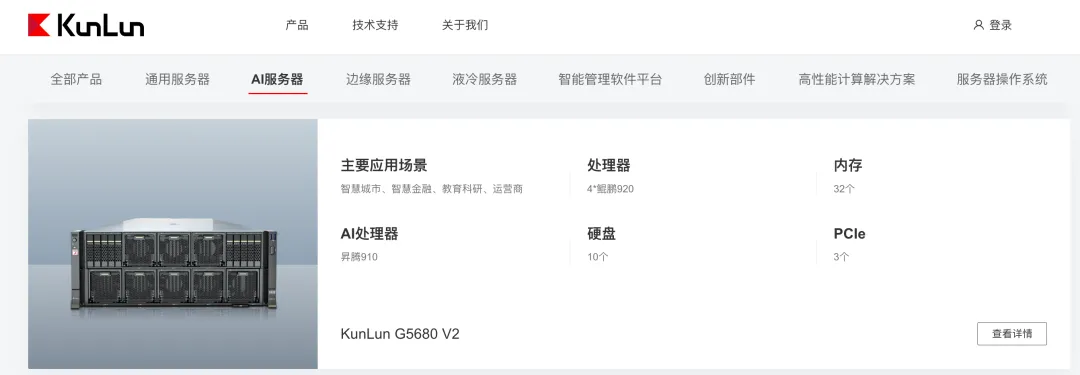
人工智能大模型离线安装部署指南在大多数场景下,在线部署只需等待即可完成。但在特种行业,情况截然不同——要么客户采购一体机,要么必须进行离线部署。当离线部署遇上国产化环境,难度直线上升。本文直奔主题,分享实战经验。目前,国内主流的国产算力芯片厂商已形成多元格局,代表企业包括华为昇腾、海光信息、寒武纪、摩尔线程、沐曦集成电路等。在党政、特种行业等关键领域,目前的应用仍以华为昇腾的解决方案为主。本文以昆仑 KunLun G5680 V2 推理服务器(2台)作为部署对象。在华为昇腾生态中,服务器整机厂商如百信、华鲲振宇、昆仑等均采用相同的昇腾算力底座,差异主要在于品牌和外观,底层架构与技术方案高度一致。非常理解你现在的心情——服务器到位了,模型不知道装啥。这确实是国产化离线部署中最头疼的一环:面对Hugging Face上几十万个模型,选哪个?下哪个版本?怎么在没有网的情况下搞定?其实到了这一步,核心思路很简单:前端应用平台决定模型的类型,算力服务器决定模型的大小。只要把业务场景拆清楚,模型选型就明朗了。
建议多看社区和官网!!!!
| | |
| openEuler-22.03-LTS-aarch64-dvd.iso | https://www.openeuler.org/zh/download/archive/detail/?version=openEuler%2022.03%20LTS |
| Ascend-hdk-910b-npu-driver_24.1.rc3_linux-aarch64.run | https://www.hiascend.com/hardware/firmware-drivers/community?product=4&model=26&cann=8.0.0.beta1&driver=1.0.28.alpha |
| Ascend-hdk-910b-npu-firmware_7.5.0.1.129.run |
| | Index of linux/static/stable/ |
| | https://quay.io/repository/ascend/vllm-ascend?tab=tags |
| | https://modelscope.cn/models |
| https://modelers.cn/models/State_Cloud/DeepSeek-R1-W8A8/tree/main |
|
| https://www.modelscope.cn/models/appofis/DeepSeek-V3-0324-w8a8/files |
| https://www.modelscope.cn/models/Qwen/Qwen3-235B-A22B/files |
其实离线安装也没有那么复杂,就是把线上安装我们看不到下载,偷偷安装部署,简单介绍下离线部署的流程:环境准备--安装驱动固件--安装Docker--导入镜像--导入模型权重--拉起模型权重--测试验证4.1环境准备:
1. 资源下载:提前准备操作系统镜像、驱动固件、安全组件、Docker、vLLM工具以及模型权重文件。
2. 存储配置与系统安装:服务器上电后配置RAID——系统盘做RAID1,数据盘做RAID5或RAID6,然后安装操作系统。
3. 基础环境配置:操作系统安装完成后,关闭防火墙和SELinux,配置网络参数,并开启SSH远程登录服务。
4.2安装NPU驱动固件:主要安装NPU的驱动,让系统能够识别NPU算力卡。
4.3安装Docker:模型权重都是基于Docker容器部署的,正常安装,建议安装最新版本。
4.4导入镜像:目前市面上较多的工具有,VLLM、MinDIE、Sglang,根据自己掌握的工具进行下载。
4.5导入模型权重:根据自己业务定的模型,到魔塔社区、魔乐社会下载。
4.5拉起模型权重:启动服务
4.7测试验证:编辑测试脚本进行测试,官网都有或者直接进行前端智能体应用接入模型测试。
本次我就以纯文本模型 MiniMax-M2.5为举例,其他模型安装类似,我们用一台服务器8卡来部署MiniMax-M2.5,230GB啊,网络环境差的,建议提前下载。
完整版《国产化环境离线部署实战手册》正在紧锣密鼓编辑中,涵盖硬件配置、环境搭建、模型选型到离线部署全流程,附赠实战脚本。想要第一时间获取完整版的朋友,点点关注,避免错过!

 夜雨聆风
夜雨聆风