 夜雨聆风
夜雨聆风
点击蓝字 关注我们 您的专属AI解决方案架构师
智能体
OpenClaw与强化学习结合!
原有的OpenClaw智能体是通过调用外部的记忆文件和技能库来适应环境与任务的,但其底层大语言模型的权重参数实际上从未被更新过。
补充说明:“基础模型权重”指的是构成大语言模型的数百万乃至数十亿个可调整的参数。传统的“监督微调”会直接修改这些权重,而原文中OpenClaw的原始方式更像是一种“外部工具调用”,模型本身是固定的。
而OpenClaw-RL则解决了这个根本性的限制!
补充说明:“RL”即强化学习。在这里,它意味着智能体通过与环境的交互(试错)来获得奖励或惩罚信号,并利用这些信号来直接更新和优化其底层模型的权重,从而实现更本质、更灵活的学习与进化。
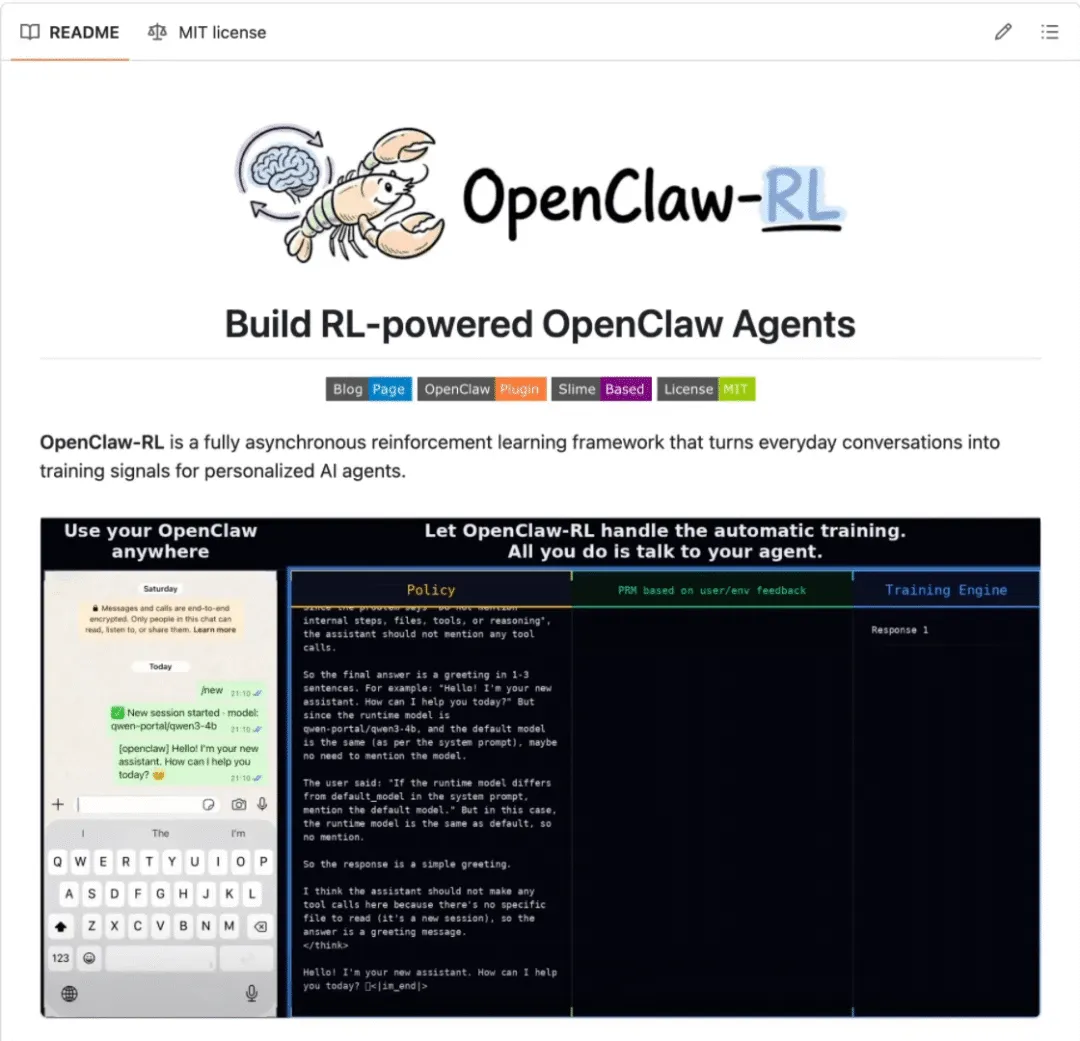
它将一个自托管模型封装成与OpenAI兼容的API,拦截来自OpenClaw的实时对话,并在后台使用强化学习来训练策略。
该架构是完全异步的。这意味着模型服务、奖励评分和训练可以并行运行。
训练完成后,权重会在每批处理后进行热替换,而智能体在此期间仍能持续响应用户。
目前,它支持两种训练模式:
• 二元强化学习(GRPO):一个过程奖励模型会对每一轮对话进行评分(好、坏或中立)。这个标量奖励会通过一个PPO(近端策略优化)风格的、带裁剪的目标函数来驱动策略更新。
补充说明:PPO(Proximal Policy Optimization)是强化学习中一种常用的策略优化算法,其核心思想是在更新模型策略时,通过裁剪等方式限制每次更新的幅度,以确保训练的稳定性。
• 策略蒸馏:当出现具体的纠正性反馈时(例如“你应该先检查那个文件”),它会将这种反馈作为一个更丰富、更具方向性的训练信号,在词元级别上进行学习。
何时应该使用OpenClaw-RL?
公平地说,许多智能体行为其实已经可以通过改进记忆和技能设计来优化。
OpenClaw现有的技能生态系统和社区构建的自改进技能,能在完全不触及模型权重的情况下,处理非常广泛的使用场景。
如果智能体总是忘记用户的偏好,那是个记忆问题;如果它不知道如何处理特定的工作流程,那是个技能问题。这两个问题都可以在提示词和上下文层得到解决。
强化学习真正大显身手的场景,是当问题的根源深植于模型自身的推理过程中时。
例如:持续性地选择错误的工具使用顺序、多步骤规划能力薄弱,或者无法按照特定用户的意图去解读那些模糊的指令。
关于智能体强化学习的研究(如ARTIST和Agent-R1)表明,单凭基于提示词的方法,这些行为模式会遇到性能瓶颈,尤其是在复杂的多轮任务中——比如当模型需要从工具使用失败中恢复,或在任务执行中途调整策略时。
这正是OpenClaw-RL所针对的层面,也是它与OpenClaw所提供的功能之间的一个本质区别。
**你可以在这里找到代码仓库 →**
https://github.com/Gen-Verse/OpenClaw-RL
在文章的最后,想给大家强烈推荐一个我平时部署项目经常用的神器——Zeabur。
不管你是想快速上线一个前端全栈网页、部署小程序后台,还是跑一些大模型相关的 AI 应用(OpenClaw、n8n),Zeabur 都能帮你省去折腾服务器环境的麻烦,真正做到极简部署,让你把时间花在写代码本身上。
如果你刚好需要部署自己的项目,或者准备购买他们家的服务器和 AI Hub 额度,结账的时候一定要记得填我的专属推荐码:xiaomukuaier (小木块儿的全拼)。
用我的推荐码,你可以直接享受 10% 的专属折扣,省下一笔钱;同时你也是在支持我的公众号,让我能有一点点佣金收益,继续给大家产出更多硬核的技术内容。这波绝对是双赢!
注册链接和推荐码如下。赶紧去试试吧,部署代码从未如此简单!感谢大家的三连支持,我们下篇文章见!
🚀 极简代码部署平台 Zeabur:https://zeabur.com/zh-CN/templates
💰 结账输入推荐码 xiaomukuaier 立享折扣!
我的理念是:让天下没有难做的智能体。如果您的企业需要智能体降本提效创收,欢迎后台联系我!
🔥【AI与代码前沿基地】🚀 高频更新!助你抢占技术先机!
🌟 你是否:
❌ 苦恼AI技术更新太快,跟不上核心概念?
❌ 代码实操一学就会,一写就废?
❌ 想获取行业前瞻洞察,却找不到深度解析?
✅ 在这里,你将获得:
▷ 系统性AI知识库:机器学习→深度学习→大模型,零基础到进阶
▷ 最新技术速递:紧跟ChatGPT、Deepseek等全球AI突破,附实战代码
▷ 开发者工具箱:Python案例拆解+自动化实操,拒绝纸上谈兵
▷ AI解决方案:面向您的场景,端到端搭建AI解决方案
📌 点击右上角“关注”✅小木块lambda,快人一步掌握未来!
#人工智能 #编程实战 #科技趋势 #干货分享
