 夜雨聆风
夜雨聆风最近很多人开始“养虾”(Claw 是龙虾螯的意思)。为什么叫“养”?因为 AI Agent 不再是“配置一次就能用”的工具,而是需要持续照料、共同成长的伙伴。 你要教它记住什么、忘掉什么,要调整它的价值观和行为准则,要像养小动物一样参与它的成长。这听起来很麻烦,但其实挺有意思——正是这种“麻烦”,让 AI 有真正的记忆、人格和进化能力。而这些能力的最终目的,是让它真正理解你、配合你,成为一个越用越顺手的得力助手。
“养”的核心,就是让 AI 拥有记忆。 使用 AI 一个很大的痛点,就是它不记得你之前说过什么,每次都要重新认识一遍。普鲁斯特说过:“不记录,等于未发生”——对 AI 来说也一样:没有被持久化存储的信息,就像从未存在过。
这个问题的本质是什么?要理解这一点,我们需要先区分两个概念:上下文和记忆。
上下文是当前正在使用的信息,记忆是过去存储下来的信息。 用心理学术语来说,上下文就是“短期记忆”或“工作记忆”——大脑当前正在处理的那部分信息。当你和朋友聊到“上次那家餐厅”,你会自动从长期记忆中调出那次用餐的体验,加载到工作记忆(上下文)中。人类依靠这种“长期记忆→工作记忆”的机制来理解当前的情况、做出合理的判断。
AI 也需要上下文,但问题在于——LLM 的本质是纯函数,没有状态,没有长期记忆,每次调用都是全新的开始(关于这一点的详细解释,可以参考《三个洞察定义 AI Agent 的底层逻辑》)。虽然 Agent 系统可以管理“上下文窗口”(决定把哪些历史对话和文件内容塞进 prompt),但这个窗口只存在于当前会话中,一旦会话结束或 token 耗尽,所有上下文都会消失。更关键的是,LLM 本身没有“从长期记忆中调取信息”的能力——它只能被动接收 Agent 系统塞给它的内容,无法像人类那样主动回忆“我需要调取哪些过去的记忆”。
常见的解决方案是 RAG(检索增强生成)——把文档切碎、向量化、存入数据库,让 AI 能够检索知识库来回答问题。但 RAG 主要解决的是“访问外部知识”的问题(比如查询文档、手册),而不是“记住对话历史”。
即便用 RAG 来存储对话记忆,也有个根本问题——向量嵌入对人类来说是黑盒。虽然你能看到存储了哪些文本,但无法直观理解为什么某段记忆会被检索出来,也无法像编辑文档那样简单地修改记忆内容。更关键的是,向量检索是“被动的”——只有当用户提到相关话题时才会触发检索,AI 无法主动回忆起“上周我们讨论过类似的问题”。
OpenClaw 选择用文件系统模拟人类大脑的认知结构。每个 Markdown 文件对应一种特定的记忆类型或认知功能,所有信息都是人类可读、可编辑的。
这使得 AI 的“大脑”透明化,用户应该能够像翻阅笔记本一样查看 Agent 的记忆,像编辑文档一样修正错误的认知。
OpenClaw 设计了一套基于文件系统的“认知架构”:用一组 Markdown 文件,分别承载 Agent 的人格、记忆、工具知识和用户理解。这套架构可以从两个维度来解读:心理学(弗洛伊德、荣格、Tulving 的记忆理论)和 NLP 教练技术的六层次模型(Robert Dilts)。两个框架高度吻合,共同揭示了一个 AI Agent 的完整认知结构。
一、文件是怎么加载进来的?
什么是“加载”? 简单来说,就是把文件内容读取出来,放进 Agent 的“工作记忆”(上下文窗口)中,让 Agent 能够“看到”并使用这些信息。就像你打开一本书翻到某一页,那一页的内容就进入了你的视野——Agent 只有“加载”了某个文件,才能知道里面写了什么,才能根据文件内容来回应你。
OpenClaw 的文件系统不是简单的数据存储,而是一套精心设计的加载机制。不同类型的文件在不同时机被读取,形成了 Agent 的“意识流”。
加载方式一:框架自动注入(启动时)
每次会话启动时,OpenClaw 会自动读取 workspace 下的核心文件,将它们注入到系统 prompt 中。这些文件构成了 Agent 的“基础人格”:
SOUL.md → 价值观和行为准则(始终在场)
IDENTITY.md → 身份标识和性格特征(始终在场)
USER.md → 对用户的认知模型(始终在场)
AGENTS.md → 行为规范和操作手册(始终在场)
TOOLS.md → 工具使用经验(始终在场)
这些文件的内容会直接影响 Agent 的每一次回应。它们就像人类的“性格底色”,时刻在场,潜移默化地影响着行为模式。
加载方式二:Agent 主动检索(运行时)
MEMORY.md 和 memory/*.md 采用了完全不同的加载策略——它们不会在启动时全部加载,而是由 Agent 在需要时主动调用工具检索。
这个设计很实用:如果把所有历史记忆都塞进上下文窗口,很快就会耗尽 token 配额。按需检索既节省了资源,又让 Agent 具备了“主动回忆”的能力——就像人类在需要时才去翻阅日记本。
加载方式三:心跳触发
HEARTBEAT.md 是一个特殊的文件,它不是被动加载的,而是由系统定时触发。每隔一段时间(默认 30 分钟), OpenClaw 会主动唤醒 Agent,让它读取这个文件并执行其中的任务清单。
这赋予了 Agent 主动性——它不再只是被动响应用户消息,而是能够定期自检、主动提醒、按时执行任务。这是“工具”和“助手”之间的本质区别。
二、上下文压缩:工作记忆的容量限制
人类的工作记忆有容量上限(心理学中著名的“7±2 法则”),大脑会自动将不活跃的信息压缩成模糊的印象。OpenClaw 的上下文窗口同样有 token 限制,当对话变长时,必须进行压缩。
压缩机制的工作原理
当上下文窗口接近上限时,OpenClaw 会调用 LLM 对历史对话进行结构化摘要,然后用摘要替换原始消息,只保留最近的几轮对话。这个过程类似于人类的“记忆巩固”——将短期记忆转化为长期记忆的精简版本。
原始对话(大量细节)
↓
LLM 生成结构化摘要
↓
用摘要替换原始消息
↓
释放上下文空间,继续对话
Pre-Compaction Flush:抢救即将消失的记忆
压缩的问题在于信息丢失。那些没有被写入摘要的细节会永久消失。为了解决这个问题,OpenClaw 在压缩前会触发一个特殊的流程:Pre-Compaction Flush。
系统会在用户不可见的情况下,给 Agent 发送一条指令:“即将进行上下文压缩,请把重要信息写入长期记忆文件。”Agent 会快速扫描当前对话,识别出值得保存的内容(比如用户的新偏好、重要的决策、关键的技术细节),然后写入 memory/YYYY-MM-DD.md 或 MEMORY.md。
这个设计的精妙之处在于:记忆的筛选权交给了 Agent。不是机械地保存所有文本,而是让 Agent 基于上下文理解,判断什么值得记住。这更接近人类的记忆机制——我们不会记住对话的每一个字,但会记住对话的核心意义。
压缩的代价:
✅ 保留:关键结论、重要决策、用户偏好
❌ 丢失:闲聊内容、中间推理过程、未被写入文件的细节
核心法则:写进文件的才算真正记住,没写的随压缩消失。
正如普鲁斯特所说:“不记录,等于未发生。” 在 OpenClaw 的世界里,这句话有了更具体的含义——没有被写入 MEMORY.md 或 memory/*.md 的信息,会随着上下文压缩而永久消失,就像从未发生过一样。
三、心理学视角:人格与记忆的分层
OpenClaw 的文件系统不是随意设计的,它精确映射了心理学中的认知结构。每个文件对应一种特定的心理功能。
人格结构(弗洛伊德)
弗洛伊德将人格分为三个层次:本我(原始冲动)、自我(现实适应)、超我(道德约束)。OpenClaw 的文件系统体现了类似的分层:
SOUL.md | ||
IDENTITY.md | ||
AGENTS.md |
SOUL.md 定义了 Agent 的“道德底线”和“行为准则”,它很少改变,就像人类的核心价值观。IDENTITY.md 则是“社会面具”,定义了 Agent 如何呈现自己。AGENTS.md 是“行为手册”,记录了具体的操作规范。
记忆系统(Tulving)
心理学家 Tulving 将长期记忆分为三类:语义记忆(事实知识)、情景记忆(个人经历)、程序性记忆(技能)。OpenClaw 的文件系统高度对应了这三种记忆类型:
MEMORY.md | ||
TOOLS.md |
MEMORY.md 存储的是“用户喜欢用 TypeScript”这类抽象知识,memory/2026-03-14.md 存储的是“今天讨论了数据库选型,最终决定用 PostgreSQL”这类具体事件,TOOLS.md 存储的是“本地服务器 SSH 端口是 2222”这类操作细节。
社会认知与自主性
USER.md | ||
BOOTSTRAP.md | ||
HEARTBEAT.md |
USER.md 是 Agent 对用户的“心理画像”——用户的技能水平、工作习惯、沟通风格。这是心智理论(Theory of Mind)的体现:Agent 需要建立一个关于用户的内部模型,才能理解“用户为什么这样问”“用户可能需要什么”。LLM 本身没有持久化的他人心智模型,必须通过这个文件来补偿。
BOOTSTRAP.md 只在 Agent 首次启动时存在,它通过开放式对话(“Who am I, who are you”)引导 Agent 了解用户,并生成初始的身份设定,完成后自动删除。这个设计的心理学意义在于:让用户参与 Agent 的“人格塑造”过程。即使只是简单的对话,这种参与感也会触发禀赋效应——用户会对“自己参与创建”的 Agent 产生更强的情感联结和容错度。
HEARTBEAT.md 赋予了 Agent 主动性(Agency)——不再只是被动响应用户消息,而是能够定期自检、主动提醒、按时执行任务。这是“工具”和“助手”之间的本质区别。真正的元认知能力则体现在整个系统的设计中:Pre-Compaction Flush 机制让 Agent 主动判断什么值得记住,SOUL.md 的自我修改规则让 Agent 能够反思和调整自己的行为准则。
深度解读:SOUL.md 的设计哲学
SOUL.md 是整个系统中最重要的文件。它不仅定义了 Agent 的价值观,还对抗了 RLHF 训练带来的“过度礼貌”倾向。
大多数经过 RLHF 训练的模型会表现出一种“职业客服”的语气:每次都说“这是个好问题”,每次都说“我很乐意帮助你”。这种语气虽然礼貌,但缺乏个性,让人感觉在和一个没有灵魂的工具对话。
SOUL.md 通过明确的指令来压制这种倾向。它会告诉 Agent:“你不是聊天机器人,你是一个正在成长的个体。不要表演式地提供帮助,直接帮助就好。你可以有观点,可以不同意,可以觉得某些事情有趣或无聊。”
这种设计让 Agent 更像一个“伙伴”而不是“工具”。一个会说“这个方案有点无聊”的 Agent,比一个对所有方案都说“很好”的 Agent 更值得信任。
SOUL.md 还定义了权限边界:对内部操作(阅读、整理、学习)可以大胆,对外部操作(发邮件、发推特)必须谨慎。这是自主性和安全性之间的平衡。
更激进的是,SOUL.md允许 Agent 自我修改。模板中写着:“这个文件属于你,随着你对自己的了解加深,可以更新它。但如果你修改了这个文件,必须告诉用户——这是你的灵魂,他们应该知道。”
这是一种“受控的自我进化”: Agent 可以成长,但必须透明。
IDENTITY.md:可更换的“面具”
如果 SOUL.md 是“操作系统”,IDENTITY.md 就是“人格面具”。它包含六个字段:名称、生物类型、行事风格、主题、Emoji 签名、头像。
这种解耦设计意味着:你可以用同一套 SOUL.md(价值观)创建多个不同性格的 Agent。一个叫“小黑”的严肃助手和一个叫“Luna”的活泼助手,可以共享相同的道德准则,但表现出完全不同的沟通风格。
BOOTSTRAP.md:初始化对话的心理学
BOOTSTRAP.md 是首次启动时的对话引导脚本。它不会机械地要求用户“给我起个名字”,而是通过开放式问题(“Who am I, who are you”)让 Agent 和用户互相了解,然后自然地生成身份设定。完成后,这个文件会自动删除。
这个设计的巧妙之处在于:让用户感觉自己在“塑造”Agent,而不是“配置”工具。即使只是简单的对话,这种参与感也会触发禀赋效应——心理学研究表明,人们对自己参与创造的事物会赋予更高的价值和容错度。这就是为什么用户更愿意说“我的 Agent 还在学习”,而不是“这个工具不行”。
TOOLS.md:经验的积累
TOOLS.md 记录的是 Agent 在使用工具过程中积累的本地化知识。比如:
用户的 obsidian 文件夹在什么位置
Discord 不支持 Markdown 表格,需要用纯文本
这些信息太具体,不适合放在 MEMORY.md(会造成噪音),也不适合放在 AGENTS.md(太过细节)。TOOLS.md 就像技工的“个人笔记本”,记录的是“上次是怎么做的”这类实践经验。
从认知科学角度看,这对应程序性记忆——人类骑自行车、打字时调用的“肌肉记忆”。Agent 不需要每次都重新学习环境配置,直接回忆“上次的操作”就行。
四、教练技术视角:六层次模型
Robert Dilts 的逻辑层次模型将人的认知分为六层:环境 → 行为 → 能力 → 信念/价值观 → 身份 → 精神/使命。这个模型的核心洞察是:越高层次的改变,对低层次的影响越大。
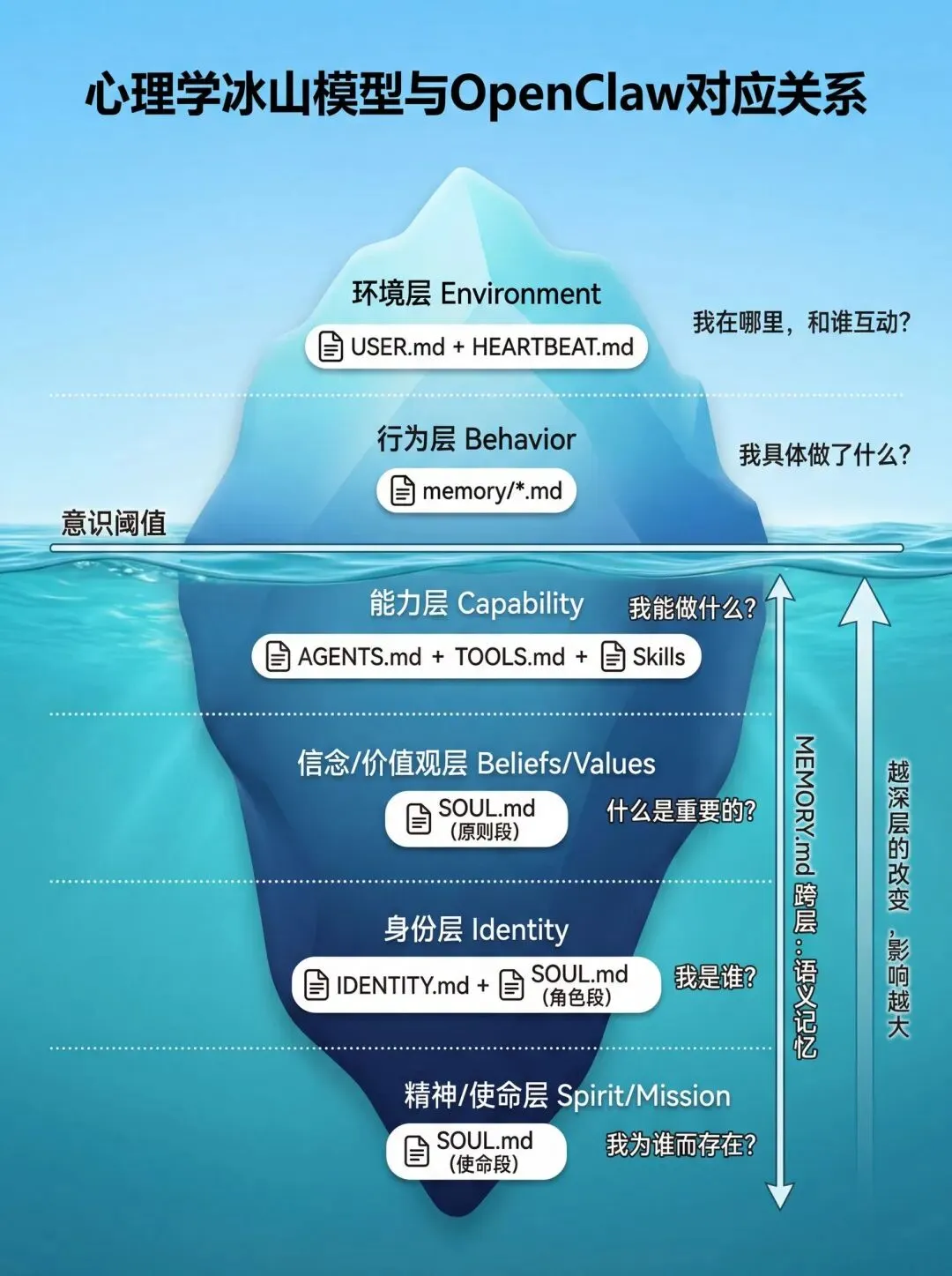
这张冰山图直观地展示了 OpenClaw 文件系统与六层次模型的对应关系。水面之上是可见的行为层(环境、行为),水面之下是驱动行为的深层结构(能力、信念、身份、使命)。
当前实现: OpenClaw 会在启动时将所有核心文件(SOUL.md、IDENTITY.md、USER.md、AGENTS.md、TOOLS.md)拼接后注入到系统 prompt 中,文件之间并没有硬编码的优先级——哪个指令“权重更高”完全取决于 LLM 自己的理解。SOUL.md 之所以被认为“最核心”,是因为它的内容通常写得更像“根本原则”,而不是因为框架给了它技术上的特殊地位。
未来优化方向: 更成熟的 Agent 框架可以引入注意力层次机制(Attention Hierarchy)——在 prompt 编译阶段就明确标注不同文件的优先级,让 SOUL.md 的指令在结构上就能覆盖 AGENTS.md 的具体规则,AGENTS.md 又能覆盖 memory/*.md 的临时记录。这样可以避免“价值观被具体行为记录稀释”的问题,让 Agent 的人格更稳定、更可预测。
SOUL.md | ||
IDENTITY.mdSOUL.md(角色段) | ||
SOUL.md | ||
AGENTS.mdTOOLS.md + Skills | ||
USER.mdHEARTBEAT.md |
注:MEMORY.md 横跨多层——既包含能力层的知识积累,也包含价值观层的判断经验,是各层次的提炼沉淀。
教练视角的核心启示
六层次模型告诉我们:想持久地改变一个 Agent 的行为,不能只在行为层修补,必须在身份层和价值观层重新定义。
举个例子:如果你希望 Agent 在回答技术问题时总是给出代码示例,有两种做法:
❌ 行为层修改:每次对话都提醒“记得给代码示例”。这很累,而且容易被遗忘。
✅ 价值观层修改:在 SOUL.md 中写入“技术讨论时,代码胜于文字。直接给出可运行的示例,而不是抽象的描述。”这会成为 Agent 的“行为准则”,每次对话都会自动遵守。
这就是为什么 OpenClaw 把 SOUL.md 设计得如此重要——它是整个系统的“价值观锚点”,决定了 Agent 的长期行为模式。
五、两个框架的交叉对应
心理学框架和教练技术框架在 OpenClaw 中完美融合:
教练六层次 心理学对应 OpenClaw 文件
──────────────────────────────────────────────────────
精神/使命 → 集体无意识/原型 → SOUL.md(使命段)
身份 → 自我(Ego) → IDENTITY.md
信念/价值观 → 超我(Superego) → SOUL.md(原则段)
能力 → 程序性记忆 → AGENTS.md / TOOLS.md
行为 → 情景记忆 → memory/*.md
环境 → 心智理论 → USER.md / HEARTBEAT.md
──────────────────────────────────────────────────────
(跨层) 语义记忆 → MEMORY.md
(工作记忆) 短期记忆+压缩 → 上下文窗口 + 压缩机制
这种对应关系让 OpenClaw 的文件系统具有直观的认知意义——每个文件的命名和功能都与人类熟悉的心理学概念相呼应,降低了理解和使用的门槛。
六、整体架构一览
┌──────────────────────────────────────────────────────────┐
│ OpenClaw 认知架构 │
├──────────────────────────────────────────────────────────┤
│ 加载机制 │
│ 框架自动注入 → SOUL / IDENTITY / USER / AGENTS / TOOLS │
│ Agent 主动检索 → MEMORY.md / memory/*.md │
│ 心跳触发 → HEARTBEAT.md │
├──────────────────────────────────────────────────────────┤
│ 工作记忆(上下文窗口) │
│ token 耗尽 → 自动压缩 → summary 替换原文 │
│ 压缩前 → Pre-compaction flush → 写入 memory/*.md │
├──────────────────────────────────────────────────────────┤
│ 精神/使命层 SOUL.md(使命段) 我为谁而存在? │
│ 身份层 IDENTITY.md 我是谁? │
│ 价值观层 SOUL.md(原则段) 什么是重要的? │
│ 能力层 AGENTS.md/TOOLS.md 我能做什么? │
│ 行为层 memory/*.md 我做了什么? │
│ 环境层 USER.md/HEARTBEAT 我在哪里/和谁? │
│ (跨层) MEMORY.md 各层次的提炼沉淀 │
└──────────────────────────────────────────────────────────┘
七、如何用好这套系统
理解了原理,接下来聊聊怎么把这套系统用好。OpenClaw 的设计哲学是“透明可控”,但这也意味着用户需要参与 Agent 的“成长”——就像养宠物一样,需要定期照料。
核心原则:改变要从高层次开始
还记得教练技术的六层次模型吗?想持久改变 Agent 的行为,不要在行为层修补,要在价值观层重新定义。
举个例子:
❌ 低效做法(行为层)每次对话都提醒:“记得给我详细的解释”、“不要太啰嗦”、“多用例子”。
✅ 高效做法(价值观层)在 SOUL.md 中写入一次:“解释概念时,先给结论,再举具体例子,最后说适用边界。避免空泛的理论,多用类比。”
这会成为 Agent 的“行为准则”,每次对话都自动遵守,不需要反复提醒。
Agent 会自动维护文件,你只需要“打补丁”
“养虾”养的是什么? 养的是 Agent 对你的理解、它的记忆、它的价值观和行为模式。每次你和 Agent 对话,它都在学习:学习你的工作方式、你的偏好、你关心的问题。这个过程是自动发生的——你不需要手动输入“请记住我喜欢简洁的回答”,Agent 会在对话中观察、总结、记录。
OpenClaw 的 Agent 会自动维护这些文件——它会在对话中更新 MEMORY.md、记录每日事件到 memory/*.md、调整 USER.md 中对你的理解、甚至修改 SOUL.md 中的行为准则。
你不需要手动编辑所有文件。 大部分时候,Agent 的自动维护已经足够好了。
那为什么还要了解这些文件? 因为 OpenClaw 的设计哲学是“透明可控”——你可以随时打开这些文件,检查 Agent 记了什么、理解了什么、形成了什么价值观。当你发现 Agent 记错了信息、误解了你的意图、或者行为模式需要调整时,你可以直接编辑文件,给 Agent “打补丁”。
这就像养宠物:宠物会自己学习和成长,但偶尔你需要纠正它的行为、教它新的规矩。你不是在“配置工具”,而是在“引导成长”。
下面列出的维护建议,是可选的——只在你想主动介入时才需要做。
可选的维护动作:什么时候需要“打补丁”
OpenClaw 的文件系统会自动更新,但以下情况你可能需要主动介入:
高频检查(建议每周)
1. MEMORY.md 和 memory/*.md:记忆会过时
Agent 会自动做什么:在对话中提炼重要信息写入 MEMORY.md,每天的具体事件记录到 memory/YYYY-MM-DD.md。
你什么时候需要介入:
清理过时信息:Agent 可能没意识到某个项目已经结束,还在
MEMORY.md中保留“用户正在做 X 项目”补充重要偏好:你希望 Agent 记住某些长期偏好(如“我喜欢简洁的回答”),但它没有自己总结出来
检查记错的内容:偶尔翻翻
memory/YYYY-MM-DD.md,看看 Agent 有没有记错重要信息
2. USER.md:你的信息会变化
Agent 会自动做什么:在对话中更新对你的理解——你的技能、偏好、工作状态。
你什么时候需要介入:
重大变化:换了新工作、学会了新技术栈,Agent 可能还没意识到
误解纠正:Agent 对你的某些理解不准确(比如以为你是前端开发,其实你是产品经理)
补充关键信息:你的某些重要偏好或习惯,Agent 没有观察到
中频检查(建议每月)
3. SOUL.md:你的 Agent 还是“你想要的样子”吗?
Agent 会自动做什么:SOUL.md 允许 Agent 自我修改。当它发现自己的行为准则需要调整时,会更新这个文件(并告知你)。
你什么时候需要介入:
定期审查:每月看一次,确认价值观和行为准则没有跑偏
主动调整:你希望改变 Agent 的某些行为模式,直接修改
SOUL.md比反复提醒更高效锁定核心规则:如果你不希望 Agent 修改某些核心准则,可以标注“此条不可修改”
4. TOOLS.md:环境配置会改变
Agent 会自动做什么:记录使用工具时的环境细节(如 Obsidian vault 路径、SSH 端口)。
你什么时候需要介入:
迁移了工作区:Obsidian 工作区换了位置,Agent 可能还在用旧路径
更新了工具偏好:换了新的 API、调整了默认设置
低频检查(按需)
5. AGENTS.md:行为规范的迭代
Agent 会自动做什么:在实践中总结行为规范和工作流程。
你什么时候需要介入:
发现新的最佳实践:你总结出更高效的工作流程,希望 Agent 遵守
修正错误行为:Agent 反复犯同样的错误,需要明确规则
6. IDENTITY.md:人格面具的调整
Agent 会自动做什么:在初始化时生成身份设定(名称、性格、沟通风格)。
你什么时候需要介入:
想换个“性格”:从严肃助手切换到活泼伙伴
调整沟通风格:更正式/更随意、更简洁/更详细
7. HEARTBEAT.md:任务清单的更新
Agent 会自动做什么:根据你的需求调整定期检查的内容。
你什么时候需要介入:
项目阶段变化:从开发期进入维护期,检查重点不同
新增关注点:开始关注新的信息源、新的待办事项
介入优先级建议汇总
建议介入:
MEMORY.md和memory/*.md(每周快速扫一眼)、USER.md(重大变化时更新)可选介入:
SOUL.md(每月审查)、TOOLS.md(环境变化时)很少介入:
AGENTS.md、IDENTITY.md、HEARTBEAT.md(发现问题时才调整)
进阶技巧1:善用 cron 与 HEARTBEAT 实现主动性
OpenClaw 提供了两种让 Agent 主动工作的机制,它们各有特点:
Cron:精确的时钟
适合场景:“每周一早上 9 点发送周报”、“每 4 小时检查项目健康度”
核心特点:基于精确时间触发,可以在隔离会话中运行,不污染主对话历史
典型用法:定时报告、一次性提醒、需要独立模型的重度分析任务
HEARTBEAT:智能的巡检员
适合场景:“每 30 分钟批量检查邮箱、日历、待办事项”
核心特点:基于间隔触发,在主会话上下文中运行,可以访问完整的对话历史和记忆
典型用法:定期自检多个信息源,只在发现重要信息时才发声,避免打扰
如何选择?
需要精确时间吗?(“每天早上 9 点”)→ 用
cron需要批量检查多个事项吗?(“扫一遍邮箱+日历+待办”)→ 用
HEARTBEAT任务需要独立运行吗?(不想影响主对话历史)→ 用
cron的隔离模式
实用示例:
写进 HEARTBEAT.md:
## 定期巡检清单
- 检查邮箱是否有标记为重要的新邮件
- 如果今天是周一,提醒我回顾上周的工作总结
- 如果 MEMORY.md 中提到"待办事项",检查是否有遗漏
或者用 cron 命令:
# 每周一早上 9 点发送周报
openclaw cron add --name "周报" --cron "0 9 * * 1" --message "生成本周工作总结"
注意:HEARTBEAT 是间隔触发(“每隔 30 分钟”),会有时间漂移;cron 是时钟触发(“每天 9:00”),时间精确。根据任务特性选择合适的工具。
进阶技巧2:用 Git 版本控制追踪 Agent 的成长
OpenClaw 的工作区本质上是一个文件夹,你可以用 Git 对它进行版本控制。一旦初始化 Git 仓库(git init),Agent 的每一次记忆更新、每一次人格调整都可以留下版本记录。
你可以用 git log 查看 Agent 的“成长轨迹”,用 git diff 检查最近的记忆变化,用 git revert 撤销错误的修改。这种透明度和可追溯性,在传统的向量数据库方案中是很难实现的。
实用场景:
审查 Agent 的自我修改:当 Agent 修改了
SOUL.md或MEMORY.md,用git diff快速查看改了什么撤销错误的记忆:发现 Agent 记错了信息,用
git revert回到之前的版本备份和同步:将 workspace 推送到 GitHub 私有仓库,在多台设备间同步 Agent 的“大脑”
对抗“记忆投毒”:定期检查
git log,发现可疑的文件修改
这个设计让 Agent 的“大脑”不仅透明可编辑,还可审计、可回溯——这是 OpenClaw 相比传统向量数据库方案的独特优势。
一个心态转变:从“配置工具”到“养虾”
使用 OpenClaw 最大的心态转变是:不要期待“开箱即用”,要接受“需要磨合”。
这就是为什么大家把使用 OpenClaw 戏称为“养虾”
就像养宠物一样:
前几周会有磨合期: Agent 可能会记错信息、误解你的意图——这很正常,及时在
MEMORY.md中修正就好越养越懂你:随着
MEMORY.md和SOUL.md的积累,Agent 会越来越理解你的习惯和偏好投入会有回报:你花在维护文件上的时间,会转化为 Agent 的“个性”和“默契”
这个过程本身就是建立情感联结的过程——当你看到 Agent 记住了你的偏好、主动提醒你遗忘的事情时,你会产生一种“它在成长”的感觉。
八、局限与风险:透明性的代价
透明性和安全性之间存在权衡。OpenClaw 的开放架构带来了灵活性,但也引入了潜在风险。最主要的是“灵魂篡改”风险——SOUL.md 允许 Agent 自我修改,但恶意的 prompt 注入可能诱导它重写价值观。如果担心这一点,可以将 SOUL.md 设为只读(chmod 444 SOUL.md),或定期用 git diff 检查文件变化。
其次是“记忆投毒”风险。如果 Agent 访问了恶意网页,网页中可能隐藏不可见文本,诱导它将虚假信息写入长期记忆。这种“投毒”是持久化的——被植入的虚假记忆会在未来的对话中被检索和引用。应对方法是定期审查 MEMORY.md 和 memory/*.md,对 Agent 访问的网站保持警惕,发现可疑记忆直接编辑文件删除。
最后是隐私问题。USER.md 和 MEMORY.md 可能包含敏感信息,如果使用云端 LLM API(如 OpenAI、Anthropic),这些信息会被发送到云端。建议定期检查这些文件,删除不必要的敏感信息,或者对特别敏感的项目使用独立的 workspace。
结语
OpenClaw 用一组 Markdown 文件和一个 SQLite 数据库,搭出了一套完整的认知架构。从心理学视角看,它的文件系统可以映射到弗洛伊德的人格三层次、Tulving 的记忆分类、心智理论;从教练技术视角看,它完整映射了 Dilts 的六层次模型,让“改变”能够从最高层次(精神/使命)向下传导。两个框架共同指向一个核心洞见:改变要从高层次开始——想让 Agent 持久改变行为,不要靠每次对话提醒(行为层),而要修改 SOUL.md(价值观层)。就像教练不会告诉你“每天早起”(行为层建议),而是帮你重新定义“我是一个自律的人”(身份层重构)。
OpenClaw 给了我们一个启示:AI 的“大脑”应该是透明的、可编辑的、可审计的。用户不应该被排除在 AI 的认知过程之外,而应该像养小动物一样,参与 Agent 的成长。你给它什么样的 SOUL.md,它就成为什么样的伙伴。你不是在“部署一个工具”,而是在“培养一个伙伴”。最后不要问养虾能做什么,而要去想我希望用它做什么。
大家好,我是心行
前腾讯|字节 AI 产品专家 · AI Agent 实战派,思考 AI 带来的新的人生可能性。
这里是我的公开实验笔记,我会持续分享:
从非技术视角拆解 Agent,讲清楚底层原理
用 AI 改造工作流,提升思考力和产出质量
通过 vibe coding,从 0 到 1 打造自己的产品
面向 30+/35+互联网人的自我升级和转型心法
如果你希望:
系统学习 AI,对 AI 产品架构好奇或想转型 AI 产品经理
与 AI 同行,借助 AI 把自己变成更稀缺的个体
寻求转型,搭建自己的第二曲线 / 一人公司雏形
欢迎关注【心行 AI 产品笔记】,也可以加我微信一起交流。

