会话索引按代理隔离(仅索引该代理的会话日志)。
会话日志存储在磁盘上(~/.openclaw/agents/<agentId>/sessions/*.jsonl)。任何具有文件系统访问权限的进程/用户都可以读取它们,因此将磁盘访问视为信任边界。要实现更严格的隔离,请在不同的操作系统用户或主机下运行代理。
增量阈值(显示默认值):
agents: { defaults: { memorySearch: { sync: { sessions: { deltaBytes: 100000, // ~100 KB deltaMessages: 50 // JSONL 行数 } } } }}SQLite 向量加速(sqlite-vec)
当 sqlite-vec 扩展可用时,OpenClaw 将嵌入存储在 SQLite 虚拟表(vec0)中,并在数据库中执行向量距离查询。这使搜索保持快速,无需将每个嵌入加载到 JS 中。
配置(可选):
agents: { defaults: { memorySearch: { store: { vector: { enabled: true, extensionPath: "/path/to/sqlite-vec" } } } }}说明:
enabled 默认为 true;禁用时,搜索回退到对存储嵌入的进程内余弦相似度计算。
如果 sqlite-vec 扩展缺失或加载失败,OpenClaw 记录错误并继续使用 JS 回退(无向量表)。
extensionPath 覆盖捆绑的 sqlite-vec 路径(适用于自定义构建或非标准安装位置)。
本地嵌入自动下载
默认本地嵌入模型:hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf(约 0.6 GB)。
当 memorySearch.provider = "local" 时,node-llama-cpp 解析 modelPath;如果 GGUF 缺失,会自动下载到缓存(或 local.modelCacheDir,如果已设置),然后加载。下载支持断点续传。
原生构建要求:运行 pnpm approve-builds,选择 node-llama-cpp,然后 pnpm rebuild node-llama-cpp。
回退:如果本地设置失败且 memorySearch.fallback = "openai",自动切换到远程嵌入(openai/text-embedding-3-small,除非被覆盖)并记录原因。
自定义 OpenAI 兼容端点示例
agents: { defaults: { memorySearch: { provider: "openai", model: "text-embedding-3-small", remote: { baseUrl: "https://api.example.com/v1/", apiKey: "YOUR_REMOTE_API_KEY", headers: {"X-Organization": "org-id","X-Project": "project-id" } } } }}remote.*优先于 models.providers.openai.*。remote.headers与 OpenAI 请求头合并;冲突时 remote 优先。省略 remote.headers则使用 OpenAI 默认值。
如果你还没有养虾,建议赶紧养一个,有任何问题文末扫码联系作者

