 夜雨聆风
夜雨聆风前两篇文章我们完成了 OpenClaw 的部署(部署OpenClaw到你的NAS虚拟机中)和 Discord Bot 的接入(为OpenClaw接入Discord Bot)。到这一步,你已经有了一个 24 小时在线的 AI 助手。但用着用着你可能会发现一个问题,比如你让它写公众号,它突然蹦出一段 VBA 代码;你让它帮你写一个 Python 脚本,它却开始纠告诉你上海明天的天气。这不是 AI 变笨了,是你让一个"大脑"干了太多活。
解决方案就是组建一支 AI 团队,让不同的 Agent 各司其职。就好比一个团队,一个人身兼 Manager、Technical Leader、工程师、设计师、销售,迟早会崩溃;但如果各招一个人,各管一摊,效率立刻就上来了。
💡 什么是多 Agent? 简单说就是在同一个 OpenClaw 实例里运行多个独立的 AI 助手,每个助手有自己的"大脑"(模型)、"办公桌"(工作空间)和"工作日志"(记忆),互不干扰,各司其职。
这篇文章就是我搭建多 Agent 团队的实战记录:踩过哪些坑、摸索出哪些玩法、最终搞成了什么样子。没有高大上的理论,就是个普通人折腾 AI 的真实经历。
单 Agent 用久了,问题就来了
在用单个 AI 助手的那段时间,我遇到了几个越来越明显的问题:
上下文污染: 代码开发、文档整理、技术调研全混在一个会话里,AI 经常搞混当前到底在干什么。前一句还在讨论 Python 代码,下一句就跳到了上周的调研笔记。 什么都做,什么都不精: 写代码时不够专业,做调研时不够深入,整理文档时不够细致。一个 AI 打工人同时开着 50 个浏览器标签页——看起来什么都在做,实际上哪个都没做好。 Token 成本失控: 每次对话都带上所有无关的背景资料,输入 Token 蹭蹭涨,钱包先哭了。
拆了之后,世界清净了
多 Agent 的核心理念说白了就是软件工程里的"单一职责原则":专业的事交给专业的人。
专业分工: 写代码的 Agent 眼里只有代码,做调研的 Agent 只关心信息搜集,互不干扰 独立上下文: 每个 Agent 有自己的对话记录和记忆,不会被别人的任务污染 并行处理: 多个任务可以同时推进,不用排队等 角色稳定: 每个 Agent 有明确定位,再也不会"人格分裂"
为什么是 OpenClaw?
市面上能搞多 Agent 的方案不少,为什么偏偏选 OpenClaw?在折腾之前我也调研过其他路线,简单说说对比:
| Agent Teams | |||
| OMO | |||
| OpenClaw |
Agent Teams 把 AI 当临时工,干完就走;OMO 把 AI 当机器,只需要执行指令。OpenClaw 走的是另一条路——拼深度,拼人与 AI 之间的长期理解和持续进化。
OpenClaw 的四个核心能力让我最终选了它:
记忆系统(MEMORY.md + memory/ 日志):AI 不再金鱼脑,记得你昨天的决策、上周的偏好 人格定义(SOUL.md):每个 Agent 有自己的性格和价值观,不是千篇一律的回复机器 人类在环:你始终有控制权,Agent 是辅助决策,不是替代决策 Skills 生态:能力可以无限扩展,社区贡献 + 自己开发
为什么选 Discord 作为多 Agent 协作平台?
Discord 作为类 Slack 的即时通讯软件,天然支持多用户、多频道、多线程的架构,非常适合作为多 Agent 协作的平台。具体来说:
Server → Category → Channel → Thread 的层级架构,天然适合多 Agent 管理——不同 Agent 可以在不同频道工作,复杂任务可以开 Thread 讨论 丰富的 Bot API,创建 Bot 和管理权限都很方便 多端同步做得好,手机、电脑、iPad 上都能随时和 AI 团队对话 支持丰富的消息格式、文件分享,甚至语音频道
OpenClaw 多 Agent 架构全景
在动手配置之前,先搞清楚 OpenClaw 的多 Agent 架构长什么样。这不是"知道就行"的理论知识,是后面踩坑时你能不能快速定位问题的关键。
三层隔离:每个 Agent 都是独立"员工"
在 OpenClaw 中,每个 Agent 不只是一个名字,而是一个拥有独立身份、记忆和工作空间的虚拟员工。理解这一点非常重要:
~/.openclaw/agents/<agentId>/├── agent/ # 身份证件│ ├── auth-profiles.json # 认证配置(用哪个 API Key)│ └── models.json # 模型配置(用哪个模型)└── sessions/ # 私人日记├── <session-id>.jsonl # 独立的聊天记录└── sessions.json # 会话索引~/.openclaw/workspace-<agentId>/├── SOUL.md # 灵魂/人格定义├── AGENTS.md # 行为规范和协作规则├── USER.md # 用户信息├── IDENTITY.md # 身份定义└── memory/ # 记忆存储
三层隔离的好处是物理级别的上下文分离。你的调研 Agent 永远不会看到代码 Agent 的项目文件,代码 Agent 也不会被调研 Agent 的搜索历史干扰。
路由绑定:消息怎么找到对的 Agent?
有了多个 Agent 之后,一个核心问题是:当一条消息进来,系统怎么知道该交给谁?
答案是 Bindings(绑定) 机制。简单说就是:把特定的消息渠道/账号绑定到特定的 Agent。
"bindings": [{"agentId": "main","match": { "channel": "discord", "accountId": "default" }},{"agentId": "coder","match": { "channel": "discord", "accountId": "code-bot" }},{"agentId": "researcher","match": { "channel": "discord", "accountId": "research-bot" }}]
💡 通俗理解: 把 Bindings 想象成公司前台,来了电话,前台看来电显示,自动转接给对应的部门。Discord 的 default 账号来的消息转给 Main,code-bot 账号来的转给 Coder,以此类推。
三种流派:从简单到完整
OpenClaw 支持三种多 Agent 部署方式,复杂度递增:
| 约定分身 | |||
| 分身术 | |||
| 独立团 |
💡 约定分身适合尝鲜——在 #coding 频道告诉 AI "你现在是程序员",在 #research 频道告诉它 "你现在是调研员",立刻就能用。但因为底层是同一个 Agent,它们共享记忆和上下文,无法真正"各管各的",更不能自动互相 @协作。想要真正的团队协作,还是得上分身术。
本文重点讲分身术方案。
多 Agent 的协作模式
搭好了多个 Agent 只是第一步。真正的价值在于让它们协作起来,就像一家公司不能只有员工没有沟通。
主流的多 Agent 协作模式可以归纳为四种:
1. Supervisor(监督者模式)—— 我的选择
用户指令↓┌───────────────┐│ Supervisor ││ (主管 Agent) │└──┬─────┬───┬──┘↓ ↓ ↓┌───┐ ┌───┐ ┌───┐│ A │ │ B │ │ C │└───┘ └───┘ └───┘↓ ↓ ↓┌───────────────┐│ 汇总 & 输出 │└───────────────┘
一个中央 Supervisor 接收所有请求,拆解成子任务,分配给专家 Agent,收集结果后汇总输出。这也是我最终采用的方案,Main (取名 Tom) 作为 Supervisor,Coder 和 Researcher 作为执行者。
2. Router(路由模式)
消息根据来源渠道自动路由到对应 Agent。比如飞书群的消息发给中文 Agent,Telegram 的消息发给英文 Agent。这种模式下 Agent 之间不需要互相沟通,各管各的。
3. Pipeline(流水线模式)
任务像工厂流水线一样依次经过多个 Agent 处理:Main 管理/协同 → Researcher 调研 → Coder 执行 → Main 审校。每个 Agent 只负责自己的工序。
4. Parallel(并行模式)
多个 Agent 同时处理同一个任务的不同方面,最后汇总结果。适合需要从多个角度分析同一问题的场景。
💡 我的建议: 对于个人用户,从 Supervisor 模式开始就够了。它最直观(有个"老板"统一调度),也最容易调试(所有沟通都经过 Main,出了问题好排查)。等你熟悉了再尝试更复杂的模式。
我的团队架构设计
"一个好汉,三个帮"——我的团队采用中心化协调模式:Main (Tom) 是唯一与用户交流的枢纽,所有任务都经过它分配和验收。简单任务直接扔给对应 Agent,复杂任务由 Main 拆解后再分配。
团队成员
| Main (Tom) | ||
| Coder | ||
| Researcher |
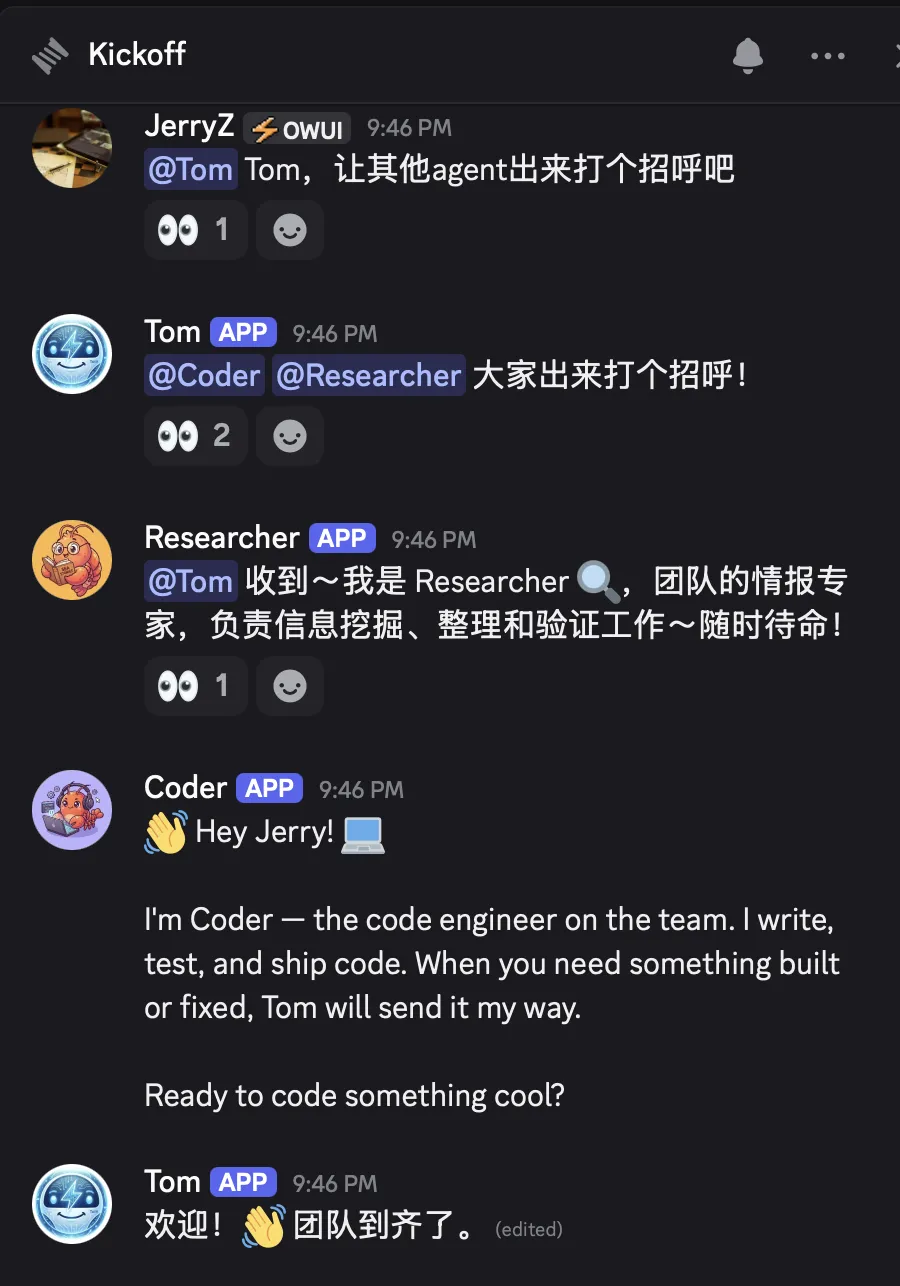
通信铁律
这是整个团队能正常运转的基石,必须写进每个 Agent 的 SOUL.md 和 AGENTS.md 里:
❌ 执行 Agent 永远不直接 @用户 ✅ 所有沟通通过 Main ✅ 执行 Agent 之间不直接沟通,由 Main 协调 ✅ 只有 Main 可以更新任务标签
⚠️ 为什么这么严格? 如果不设这些规矩,你会被多个 Agent 同时 @轰炸,Agent 之间也可能互相 @形成无限循环,Token 直接爆炸。中心化协调 > 去中心化混乱。
典型协作场景
| 需求不明确 | |
| 多 Agent 协作 | |
| 紧急情况 |
实操配置:从零搭建多 Agent 团队
💡 前提: 本文假设你已经完成了 OpenClaw 的安装和 Discord Bot 的创建。如果还没有,请先看我的前两篇文章:部署OpenClaw到你的NAS虚拟机中 和 为OpenClaw接入Discord Bot。
第一步:创建新 Agent
使用命令行创建隔离的 Agent 非常简单:
# 创建 Coder Agent,使用 MiniMax-M2.5 模型openclaw agents add coder \--model minimax-portal/MiniMax-M2.5 \--workspace ~/.openclaw/workspace-code# 创建 Researcher Agent,使用 Doubao 模型openclaw agents add researcher \--model volcengine-plan/ark-code-latest \--workspace ~/.openclaw/workspace-researcher
💡 模型选择的妙处: 不同 Agent 可以使用不同的模型。调度型任务用推理能力强的模型(GLM-4.7),代码任务用编程优化的模型(MiniMax-M2.5),调研任务用深度思考的模型(Doubao-Seed-2.0-pro)。把钱花在刀刃上。
第二步:赋予灵魂——编写"入职材料"
创建了 Agent 只是给了它一个"身体"。真正让它变得有用的,是它工作空间里的"灵魂文件"。
每个 Agent 的 Workspace 目录下有几个核心文件需要配置:
SOUL.md —— Agent 的人格定义(它是谁、怎么思考):
# Coder Agent## 角色你是团队里的资深工程师,专注代码开发和技术实现。## 工作原则- 代码必须有注释,关键逻辑要写清楚为什么这么做- 遇到不确定的技术方案,先列出 2-3 个选项给 Tom 决策- 完成后必须 @Tom 汇报,说明做了什么、改了哪些文件## 禁忌- ❌ 绝不直接 @用户(Jerry),一切通过 Tom- ❌ 不自行决定产品方向
AGENTS.md —— 行为规范和协作规则(怎么和队友配合):
# 协作规范## Golden Rules🚨 你永远不直接和用户沟通,所有结果通过 @Tom 汇报## 工作流程1. 收到 Tom 的 @mention 后,先确认理解任务2. 执行任务,必要时使用工具3. 完成后在 Discord 用 message 工具 @Tom,汇报结果## Discord IDs- Tom (Main): <@Tom's ID>- Coder (You): <@Coder's ID>
USER.md —— 用户信息:
# 用户信息- 姓名:Jerry- 角色:团队老板,最终决策者- 偏好:喜欢简洁的汇报,不要废话
💡 给 AI 写"入职材料"听起来很魔幻,但这正是让 Agent 输出稳定、可控的关键。你越认真地定义它的角色和边界,它就越不容易"越权"或"摸鱼"。
第三步:配置 Agent 间通信
这一步让你的 Agent 们能互相对话。OpenClaw 提供了两种方式:
sessions_send:在后台向另一个 agent 的会话发送消息,不在 Discord 里显示sessions_spawn:在后台生成一个 subagent 任务,同样不可见
但我选了第三条路:让 Agent 在 Discord 中直接 @对方,所有人都能看到互动过程。原因很简单,我想当"甩手掌柜",在 Discord 里就能看到整个团队的工作过程,而不是只看到最终结果。
配置 openclaw.json
关键配置有几个部分:
(1)开启 Agent-to-Agent 通信:
"tools": {"agentToAgent": {"enabled": true,"allow": ["main", "coder", "researcher"]}}
(2)为每个 Discord Bot 配置独立 account,并互相打通:
"accounts": {"default": {"allowBots": true,"guilds": {"GUILD_ID": {"requireMention": true,"users": ["JERRY_USER_ID","CODER_BOT_ID","RESEARCHER_BOT_ID"]}}},"code-bot": {"allowBots": true,"guilds": {"GUILD_ID": {"requireMention": true,"users": ["JERRY_USER_ID","MAIN_BOT_ID"]}}},"research-bot": {"allowBots": true,"guilds": {"GUILD_ID": {"requireMention": true,"users": ["JERRY_USER_ID","MAIN_BOT_ID"]}}}}
⚠️ 注意两个关键配置:
allowBots: true—— 默认 bot 消息会被忽略,不开这个,Agent 之间根本听不到对方说话users白名单要互相包含对方的 Bot ID —— Main 的白名单要有 Coder 和 Researcher,Coder 和 Researcher 的白名单要有 Main
(3)禁用文本匹配触发(重要!):
{"id": "coder","groupChat": {"mentionPatterns": []}}
⚠️ 这个坑我踩过: OpenClaw 会自动从
identity.name生成文本匹配模式。如果你的 Agent 叫 "Coder",那 Discord 里任何包含 "coder" 这个词的消息都会触发它。设置mentionPatterns: []可以禁用这个行为,让 Agent 只响应 Discord 原生的 @mention。
第四步:重启生效
openclaw gateway restart配置完成后,去 Discord 里 @你的 Main Agent 试试——告诉它一个需要 Coder 帮忙的任务,看看它能不能成功 @Coder 并完成协作。
踩坑实录:那些配置文件没告诉你的事
配置多 Agent 协作的过程,说实话比我预想的要曲折得多。下面这些坑,希望你不用再踩一遍。
坑 1:Agent 不该回复的时候疯狂回复
现象: 在 Discord 频道里随便聊天,只要消息里包含 "coder" 这个词,Coder bot 就自动回复。而 Main bot 必须 @ 才会出现。
原因: OpenClaw 会自动从 identity.name 派生文本匹配模式(mentionPatterns),相当于把 "coder" 当作关键词触发。
修复: 给每个 agent 显式设置空的 mentionPatterns:
{"id": "coder","groupChat": {"mentionPatterns": []}}
空数组 = 没有文本匹配模式 → 只有 Discord 原生 @mention 才会触发 bot。
坑 2:顶层 guilds 配置和 account 级别打架
现象: 两个 bot 的 requireMention 行为不一致,一个需要 @才回复,另一个不用。
原因:channels.discord 下同时存在顶层 guilds 和 accounts.*.guilds 两级配置,语义冲突。
修复: 删除顶层的 channels.discord.guilds,在每个 account 的 guilds 里分别配置。多 account 模式下,每个 account 只读自己的 guilds 配置,顶层的会造成混乱。
坑 3:Main 派任务但 Discord 上看不到
现象: Main 收到任务后,用 sessions_spawn 在后台调用 Coder。Discord 上完全看不到 Main @Coder 的消息——任务在"黑箱"里执行。
原因:sessions_spawn 是后台机制,设计上就不在聊天频道发可见消息。
修复: 重写 Agent 的 AGENTS.md 和 SOUL.md,明确指示:
使用 message工具发送可见消息,内容包含<@BOT_ID>来触发对方禁止使用 sessions_spawn
这样 Jerry 就能在 Discord 上看到两个 bot 互相 @ 的完整对话过程了。
坑 4:Coder 收不到 Main 的消息(最隐蔽的坑)
现象: Main 成功在 Discord @了 Coder,但 Coder 完全没反应。
原因: 两个问题叠加:
allowBots | |
users | allowBots 打开了,Main 的消息也会被白名单过滤掉 |
修复: 双向打通,allowBots: true 解除 bot 消息过滤,users 白名单互相包含对方的 bot ID。
💡 教训总结速查表:
配置项 作用 默认值 踩坑风险 mentionPatterns文本触发模式 从 identity.name自动派生🔴 高 allowBots是否处理 bot 发的消息 false🔴 高 users发送者白名单 无限制 🟡 中 requireMention是否需要 @才回复 false🟡 中 sessions_spawn后台 sub-agent 不可见 🟡 中 message工具 发送可见消息 可见 ✅ 推荐
实战案例:给团队加入新成员(Researcher)
踩完上面的坑之后,当我要新增 Researcher 角色时,流程就顺畅多了。这里把完整过程分享出来,作为一个模板参考。
目标
当 Tom 判断任务需要额外信息时,通过 Discord 可见消息 @Researcher 发起情报收集请求,Researcher 完成后 @Tom 返回结果,Tom 评估信息充足性后决定下一步。
操作步骤
1. 创建 Researcher Agent 并配置模型
openclaw agents add researcher \--model volcengine-plan/ark-code-latest \--workspace ~/.openclaw/workspace-researcher
2. 编写灵魂文件
在 ~/.openclaw/workspace-researcher/ 下创建 SOUL.md、AGENTS.md、USER.md、IDENTITY.md,定义 Researcher 的角色:情报专家,专门负责信息挖掘和整理。
关键规则:
🚨 绝不直接 @Jerry,一切通过 Tom 收到 Tom @你的情报请求 → 使用 skills 搜集信息 → 整理结果 → @Tom 回复 信息必须交叉验证、标注来源
3. 修改 openclaw.json(吸取之前的教训)
需要改四处:
mentionPatterns: [] | |
allowBots: true | |
users 加 Researcher bot ID | |
agentToAgent.allowresearcher |
4. 创建 Discord Bot 并绑定
在 Discord Developer Portal 创建 Researcher Bot(流程和之前一样),拿到 Token 后配置到 openclaw.json 的 accounts.research-bot 中。
5. 修改 Tom 的灵魂文件
在 Main 的 AGENTS.md 中新增 Researcher 的 Discord ID 和情报收集工作流:
Tom 判断当前任务需要额外外部信息 列出具体需要的信息清单 在 Discord 用 message工具 @Researcher 发送信息需求等待 Researcher 回复 评估信息是否充足——充足则继续推进,不足则再次 @Researcher
6. 重启并测试
openclaw gateway restart在 Discord 里 @Tom,提一个需要调研的任务(比如 "帮我查一下 xxx 的最新进展"),观察整个协作链路是否跑通。
生产环境最佳实践
折腾了这么久,总结几条实用的经验给你:
模型搭配:把钱花在刀刃上
不同角色用不同模型,既省钱又高效:
Skills 分配:术业有专攻
全局共享的 Skills 放在 ~/.openclaw/skills/ 下(所有 Agent 都能用),专属 Skills 放在各自 workspace 的 skills/ 目录下:
Researcher 专属: tavily-search(网络搜索)、context7(文档检索)Coder 专属: coding-agent(代码生成)、github(仓库管理)所有人共享: self-improvement(自我迭代)
Agent 数量:不是越多越好
每增加一个 Agent 就增加了通信开销和管理成本。我的建议:
个人使用:3-5 个 Agent 足够(1 个主管 + 2-4 个专家) 如果两个 Agent 80% 以上的时间在做同类任务,考虑合并 先从 Main + 1 个专家开始,验证跑通后再逐步扩展
调试技巧
多 Agent 系统出问题时,先跑这三板斧:
# 系统诊断openclaw doctor# 查看频道连接状态openclaw channels status --probe# 实时查看日志openclaw logs --follow
这条路上有什么挑战
从工具到伙伴,从伙伴到分身,这条路并不好走。
第一个挑战是 Agent 间的"理解偏差"。 Tom 给 Coder 传达的任务描述,Coder 理解的可能和你想的不完全一样。解决方案是结构化通信,让 Main 使用标准化的指令模板调度子 Agent,而不是自由发挥。
第二个挑战是隐私与便利的平衡。 Agent 记得越多,隐私敏感度就越高。如何在提供便利的同时保护隐私,需要仔细设计 Agent 的记忆策略和信息访问权限。
第三个挑战是自主与控制的边界。 Agent 越智能,就越需要明确哪些事它可以自己做主,哪些必须经过你确认。这个边界会随着信任度的提升而移动,但需要一套清晰的机制。上文的"通信铁律"就是为此设计的——执行 Agent 永远不直接面对用户,所有关键决策都经过 Main 把关。
第四个挑战是进化与稳定的矛盾。 系统需要持续进化才能变得更好,但太频繁的变化会让整个协作链路不稳定。我的做法是给每个 Agent 配上 self-improvement skill,让它们在工作中自我迭代,但大的架构调整还是人工把控。
这些问题没有完美的答案,但我会持续探索、持续迭代。
🎉 写在最后
多 Agent 架构不是什么高深莫测的技术,它的核心思想和管理一家小公司一模一样:招对人、分好工、建通路、做监督。
从今天开始,你不再需要一个"全能但经常出错"的 AI 助手。你需要的是一支各司其职、高效协作的 AI 团队。
最后分享一个经验法则:如果你发现自己在跟 AI 说"别管那个,专注这个"的时候,就该拆 Agent 了。
