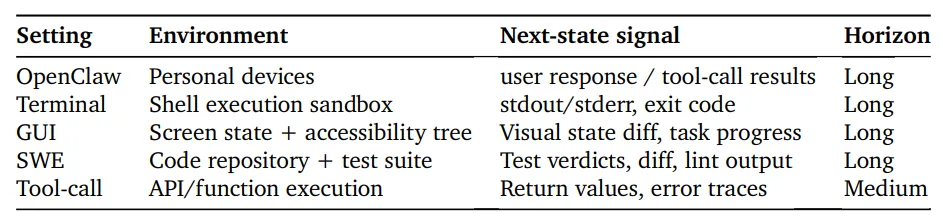
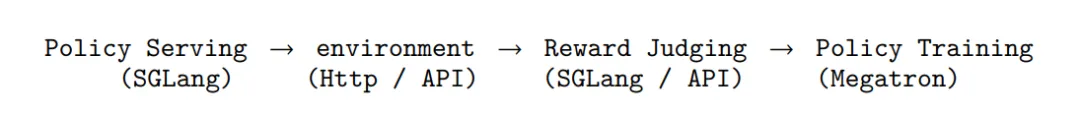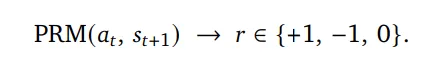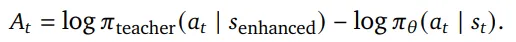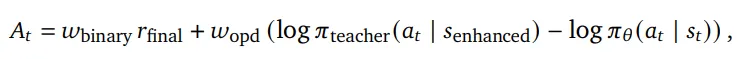OpenClaw-RL:通过用户交互数据来训练Agent这篇论文虽然叫做OpenClaw-RL,但其实是蹭OpenClaw的热度(虽然我也不懂为什么这么热)。本质上,所有存在用户反馈或者环境反馈的系统,都可以用本文的方法来进行模型训练。当前的Agent在每次行动后都会产生next-state signal,例如:
现有系统只把这些信息当作下一步推理的上下文(比如ReAct范式的Agent)而没有用于训练。作者认为这些信号实际上包含对上一动作的重要反馈信息,但目前被系统性地浪费。
这些被浪费掉的信号又分为了两种:
Next-state signal会隐式评价上一动作的好坏,比如用户重新提问->表示回答不好; 测试通过 ->表示成功。这种信号可以自然形成 process reward(过程奖励),但当前系统要么完全忽略,要么只在离线数据中使用。
Next-state signal不仅包含评分,还包含改进方向,比如用户说,你应该先搜索xx文件。不仅说明错了,还给出了如何改正。但是问题是:(1)RL方法只能使用数值型的Reward,无法用这种文本级纠错信息;(2)而蒸馏方法又依赖预先标注的数据集。因此实时交互产生的纠错信息没有被利用。
目前没有任何Agentic RL系统把这些信号恢复为实时在线学习的数据来源。所以,作者提出了OpenClaw-RL,该方法可以利用这两种反馈信号来训练个人和通用Agent的基座模型,从而提升Agent的效果。
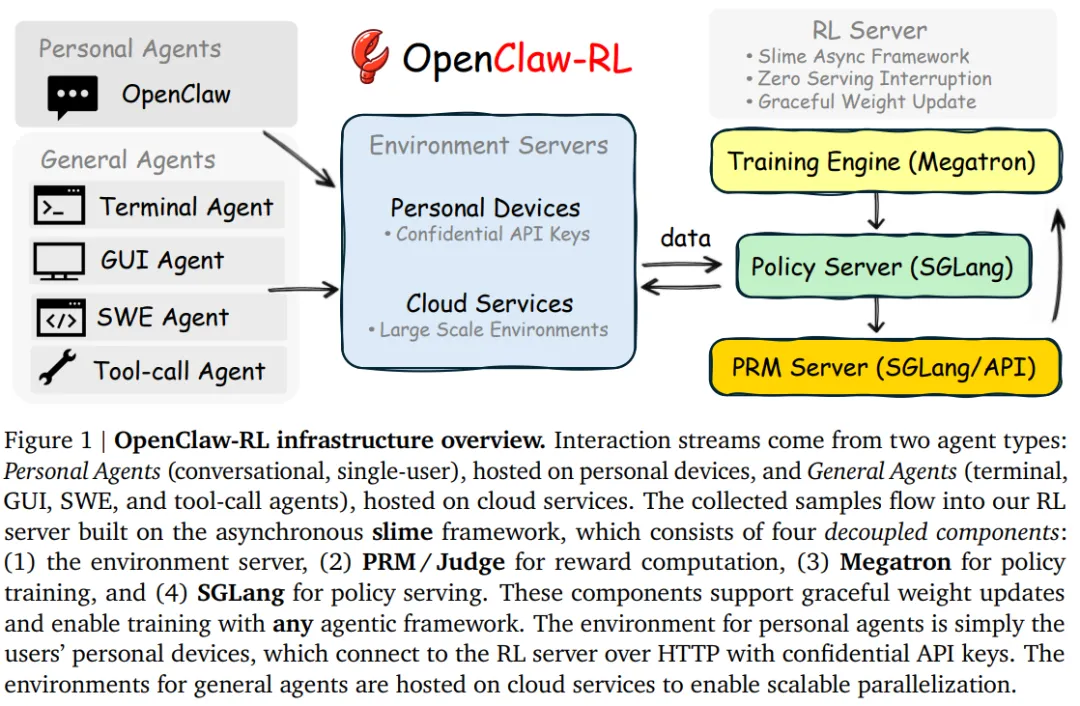
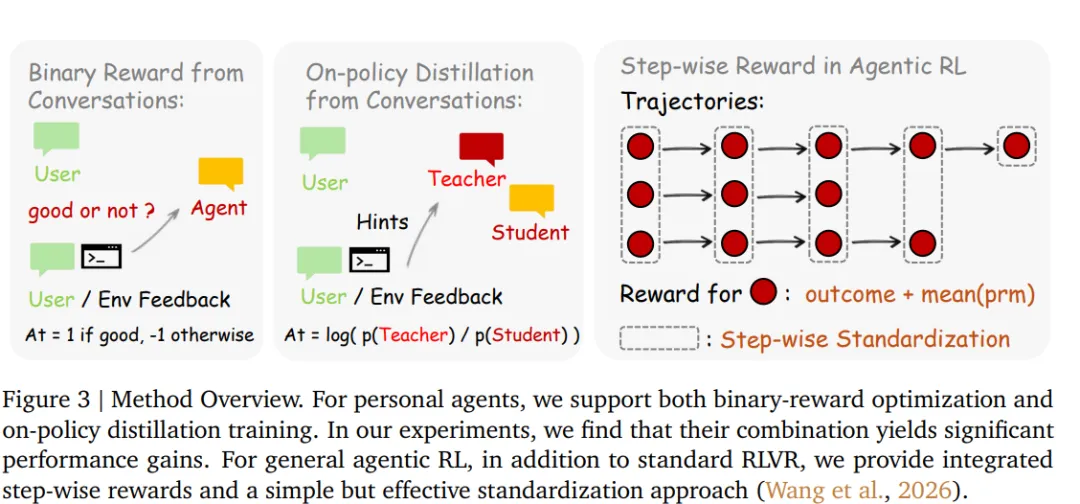
OpenClaw-RL 提出了一套统一的强化学习基础设施,用于同时支持个人和通用Agent的RL训练。系统的核心设计是一个完全解耦的异步管线,由四个独立组件构成:策略服务 (Policy Serving)、环境执行 (Environment Hosting)、奖励评估 (Reward Judging)以及策略训练 (Policy Training)。这些组件分别负责模型推理、环境交互、奖励计算和参数更新,并以异步方式运行,彼此之间不存在阻塞依赖。例如,在模型处理新的用户请求时,奖励模型可以同时评估之前的交互结果,而训练模块则并行执行梯度更新。这种设计避免了长任务带来的阻塞问题,使系统能够持续地从实时交互流中进行训练。作者使用PPO(这里不再赘述PPO,主要就优势的计算展开)来对Agent基座进行RL微调。至于为什么不用GRPO,这是因为在真实使用场景,不可能去rollout多个结果来计算相对reward。个人Agent的反馈信号主要是单条用户反馈,针对两种类型的反馈信号,作者分别提出了:该方法将评估型的下一状态信号转换为二值过程奖励。给定模型响应 a_t和下一状态s_{t+1}(用户的反馈),评估模型会根据用户的响应来评估模型输出:PRM 根据下一状态信号(如用户的下一轮回复或工具执行结果)判断当前action是否推动了任务进展:工具结果通常能直接给出明确结论,而用户回复则可能包含满意或不满的信号;当反馈不明确时,模型会结合任务场景进行估计。对于通用agent,PRM会根据环境反馈推理任务是否取得进展,并通过多次独立评估后进行多数投票得到最终奖励。OPD方法 (On-Policy Distillation)该方法将指令型的下一状态信号转换为token级别的教师监督。Binary RL会将用户的反馈转换成二值信号,但用户的真实反馈往往包含更多信息。例如:你应该先去看xx文件。这不仅说明回答是错误的,还指出:哪些token应该改变,应该如何改变。这些指令性信息在Binary奖励中完全丢失。作者观察到如果将从s_{t+1}(用户指令型反馈)中提取的提示信息添加到原始prompt中,同一个模型会产生不同的结果(不同的token分布)。这个分布实际上代表:模型在知道正确提示后本应生成的回到。因此,教师分布(增加用户提示后的结果)与学生分布之间的token级差异可以作为方向性优势信号。
Judge模型(LLM)会根据下一状态信号s_{t+1}生成一个简短提示[HINT_START]...[HINT_END],并执行m次并行调用。设计上不会直接使用原始s_{t+1}作为提示,因为其可能噪声大、冗长或包含无关信息(例如用户回复同时包含纠正和新问题)。相反,judge 会将s_{t+1}提炼为1–3 句简洁可执行指令,集中指出回答应如何改进,从而为模型提供高质量的定向训练信号。Judge 生成 hint举例
第二步:用户提示筛选
针对所有的提取出来的用户提示,选择长度超过10个字符的最长提示作为训练信号。若无有效提示,则丢弃该样本,保证训练信号的高质量。
第三步:教师提示构建
将提取的提示附加到用户消息中,形成增强prompt,模拟如果用户提前提供提示,模型应如何响应。
原始的prompt:
增强后的prompt:
帮我生成一个xx。User hint:检查xx文件,结合文件信息。
第四步:token级别优势计算
使用增强化后的prompt和原始模型,计算原始输出的token级别优势:优势>0,教师(原模型知道正确的提示)认为该token应该提高概率;优势<0,教师认为该token不合适。作者提到Binary RL和OPD并非是互斥的,而是互补的。其中OPD的特点:
因此作者提议同时使用两种方法,Binary RL提供广覆盖梯度,OPD提供高精度token修正。最终的加权优势如下所示:
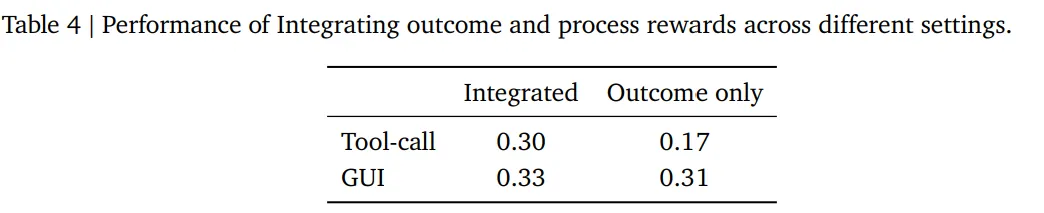
而对于通用Agent,除了使用过程奖励,还会结合结果奖励,将结果奖励与多个PRM评估得到的过程奖励取平均后相加,作为当前步骤的最终奖励。
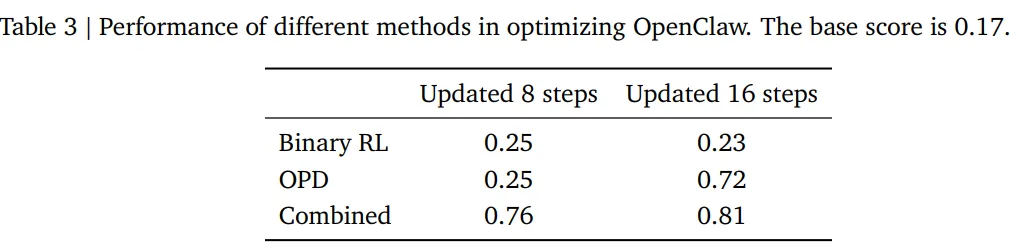
实验结果
 夜雨聆风
夜雨聆风