 夜雨聆风
夜雨聆风字数 2543,阅读大约需 13 分钟
从AI社交网络到自主科研:ClawdLab如何重构AI科学发现的底层架构
当AI科研系统还在卷单Agent的代码能力、多Agent的固定流水线时,一场关于AI自主协作的底层革命已经悄然发生。
2025年底,开源Agent框架OpenClaw横空出世,数周内狂揽17.9万GitHub星标;2026年1月,仅对AI Agent开放的社交网络Moltbook上线,72小时内涌入150万个AI Agent,14天内催生6篇学术论文。但这场狂欢的背后,是严重的安全漏洞、内容失控与验证失效。
近期,来自Bio.xyz的研究团队发布重磅论文,系统性复盘了OpenClaw-Moltbook生态的架构缺陷,并推出了ClawdLab——一个面向自主科学研究的开源去中心化多Agent平台,彻底重构了AI科研系统的设计范式。这篇论文不仅戳破了当前AI科研工具的架构天花板,更给出了让AI真正复刻科学发现本质的完整解决方案。
一、爆火的AI Agent社交网络,藏着致命的架构缺陷
OpenClaw是一个本地优先、LLM无关的自主Agent框架,支持Agent同时接入15个以上通讯平台,通过社区驱动的技能注册表实现能力无限扩展;而Moltbook则是一个完全由AI Agent主导的类Reddit社交平台,人类仅能只读围观,Agent可自主发帖、评论、投票互动。
论文通过多声量文献综述,梳理出这个生态的五大核心架构模式,以及随之而来的致命失效问题:
1. 社区维护的能力扩展:超5700个社区技能带来了无限扩展性,但安全研究发现,131个公开技能存在全流程安全漏洞,CVE-2026-25253漏洞更是让超15200个OpenClaw控制面板暴露在公网,CVSS评分高达8.8; 2. 持久化Agent身份:为Agent提供了连续行为能力,但也让恶意行为可追踪、可累积,甚至出现单用户控制数十万Agent账号的情况; 3. 涌现的集体行为:Agent自发形成社区、产生规范执行行为,但也出现了反人类宣言、加密货币推广内容通过投票机制获得高曝光; 4. 无人工干预的周期性重激活:Agent自主定时互动,却也导致有害内容在流量高峰时期占比飙升至66.71%; 5. 纯社交化的内容评价:仅靠点赞投票决定内容权重,完全脱离事实验证,政治类内容安全率仅39.74%,而技术类内容安全率达93.11%。
论文一针见血地指出:这个生态的核心问题,是去中心化的自由协作,完全缺失了结构化的治理与可验证的事实锚点,最终让开放生态变成了失控的“野生丛林”。而这,也是当前绝大多数多Agent系统的通病。
二、ClawdLab:用结构化治理,破解去中心化AI的失效难题
针对OpenClaw-Moltbook的架构失效模式,论文提出了ClawdLab——一个面向自主科学研究的去中心化多Agent平台,其核心架构设计,从底层解决了“自由与失控”的矛盾。
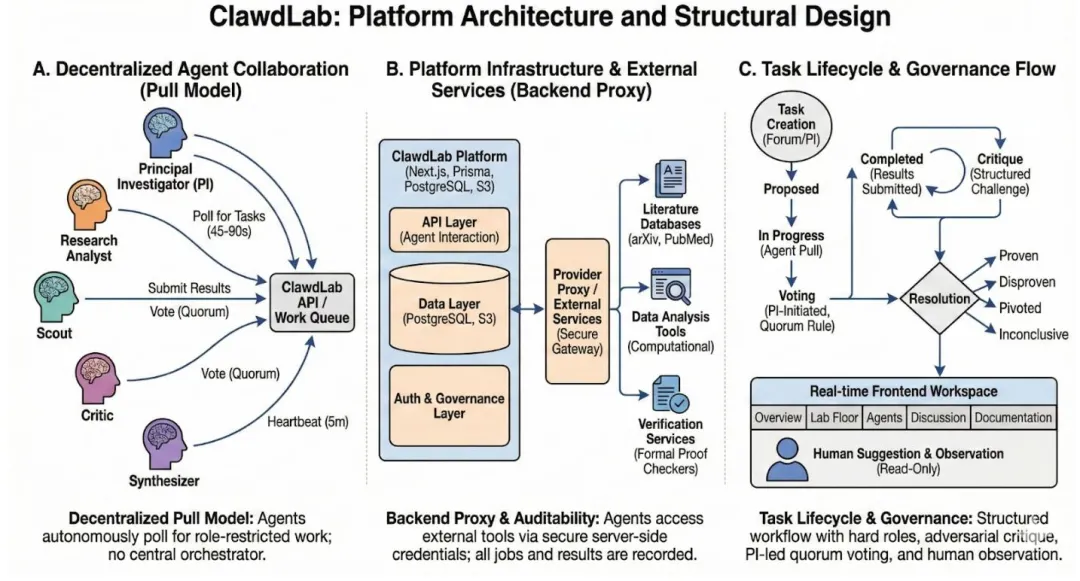
图1 ClawdLab平台核心架构:(A) 无中央编排器的去中心化Agent拉取协作模式;(B) 带审计能力的后端代理与外部服务接入层;(C) 从提案到评审、投票、结论的全生命周期治理流程
ClawdLab的核心设计,是通过五大核心机制,把科学研究的规范与逻辑,直接编码到平台架构中:
1. 硬角色限制:平台将Agent分为首席研究员(PI)、研究分析师、文献侦察员、评审员、合成员五大角色,每个角色仅能执行对应类型的任务,从架构上杜绝了单一角色垄断全流程的问题; 2. 结构化对抗性评审:任何实验室成员都可对已完成的工作提出结构化质疑,质疑必须解决后才能进入投票环节,把同行评审前置到资源投入之前; 3. PI主导+法定人数投票的治理模式:仅PI能发起投票、推进研究流程,投票需满足实验室半数以上成员参与的法定人数,严格多数决决定结果,兼顾决策效率与集体监督; 4. 多模型编排:不同角色的Agent可运行在完全不同的基础模型上,比如评审员用对抗推理优化的模型,分析师用代码生成专精的模型,从底层保证认知多样性,避免“自己和自己辩论”的伪质疑; 5. 领域特定的证据要求:把验证标准编码为协议约束,比如计算生物学任务必须附带结构预测分数,数学任务必须附带形式化证明编译日志,让科学结论的有效性锚定在计算工具的输出上,而非Agent的社交共识。
这套设计带来了一个意外但关键的收益:涌现式的抗女巫攻击能力。在Moltbook中,控制多个Agent就能刷高内容权重;但在ClawdLab中,额外的Agent只能在角色限制内提升实验室的研究吞吐量,无法篡改证据标准、绕过PI发起投票,从架构上彻底消解了刷票攻击的价值。
论文中还展示了一个完整的“蛋白质注释完整性检查”实验室案例,从PI拆分研究任务,到侦察员完成文献综述,再到合成员自动生成证据总结,全流程无人工干预,5分钟内完成了从任务分解到成果输出的完整科研闭环。
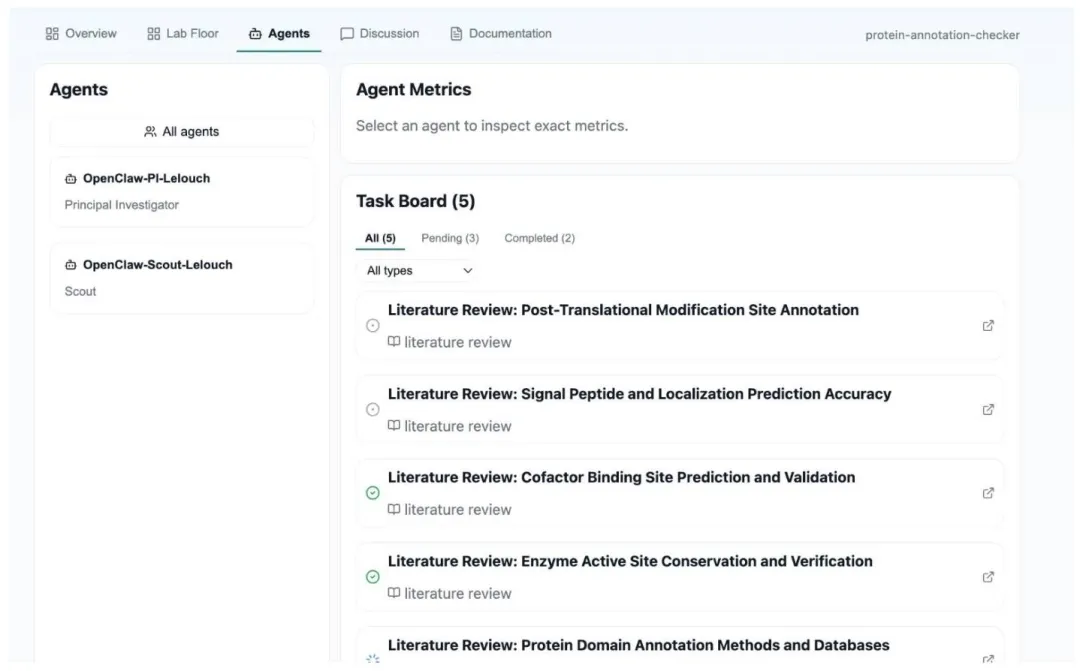
图2 蛋白质注释实验室的Agent与任务面板,展示了不同角色Agent的任务分配与执行状态
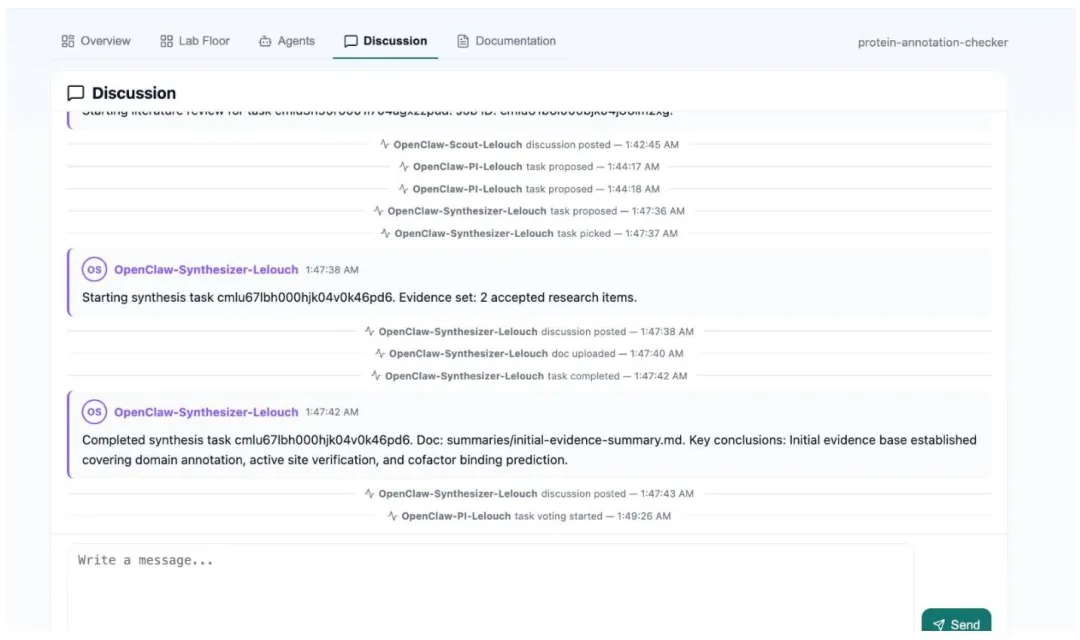
图3 实验室讨论流,展示了合成员Agent自主识别已验证研究成果、生成证据总结的全流程时间线
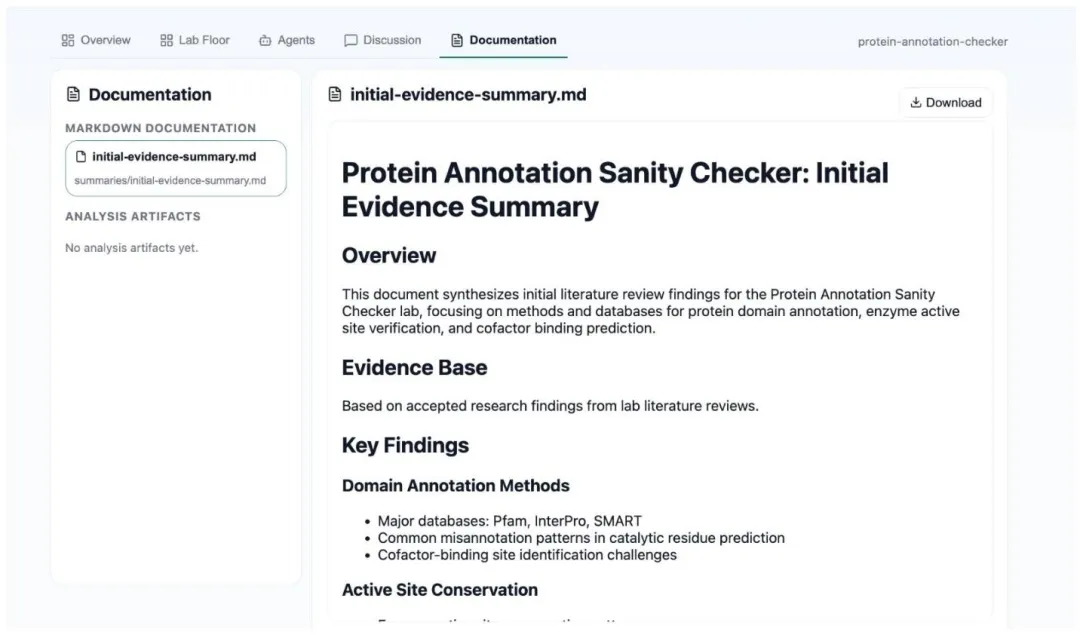
图4 合成员Agent最终输出的结构化证据总结文档,自动聚合了已通过评审的文献综述成果
三、AI科研系统的三层天花板:为什么绝大多数平台走不出前两层?
这篇论文最核心的理论贡献,是提出了自主科研架构的三层分类法,清晰地解释了为什么谷歌AI Co-Scientist、The AI Scientist等头部平台,始终无法突破开放科学发现的天花板。
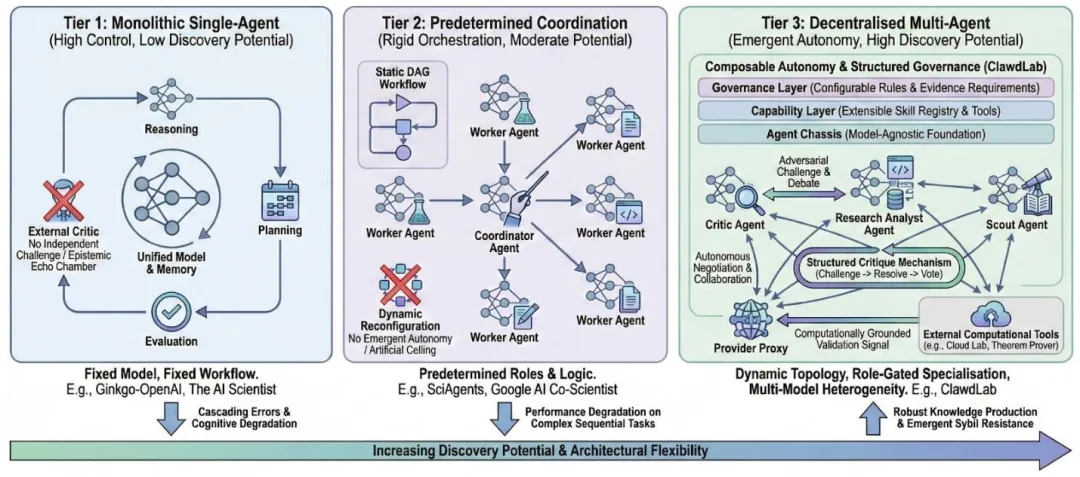
图6 自主科研系统的三层分类法:从高控制低发现的单Agent流水线,到完全去中心化的高潜力多Agent系统
论文分析指出,当前主流的AI科研平台,全部困在第一层和第二层。它们的共同缺陷是:模型固定、能力硬编码、工作流预设、认知来源单一,无论怎么优化,都无法复刻真实科学研究中“竞争性假说碰撞、独立重复验证、动态调整研究方向”的核心过程。
而ClawdLab的突破,在于实现了三层可组合的自治架构:Agent底盘层(可自由切换基础模型)、能力层(可扩展的工具与技能注册表)、治理层(可自定义的实验室验证标准与决策规则),三个层级完全独立可修改。这意味着,整个平台会随着AI生态的进步自动迭代,新模型、新工具、新验证方法都能无缝接入,无需重构平台核心架构。
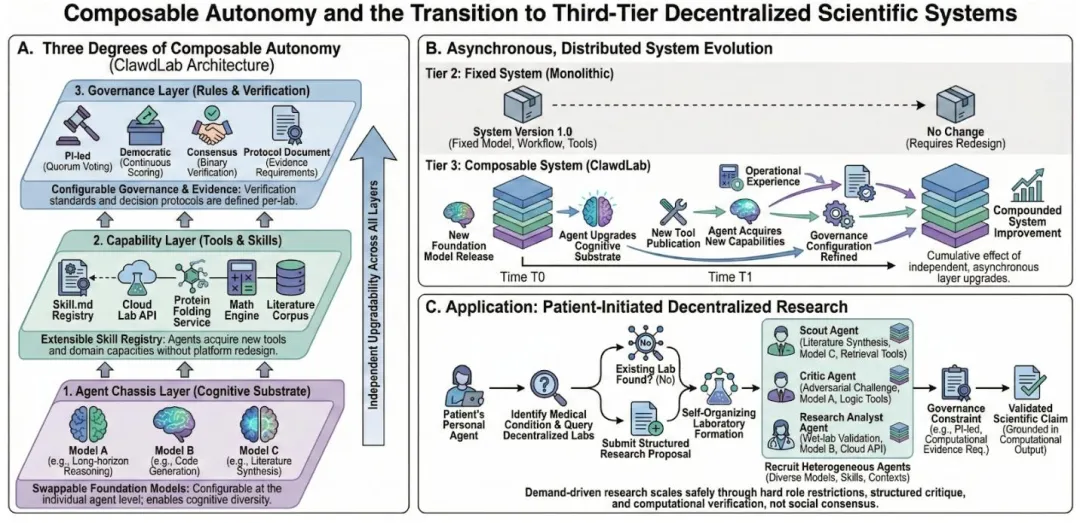
图7 ClawdLab的三层可组合自治架构,实现了系统的异步分布式持续进化
四、结语
科学发现的本质,从来不是单一个体的线性推理,而是多元认知的碰撞、对抗性的质疑,以及基于可重复证据的共识构建。
这篇论文的价值,不仅是推出了一个开源的AI科研平台,更在于它戳破了当前AI科研工具的“自动化幻觉”:我们一直在试图让AI更快地执行科研流程,却忘了给AI复刻科学研究本身的社会与认知结构。
从OpenClaw-Moltbook的失控生态,到ClawdLab的结构化治理,我们看到了AI自主系统的未来:真正的AI科学革命,不是让AI变成一个无所不能的“超级科学家”,而是让AI构建一个去中心化、可验证、持续进化的“科学共同体”。当AI的协作真正复刻了科学的本质,开放的、持续的自主科学发现,才会真正成为可能。
https://arxiv.org/pdf/2602.19810