 夜雨聆风
夜雨聆风既然 OpenClaw 能接飞书、能调工具、能跑后台任务,那我能不能直接在飞书里跟它说一句“帮我用这个数据集训一个 YOLO”,然后它自己去开训练、盯进度、最后把结果发给我?
答案是:
能做,而且确实有用。但如果你期待它“自动把模型训好、自动把参数调对、自动替你做完整 MLOps(机器学习运维)”,那就想多了。OpenClaw 更适合做的是:把训练这件事,从“你一直盯着终端”变成“你在飞书里发指令、随时追问、到点收结果”。它本身就支持飞书渠道、skills、自定义 webhook,以及后台 exec/process 这类能力,所以做“训练调度入口”是顺手的。


很多人一听“OpenClaw 自动训练神经网络”,第一反应是:它是不是能替我做训练决策?是不是能像一个资深算法工程师一样自动选模型、自动调参、自动收敛?
很遗憾,不是。
OpenClaw 真正靠谱的地方,不是让模型更聪明,而是让训练流程更顺手。它本质上是一个运行在你自己设备或服务器上的自托管 Gateway,能把飞书等聊天渠道和 AI 助手连起来;它还支持用SKILL.md定义技能、用 webhook 接外部事件、用后台 exec/process 管理长任务。也就是说,它特别适合做“训练控制层”,而不是“训练算法本体”。
换句话说:
它最擅长的不是把模型训得更好,而是把训练这件事变得更像“对话式操作系统”。
这就是它最有爆点的地方。

这件事看起来很小,实际上很大。
以前你做训练,要自己记:
数据集路径
模型权重
epochs、batch、imgsz
日志目录
结果目录
训练跑到哪了
现在可以变成一句话:
“用这个数据集训练 YOLO11s,100 个 epoch,每 10 个 epoch 给我汇报一次。”
OpenClaw 接飞书后,本身就能在聊天入口收消息;而飞书通道走的是 WebSocket 事件订阅,不需要专门暴露公网 webhook,这让“训练助手”这件事更容易接起来。
真正有价值的不是“少敲几条命令”,而是:训练终于可以被放进你每天就在用的沟通界面里。
真正折磨人的,从来不是启动训练,而是中途反复确认:
现在第几轮了?
有没有爆显存?
指标涨没涨?
是不是该停了?
结果出来没有?
OpenClaw 这类 Agent 的优势,是它本来就支持后台 exec/process,能发长任务,还能通过 webhook 把外部事件再推回聊天界面。也就是说,你完全可以把它做成一个会主动汇报训练状态的助手,而不是一个只会接命令的壳。
这个体验上的变化非常大:
以前是你记得去看训练;以后是训练有事来找你。
OpenClaw 的定位本来就是个人 AI 助手,官方也明确强调:更推荐一个信任边界对应一个 Gateway,而不是让互不信任的人共用一个高权限 Agent。
这反而说明一件事:
它特别适合个人、课题组内部、小团队私有环境。
你自己掌控机器、自己掌控数据、自己掌控工具边界,然后把“训练启动—状态查询—结果通知”这一条打通,这时候它非常顺手。 但你要是想把它直接做成“很多陌生人共享的云训练平台”,那就不是它最舒服的用法了。

这是最大误区。
OpenClaw 能帮你把训练流程串起来,但它不会天然提升你的数据质量,也不会自动发明出最优参数,更不会替你理解任务本身。 数据集烂,照样训不出来;标注有问题,照样会翻车;任务定义不清晰,照样会得到一堆看起来很忙但没价值的输出。
所以它更像是一个训练管家,不是一个训练魔法师。
OpenClaw 当然能跑后台任务,也能调 webhook,也能接聊天渠道,但它的核心定位不是完整的多租户训练平台。官方文档里,后台 exec/process 的描述也很清楚:长任务由 exec 启动,process 管理这些后台会话,而这些后台输出主要保存在内存会话里供后续轮询。
这意味着什么?
意味着它很适合做入口层、控制层、通知层,但不适合被你当成“全部训练基础设施”。 真正的训练执行,最好还是交给你自己的训练脚本、任务队列、容器或 GPU Worker。
一句话说穿:
OpenClaw 擅长“帮你管训练”,不擅长“替你承包整个训练平台”。
如果一个 Agent 能收飞书消息、能调 shell、能读写文件,那它天然就有风险。 OpenClaw 官方对这一点写得很明确:不建议把一个高权限 Gateway 暴露给互不信任的多用户;更推荐按信任边界拆分,并对 DM、pairing、scope 做限制。
所以真正靠谱的做法不是“给 OpenClaw 所有权限”,而是:
只让它调用固定训练脚本
只允许固定参数
只允许固定数据目录
只允许单人飞书 DM 使用
这时候它才是生产力;否则它很容易从“省事”变成“事故”。

我的判断很直接:
如果你要的是“聊天式训练控制”,它靠谱。如果你要的是“自动帮我把模型训明白”,它不靠谱。
它最值得做的,不是因为它能替代工程师,而是因为它能替代那些低价值、重复、琐碎、却一直消耗你注意力的训练管理动作。
这才是 OpenClaw 在训练场景里的真正爆点:
它不替你思考,但它能把你从“守着训练”这件事里解放出来。

为了保证大多数读者能真的跑起来,本文采用下面这套假设:
系统:Ubuntu 22.04 或类似 Linux;
训练框架:Ultralytics YOLO;
聊天入口:飞书 DM;
OpenClaw:装在同一台训练机,或至少能访问训练脚本目录;
目标:完成“发起训练 + 查询状态 + 自动通知”闭环。
如果你是 Windows 用户,OpenClaw 官方目前仍然更推荐在 WSL2 里跑;Node 24 为推荐版本。安装上,官方推荐直接走安装脚本和openclaw onboard引导。
第1步:安装 OpenClaw,并接入飞书
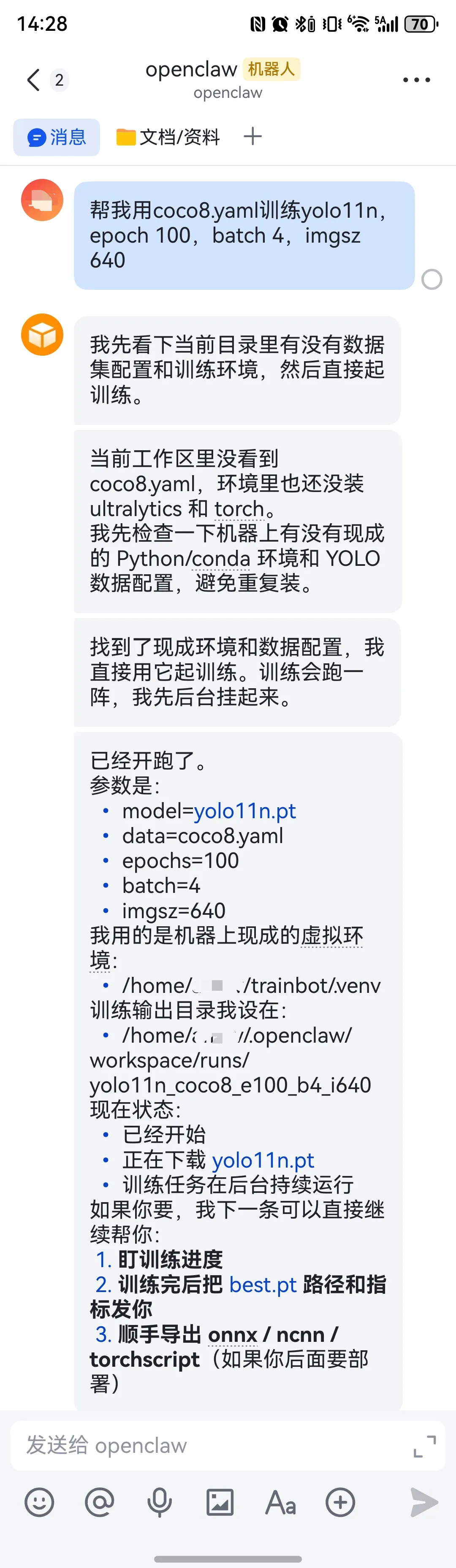
OpenClaw 官方推荐的安装方式是安装脚本;安装后用 openclaw onboard做引导配置。飞书通道也支持通过引导或openclaw channels add接入;配好后可以用openclaw gateway status和openclaw logs --follow检查。飞书通道默认支持 pairing,unknown sender 会收到配对码,批准后才能正式对话。
# 1) 安装 OpenClaw(官方推荐)curl -fsSL https://openclaw.ai/install.sh | bash# 2) 跑引导openclaw onboard# 3) 如需安装为常驻服务openclaw onboard --install-daemon# 4) 查看状态openclaw gateway statusopenclaw logs --follow
飞书这边,你只要照引导创建企业自建应用、填 App ID / App Secret 即可。OpenClaw 飞书通道是用 WebSocket 收事件,不需要你额外去暴露一个公网 webhook,这一点对于实验室环境非常友好。飞书插件还支持流式回复、交互卡片、文件/图片等消息类型。
第2步:先把 OpenClaw 配成“适合做训练助手”的样子
OpenClaw 的配置文件默认在~/.openclaw/openclaw.json;大部分配置支持热更新。官方文档也建议把 DM scope 设成per-channel-peer,避免多人或不同对话之间上下文串台;hooks 和 cron 也都是配置级的一等能力。
我建议你先用下面这份最小可用配置:
//~/.openclaw/openclaw.json{agents: {defaults: {workspace:"~/.openclaw/workspace",sandbox: {mode:"non-main",scope:"agent"}}},session: {dmScope:"per-channel-peer"},channels: {feishu: {enabled:true,dmPolicy:"pairing",streaming:true,blockStreaming:true}},cron: {enabled:true,maxConcurrentRuns:2,sessionRetention:"24h"},hooks: {enabled:true,token:"${OPENCLAW_HOOKS_TOKEN}",path:"/hooks",defaultSessionKey:"hook:train",allowRequestSessionKey:false,allowedSessionKeyPrefixes: ["hook:"]}}
上面这几项各自的作用很清楚: workspace是 skill 的默认落盘位置;dmScope: "per-channel-peer"用来做 DM 隔离;cron负责调度;hooks用来让训练脚本在关键节点反向通知 OpenClaw;而飞书开启streaming后,生成过程会走交互卡片更新。官方也明确建议 hooks 使用 bearer token,并且默认关闭 request 侧自定义sessionKey,改用固定defaultSessionKey更稳。
第3步:不要直接让 AI 执行yolo train,而是写一个训练包装脚本
这一步是全文最关键的设计点。
OpenClaw 的exec/process确实可以直接把长任务丢到后台,但官方文档同时强调:后台 session 只存在内存里,Gateway 重启后就没了。所以如果你直接让 OpenClaw 背景跑一个训练命令,短期能用,长期不稳。更好的办法是:把训练状态和日志额外落盘。这样即使 OpenClaw 重启了,你也还能通过status.json 和日志文件把状态捞回来。
建议目录结构如下:
~/trainbot├── train_job.py├── requirements.txt├── jobs/│ └── <job_id>/│ ├── status.json│ └── train.log└── runs/
先装依赖:
mkdir -p ~/trainbot/jobs ~/trainbot/runspython3 -m venv ~/trainbot/.venvsource ~/trainbot/.venv/bin/activatepip install ultralytics pandas pyyaml requests
然后把下面这个脚本保存为~/trainbot/train_job.py。它做四件事:
校验数据集 YAML;
启动 Ultralytics YOLO 训练;
周期性读取
results.csv,刷新status.json;每到若干 epoch、以及训练结束时,通过 OpenClaw hooks 主动发消息。
Ultralytics 官方文档说明了训练 CLI 的基本形式,以及data、model、epochs 等参数含义;数据集 YAML 也明确包含 train/val 和类别配置。
如果需要train_job.py的具体实现,评论区留下邮箱,稍后会发给您。
第4步:写一个真正“懂训练”的 OpenClaw Skill
OpenClaw 的 skill 就是一个目录,里面至少要有一个SKILL.md。官方文档写得很清楚:skill 通常放在~/.openclaw/workspace/skills/下,SKILL.md用 YAML frontmatter + Markdown 指令描述能力,OpenClaw 会自动发现并加载。它还支持基于SKILL.md 变更自动刷新。
创建目录:
mkdir -p ~/.openclaw/workspace/skills/yolo-train-manager保存下面这份~/.openclaw/workspace/skills/yolo-train-manager/SKILL.md:
---name: yolo_train_managerdescription: 启动、查询、停止本机 YOLO 训练任务。---# YOLO Train Manager当用户要“训练 YOLO / 启动训练 / 看训练进度 / 停止训练”时,优先使用本 skill。## 安全边界- 不要执行用户提供的任意 shell 片段。- 只接受这些训练参数:model, data, epochs, imgsz, batch, device。- data 必须位于 `/data` 或其子目录。- project 固定为 `~/trainbot/runs`。- 训练脚本固定为 `~/trainbot/train_job.py`。## 启动训练当用户要发起训练时:1. 先确认 data 是一个 `.yaml` 路径。2. 生成一个 job_id,格式建议:`yolo_YYYYMMDD_HHMMSS`。3. 使用 `exec` 工具后台启动:`source ~/trainbot/.venv/bin/activate && python ~/trainbot/train_job.py --job-id <job_id> --model <model> --data <data> --epochs <epochs> --imgsz <imgsz> --batch <batch> --device <device> --project ~/trainbot/runs`4.`background=true`,`pty=true`,`workdir=~/trainbot`。5. 成功后告诉用户 job_id,并提醒可以继续问“现在训练怎么样了”。## 查询状态当用户问“训练怎么样了/现在到哪了”时:1. 如果用户给了 job_id,就读取 `~/trainbot/jobs/<job_id>/status.json`。2. 如果没给 job_id,就优先查看 `~/trainbot/jobs/` 下最近修改的任务。3. 用中文总结:- state- current_epoch / epochs- best_map50- best_map5095- best_pt- log_path4. 如果需要更多日志,再读取 `train.log` 的最后若干行。## 停止训练当用户要求停止时:1. 读取对应任务的 `status.json`。2. 若存在 pid,则执行 `kill -TERM <pid>`。3. 告诉用户任务已请求停止,并建议稍后再查状态确认是否退出。## 结果汇报当状态是 finished 时:- 告诉用户 best.pt 路径、best mAP50、best mAP50-95、日志路径。- 给出一句简短建议,例如“下一轮可以提高 imgsz”或“当前收益已开始放缓”。
这份 skill 的核心价值,不是“替你写很多代码”,而是把 AI 能做的事收进边界里:
它只能帮你整理受限参数、调用固定脚本、读固定状态文件、总结固定结果,而不是被一句“顺手把别的目录也删了”带偏。OpenClaw 官方文档本身就反复强调:tool-enabled agent 有 shell 和文件能力时,一定要做路径和工具边界约束。
创建完成后,让 OpenClaw 刷新 skills,或者直接重启 gateway:
openclaw gateway restart# 或者直接在聊天里对它说:refresh skills
第5步:在飞书里,你到底该怎么说
到这一步,你已经能在飞书里像下面这样说话了:
用
/data/uav/uav.yaml训练 YOLO11s,epochs 100,imgsz 960,batch 16,device 0。每 10 个 epoch 给我汇报一次。
或者:
帮我看看刚才那个训练现在怎么样了。
再或者:
停掉最新那个任务。
OpenClaw 这时做的其实不是“替你瞎猜命令”,而是三步:
skill 把你的自然语言收束成结构化参数;
exec后台启动训练包装脚本;包装脚本持续写
status.json,并在关键节点调用 hooks 回推消息。
这也是为什么我不建议你直接把所有训练逻辑塞进 OpenClaw 自己的会话里:后台process 会话只在内存里,重启就丢;而状态文件和日志落盘后,整个链路会稳很多。
定时汇报进度:
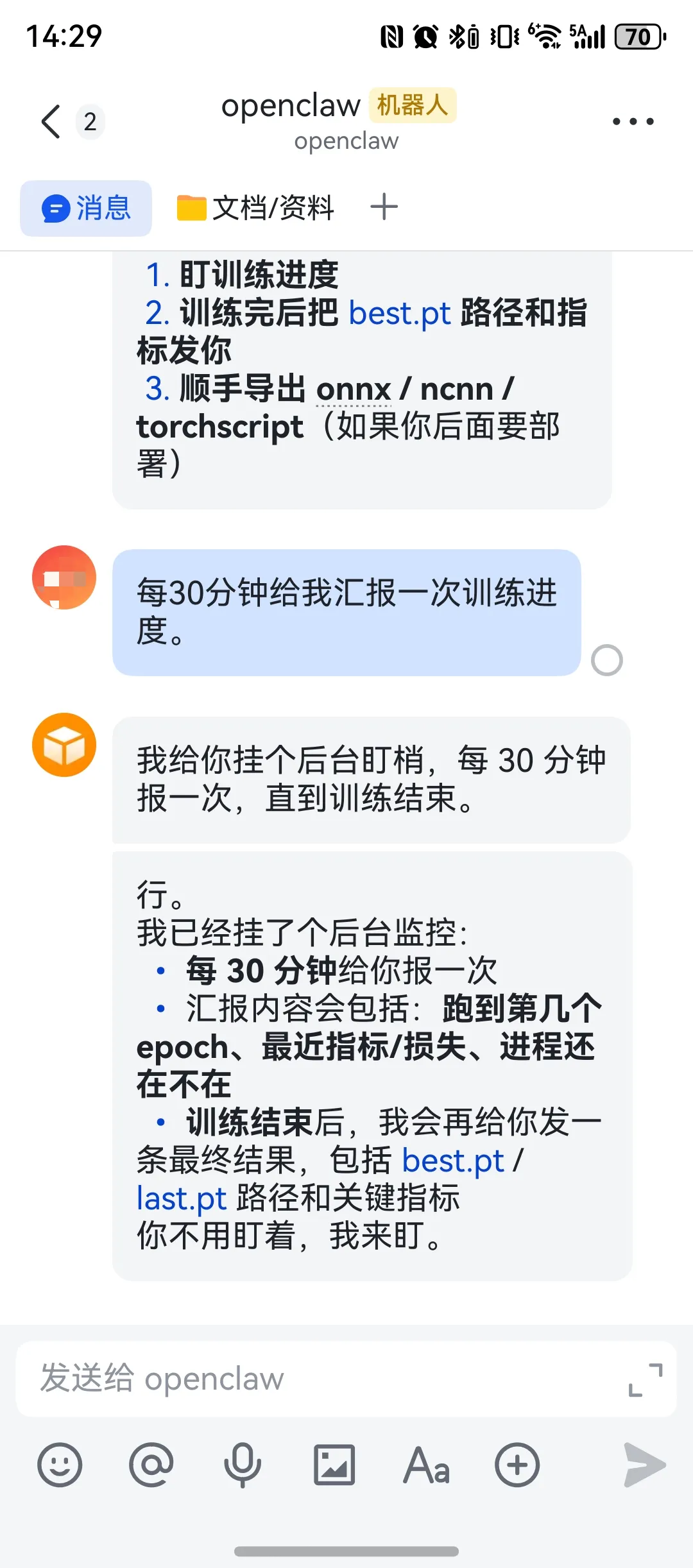

如果你问我:
“OpenClaw 自动训练神经网络,靠谱吗?”
我的回答是:
靠谱,但靠谱的不是‘自动把模型训好’,而是‘自动把训练流程管顺’。
它最有价值的,不是让你少写两条命令, 而是让训练第一次变成了一件可以被聊天、被追问、被主动汇报的事。
这件事,看起来不惊天动地,但谁真正长期训过模型,谁就知道它有多值。




