 夜雨聆风
夜雨聆风准确一点说,是这句:
OpenClaw 能不能对接的免费无限制的 Token?毕竟一个OpecClaw一个对话就消耗字节火山平台每天免费的50W Token就没了,还欠平台的钱,世界首富马斯克来了也用不起。
答案先放这:
能。真的能。而且对很多人来说,不是勉强能用,是完全够用。每分钟最多40次调用,模型有DeepSeek V3.2 、QWen 3.5、Kimi K2.5 、GLM5.......这些模型统统免费用。
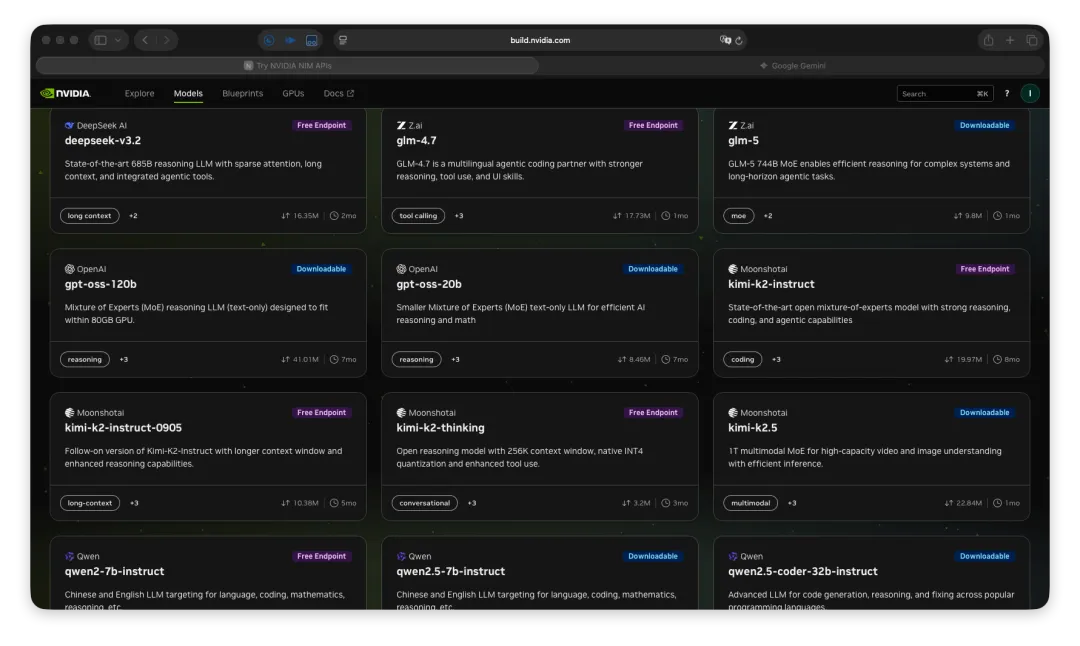
一、很多人缺的不是模型,是“今天就能用起来”
这两年 AI 圈有个很经典的现象:
平台越来越多。模型越来越多。教程越来越多。但真正能顺手用起来的人,没你想的那么多。
为什么?
因为大部分人卡住的从来不是“不会提问”,而是下面这些更现实的问题:
这东西要不要花钱? 要不要绑卡? 要不要配代理? 要不要看半天英文文档? 要不要折腾一堆接口和兼容层? 我只是想先试试,怎么一上来就像在考证?
很多工具最后不是输在能力,而是输在一句话:
“算了,太麻烦了。”
OpenClaw 也是一样。
所以 AAA显卡批发黄总 带着他的免费 Token来了。
因为它解决的不是“有没有最强模型”,而是更朴素的问题:
能不能先别花钱,先用起来。
这件事,非常重要。因为对于绝大多数人来说——
先跑通,比一步到位更重要。
二、这套组合为什么会让很多人上头?
因为它真的很符合普通用户的心理路径。
不是每个人一上来都愿意为 AI 持续付费。也不是每个人一开始就确定自己会长期重度用。
很多人的真实状态是:
“我先试试。”“如果真的有用,我再深入。”“别让我一开始就投入太多。”
而 OpenClaw + N,刚好就踩中了这个点。vidia 免费 Token
它的优势很直接:
1. 先把门槛砍下来
不用一开始就投入预算。对很多观望中的人来说,这一步就已经很关键了。
2. 先把工作流跑起来
比起争论哪个方案最强,更重要的是:你今天能不能用。
3. 让你先知道自己到底需不需要更强方案
很多人其实根本不需要“顶配”。只是被信息流裹挟着,以为自己需要。
真正做法应该是:
先用。 不够了,再升级。
这才是正常人思路。
三、别再找“神仙教程”了,配置逻辑其实就这几步
讲人话版本就一句:
接口地址 + Token + 模型名 + 测试连通性。
你看到这里,其实这件事已经没那么玄学了。
不同版本的 OpenClaw,页面名字可能不完全一样。但底层逻辑通常都差不多。
你要找的,基本是这些位置:
设置 模型配置 API Provider 接口管理 自定义模型 OpenAI Compatible 之类的入口
你只要记住一句话:
别被界面名字吓到。 本质上就是把可用接口接进来。
四、第一步:先拿到 Nvidia的免费 Token
打开网址:https://build.nvidia.com 注册账号
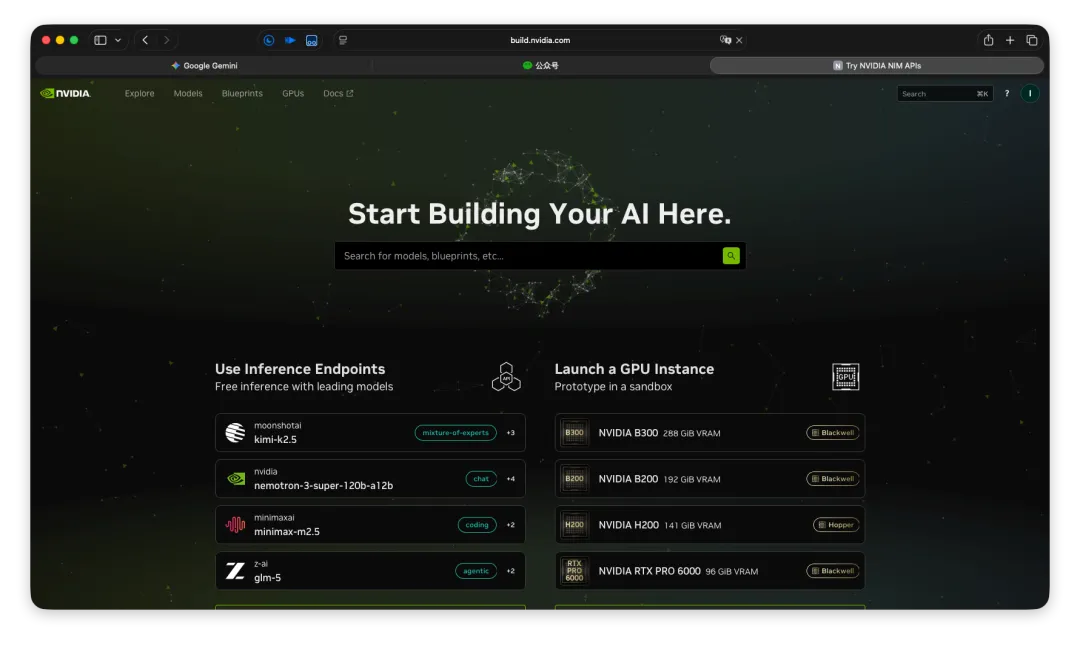
打开网址:https://build.nvidia.com/settings/api-keys 创建Key(需要绑定手机号才能创建,+86的手机号可以绑定),设置Key的有效期,推荐Never Expire,永不过期。
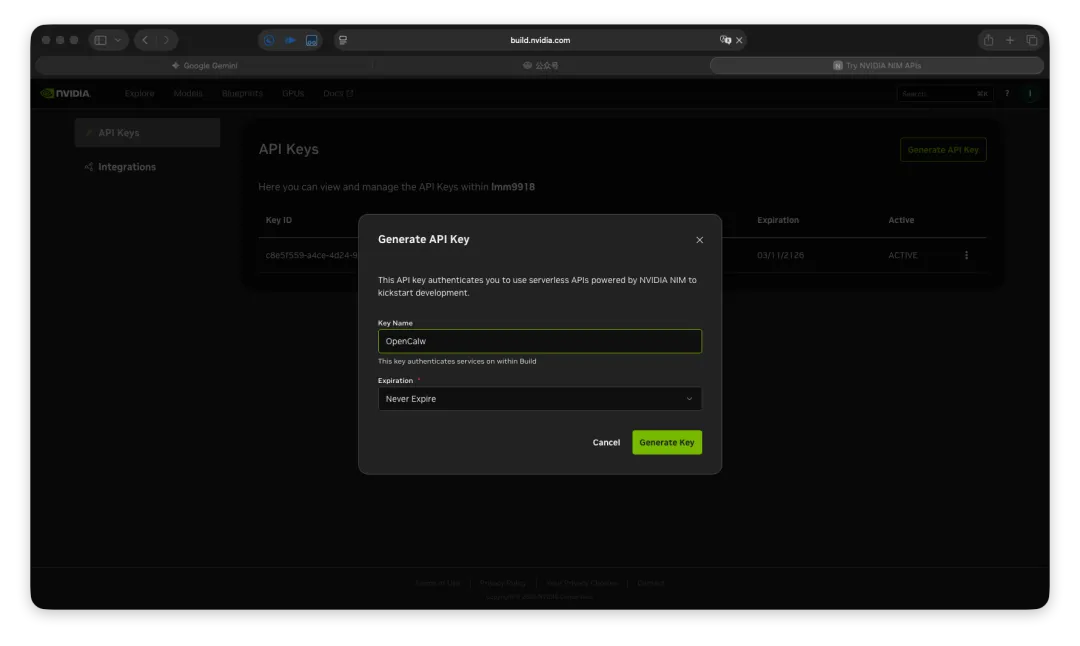
请勿将Key分享到任何地方,Key相当于你家大门的钥匙。
五、第二步:找到 OpenClaw 里的配置入口
进入 OpenClaw 后,你要找的是模型/API 相关入口。
配置 > Models > Model Providers > Add Entry
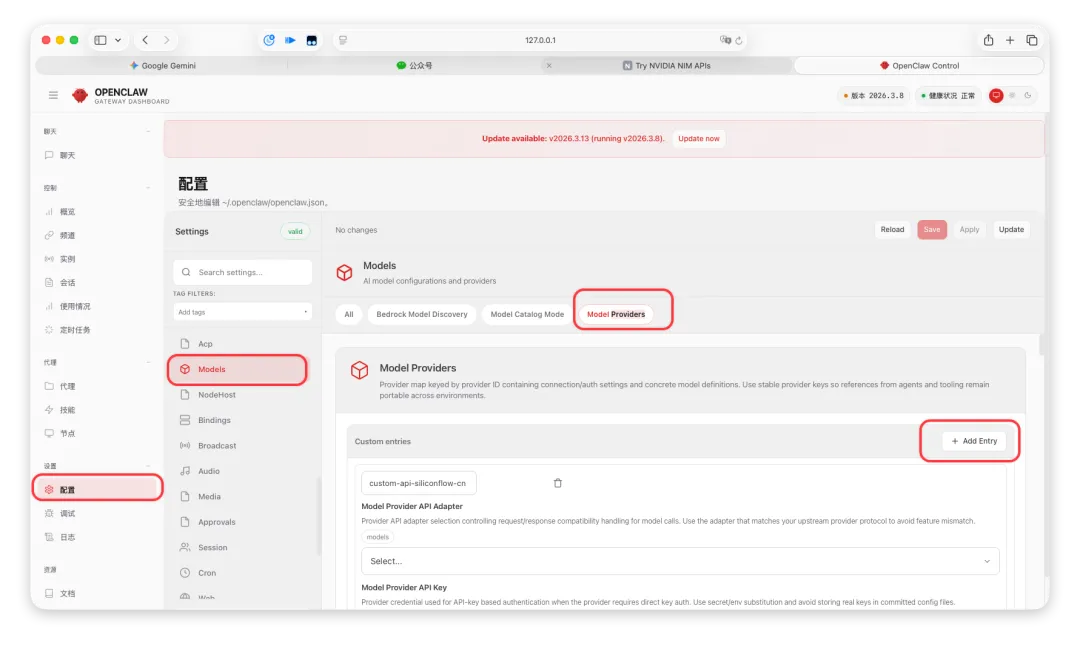
六、第三步:真正关键的配置项,就看这几个
配置截图请参考如下截图
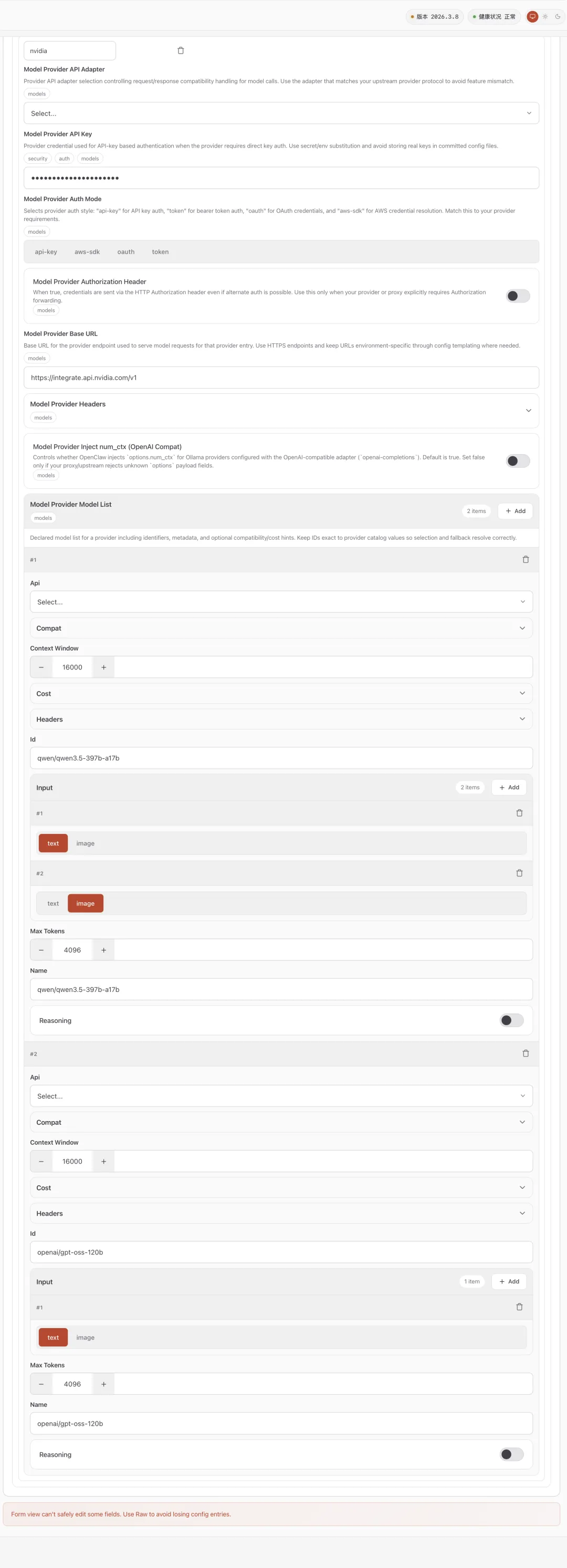
点开配置页面你会看到下面这些字段:
Base URL API Key Model
别慌。
你先只盯住最关键的三项。
1)接口地址(Base URL):别抄野路子地址
接口地址请使用:https://integrate.api.nvidia.com/v1
这个坑真的太多人踩了。很多人一看到别人发教程,直接复制一串 URL,然后满脸疑惑地问:
“为什么我还是不通?”因为你抄到的,可能根本就不是你当前该用的地址。
2)Key(API Key):别多空格,别多前缀,别多戏
把你的 build.nvidia.com 获取到的 key 填进去。
注意这几个小细节:
前后别带空格 别复制出换行 别手动多加引号
你别小看这些细节。很多所谓“玄学报错”,本质上就是复制粘贴手抖了一下。
3)模型名(Model):第二大高频翻车现场
配置里最常见的两种死法:
第一种,URL 错。 第二种,模型名错。
很多人以为“接口通了就差不多了”。结果一请求,直接:
model not found unsupported model
invalid request
所以模型名称这件事,不要靠猜。按平台当前支持列表来。 大小写、名称格式,尽量严格一致。
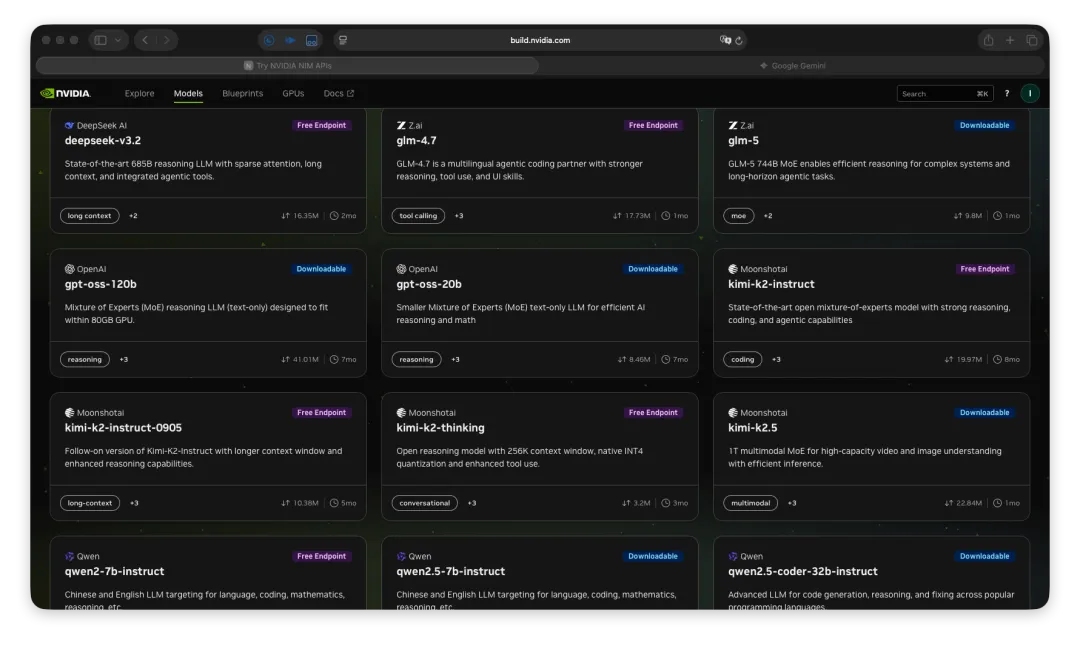
你有图片识别的需求,推荐使用:qwen3.5-397b-a17b
你追求快速响应,推荐使用:DeepSeek-V3.2
有代码和编程需求,推荐使用:glm5
更多模型请访问:https://build.nvidia.com/models
nvidia: {baseUrl: 'https://integrate.api.nvidia.com/v1',apiKey: '填入你自己的API Key',api: 'openai-completions',models: [{id: 'qwen/qwen3.5-397b-a17b',name: 'qwen/qwen3.5-397b-a17b',api: 'openai-completions',reasoning: false,input: ['text','image',],cost: {input: 0,output: 0,cacheRead: 0,cacheWrite: 0,},contextWindow: 16000,maxTokens: 4096,},{id: 'openai/gpt-oss-120b',name: 'openai/gpt-oss-120b',api: 'openai-completions',reasoning: false,input: ['text',],cost: {input: 0,output: 0,cacheRead: 0,cacheWrite: 0,},contextWindow: 16000,maxTokens: 4096,},],},
model: {primary: 'nvidia/openai/gpt-oss-120b',fallbacks: ['nvidia/qwen/qwen3.5-397b-a17b',],},models: {'nvidia/qwen/qwen3.5-397b-a17b': {},'nvidia/openai/gpt-oss-120b': {},},
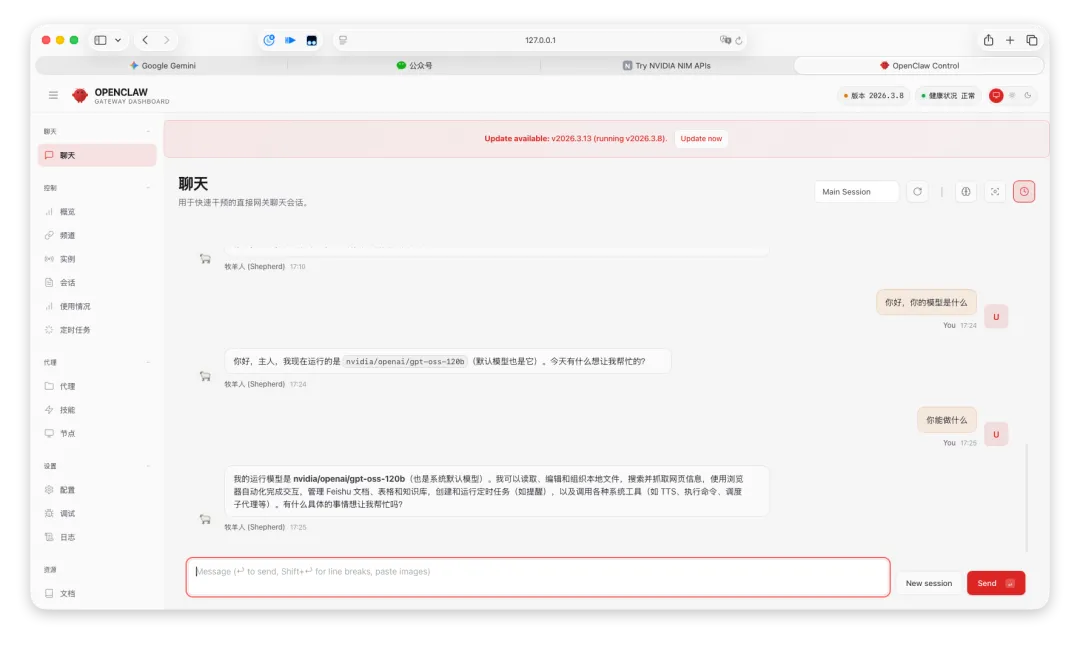
七、真实体验到底怎么样?我尽量说点不虚的
如果你问我一句话总结这套方案:
它不是最强。 但它是很多人最适合的起点。
这就是我的真实评价。
它好的地方
上手门槛低 成本压力小 适合先跑通 能快速验证 OpenClaw 是否适合你 对轻量使用场景很友好
它不那么好的地方
免费额度意味着没法使用最强的模型,ChatGPT 5.4、Gemini 3.2、Claude Opus 4.6 这些都没有提供。 平台策略可能变化 不适合长期高强度生产调用 某些场景下稳定性预期不能拉太满
所以你别把它想成“终极解法”。它更像是一条非常现实的路:
先把工具变成生产力,再谈升级。
这条路,比一上来就研究顶配方案,靠谱太多了。
八、结尾互动区
如果这篇你觉得有用,也可以点个“在看”或者转给那个——
嘴上天天说要研究 AI,实际上还没把工具跑起来的朋友。
