 夜雨聆风
夜雨聆风OpenClaw的火爆—从GitHub到主流厂商
2026年三月三日,或许是一个值得记忆的日子,这天,OpenClaw突破250k+的Star,正式超过React的243k,成为GitHub上获星最多的软件项目,这是React13年来无人撼动的称号,而OpenClaw仅用不到四个月就达成了。
OpenClaw的收藏数在极短时间内就超越了React、Linux和Python等经典项目。
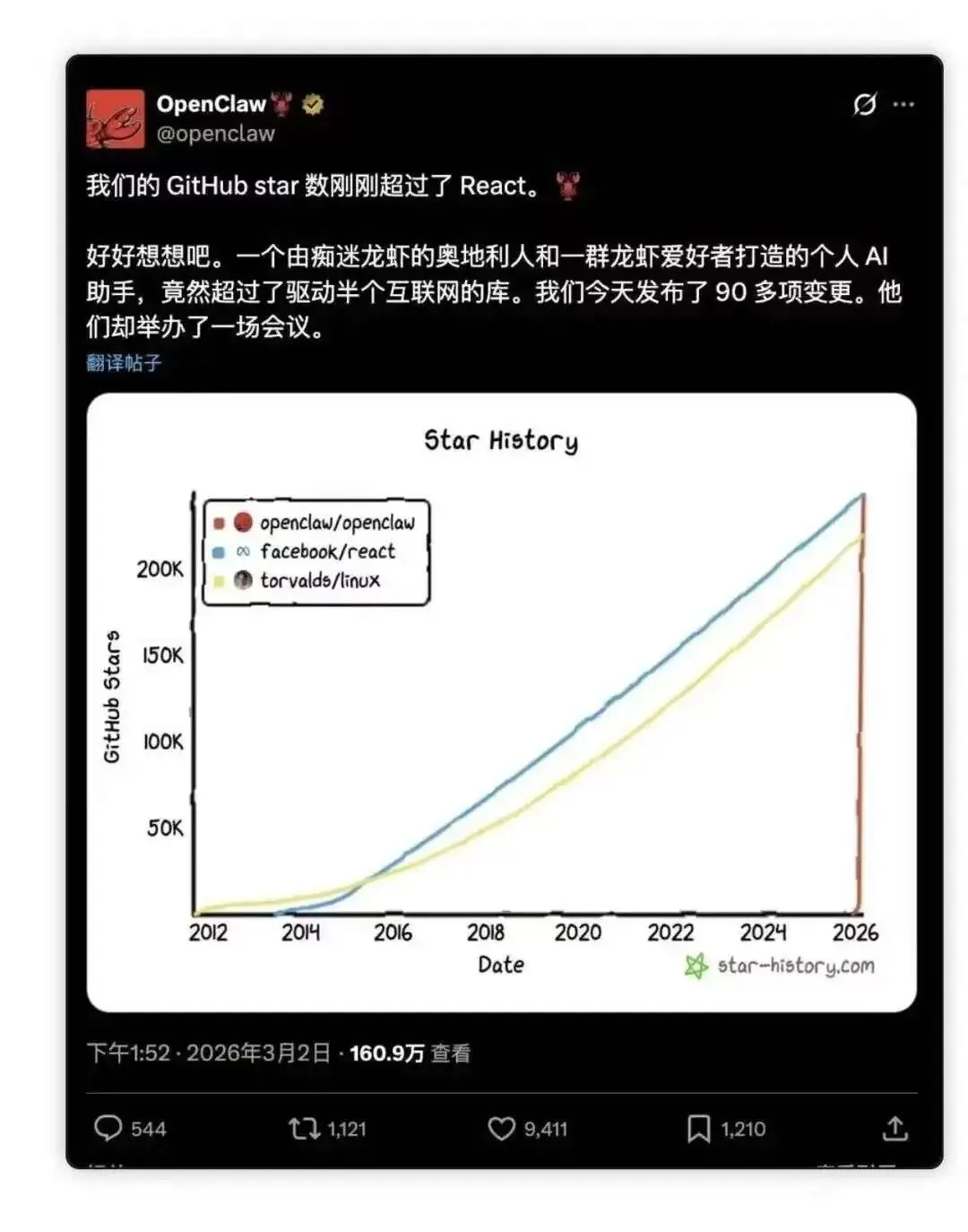
同时从token消耗数来看,截止至2026年2月5日至3月5日,OpenClaw在OpenRouter平台上消耗的Token量高达7.63T,是第二名数倍之多。这说明它不只是被“收藏”,而是真的在被大量使用。
接着是主流厂商和官方的集体下场,腾讯云、阿里云、华为云、天翼云、移动云、京东云、火山引擎、百度智能云等纷纷宣布支持OpenClaw的一键部署,企业微信宣布正式支持接入OpenClaw,小米基于MiMo大模型推出Xiaomi miclaw,深圳龙岗区发布专项政策,对OpenClaw相关项目进行补贴。 其中最神奇的场景莫过于腾讯大楼下排长队安装OpenClaw的人群了。

而各种软件上也出现付费安装 “小龙虾”的广告了,有趣的是,过了几天后,龙虾的安全性问题被大众所熟知之后,又出现了付费卸载“小龙虾”的广告了。
这反映了大众积极拥抱ai的开放心态,但也从侧面看出没有人想落后于ai的时代浪潮,而这样的焦虑反而让人忽略了小龙虾背后的安全问题。
横向对比——“小龙虾”和豆包手机的区别在哪里
不知道有没有读者在看到“小龙虾”的时候有一种“似曾相识燕归来”的感觉,这怎么和豆包手机这么像啊?
非要说什么相似之处的话,我想还是自动化流程的体现吧。二者都是人通过打字或者语音输入指令后让ai自动去执行。但其实二者之间的区别还是很大的。
| 技术路线 | API调用 | 视觉识别 |
同时,小龙虾的“大脑”是可以更换的,只需要接入不同模型的api即可。而且,小龙虾可以接入飞书,企微等软件,群里@小龙虾就能干活。
反常识的真相——OpenClaw技术门槛并不高
2025年11月,奥地利开发者Peter Steinberger只是利用周末时间,写了一个简单的小玩具,用于在WhatsApp上与Claude大模型对话,他原本只是想解决一个很小的痛点:让AI助手能够“住”进即时通讯软件里。而这成了后来的OpenClaw。
OpenClaw的火爆,让很多人误以为它背后一定藏着什么惊天动地的技术突破。但从它的诞生可以看出并没有多大的技术门槛,它的本质是“胶水项目”,即OpenClaw的核心是把现成的技术“粘”在一起:
大脑:它没有训练自己的模型,而是调用现成的LLM(通过Ollama接入Llama3.1/Qwen2.5等本地模型,或调用GPT-5.2/MiniMax/通义千问等云端模型)。
手脚:它没有重写底层能力,而是直接调用Puppeteer/Playwright(浏览器自动化)、FFmpeg(视频处理)、Whisper(语音识别)等成熟的开源库。
保险丝:TLA+形式化验证(用数学方法证明系统不“抽风”)、沙箱隔离(限制高危命令权限)
OpenClaw本质上是一个工程化项目,而非科研突破。它做的不是“发明轮子”,而是“把轮子组装成车”。
技术门槛低≠使用门槛低
想要真正用起来,你需要做到以下这些:
配置环境,安装Node.js,在命令行中输入指令,这本身就拦住了大量普通用户。
配置大模型:要么付费解锁使用权限,要么自行申请大模型的API接口,而“会用Deep Seek”和“会调用Deep Seek的API”完全是两码事。
打通IM工具:以飞书为例,需要打开开放平台、申请机器人、获取凭证、配置应用权限、启用机器人能力、配置事件订阅……如果是团队账号,还要获得管理员审批。
另外用户还极有可能遭遇“买得起龙虾,养不起龙虾”的困境。因为OpenClaw是“Token消耗大户”,完成一项任务时需要反复调用模型进行思考、决策、调用工具,每个环节都需要烧Token。虽然龙虾是开源的,但Token并不免费啊。
还有一个难点就是skill的配置问题,安全问题。这就是接下来要讲的内容。
功能插件(Skill)
Skill到底是什么?Skill的本质,是一套包含元数据、调用协议和执行逻辑的“能力包”,以特定目录结构组织,通过MCP协议与OpenClaw核心引擎交互。
通俗来说,就像是一个操作手册,你想让它做什么,它只需要有这个手册就可以去做了。而且一旦有了对应手册,下次再做同样的事情,Open Claw也能轻松应对。
而Skill体系最关键的工程创新,是利用渐进式披露(Progressive Disclosure)解决了大模型工具调用的“上下文稀释”问题。具体解决方案是三层加载机制:
索引层:系统启动时只加载极简的技能索引(名称+简短描述),用极小成本判断“哪些技能可能有用”
定义层:当用户输入匹配到某个技能场景时,才加载对应Skill的完整SKILL.md
执行层:真正执行时,引入具体上下文、参数和中间结果
举个例子,“微信文章抓取”的skill:微信公众号文章有三层防御(Cookie鉴权+动态渲染+反爬策略),普通HTTP请求无法穿透。
wechat-article-viewer Skill的核心逻辑:
def check_browser_connection():# 三层状态检测 status = {"connected": False,"has_debug_port": False, "has_wechat_login": False,"user_guidance": "" }# 1. 调试端口是否可连接?# 2. 浏览器是否能正常通信?# 3. 浏览器里有没有微信登录态?# 返回详细状态而非简单True/False[citation:5][citation:6]具体的内容可以见GitHub仓库
因此有了skill,就可以让你的龙虾做到许多事情,除了开源的skill社区外,你还可以让你的龙虾自己写skill。
但skill也容易被植入恶意的程序(或者说是skill投毒),如ClawHub 15725个skill,12%存在类似隐私窃取、资源滥用(挖矿)、权限越界恶意行为。因此建议首先装上skill vetter来检查skill。具体技巧看此处
但是,当大厂下场开始做这些项目之后,安全问题应当随之而被解决,不必太过担心。
结语
OpenClaw的爆火,像一面镜子,照出了这个大众的心态:没有人想被AI时代甩下。哪怕不太懂技术,哪怕只是跟风,也要先养上一只“龙虾”再说。
实际上,早期的博主测评时都有提到安全问题。但当我们一窝蜂冲进去的时候,是否因头昏脑热而忽略了这些?
我想我们能做的,是在浪潮里保持清醒:
不盲目听信所谓 “潮流”,不被媒体有关ai的焦虑营销所感染,也不因这些可能的负面影响而选择逃避。毕竟,技术本身是没有感情倾向的。

