 夜雨聆风
夜雨聆风已关注
关注
重播 分享 赞
ASM3029213v1:Bacillus albus的基因组在NCBI上的名字
GCF_030292135.1:Bacillus albus在NCBI上的身份证号,具有唯一性
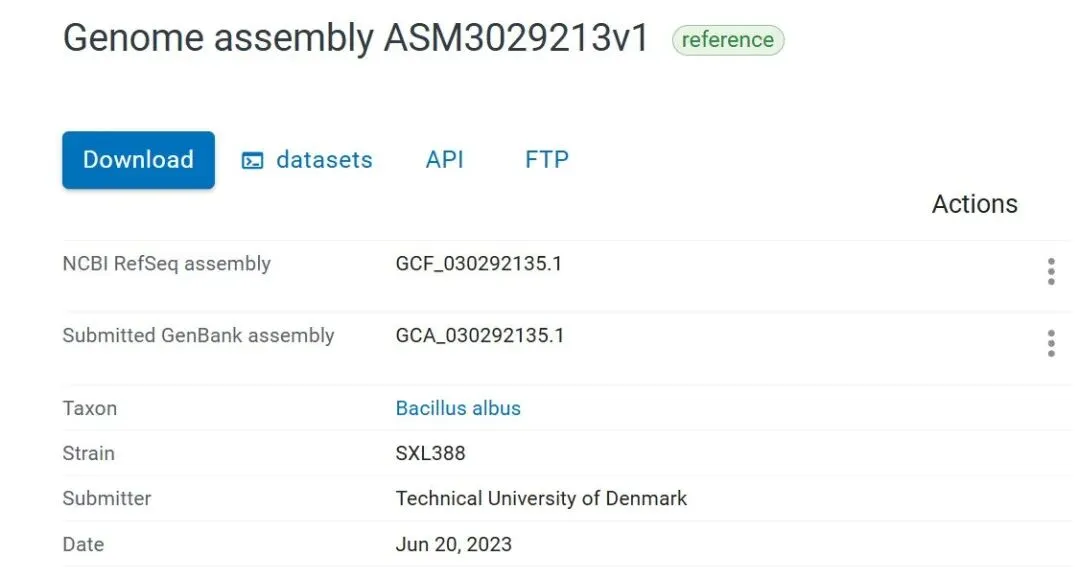
基因组装质量:
Completeness = 98.82%:98.82%完整度
Contamination 0.1%:污染极低
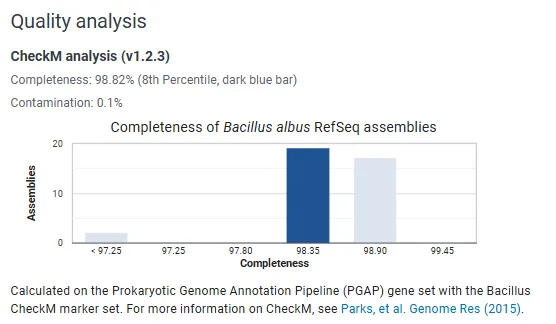
下载的基因组必要信息解读:
GCF_030292135.1:微生物的身份信息
md5sum.txt:用来校验文件是否完整
GCA_030292135.1 和 GCF_030292135.1:同一个基因组装配的两个数据库版本
GCF_030292135.1:优先用 GCF
核心分析文件:*.fna、*.gff、*.faa
 使用服务器批量逐个下载基因组数据:
使用服务器批量逐个下载基因组数据:#!/bin/bash#SBATCH -J download_ncbi_genomes#SBATCH -p common#SBATCH -N 1#SBATCH -c 2#SBATCH --mem=5G#SBATCH -t 4:00:00#SBATCH -o /xxx/xxxx/xxx/genes/log/download.%j.out#SBATCH -e /xxx/xxxx/xxx/genes/log/download.%j.errset -uo pipefail# 基础目录BASE_DIR="/xxx/xxxx/xxx/genes"LOG_DIR="$BASE_DIR/log"OUT_DIR="$BASE_DIR/single_downloads"ACC_FILE="$BASE_DIR/accessions.txt"FAILED_FILE="$BASE_DIR/failed_accessions.txt"# datasets 工具路径DATASETS="/xxx/xxxx/xxx/conda/envs/ncbi/bin/datasets"# 自动创建目录mkdir -p "$BASE_DIR" "$LOG_DIR" "$OUT_DIR"# 自动写入 accession 列表(*需要下载多少个,将“身份证号”进行对应替换*)cat > "$ACC_FILE" << 'EOF'GCA_xxxxxxxxx.1GCA_xxxxxxxxx.2GCA_xxxxxxxxx.3GCA_xxxxxxxxx.4GCA_xxxxxxxxx.5GCA_xxxxxxxxx.6GCA_xxxxxxxxx.7GCA_xxxxxxxxx.8 #微生物基因组的身份证信息EOF# 清空失败记录: > "$FAILED_FILE"# 检查 datasets 是否存在if [[ ! -x "$DATASETS" ]]; thenecho "Error: datasets not found or not executable: $DATASETS" >&2exit 1fiecho "=== datasets path ==="echo "$DATASETS"echo "=== datasets version ===""$DATASETS" versioncd "$OUT_DIR"echo "=== 开始逐个下载基因组 ==="datesuccess_count=0fail_count=0while read -r acc; do[[ -z "$acc" ]] && continueecho "=== downloading $acc ==="rm -f "${acc}.zip"if "$DATASETS" download genome accession "$acc" \--include genome,gff3,protein \--filename "${acc}.zip"; thenecho "=== finished $acc ==="success_count=$((success_count + 1))elseecho "=== failed $acc ===" >&2echo "$acc" >> "$FAILED_FILE"rm -f "${acc}.zip"fail_count=$((fail_count + 1))fidone < "$ACC_FILE"echo "=== 下载结束 ==="echo "success: $success_count"echo "failed : $fail_count"echo "failed list:"cat "$FAILED_FILE" || truedate
