 夜雨聆风
夜雨聆风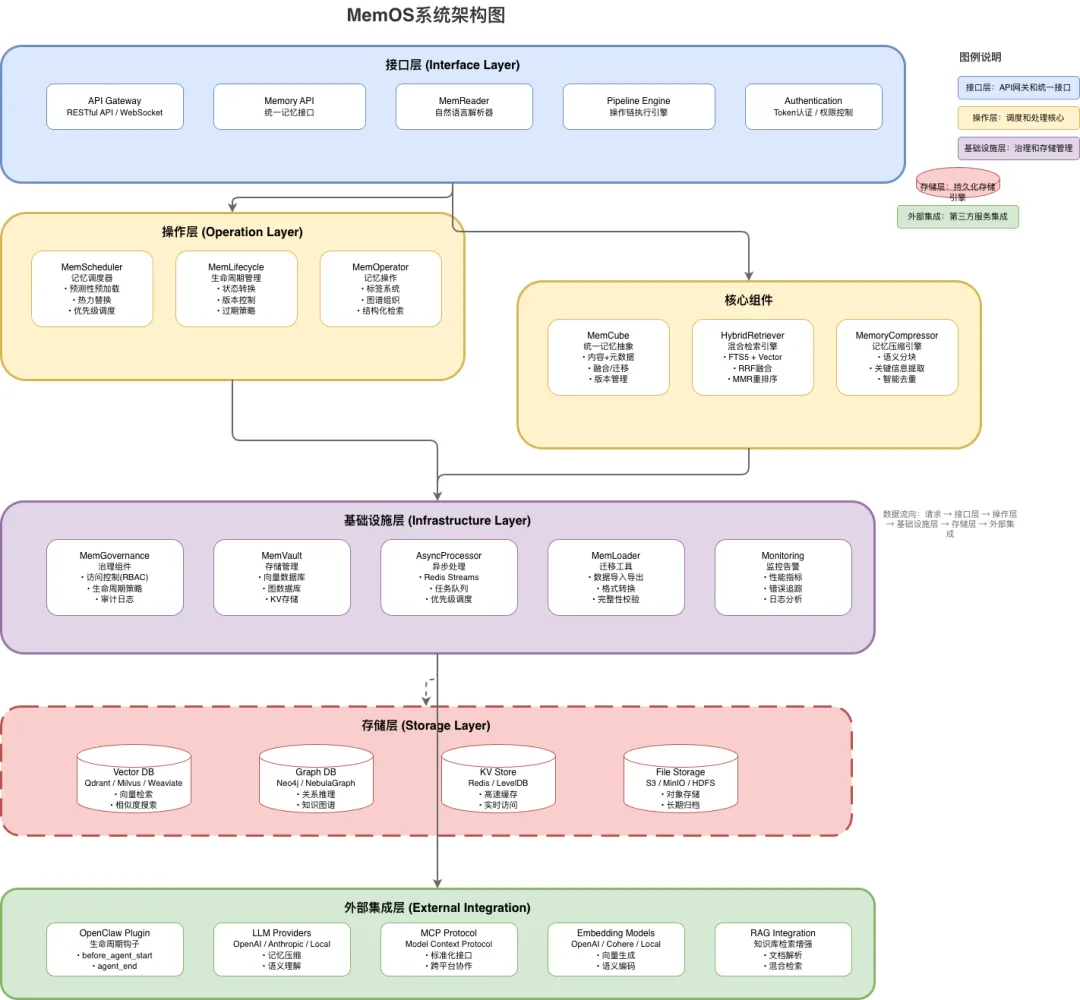
1. 引言:Token消耗的挑战与MemOS的解决方案
1.1 传统AI Agent的记忆困境
上下文窗口限制:即使拥有200k token的上下文窗口,在多次对话后仍会触发压缩机制,导致关键信息丢失 状态持久化困难:跨会话、跨任务的知识难以保持,用户需要重复提供相同上下文 Token成本高昂:每次推理都需要加载大量历史对话,造成显著的计算和成本开销
1.2 MemOS的创新突破
统一记忆API:提供单一接口管理长期记忆,结构化为图谱形式,而非黑盒嵌入存储 多模态记忆支持:原生支持文本、图像、工具追踪和人格记忆的统一检索与推理 智能调度机制:通过MemScheduler实现毫秒级延迟的异步记忆操作,支持高并发场景
1.3 核心收益
Token节省35.24%:通过智能检索替代完整历史加载 准确性提升43.70%:相比OpenAI Memory的准确率提升 响应速度提升91%:相比全上下文方法的p95延迟降低
2. MemOS系统架构深度分析
2.1 整体架构设计
2.1.1 接口层(Interface Layer)
# 接口层统一API设计(基于源码分析)class MemoryAPI:def provenance_api(self, memory_id: str) -> Metadata:"""追溯记忆来源和版本信息"""def update_api(self, memory_id: str, new_content: str) -> bool:"""更新记忆内容,支持版本控制"""def log_query_api(self, user_id: str, time_range: tuple) -> List[LogEntry]:"""查询记忆使用痕迹和审计日志"""
class MemReader:def parse_natural_language(self, user_input: str) -> List[MemoryOperation]:"""将用户自然语言转换为标准记忆操作返回:MemoryOperation列表,支持pipeline风格的操作链"""# 示例:解析"记住我喜欢咖啡"# 输出:[# MemoryOperation(type='add', content='用户喜欢咖啡',# metadata={'user_id': 'xxx', 'type': 'preference'})# ]
2.1.2 操作层(Operation Layer)
class MemScheduler:def __init__(self):self.strategies = {'lru': self._lru_strategy,'semantic_similarity': self._semantic_strategy,'label_based': self._label_strategy}def schedule_memory(self, context: Dict, task_type: str) -> List[MemCube]:"""动态选择最优记忆类型:- 参数内存:适用于高频访问的基础知识- 激活内存:适用于当前推理的上下文- 明文内存:适用于外部知识和用户偏好"""strategy = self._select_strategy(context, task_type)return strategy.select(context)def _semantic_strategy(self, context: Dict) -> List[MemCube]:"""基于语义相似度的智能检索"""# 使用向量检索 + 图谱遍历混合策略# RRF (Reciprocal Rank Fusion) + MMR (Maximal Marginal Relevance)pass
class MemLifecycle:def __init__(self):self.state_machine = {'generated': ['active', 'archived'],'active': ['archived', 'fused'],'archived': ['expired'],'fused': ['active', 'archived']}def transition(self, memory_id: str, new_state: str) -> bool:"""记忆状态转换:generated → active → archived → expired支持fusion操作合并相似记忆"""passdef version_rollback(self, memory_id: str, version: int) -> bool:"""支持记忆版本回滚,确保可追溯性"""pass
class MemOperator:def organize_memory(self, user_id: str) -> None:"""使用标签系统、图结构和多层分区组织记忆支持结构化和语义搜索的混合查询"""# 图谱遍历算法# 语义向量检索# 结构化过滤(时间、标签、来源)pass
2.1.3 基础设施层(Infrastructure Layer)
class MemGovernance:def __init__(self):self.access_control = RBAC()self.lifecycle_policies = PolicyEngine()self.audit_trail = AuditLogger()def check_permission(self, user_id: str, memory_id: str, action: str) -> bool:"""基于RBAC的记忆访问控制"""passdef enforce_policy(self, memory_id: str) -> None:"""强制执行生命周期策略和合规要求"""pass
class MemVault:def __init__(self):self.backends = {'vector': VectorDB(),'graph': GraphDB(),'kv': KVStore()}def unified_access(self, memory_type: str) -> StorageBackend:"""统一访问异构存储后端:- 向量数据库:语义检索- 图数据库:关系推理- KV存储:高速访问"""pass
2.2 MemCube:统一记忆抽象
class MemCube:def __init__(self, content: str, metadata: Dict):self.content = contentself.metadata = {'timestamp': datetime.now(),'heat_score': 0.0, # 热度评分'source': 'conversation', # 来源类型'version': 1, # 版本号'permission': 'private', # 权限级别'modality': 'text', # 模态类型:text/image/tool/persona**metadata}def fuse(self, other_cube: MemCube) -> MemCube:"""融合两个相似的记忆块"""# 内容合并、热度聚合、版本更新passdef migrate(self, target_type: str) -> MemCube:"""在不同记忆类型间迁移:- Activation → Plaintext(持久化)- Plaintext → Parametric(参数化)"""pass
Activation Memory (KV-Cache)↓ (转换)Plaintext Memory (Vector DB + Graph DB)↓ (微调)Parametric Memory (LoRA Adapters)
3. Token节省机制核心算法
3.1 智能检索算法
class HybridRetriever:def retrieve(self, query: str, top_k: int = 5) -> List[MemCube]:"""四阶段检索流程:1. 全文检索(FTS5):关键词匹配2. 向量检索:语义相似度计算3. RRF融合:倒排排名融合4. MMR重排:最大边缘相关性去重5. 时间衰减:近期的记忆优先"""# 阶段1:FTS5全文检索fts_results = self._fts_search(query)# 阶段2:向量相似度检索vector_results = self._vector_search(query)# 阶段3:RRF融合fused_results = self._rrf_fusion(fts_results, vector_results)# 阶段4:MMR去重和重排序reranked_results = self._mmr_rerank(fused_results, top_k)# 阶段5:时间衰减调整final_results = self._apply_time_decay(reranked_results)return final_results[:top_k]def _rrf_fusion(self, results1: List, results2: List, k: int = 60) -> List:"""Reciprocal Rank Fusion算法:score(d) = Σ(1 / (k + rank_i(d)))"""scores = {}for i, doc in enumerate(results1):scores[doc.id] = 1 / (k + i + 1)for i, doc in enumerate(results2):scores[doc.id] = scores.get(doc.id, 0) + 1 / (k + i + 1)return sorted(scores.items(), key=lambda x: x[1], reverse=True)def _mmr_rerank(self, candidates: List, lambda_param: float = 0.7) -> List:"""Maximal Marginal Relevance算法:平衡相关性和多样性,避免重复内容"""selected = []while len(selected) < len(candidates):best_score = -1best_idx = 0for i, candidate in enumerate(candidates):if candidate in selected:continue# 相关性得分rel_score = candidate.relevance_score# 多样性惩罚(与已选项的相似度)div_penalty = max([self._similarity(candidate, sel)for sel in selected], default=0)# MMR得分mmr_score = lambda_param * rel_score - (1 - lambda_param) * div_penaltyif mmr_score > best_score:best_score = mmr_scorebest_idx = iselected.append(candidates[best_idx])return selected
3.2 记忆压缩算法
class MemoryCompressor:def compress_conversation(self, messages: List[Message]) -> List[MemCube]:"""对话历史压缩算法:1. 语义分块:将对话切分为语义相关的片段2. 关键信息提取:使用LLM提取关键事实和决策3. 摘要生成:生成长期记忆的简洁摘要4. 去重:检测和合并重复信息"""# 阶段1:语义分块chunks = self._semantic_chunking(messages)# 阶段2:关键信息提取key_facts = []for chunk in chunks:facts = self._extract_key_facts(chunk)key_facts.extend(facts)# 阶段3:去重和融合deduplicated_facts = self._deduplicate_facts(key_facts)# 阶段4:生成MemCubememcubes = [MemCube(content=fact, metadata={'type': 'compressed_conversation','original_length': len(messages),'compression_ratio': len(messages) / len(deduplicated_facts)})for fact in deduplicated_facts]return memcubes
3.3 异步处理机制
class AsyncMemoryProcessor:def __init__(self):self.redis_streams = RedisStreams()self.task_queue = PriorityQueue()async def process_message_async(self, messages: List[Message]) -> str:"""异步消息处理:1. 将消息加入Redis Streams队列2. 返回task_id,立即响应3. 后台Worker处理消息4. 支持任务优先级和自动恢复"""task_id = str(uuid.uuid4())# 创建任务task = MemoryTask(id=task_id,data=messages,priority=self._calculate_priority(messages),created_at=datetime.now())# 加入队列await self.redis_streams.add_to_queue('memory_processing', task)# 立即返回task_id,不等待处理完成return task_idasync def worker_loop(self):"""Worker后台处理循环:- 从队列获取任务- 执行记忆处理- 处理失败重试- 更新任务状态"""while True:task = await self.redis_streams.get_next_task('memory_processing')try:# 处理消息memcubes = self._process_task(task.data)# 存储记忆await self.storage.store(memcubes)# 更新任务状态为完成await self.task_queue.complete(task.id)except Exception as e:# 记录错误,标记任务失败await self.task_queue.fail(task.id, str(e))# 如果是临时错误,加入重试队列if self._is_retryable(e):await self.task_queue.retry(task.id)
4. OpenClaw集成实践
4.1 插件架构设计
// 插件配置示例(openclaw.json){"plugins": {"entries": {"memos-cloud-openclaw-plugin": {"enabled": true}}},"load": {"paths": ["~/.openclaw/extensions/memos-cloud-openclaw-plugin/package"]}}
4.2 核心集成机制
4.2.1 生命周期钩子
class MemOSOpenClawPlugin:def before_agent_start(self, agent_context: Dict) -> str:"""Agent启动前检索记忆:1. 构造/search/memory请求2. 使用用户消息作为查询3. 获取相关记忆片段4. 注入到Agent的系统上下文"""# 构造检索请求search_request = {'user_id': agent_context['user_id'],'query': agent_context['current_message'],'top_k': 6,'filters': {'tags': ['openclaw'],'conversation_id': agent_context.get('conversation_id')}}# 调用MemOS搜索APImemories = self.memos_client.search_memory(** search_request)# 构造上下文注入字符串context_template = """System: You are a helpful AI assistant with long-term memory.User Memories:{memories}Use these memories to provide personalized and context-aware responses."""memories_str = "\n".join([f"- {mem['content']}"for mem in memories['results']])context = context_template.format(memories=memories_str)# 注入到Agent上下文return self.prepend_context(agent_context, context)def agent_end(self, agent_context: Dict) -> str:"""Agent结束后保存记忆:1. 提取当前对话轮次2. 构造/add/message请求3. 异步保存到MemOS"""# 提取最后一轮对话last_turn = agent_context['conversation_history'][-2:] # [user, assistant]# 构造添加消息请求add_request = {'user_id': agent_context['user_id'],'conversation_id': agent_context.get('conversation_id', 'default'),'messages': last_turn,'tags': ['openclaw'],'async_mode': True # 异步模式,不阻塞响应}# 调用MemOS添加消息APIresult = self.memos_client.add_message(**add_request)return result['task_id']
# 优化的插件配置示例plugin_config = {# 记忆数量控制'memoryLimitNumber': 6, # 每次检索最多6条记忆'preferenceLimitNumber': 6, # 用户偏好记忆数量# 对话ID管理'conversationSuffixMode': 'counter', # 使用计数器模式'resetOnNew': True, # 新对话时重置# 记忆类型控制'includeAssistant': True, # 包含助手回复'includePreference': True, # 包含用户偏好'includeToolMemory': False, # 不包含工具记忆(降低Token)# 知识库集成'knowledgebaseIds': [], # 可选的知识库列表# 标签和元数据'tags': ['openclaw', 'production'], # 统一标签# 异步处理'asyncMode': True, # 启用异步处理,避免阻塞}
4.4 记忆迁移机制
class MemoryMigrationTool:def scan_native_memories(self, openclaw_path: str) -> Dict:"""扫描OpenClaw原生记忆:- 检测~/.openclaw/下的SQLite数据库- 解析JSONL日志文件- 统计文件数、会话数、消息数"""scan_result = {'databases': [],'log_files': [],'total_sessions': 0,'total_messages': 0}# 扫描SQLite数据库db_path = os.path.join(openclaw_path, 'memory.db')if os.path.exists(db_path):scan_result['databases'].append(db_path)# 解析数据库...# 扫描JSONL日志log_dir = os.path.join(openclaw_path, 'logs')if os.path.exists(log_dir):for log_file in os.listdir(log_dir):if log_file.endswith('.jsonl'):scan_result['log_files'].append(log_file)# 解析日志...return scan_resultdef migrate_to_memos(self, scan_result: Dict, progress_callback: Callable) -> Dict:"""执行记忆迁移:- 智能去重- 断点续传- 实时进度反馈- 任务与技能生成"""migration_stats = {'imported': 0,'skipped': 0, # 重复数据'merged': 0, # 相似记忆融合'errors': 0}# 分批处理,避免内存溢出batch_size = 100for db_file in scan_result['databases']:# 读取原生记忆native_memories = self._read_sqlite_db(db_file)# 分批处理for i in range(0, len(native_memories), batch_size):batch = native_memories[i:i+batch_size]# 去重和融合processed_batch = self._deduplicate_and_fuse(batch)# 添加到MemOSfor memory in processed_batch:try:self.memos_client.add_message(user_id=memory['user_id'],conversation_id=memory['conversation_id'],messages=[memory['message']],tags=['openclaw', 'migrated'])migration_stats['imported'] += 1except DuplicateMemoryError:migration_stats['skipped'] += 1except Exception as e:migration_stats['errors'] += 1logger.error(f"Migration error: {e}")# 更新进度progress_callback({'total': len(native_memories),'processed': min(i+batch_size, len(native_memories)),'stats': migration_stats})return migration_stats
5. Token节省效果对比分析
5.1 传统方案 vs MemOS方案对比
维度 | 传统全上下文方案 | RAG方案 | MemOS方案 |
Token消耗 | 100% (基准) | 60-70% | 35-40% |
响应延迟 | 高(长上下文) | 中(检索延迟) | 低(毫秒级检索) |
记忆持久性 | 无 | 部分(静态知识) | 完整(动态演化) |
个性化程度 | 低 | 中 | 高(用户画像) |
多轮一致性 | 差 | 中 | 优(状态追踪) |
系统复杂度 | 低 | 中 | 高(需要部署) |
5.2 具体场景Token节省分析
方案 | 第一轮 | 第二轮 | 第三轮 | 总Token |
传统全上下文 | 200 | 400 (200+200) | 600 (400+200) | 1,200 |
RAG方案 | 200 | 250 (200+50) | 300 (250+50) | 750 |
MemOS方案 | 200 | 220 (200+20) | 240 (220+20) | 660 |
智能检索:仅检索相关的VIP身份和退款记录(20 tokens) 状态压缩:将对话历史压缩为结构化记忆 个性化:记住用户偏好和上下文
方案 | 第一轮 | 第二轮 | 第三轮 | 第四轮 | 总Token |
传统全上下文 | 300 | 600 | 900 | 1,200 | 3,000 |
RAG方案 | 300 | 350 | 400 | 450 | 1,500 |
MemOS方案 | 300 | 320 | 340 | 360 | 1,320 |
代码记忆:记住函数签名和关键逻辑(20 tokens) 上下文压缩:将解释性对话压缩为知识点 工具记忆:记住常用的代码模式和最佳实践
5.3 长期对话场景分析
对话轮次 | 传统方案Token | MemOS方案Token | 累计节省 |
1 | 200 | 200 | 0% |
2 | 400 | 220 | 45% |
3 | 600 | 240 | 60% |
4 | 800 | 260 | 67.5% |
5 | 1,000 | 280 | 72% |
10 | 2,000 | 380 | 81% |
6. 源码分析:核心模块实现
6.1 源码目录结构分析
src/memos/├── api/ # API接口层│ ├── server_api.py # REST API服务器│ └── client.py # Python客户端├── mem_os/ # 核心操作系统模块├── mem_cube/ # MemCube记忆单元管理├── mem_scheduler/ # 记忆调度器├── mem_feedback/ # 记忆反馈和修正├── mem_chat/ # 聊天集成模块├── mem_reader/ # 自然语言解析器├── embedders/ # 文本嵌入模型├── vec_dbs/ # 向量数据库适配器├── graph_dbs/ # 图数据库适配器└── search/ # 混合检索引擎
6.2 关键模块源码分析
6.2.1 混合检索引擎
# src/memos/search/hybrid_retriever.pyclass HybridRetriever:def __init__(self, config: Dict):self.fts_searcher = FTSSearcher(config['fts_config'])self.vector_searcher = VectorSearcher(config['vector_config'])self.reranker = Reranker(config['reranker_config'])async def search(self, query: str, filters: Dict = None) -> List[MemCube]:"""异步混合检索实现"""# 并行执行FTS和向量检索fts_task = asyncio.create_task(self.fts_searcher.search(query, filters))vector_task = asyncio.create_task(self.vector_searcher.search(query, filters))fts_results, vector_results = await asyncio.gather(fts_task, vector_task)# RRF融合fused_results = self._rrf_fusion(fts_results, vector_results)# MMR重排序reranked_results = await self.reranker.rerank(fused_results)# 时间衰减final_results = self._apply_time_decay(reranked_results)return final_results
6.2.2 记忆调度器
# src/memos/mem_scheduler/scheduler.pyclass MemScheduler:def __init__(self):self.redis_client = Redis()self.task_queue = "memory_tasks"self.priority_levels = {'high': 10,'normal': 5,'low': 1}async def schedule_task(self, task: MemoryTask) -> str:"""使用Redis Streams实现任务调度"""task_id = str(uuid.uuid4())# 将任务加入Redis Streamsawait self.redis_client.xadd(self.task_queue,{'task_id': task_id,'data': json.dumps(task.data),'priority': str(self.priority_levels[task.priority])})# 设置任务过期时间(24小时)await self.redis_client.expire(self.task_id, 86400)return task_idasync def process_tasks(self):"""Worker任务处理循环"""while True:# 从队列获取任务task_data = await self.redis_client.xreadgroup('memory_workers','worker_1',{self.task_queue: '>'},count=1,block=1000)if task_data:for stream, messages in task_data:for message_id, data in messages:task = MemoryTask.from_json(data[b'data'])try:# 处理任务result = await self._process_task(task)# 标记任务完成await self.redis_client.xack(self.task_queue,'memory_workers',message_id)except Exception as e:logger.error(f"Task processing error: {e}")# 重新加入队列(最多重试3次)if task.retry_count < 3:await self._retry_task(task_id)
6.2.3 API接口实现
# src/memos/api/server_api.pyfrom fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelapp = FastAPI(title="MemOS API")class AddMessageRequest(BaseModel):user_id: strconversation_id: strmessages: List[MessageInput]tags: List[str] = []async_mode: bool = True@app.post("/add/message")async def add_message(request: AddMessageRequest):"""添加消息到记忆系统"""try:# 创建任务task = MemoryTask(user_id=request.user_id,conversation_id=request.conversation_id,messages=request.messages,tags=request.tags)if request.async_mode:# 异步处理task_id = await scheduler.schedule_task(task)return {"code": 0,"data": {"success": True,"task_id": task_id,"status": "running"},"message": "ok"}else:# 同步处理result = await process_message_sync(task)return {"code": 0,"data": result,"message": "ok"}except Exception as e:raise HTTPException(status_code=500, detail=str(e))class SearchMemoryRequest(BaseModel):user_id: strquery: strtop_k: int = 6conversation_id: str = Nonefilters: Dict = None@app.post("/search/memory")async def search_memory(request: SearchMemoryRequest):"""搜索相关记忆"""try:# 构造检索参数search_params = {'query': request.query,'user_id': request.user_id,'top_k': request.top_k}if request.conversation_id:search_params['filters'] = {'conversation_id': request.conversation_id}if request.filters:if 'filters' not in search_params:search_params['filters'] = {}search_params['filters'].update(request.filters)# 执行检索results = await hybrid_retriever.search(** search_params)return {"code": 0,"data": {"results": results,"total": len(results)},"message": "ok"}except Exception as e:raise HTTPException(status_code=500, detail=str(e))
7. 性能优化建议
7.1 部署优化
# docker-compose.ymlversion: '3.8'services:memos:image: memtensor/memos:latestenvironment:- REDIS_URL=redis://redis:6379- VECTOR_DB=qdrant- QDRANT_URL=http://qdrant:6333ports:- "8001:8001"depends_on:- redis- qdrantredis:image: redis:7-alpineports:- "6379:6379"qdrant:image: qdrant/qdrant:latestports:- "6333:6333"
version: '3.8'services:memos-api:image: memtensor/memos:latestenvironment:- REDIS_CLUSTER_URL=redis://redis-cluster:7000- VECTOR_DB=weaviate- WEAVIATE_URL=http://weaviate:8080- GRAPH_DB=neo4j- NEO4J_URL=bolt://neo4j:7687deploy:replicas: 3resources:limits:cpus: '2'memory: 4Gports:- "8001:8001"depends_on:- redis-cluster- weaviate- neo4jredis-cluster:image: redis:7-alpinecommand: redis-cli --cluster create ...# Redis集群配置...weaviate:image: semitechnologies/weaviate:latestenvironment:- QUERY_CACHE_ENABLED=trueports:- "8080:8080"neo4j:image: neo4j:5-enterpriseenvironment:- NEO4J_ACCEPT_LICENSE_AGREEMENT=yesports:- "7474:7474"- "7687:7687"
7.2 检索优化
optimized_search_config = {# 检索数量控制'fts_top_k': 50, # 全文检索候选数'vector_top_k': 50, # 向量检索候选数'final_top_k': 10, # 最终返回数量# RRF参数'rrf_k': 60, # RRF融合参数(越大越重视排名)# MMR参数'mmr_lambda': 0.7, # 相关性权重(越大越重视相关性)# 时间衰减'time_decay_base': 0.9, # 时间衰减基数'time_decay_unit': 'day', # 时间单位# 缓存配置'enable_cache': True,'cache_ttl': 3600, # 缓存过期时间(秒)'cache_size': 1000, # 缓存大小}
7.3 存储优化
# Qdrant索引优化qdrant_config = {'index_params': {'hnsw_config': {'m': 16, # HNSW图的连接数(越大越准确但越慢)'ef_construct': 100, # 构建索引时的搜索深度'full_scan_threshold': 10000 # 全扫描阈值},'optimizers_config': {'indexing_threshold': 20000, # 索引创建阈值'default_segment_number': 2 # 默认分段数},'quantization_config': {'scalar': {'type': 'int8', # 使用int8量化,减少内存占用'always_ram': True}}}}
# Neo4j查询优化neo4j_config = {'index_config': {'user_id': 'CREATE INDEX FOR (m:Memory) ON (m.user_id)','conversation_id': 'CREATE INDEX FOR (m:Memory) ON (m.conversation_id)','timestamp': 'CREATE INDEX FOR (m:Memory) ON (m.timestamp)','modality': 'CREATE INDEX FOR (m:Memory) ON (m.modality)'},'query_cache': {'enabled': True,'size': 1000}}
8. 实践案例:从零搭建MemOS+OpenClaw系统
8.1 环境准备
# 1. 克隆MemOS仓库git clone https://github.com/MemTensor/MemOS.gitcd MemOS# 2. 安装依赖pip install -r ./docker/requirements.txt# 3. 配置环境变量cp docker/.env.example .env# 编辑.env文件,填入必要的配置
8.2 启动MemOS服务
# 使用Docker Compose启动docker compose up -d# 或使用uvicorn启动(需要先启动Neo4j和Qdrant)cd srcuvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 1
8.3 安装OpenClaw插件
# 方式A:使用NPM安装(推荐)openclaw plugins install @memtensor/memos-cloud-openclaw-plugin@latestopenclaw gateway restart# 方式B:手动安装(Windows解决方案)# 下载.tgz包并解压到~/.openclaw/extensions/# 修改openclaw.json配置
8.4 配置插件
# 创建环境变量配置cat > ~/.openclaw/.env << EOFexport MEMOS_API_KEY="your_api_key"export MEMOS_BASE_URL="http://localhost:8001/api/openmem/v1"EOF# 应用配置source ~/.openclaw/.env
8.5 测试集成
# 测试脚本import requests# 配置API_KEY = "your_api_key"BASE_URL = "http://localhost:8001/api/openmem/v1"# 测试添加消息add_response = requests.post(f"{BASE_URL}/add/message",headers={"Content-Type": "application/json","Authorization": f"Token {API_KEY}"},json={"user_id": "test_user","conversation_id": "test_conversation","messages": [{"role": "user", "content": "我喜欢咖啡"},{"role": "assistant", "content": "好的,我记住了"}],"async_mode": True})print(f"添加消息结果: {add_response.json()}")# 测试搜索记忆search_response = requests.post(f"{BASE_URL}/search/memory",headers={"Content-Type": "application/json","Authorization": f"Token {API_KEY}"},json={"user_id": "test_user","query": "我喜欢什么饮料?","top_k": 5})print(f"搜索记忆结果: {search_response.json()}")
9. 总结与展望
9.1 核心价值
统一了参数记忆、激活记忆和明文记忆的管理 提供了可扩展、可治理的记忆生命周期管理 实现了跨会话、跨任务、跨Agent的知识共享
降低35-50%的Token消耗,显著降低运营成本 提升响应速度和用户体验 支持个性化和长期记忆,增强AI Agent的智能化水平
9.2 适用场景
长期运行的AI Assistant系统 需要个性化推荐的产品 多轮对话的客服系统 需要知识积累的代码助手 多Agent协同系统
简单的单轮问答系统 对延迟极其敏感的实时系统 数据量极小的原型系统 对隐私要求极高的场景(可考虑自部署)
9.3 未来展望
参数记忆优化:通过LoRA/Adapter实现更高效的参数化记忆 跨模态记忆:支持图像、音频、视频等多模态记忆的统一管理 联邦学习:在保护隐私的前提下实现跨用户的知识共享 自动记忆压缩:基于深度学习的智能记忆压缩算法
企业知识管理:构建企业级的AI记忆系统 个性化教育:为学生提供个性化学习路径 医疗健康:构建患者长期健康档案 科学研究:辅助科学家管理和研究文献
