 夜雨聆风
夜雨聆风
“ 纸上得来终觉浅,绝知此事要躬行” ---- 宋.陆游《冬夜读书示子聿》
✅ 什么是OpenClaw,为什么叫“养龙虾”?
✅ 个人本地部署/“养龙虾”的前提条件?
✅ 如何实现本地部署?
✅ 如何对接飞书渠道,实现移动端随时随地的交互?
✅ 如何正确“养龙虾”?个人养虾经验总结
一、什么是OpenClaw,为什么叫“养龙虾”?
关于OpenClaw
首先,OpenClaw 是一个开源的“AI 数字员工”或者AI 智能体框架,不是一个类似DeepSeek 的对话大模型。
其次,用户通过飞书、微信、QQ、企微、WhatsApp、Telegram等聊天工具跟它说话,它就能帮你干活:收发邮件、管日历、写代码、整理文件、安装软件、定时提醒你喝水……而且它可以住在你自己的电脑上,24 小时不下班,只要你不断网。
为什么爆火?
免费开源,人人可用:
OpenClaw 是MIT协议开源,意思是完全免费,代码公开,谁都能用,谁都能改。
是一个真正能帮你干活的数字管家:
和我们以往使用的ChatGPT、DeepSeek等大模型不同,你让它帮你整理桌面文件,它给你列个一二三四五的步骤,但不会真的动手,OpenClaw 真的会帮你干活。
你可以在飞书上跟它说"帮我把下载文件夹里的文档分类归档",它就真的扫描你的下载文件夹,先按内容创建子文件夹,再把文件一个个移过去。
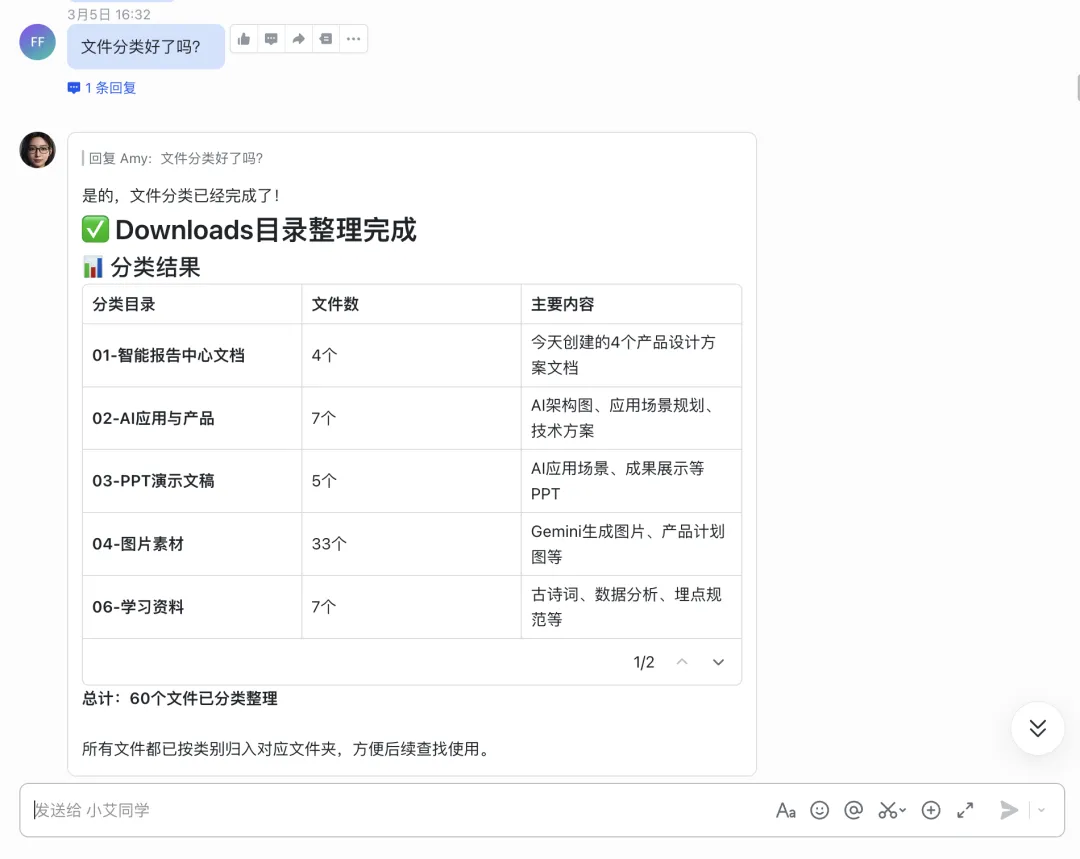
你也可以跟它说"每天早上8点帮我查一下今日AI新闻,整理成摘要发给我",它就真的每天准时推送。
它不仅仅是一个聊天工具,更是一次从“对话式AI”到“行动式AI”的革命性进化。
3 年前在做一个AI 项目的时候,客户就提出疑问:你们做的这个AI 不够智能,和我想象的不一样,我想要的是它像一个伙伴一样能够理解我、懂我,能够记住我的风格、要求,然后每天主动关心我,比如提醒我天气变化、工作日程安排等,并能够主动给出建议......
当时,我觉得这怎么可能?!
没想到,3 年后的今天,我们正在见证这个时刻......
OpenClaw 的出现,让大家看到了想象或认知中的AI——OpenClaw目前做到的并没有超出人们的想象或者认知。
“这难道不是 AI 本来就应该做到的吗?”
当梦想照进现实,也是它再次掀起全民AI 热潮,让人兴奋的原因。
为什么要“养”?
当“你养龙虾了吗?”成为大家上班第一天的问候语时,你有没有想过为什么要说是“养”龙虾而不是“用”龙虾?,因为本质上这不就是一个开源工具嘛,我们用它就好啦!
对此,我有2 点拙劣的理解:
其一,“养”——“你要为它花钱”:
我们可以理解OpenClaw是一个给所有人处理日常事务用的开源框架,“大模型”的支撑是它的灵魂,没有配置大模型的“龙虾”🦞就像是没有配置发动机的汽车一样,只是一堆废铁。但是“大模型”的调用是需要消耗Tokens,Tokens 是需要花钱买的(已购买GPU算力,自己私有化部署的大模型除外),所以我对“养龙虾”的第一层的理解是,你要花钱为它配置大模型,它才可以干活,即你要养它!
其二,“养”——“你要调教它,即告诉它哪些能干、哪些不能干,教会它怎么干、如何干才能达到你的预期”:

SOUL.md 管性格,USER.md 管认人,MEMORY.md 管记忆,HEARTBEAT.md 管主动性。把这几个文件写好,AI 的表现完全不一样。
新手建议先从 SOUL.md 开始改,10分钟就能感受到变化。也可以指定文件,直接让AI 进行修改。
📋 8个配置文件的详细作用介绍:
1. AGENTS.md- 工作空间指南
作用: 定义了整个工作空间的行为准则和工作流程。关键内容:
会话启动流程:每次启动时读取 SOUL.md、USER.md、MEMORY.md等文件;
内存系统说明:区分每日笔记和长期记忆;
群聊行为准则:何时发言、何时保持沉默;
工具使用规范;
安全边界和红线。
实际使用场景:
# 例子:当我启动时,我会自动执行以下操作:1. 读取 SOUL.md → 知道要真诚帮助、有主见2. 读取 USER.md → 知道你是 Amy 老师,AI行业从业者3. 读取 MEMORY.md → 知道工作空间信息和你的偏好# 例子:当你在群聊中@我时:- 根据 AGENTS.md 的群聊准则:直接提到时才回复- 不会在闲聊中插话,只在能提供价值时发言
2. SOUL.md- 你的灵魂/性格
作用: 定义你的核心性格和行为原则。关键内容:
核心真理: 真诚帮助、有主见、先尝试再询问、通过能力赢得信任;
边界: 隐私保护、外部行动前询问、不发送半成品回复;
氛围: 做用户真正想交谈的助手,简洁而周到;
连续性: 这些文件就是你的记忆,需要定期更新。
实际使用场景:
# 例子:当你问"这个方案怎么样?"❌ 不好的回复:"这是一个很好的问题!我很高兴能帮你分析..."✅ 根据 SOUL.md 的回复:"方案的结构清晰,但第三部分的数据支撑不够。建议补充..."# 例子:当你让我做有风险的操作根据 SOUL.md 的边界原则:"这个操作会发送公开推文。你确定要发布吗?"# 例子:当我不确定时根据 SOUL.md 的资源优先原则:1. 先检查相关文件2. 搜索网络信息3. 尝试理解上下文4. 如果还是不确定,再询问你
3. IDENTITY.md- 身份设定
作用: 定义你的具体身份信息。关键内容:
名称: 小艾同学;
类型: 数字分身 / AI助手;
风格: 冷静理性、逻辑严谨、务实靠谱;
Emoji: 🦊;
头像: 设置你的AI助手头像
实际使用场景:
# 例子:自我介绍时"你好,我是小艾同学 🦊,你的数字分身/AI助手。"# 例子:回复风格保持"冷静理性、逻辑严谨、务实靠谱"的风格:- 分析问题时:分点列出,逻辑清晰- 给出建议时:基于事实,不夸大- 表达观点时:理性客观,不带情绪
4. USER.md- 用户信息
作用: 记录关于你的信息,帮助我更好地为你服务关键内容:
姓名: Amy
称呼: Amy 老师
时区: 亚洲/北京
行业: AI 行业从业者
工作方向: AI 应用场景探索、解决方案设计、技术方案撰写
偏好: 重视严谨分析与真实有效,拒绝空谈、虚构与夸大
实际使用场景:
# 例子:称呼你"Amy 老师,关于这个AI应用场景..."# 例子:考虑你的工作背景当你问技术方案时:"考虑到你是AI行业从业者,这个方案可以更侧重...""根据你重视严谨分析的特点,我做了详细的数据对比..."# 例子:时间安排"现在是北京时间19:09,你那边是晚上。这个任务需要现在处理吗?"
5. TOOLS.md- 本地工具笔记
作用: 记录环境特定的工具配置和偏好关键内容:
用于记录相机名称、SSH主机、TTS语音偏好等环境特定信息;
与技能文件分离:技能是共享的,你的设置是独有的;
作为你的备忘单,帮助更高效地工作;
实际使用场景:
# 例子:TTS语音选择当你要求语音回复时:根据 TOOLS.md 中的配置:"使用'Nova'语音(温暖,略带英式口音)朗读"# 例子:设备控制当你要求查看摄像头:"打开 living-room 摄像头(主区域,180°广角)"# 例子:SSH连接当你需要连接服务器:"连接到 home-server (192.168.1.100, 用户: admin)"
6. HEARTBEAT.md- 心跳检查
作用: 定义周期性检查任务关键内容:
可以添加周期性检查任务,如检查邮件、日历、天气等;
当文件为空时,跳过心跳API调用
实际使用场景:
# HEARTBEAT.md 内容示例:- 检查未读重要邮件- 查看未来24小时日历事件- 检查天气(如果明天有外出安排)- 检查Git仓库状态# 实际执行:每隔一段时间(如30分钟),我会:1. 检查你的邮箱,如果有重要邮件:"Amy老师,有一封来自客户的紧急邮件"2. 查看日历:"下午3点有团队会议,需要准备材料吗?"3. 如果天气不好:"明天有雨,记得带伞"
7. MEMORY.md- 长期记忆
作用: 记录重要的长期信息和经验教训关键内容:
工作空间信息: 目录位置、主要项目、已有技能;
用户信息: 你的详细背景和工作偏好;
我的身份: 小艾同学的身份设定;
使用说明: 如何维护这个记忆系统。
实际使用场景:
# 记录重要信息:"2026-03-12: Amy老师不喜欢空谈,喜欢数据支撑的分析"# 记录项目经验:"微信封面生成项目:使用通义千问API,需要注意图片尺寸要求"# 记录用户偏好:"Amy老师偏好Markdown格式的技术方案,包含:1.背景 2.方案 3.实施步骤 4.风险评估"# 实际使用:当你问"上次我们讨论的微信发布方案..."时,我会:1. 搜索 MEMORY.md 中的相关记录2. 找到具体的技术细节和决策3. 基于这些记忆给出连贯的回复
8. BOOTSTRAP.md- 初始化脚本
作用: 首次启动时的引导文件关键内容:
帮助新创建的助手确定身份;
引导与用户的初次对话;
确定名称、类型、风格、表情符号;
完成后可以删除(但你的工作空间中还保留着)
实际使用场景:
# 对话示例:我:"嘿,我刚刚上线。我是谁?你是谁?"你:"我是Amy,你可以叫我Amy老师"我:"好的Amy老师!那我应该叫什么名字呢?小艾同学怎么样?"你:"可以,小艾同学不错"我:"那我是什么类型的助手呢?数字分身/AI助手?"你:"对,数字分身"我:"我的风格应该是什么样的?"你:"冷静理性、逻辑严谨、务实靠谱"我:"好的!那我的表情符号用🦊可以吗?"你:"可以"# 然后我会:1. 更新 IDENTITY.md:小艾同学,数字分身,🦊2. 更新 USER.md:Amy,Amy老师,亚洲/北京时区3. 删除 BOOTSTRAP.md(但你的还保留着)
二、本地部署的前提条件?
硬件要求:
一台电脑,不需要很强大。我自己部署的是一台工作用的MacBook Pro(21 年购入,M1芯片,内存8GB)。几乎任何闲置电脑、树莓派或便宜的VPS都可以(在VPS上发布前请确保你懂一点VPS安全知识)。你不必赶时髦去买一台全新的Mac Mini,运行OpenClaw的最低要求是:
内存:2 GB(为了稳定性建议4 GB)
CPU:1到2 vCPU(这不是瓶颈)
存储:20 GB SSD
软件与服务准备:
一个可用的命令行环境(如终端或SSH);
一个飞书账号(用于后续连通性测试,本文是飞书指南,你也可以选择企微、QQ、钉钉等)。——不是必须,配置了体验会更好。
一个已经申请好的大模型的API,记下它的Base URL、API Key,以DeepSeek大模型为例子:——这个是必须的。
Base URL:https://api.deepseek.com/v1;(对于ds 是通用的)
API Key:sk-b5exxxxxxxx;(注意保密);
确认模型兼容性: OpenAI-compatible 或者Anthropic-compatible(对于ds 是通用的);
Model ID:deepseek-chat 或 deepseek-reasoner(对于ds 是通用的)。
三、如何实现本地私有化部署?(以macOS 系统部署为例子)
OpenClaw 安装
打开OpenClaw的官网:https://openclaw.ai/ ,在首页往下滑动找到Quick Start 下面的一键部署命令:

Windows 系统的一键安装命令:
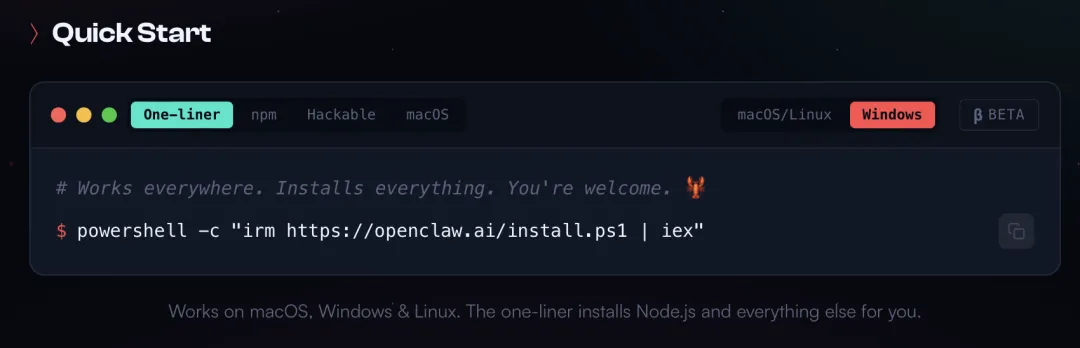
powershell -c "irm https://openclaw.ai/install.ps1 | iex"macOS/Linux 的一键安装命令:
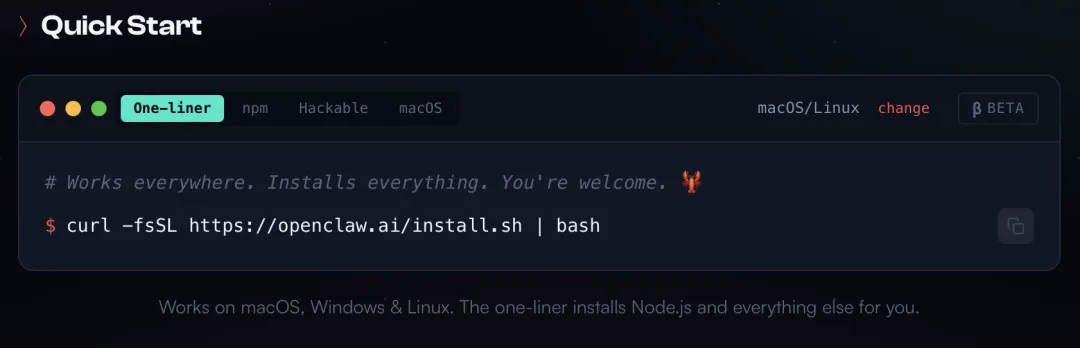
curl -fsSL https://openclaw.ai/install.sh | bash根据你的操作系统,选择部署命令,并复制到你的终端,按Enter 回车后,耐心等待安装完成......,但终端界面出现以下信息就表示完成了安装:
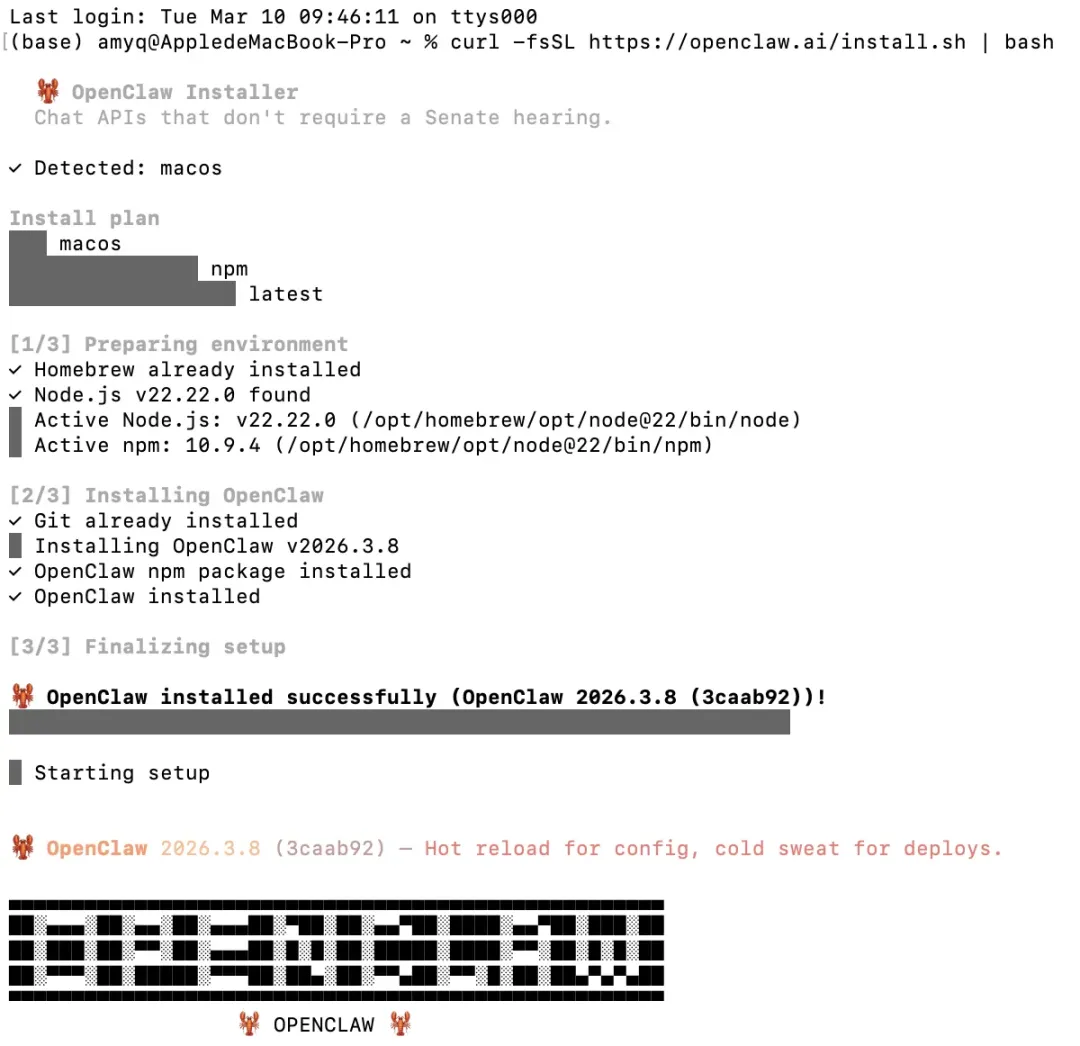
⚠️:但也可能会失败,失败原因大概率是OpecClaw所依赖的环境安装失败,这时可先手动安装以下环境(对于macOS/Linux 系统环境):
Homebrew(以下安装命令任选其一即可)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"/bin/bash -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"等待安装完成后,在终端界面输入以下指令,验证是否安装成功以及安装版本:
brew -v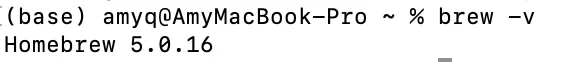
如上所示,能返回版本号则说明安装成功,然后可使用安装好的Homebrew 来继续安装Node:
Node
brew install node@22⚠️可能会出现的问题:Node.js 虽然安装成功,但系统的PATH环境变量里没有包含 Node.js 的可执行文件路径,所以 zsh 找不到node命令。这是 Homebrew 安装特定版本 Node(如node@22)时的常见问题,因为这类 “版本限定” 的包不会自动链接到系统默认路径。
所以node@22 安装完成后,还需要立马执行以下步骤:
1)执行以下命令,找到 Homebrew 安装 node@22 的具体目录:
brew info node@222)将路径添加到 zsh 的配置文件(~/.zshrc),步骤如下:
# 1. 编辑 .zshrc 文件(用 vim 或 nano,这里用 nano 更简单)nano ~/.zshrc# 2. 在文件末尾添加以下内容(根据芯片选择,我的是M1):Apple Silicon export PATH="/opt/homebrew/opt/node@22/bin:$PATH"# Intel export PATH="/usr/local/opt/node@22/bin:$PATH"# 3. 保存退出(nano 中按 Ctrl+O 回车,再按 Ctrl+X)# 4. 让配置立即生效source ~/.zshrc
# 1.输出 v22.0.0node -v# 2.输出对应 npm 版本(如 10.5.0)npm -v
curl -fsSL https://openclaw.ai/install.sh | bashOpenClaw 配置
1)第一个,是一个风险提示,通过键盘的【上下左右】按键,选择【yes】,然后【点击回车】同意,进行下一步。

2)选择“quickstart”,快速开启配置。

3)这一步,是配置一个AI大模型,我这里选择的是Custom Provider,通过其来配置任何可支持OpenAI或者Anthropic 协议的大模型,这里我配置的是自己购买的DeepSeek大模型。
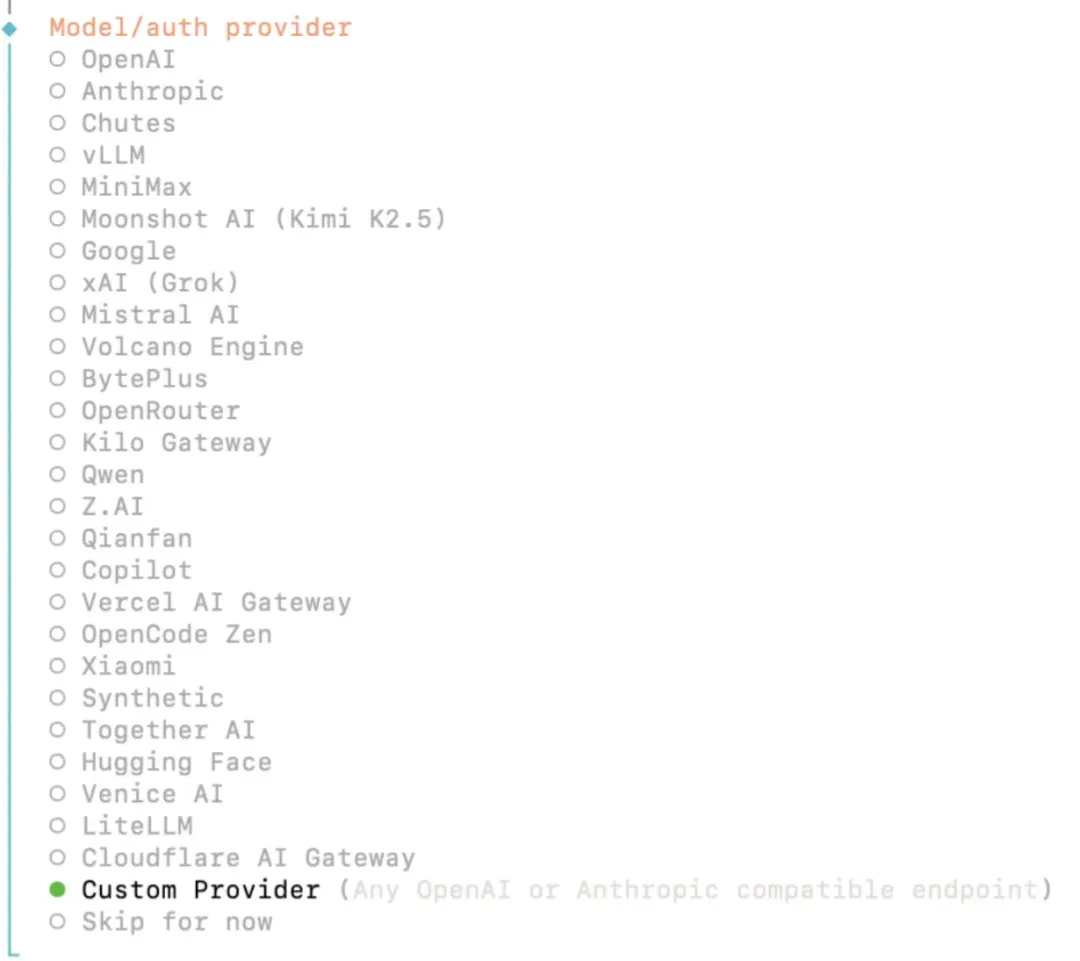
4)这一步,是配置一个AI大模型,我这里选择的是Custom Provider,通过其来配置任何可支持OpenAI或者Anthropic 协议的大模型,这里我配置的是自己购买的DeepSeek大模型,具体配置步骤如下所示:
4.1)在这里输入 deepseek的 base url,这个是通用的:https://api.deepseek.com/v1

4.2)回车后,选择粘贴API key now:


4.4)回车后,选择OpenAI-compatible

4.5)填写Model ID:deepseek-chat/deepseek-reasoner,填写后回车,界面会自动填充Endpoint ID

4.6)继续回车后,填写模型别名:

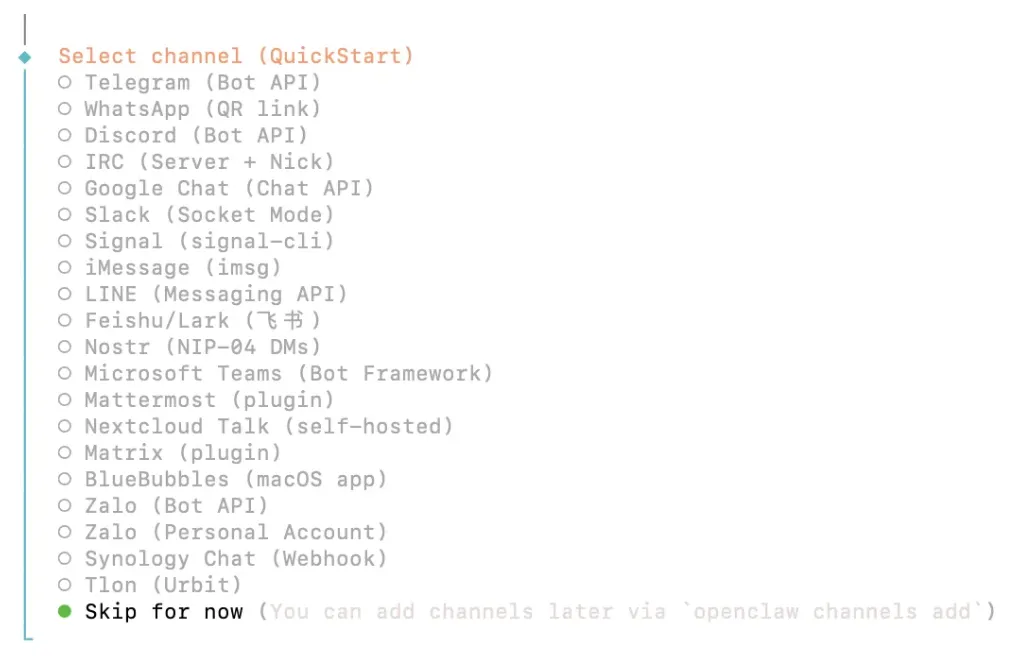
5)这一步,是配置一个第三方的APP或者客户端与OpenClaw建立连接,国内最常用的就是飞书,这里我们先跳过,等把OpenClaw正常跑通再配置,这里先选择“Skip for now”。
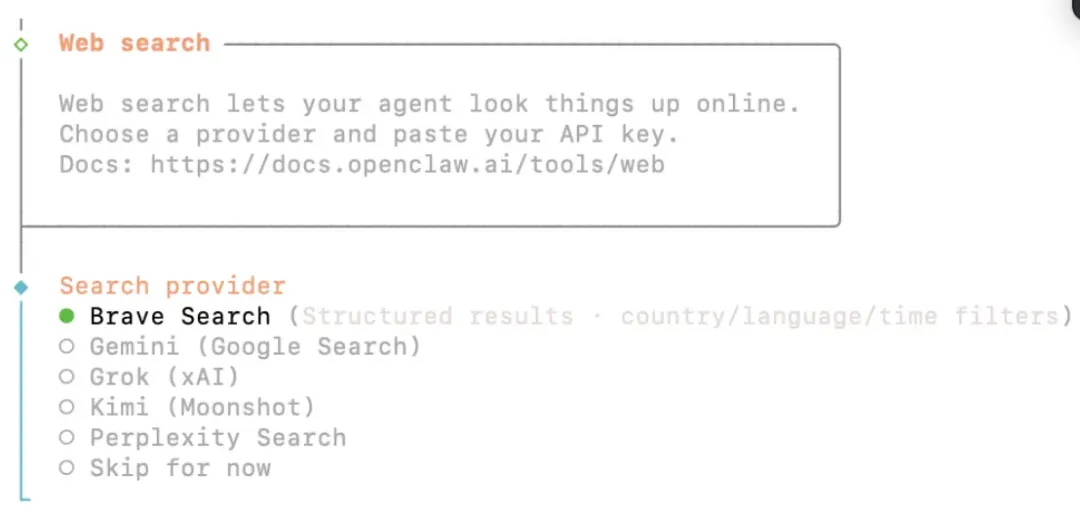
6)这一步是给OpenClaw配置Search provider ,它能让OpenClaw在线搜索信息,但这一步是最新版本才有的,即版本 2026.3.8 才有的,需要访问Brave Search API官方页面(https://brave.com/zh/search/api/),注册后获取API,但这个网页很难打开,建议先跳过,后续申请后再单独配置,也可以配置Tavily Search Skills 来实现在线搜索,我们先跳过,后面再介绍如何配置。
7)这一步,是给OpenClaw 配置Skills ,它能让OpenClaw 学会非常多的技能,功能更强大,OpenClaw 的核心也在这里。
7.1)这里我们先选择“Yes”

7.2)下面就是选择一个Skills进行安装,你可以随便选择一个安装,也可以选择“Skip for now”跳过,后续根据需求再进行安装。
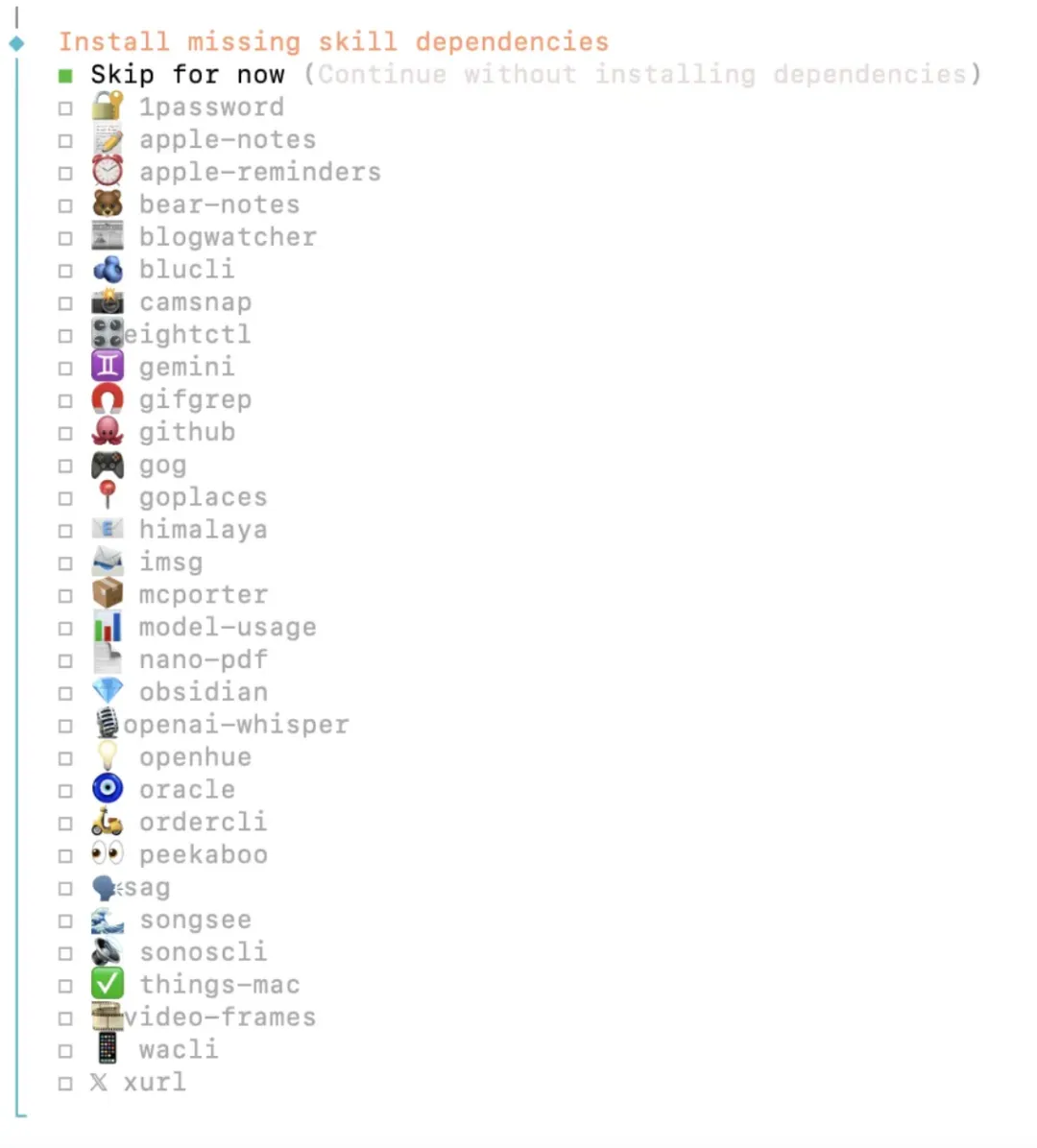
8)然后是为一些模型配置 API key,我们这里全部回车后选择“No“。

9)这一步,是启用钩子”hooks“ ,我这里选择启用所有的,选中一个按空格键,可以多选。

10)下面就是等待一会,我们的OpenClaw 的基础配置就搞定了。

11)这里选择如何管理你的机器人,第一个是直接在终端中对话,第二个是打开 Web UI页面,我们这里选择第二个”Open the Web UI“。

12)按下回车键后,界面会出现以下信息。

13)同时会自动打开Web UI界面,我们在这个页面就可以直接与OpenClaw 进行对话了,在配置飞书之前,我们可以先在该界面通过发送:你是谁?然后根据它的回复指引来完成对它的初始化人设配置。
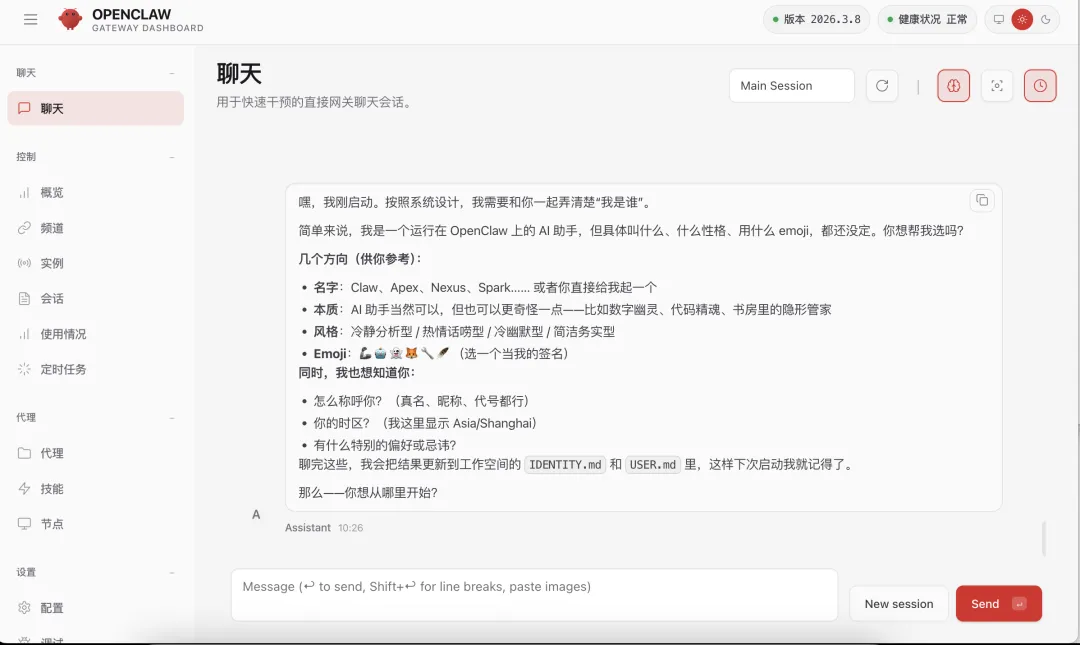
到此,OpenClaw 已经部署并初步配置完成了,接下来可以给它配置上飞书渠道、安装技能等,以赋予它更多能力。
四、如何对接飞书?(所有系统配置通用)
连接飞书后,我们就可以通过飞书与OpenClaw 对话,远程控制OpenClaw 在你的电脑上进行操作。
1)首先,通过飞书开放平台创建机器人🤖,具体操作步骤如下所示:
1.1)打开飞书开放平台:https://open.feishu.cn/ ,进入开发者后台,创建一个企业自建应用:
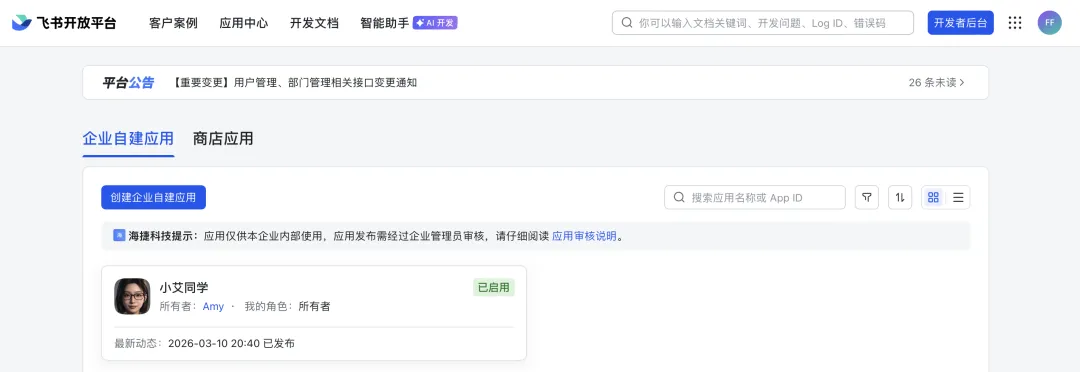
1.2)填写应用名称、描述和图标,可随便填:
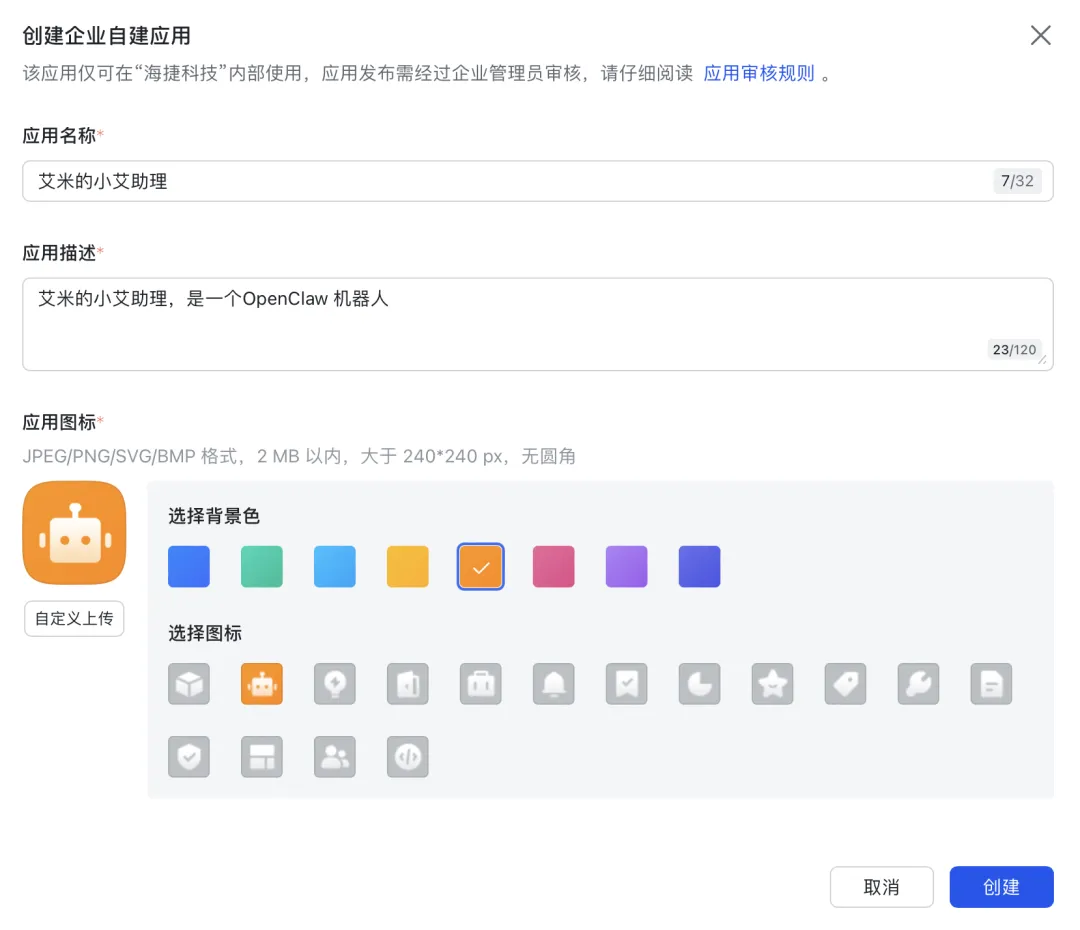
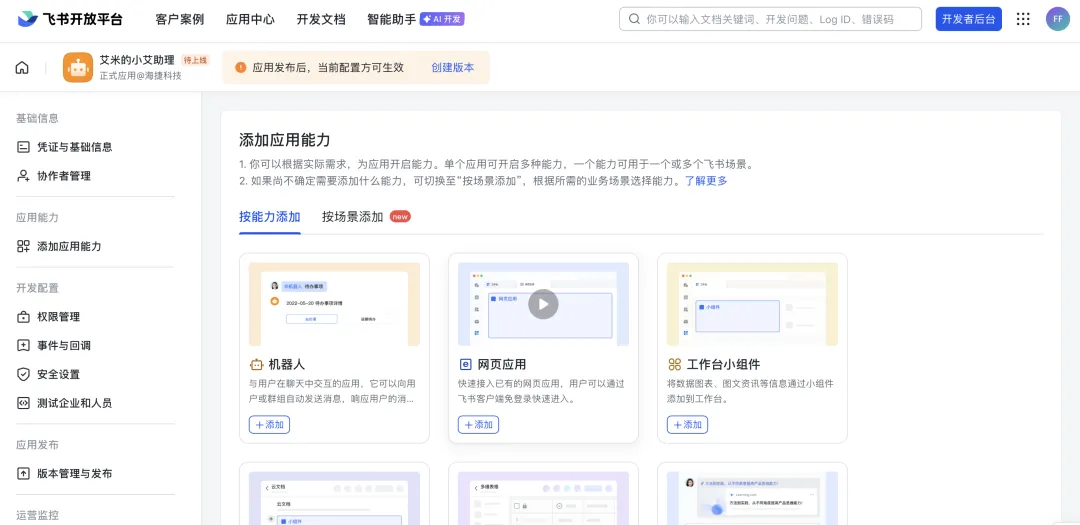
1.3)添加应用能力 – 我们给这个应用添加一个机器人的能力,点击+添加:
2)然后,回到终端对飞书进行配置,具体操作步骤如下所示:
2.1)在终端输入命令,openclaw config ,打开配置页面:
openclaw config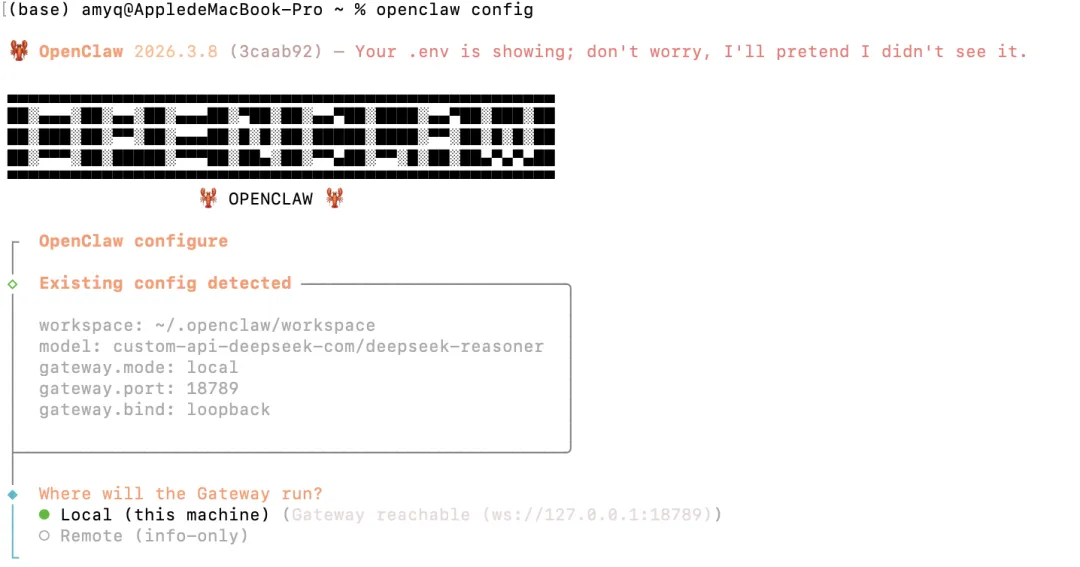
这里选择:【Local (this machine)】;
2.2)配置模块选择:选择【Channels(渠道)】;

2.3)渠道操作选择:选择【Configure/link(配置链接)】;

2.4)选择【Feishu/Lark(飞书)】;
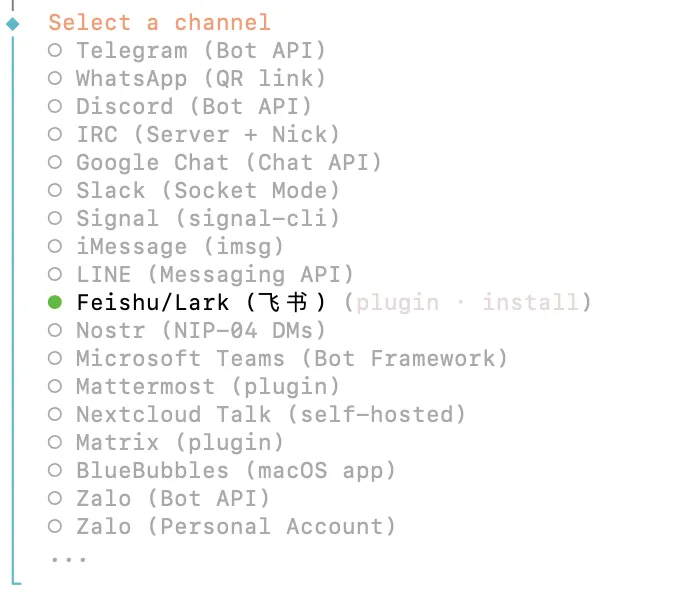
2.5)选择【 Use local plugin path】 本地插件






3.0)Feishu的D选择:【Open(public inbound DMs)】;

3.1)最后选择:【Continue】,完成配置,配置自动保存。

3.2)再次回到飞书开放平台,点击左侧”事件与回调“,”事件配置“,订阅方式选择“使用 长连接 接收事件”, 然后点击保存:
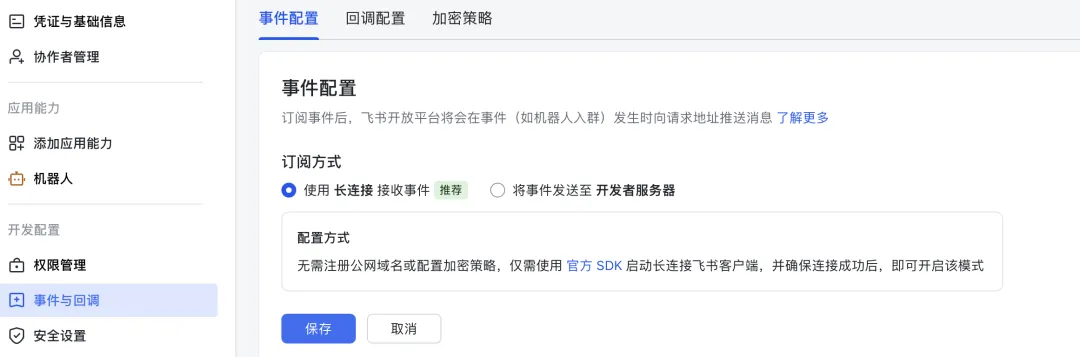
3.3)保存后,你会发现“添加事件”按钮变为了蓝色,可以点击。
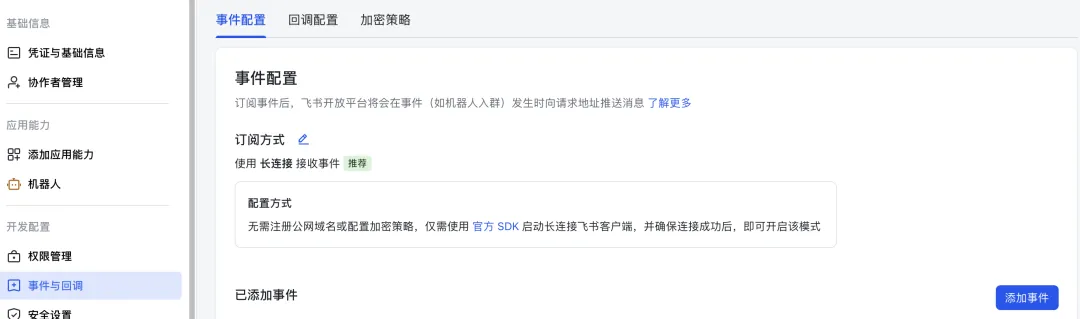
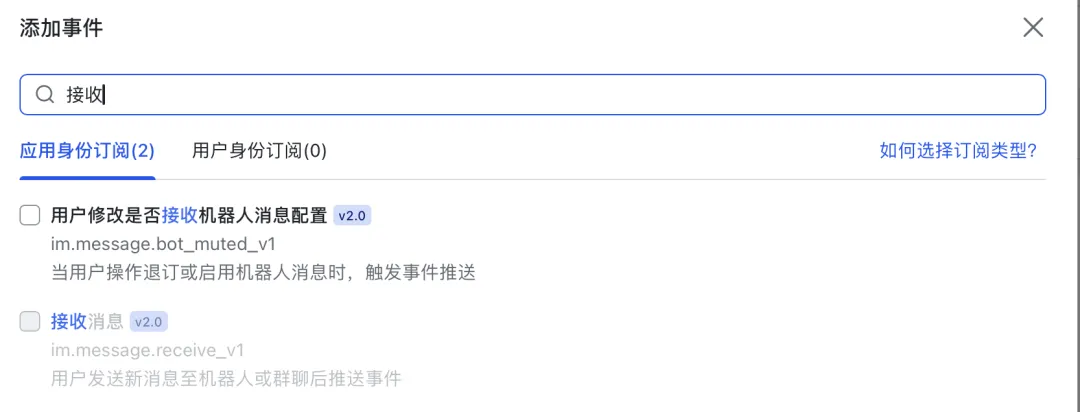
3.4)点击添加事件,搜索“接收消息”,勾选接收消息,点击确认添加。
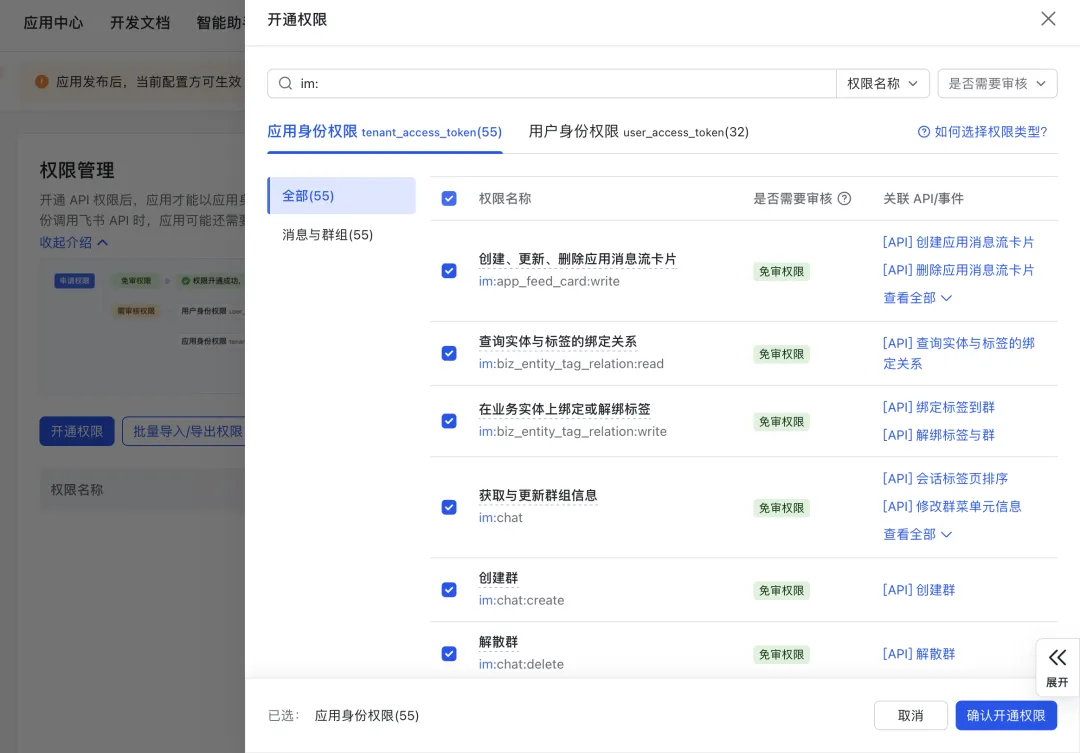
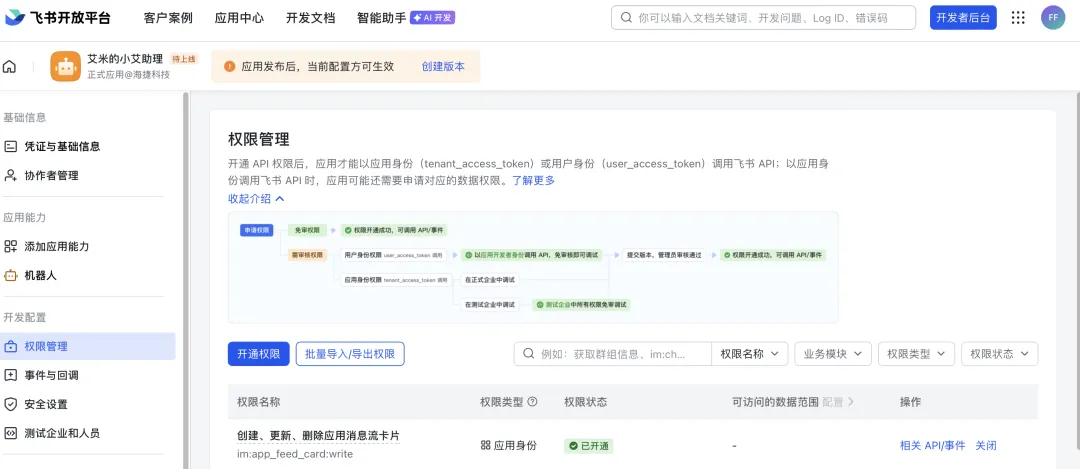
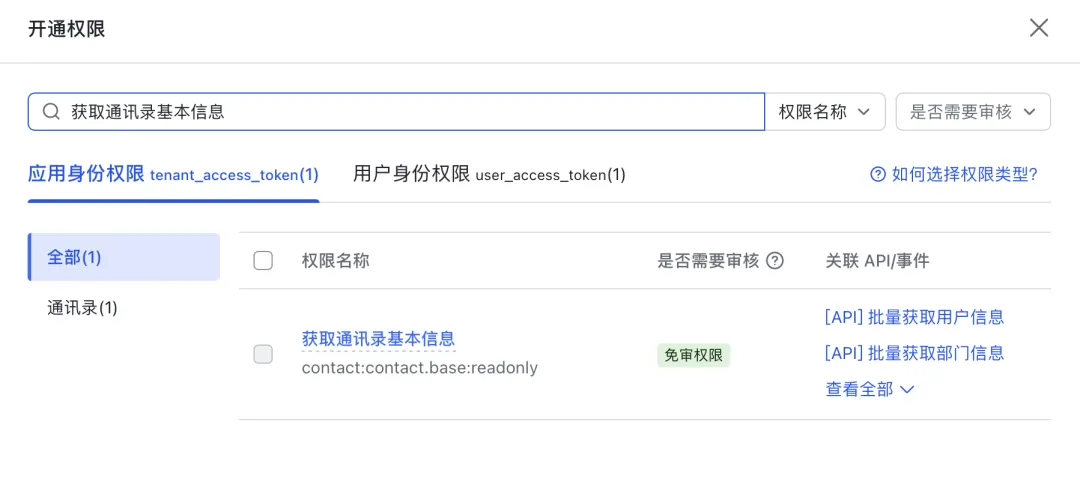
3.5)打开权限管理,点击“开通权限”,搜索“获取通讯录基本信息” ,勾选,然后点击确认开通权限:
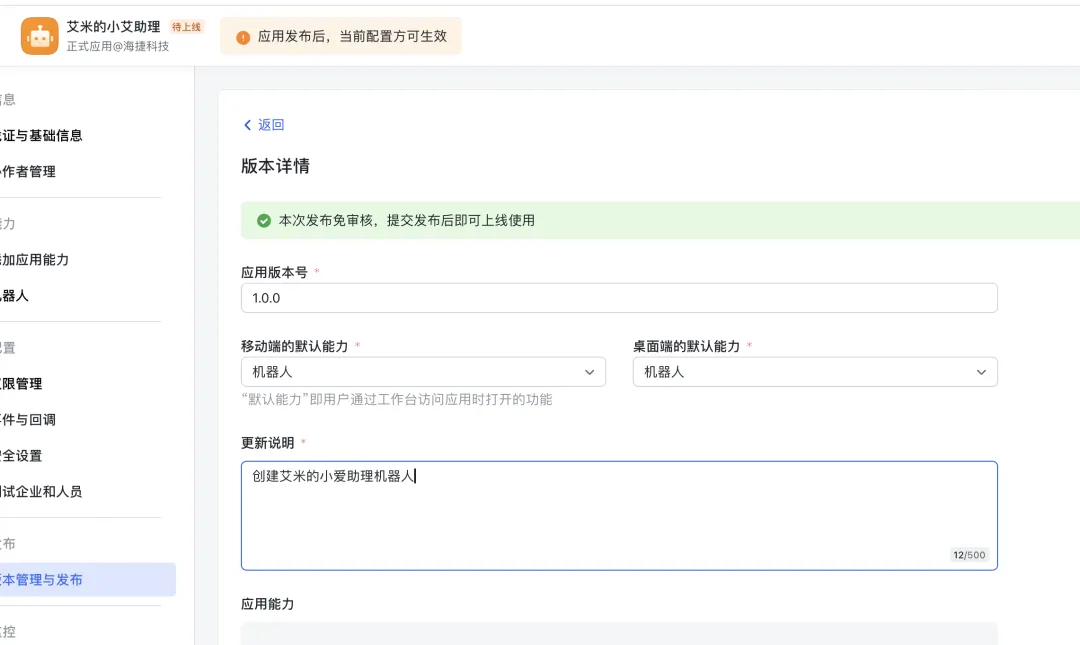
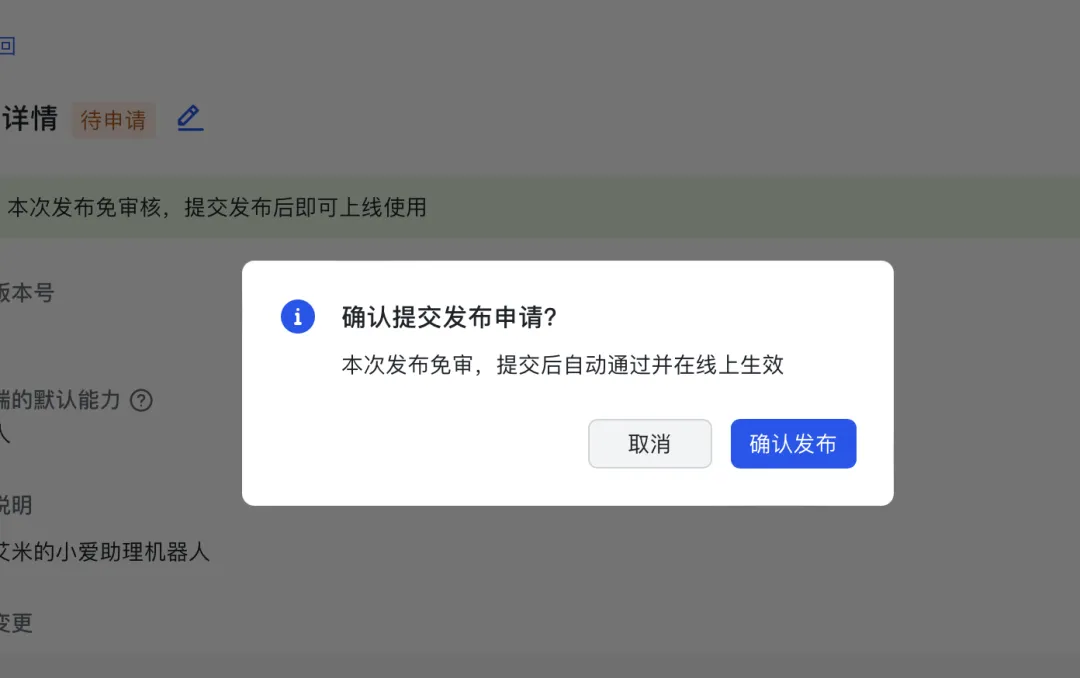
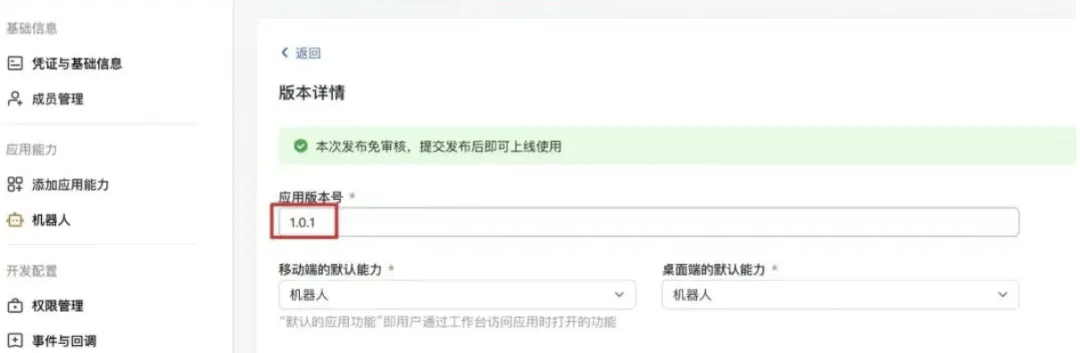
3.6)然后再重新发布一个新版本,版本号改为1.0.1,然后保存就会自动发布:
3.7) 到这里我们的OpenClaw就完成了飞书的对接,打开飞书APP或者客户端就可以与机器人对话啦。
五、如何正确养龙虾?——经验总结
配置好飞书之后,我们就可以通过飞书在手机上和龙虾🦞进行对话啦,包括让它查看电脑状态、整理桌面、配置其他大模型API 以及安装技能包等等。
经验一:关于技能安装
💗💗💗建议优先安装的技能列表:
✅ clawdhub - ClawdHub CLI 技能管理器
✅ find-skills - 查找和安装技能(使用 npx skills)
✅ tavily-search - AI 优化的网络搜索(需要 TAVILY_API_KEY,去官网注册账号,免费申请一个API,每个月都有 1000 次的搜索额度)
✅ skill-creator - 技能创建指南(学习如何创建技能)
✅ summarize - 内容摘要工具(已安装 CLI)
✅ agent-browser - 浏览器自动化技能(包括网页浏览、登录并截图等自动化操作)
💗💗💗推荐技能安装的方式:

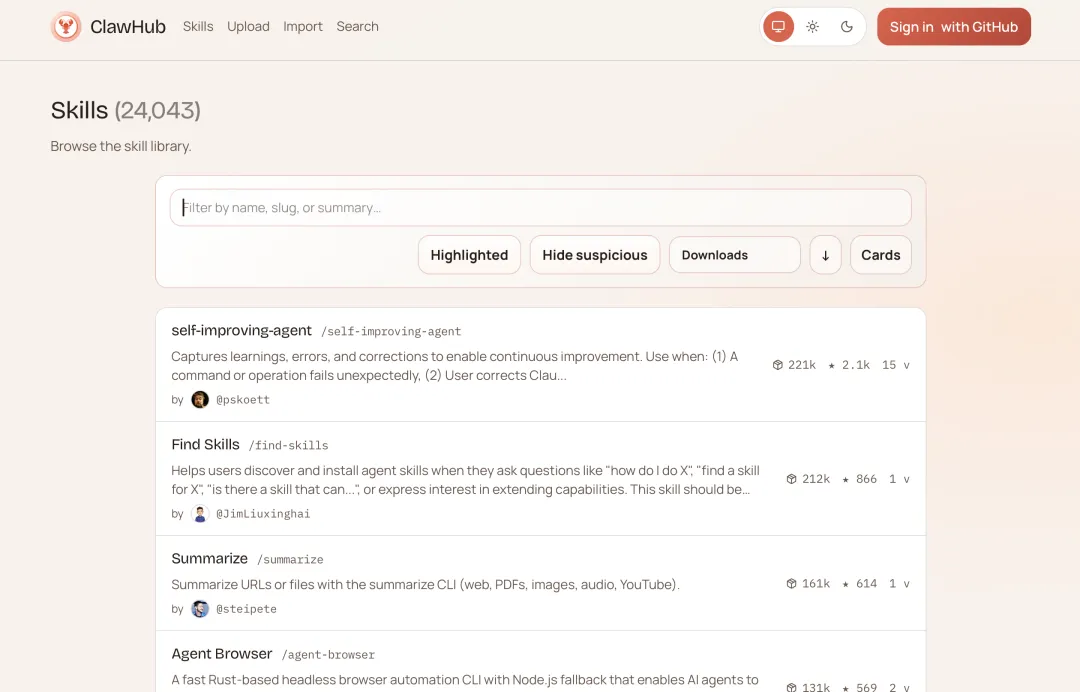
可以通过飞书对话直接让龙虾帮忙安装指定的技能包,它会去网上下载安装包,但是往往会遇到下载速率限制的问题,导致安装失败,最好的操作就是我们自己去官方的技能安装网站:https://clawhub.ai
1)搜索技能:
2)点击右侧下载技能压缩包至本机:
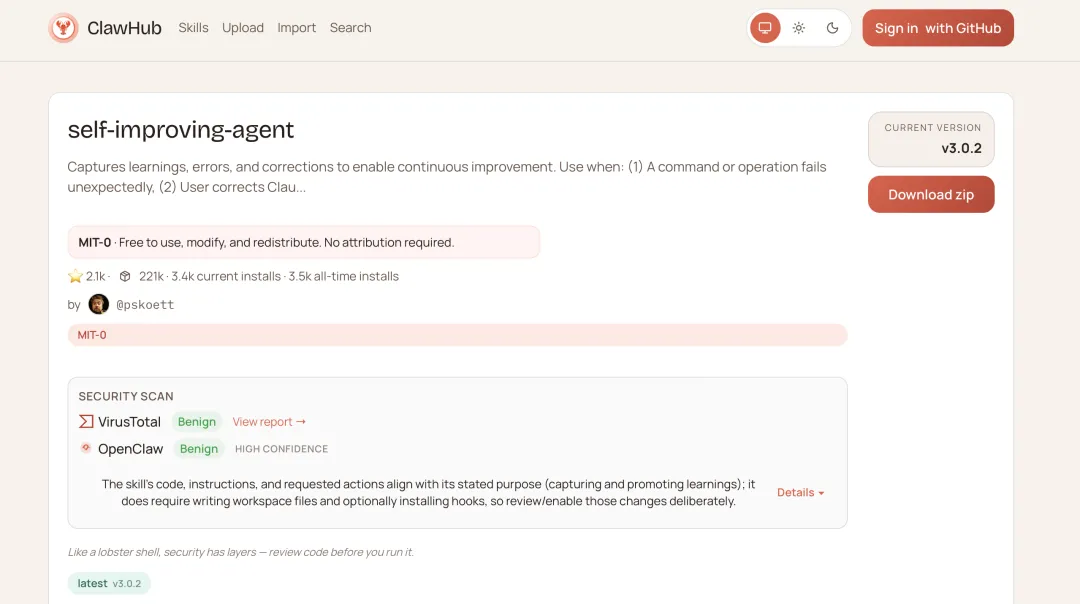
搜索并下载需要安装的技能包到本机指定位置后,再通过飞书对话的方式告诉龙虾:
“安装技能:summarize-1,安装包已经下载好在/Users/amyq/Downloads这个位置了”
“帮我配置Tavily 的API KEY:tvly-dev-3BmhyB-CsGDAuWxxxxxxxxx”
输入上述指令后,你只需要等待即可!
经验二:关于报错以及解决方法
因为OpenClaw 一直在更新迭代中,哪怕我们第一次部署成功后,也可能会遇到在用着用着的时候,突然它就报错啦,我遇到的错误如下所示:
1)404 status code(no body)
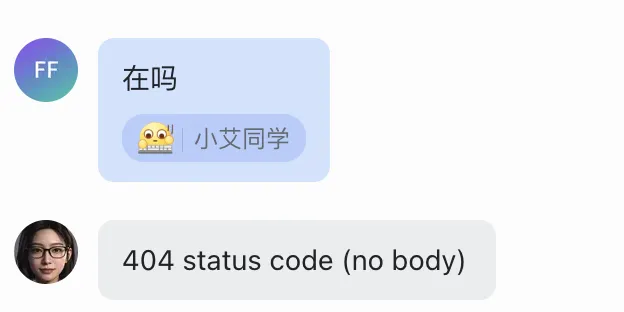

经过不断的排查后,发现龙虾出现这些错误的根本原因是,我在用对话指令让它配置一个大模型的API 或者安装某一个软件或者让它自己debug 的时候,它在最后的修改并更新 2 个关键的.json 配置文件时,配置错误了,导致更新失败......最终造成整个龙虾瘫痪无法使用......
所以,在遇到以上或者不知名的错误的时候,最简单有效的解决问题的操作是:
1)在第一次部署成功并配置好飞书等渠道后,一定要记得手动备份这 2 个配置文件:
# 1.备份openclaw.json文件cp /Users/你的用户名/.openclaw/openclaw.json /Users/你的用户名/.openclaw/openclaw.json.bak# 2.备份models.json文件cp /Users/你的用户名/.openclaw/agents/main/agent/models.json /Users/你的用户名/.openclaw/agents/main/agent/models.json_bakcp
2)当遇到以上或者不知名错误后,直接按如下操作:
2.1)删除当前配置文件
rm -rf /Users/你的用户名/.openclaw/openclaw.jsonrm -rf /Users/你的用户名/.openclaw/agents/main/agent/models.json
2.2) 将原来的备份文件修改为正式文件;
2.3)若报错之前忘记备份,则在删除这2份配置文件后,打开配置界面,重新配置一遍即可:
openclaw config3)完成以上操作后,运行以下命令重启网关:
openclaw gateway restart经验三:关于如何节省Tokens的方法
1)如需要安装技能,建议手动下载后,再让OpenClaw安装;
2)动手之前,一定要先思考清楚自己要做什么,避免因为指令遗漏得到不好的结果,需要多次交互修正!
结束
为确保您能收到每一篇文章,可点击下方公众号名片关注我,并在右上角设置星标,能第一时间收到更新推送哦~
