 夜雨聆风
夜雨聆风感谢国内大中小厂在过去一个月中的狂飙突进,OpenClaw🦞的安装部署已不再如一个月前那样困难,我也基本上把国内近半数🦞的安装部署保姆教程写了一遍...该进入下个阶段了:养虾🦞
养虾养虾,养的究竟是什么?给🦞配上实用高效的skills;让🦞不常忘事儿;让🦞可以持续自我提升;让多个🦞可以彼此协作;等等等等...... 都是养虾
没有两个人(或两个组织)的工作流是完全相同,这或许就意味着没有两只🦞会相同:
• 它们要记的东西不一样; • 它们拥有的skills不同(即便是从同一个source下载的同一个skill可能也会在很短时间内演化成不同的特异化skills); • 它们进化的路径不同; • 它们彼此协作的模式也互不相同~
养虾🦞的最高境界,就是能养出每个组织(现在一个人OPC也是组织)里可以完美fit in业务场景的Agents
虽然虾各不同,但总是会存在一些非常重要基础设施明显优于绝大多数其他同类的。因此,从今天开始,我将启动一个新“养虾基建系列”,将一些在特定任务方向上你大概率躲不掉的养虾基建介绍给你。
今天是该系列第1篇:给大家介绍视频下载界的瑞士军刀yt-dlp,它可以下载1700个网站的视频;如果你的工作流经常围绕视频展开(下载视频,提取音频,抽取文本,二次加工等等),你必然不能错过yt-dlp;它的归宿是:被封装成🦞的skill。
第一章:yt-dlp 是什么?开源世界的接力赛
1.1 从 youtube-dl 到 yt-dlp:一场善意的"叛乱"
要理解 yt-dlp 的来历,得先聊聊它的"老祖宗" youtube-dl。
2006年,youtube-dl 项目横空出世。这是一个用 Python 编写的命令行工具,专门用于从 YouTube 下载视频。在当年那个在线视频刚刚兴起的年代,youtube-dl 简直就是技术爱好者的福音。它开源、免费、跨平台,支持自定义下载参数,很快就在开发者圈子里积累了大量拥趸。
随后的十几年里,youtube-dl 逐渐成长为一个庞然大物。支持的网站从最初的几家扩展到上千家,功能也从单纯的视频下载发展到音频提取、字幕下载、播放列表批量处理等方方面面。它成为了 GitHub 上 Star 数最多的项目之一,被无数用户视为必备工具。
然而,到了 2020 年左右,youtube-dl 的开发节奏开始明显放缓。
问题的根源在于维护模式。youtube-dl 采用了一种相对传统的开源治理方式,代码审查严格但响应速度较慢。而视频网站的反爬机制却在不断进化——YouTube 频繁调整页面结构,TikTok 不断更换 API 接口,各大平台都在用各种技术手段阻止自动化下载。当 youtube-dl 的更新速度跟不上网站变化的速度时,用户开始感受到明显的阵痛:今天还能用的命令明天就失效了,昨天刚修复的 bug 今天又以另一种形式出现了。
2020 年,一位名叫 pukkandan 的开发者基于 youtube-dl 创建了一个分支版本,命名为 youtube-dlc(那个 "c" 代表 "community",社区版)。这个版本的目标是更激进地合并社区贡献的修复和新功能,以更快的响应速度应对网站的变化。
但这还只是开始。2021 年,pukkandan 决定更进一步,从 youtube-dlc 中分化出一个全新的项目,这就是 yt-dlp。名字中的 "yt" 代表 YouTube(虽然它远不止支持 YouTube),"dlp" 则是 "download plus" 的缩写——下载,再加上更多。
这个决策的时间点把握得恰到好处。就在 yt-dlp 诞生后不久,youtube-dl 的维护陷入了更长时间的停滞,而 yt-dlp 凭借其活跃的开发节奏和丰富的功能特性,迅速接管了大部分用户群体。如今,yt-dlp 在 GitHub 上已经积累了近 10 万个 Star,成为了视频下载工具领域毋庸置疑的事实标准。
1.2 为什么叫"瑞士军刀"?
瑞士军刀之所以经典,不在于某一项功能有多么惊艳,而在于它把各种实用的工具都集成在了手掌大小的空间里。yt-dlp 也是如此。
想象一下这样一个场景:你需要下载一个 YouTube 播放列表里的所有视频,但只想要 1080p 分辨率的 MP4 格式,还要把视频里的字幕提取出来嵌入到文件中,同时自动跳过片头的赞助商广告片段,最后把下载好的文件按照"上传日期-频道名-视频标题"的格式命名,并存放到不同的文件夹里。
用普通的下载工具,这恐怕需要打开好几个软件,进行无数次点击和设置。而用 yt-dlp,只需要一行命令就能搞定。
这种"一键搞定复杂需求"的能力,正是 yt-dlp 的核心竞争力所在。它就像是一位训练有素的数字管家,你告诉它想要什么,它就会调动各种内部模块,自动完成从网络请求、格式解析、数据下载、格式转换到文件整理的全套流程。
第二章:震撼数字背后的硬实力
2.1 支持的网站:超过 1700 个平台
yt-dlp 到底能下载多少个网站的视频?答案是:超过 1700 个。
这个数字听起来可能有些抽象。让我们换个角度理解:基本上你在日常使用互联网时会接触到的所有主流视频平台,yt-dlp 都能处理。
海外视频平台:YouTube、Twitch、Instagram、Vimeo、Reddit等视频网站、直播平台、社交媒体视频、视频分享网站等各类国际主流视频平台(甚至一些在这里不能提及名字的视频网站)……这些都是基础配置。
国内平台同样覆盖全面:小红书、Bilibili(支持分P视频、弹幕、收藏夹、频道)、抖音、快手、西瓜视频、优酷、爱奇艺(部分)、腾讯视频(部分)、微博视频……
新闻媒体和专业站点:全球各大电视台、新闻网站、学术平台、教育站点、技术分享社区等。
音乐平台也能搞定:SoundCloud、Bandcamp、Spotify(播客)、Apple Music(部分)……你可以直接从这些平台下载音频文件。
更有趣的是,yt-dlp 采用了一种模块化的"提取器"(Extractor)架构。每一个支持的网站都对应一个独立的提取器模块,负责处理该网站的页面解析和链接提取。这意味着当某个网站改版时,只需要更新对应的提取器即可,不会影响到其他功能。同时,这种架构也让社区贡献新网站的变得相对容易——有经验的开发者可以按照既定规范编写新的提取器,提交合并请求,经过审核后就能让 yt-dlp 支持新的平台。
2.2 下载速度:从龟速到火箭的蜕变
很多早期用过 youtube-dl 的用户都有一个痛苦的记忆:下载速度奇慢无比。
这不是 youtube-dl 本身的问题,而是 YouTube 的"锅"。大约从 2021 年开始,YouTube 引入了一种基于 "n-sig"(签名)的节流机制。简单来说,如果系统检测到请求来自非浏览器环境(比如命令行工具),就会故意限制下载速度,从正常的几 MB/s 骤降到几十 KB/s。以这种速度下载一个 1GB 的视频,可能需要好几个小时。
yt-dlp 的团队很快注意到了这个问题。经过深入分析,他们找到了绕过这种节流机制的方法,并在 yt-dlp 中实现了相应的修复。这一改进的效果是立竿见影的:同样网络环境下,yt-dlp 的下载速度可以达到 16-17 MB/s,而 youtube-dl 只有 50-60 KB/s——差距达到了两三百倍。
但这还不是全部。yt-dlp 还引入了多线程分段下载(Multi-threaded Fragment Downloads)的功能。
现代视频网站为了优化播放体验,普遍采用 HLS(HTTP Live Streaming)或 DASH(Dynamic Adaptive Streaming over HTTP)技术。这些技术会把一个完整的视频切割成无数个几秒的片段(fragments),播放时根据网络状况动态选择不同清晰度的片段。这种架构对下载工具提出了新的挑战:你需要同时下载成百上千个片段,然后再把它们拼接起来。
yt-dlp 的解决方案是并行下载。通过 --concurrent-fragments(或简写 -N)参数,你可以指定同时下载多少个片段。比如设置为 4,就意味着有 4 个线程同时工作,理论上可以把下载速度提升到单线程的 4 倍。再配合 aria2c 这样的外部下载器(yt-dlp 支持调用 aria2c 来处理 HLS/DASH 流),速度还能进一步提升。
2.3 音视频质量:不做选择题,全都要
早期的视频下载工具往往面临一个两难选择:要么下载画质最好的版本(但只有视频没有声音),要么下载带声音但画质一般的版本。这是因为 YouTube 等平台从某个时间点开始,将视频流和音频流分离存储——高清视频单独一个文件,音频单独一个文件,播放器在播放时才会把它们合并起来。
yt-dlp 彻底解决了这个问题。当你要求下载"最佳质量"时,它会自动分析可用的格式,分别选择画质最好的视频流和音质最好的音频流,下载完成后再调用 FFmpeg 自动合并成一个完整的文件。整个过程对用户完全透明,你拿到手的永远是一个音画同步、质量最优的视频文件。
更妙的是格式选择功能。通过 -F 参数,yt-dlp 会列出目标视频所有可用的格式(分辨率、编码格式、文件大小等),每个格式对应一个数字 ID。然后你可以用 -f 参数指定想要的格式,比如只下载音频、只下载 720p 以下视频等。甚至可以用类似 -f "bestvideo[height<=1080]+bestaudio/best" 这样的条件语句,让 yt-dlp 自动选择最佳组合。
第三章:那些让人直呼"卧槽"的高级功能
3.1 SponsorBlock:自动跳过广告的神器
如果你经常看 YouTube 上的技术教程、测评视频或播客,一定对"本期视频由 XX 赞助"这种开场白深恶痛绝。更烦人的是,这类赞助片段往往长达几十秒,而且创作者通常会把它放在视频最精彩的部分之前,让你不得不看完。
SponsorBlock 是一个众包项目,它让用户手动标记视频中的各种片段类型:赞助商广告、片头片尾、订阅提醒、自我宣传、无关闲聊等。这些数据被整理成一个公开的数据库,供各种工具调用。
yt-dlp 内置了对 SponsorBlock 的支持。你可以通过 --sponsorblock-remove 参数,在下载视频时自动删除被标记的赞助片段。或者使用 --sponsorblock-mark 把这些片段保留下来,但标记为章节(chapter),方便你在播放器里快速跳过。
想象一下:下载一个一小时的编程教程,里面的三个广告片段被自动剔除,你拿到的就是一个纯净的教学视频。这种体验简直不要太爽。
3.2 从浏览器导入 Cookie:访问受限内容
很多视频网站都有年龄限制内容,需要登录并验证年龄后才能观看。还有些视频是私人的,只有特定用户或订阅者才能访问。传统的下载工具面对这种情况往往束手无策,因为它们无法提供登录凭证。
yt-dlp 提供了一个优雅的解决方案:直接从你的浏览器里读取 Cookie。
通过 --cookies-from-browser 参数,你可以指定 Chrome、Firefox、Safari、Edge、Brave、Opera 等主流浏览器。yt-dlp 会自动读取浏览器存储的 Cookie 文件,提取出目标网站需要的登录凭证。这样一来,只要你在浏览器里能看的视频,yt-dlp 就能下载。
更贴心的是,这个操作是只读的——yt-dlp 只是读取 Cookie,不会修改或泄露你的登录信息。当然,为了安全起见,建议只在个人电脑上使用这个功能。
3.3 下载视频的任意片段:精准裁剪
有时候你不需要下载整个视频,只想保存其中的某个精彩片段。yt-dlp 的 --download-sections 参数就是为了这种场景而生的。
你可以通过时间戳指定要下载的片段,比如 --download-sections "*0:30-2:15" 表示下载从 30 秒到 2 分 15 秒的部分。通配符 * 表示对视频中的每个章节都应用这个时间范围。
更进一步,如果你下载的是带章节标记的视频(比如音乐专辑、课程视频),还可以用 --split-chapters 参数把视频按章节自动分割成多个独立的文件。每个章节都会成为一个单独的视频文件,文件名里包含章节编号和标题。
3.4 实时直播的"时光机"
看直播最大的遗憾是什么?是错过。主播刚说了个重磅消息,你因为走神或网络卡顿没听清;或者你想回顾直播开头的内容,但已经播了两个小时。
yt-dlp 的 --live-from-start 参数为这个问题提供了一个解决方案:它可以从直播开始的地方下载,而不是从当前时间点。也就是说,即使直播已经进行了三小时,你也能从头开始下载完整的内容。
这个功能对于那些希望存档重要直播(比如发布会、赛事、学术讲座)的用户来说简直是救星。配合 --wait-for-video 参数,你甚至可以提前设定好命令,等直播开始后再自动执行下载。
3.5 元数据的艺术:让文件自己会说话
下载下来的视频文件,如果只是一串随机字符的文件名,很快就会淹没在硬盘的海量文件中。yt-dlp 提供了强大的元数据(Metadata)处理能力,让下载的文件自带"身份证"。
首先是指定输出文件名的模板。通过 -o 参数,你可以使用各种变量来组合文件名,比如 %(title)s(标题)、%(uploader)s(上传者)、%(upload_date)s(日期)等。
比如 -o "%(upload_date)s_%(uploader)s_%(title)s.%(ext)s",下载的文件名就会是"20260318_频道名_视频标题.mp4"的格式。
更进一步,yt-dlp 可以把这些信息直接写入视频文件的元数据标签中。通过 --embed-metadata 参数,标题、艺术家、日期、描述等信息会被嵌入到 MP4、MKV 等格式文件的元数据区域,方便媒体库软件(如 Plex、Emby、Jellyfin)自动识别和分类。
对于音频文件,还可以用 --embed-thumbnail 把视频的封面图嵌入为音频文件的专辑封面。想象一下,下载下来的播客 MP3 在播放器里显示着精美的封面,体验提升不止一个档次。
第四章:实战场景——yt-dlp 能为你做什么
4.1 场景一:建立个人视频资料库
假设你是一名深度学习研究者,经常需要观看各种学术报告和教程视频。YouTube 上有大量优质内容,比如 NeurIPS、ICML 等顶会的官方频道,各种大学教授的课程录像,还有像 "3Blue1Brown" 这样优秀的数学可视化频道。
用 yt-dlp,你可以建立一个自动化的资料收集流程:
# 下载整个播放列表,按顺序命名yt-dlp -o "%(playlist_index)02d - %(title)s.%(ext)s" \ -f "bestvideo[height<=1080]+bestaudio/best" \ --embed-metadata --embed-subs --sub-langs en \ "PLAYLIST_URL"这条命令会:
1. 下载播放列表中的所有视频 2. 文件名以两位数序号开头(01、02、03……),方便按顺序观看 3. 限制最高 1080p 分辨率(节省硬盘空间) 4. 嵌入元数据和英文字幕 5. 如果视频本身没有字幕,还会尝试下载自动生成的字幕
4.2 场景二:音频播客订阅
很多优质的播客内容发布在 YouTube 上,但你可能更习惯在通勤时用耳机听音频版。yt-dlp 可以把视频一键转换为音频:
# 提取最佳音质音频并转换为 MP3yt-dlp -x --audio-format mp3 --audio-quality 0 \ --embed-thumbnail --embed-metadata \ -o "%(uploader)s/%(title)s.%(ext)s" \ "VIDEO_URL"参数说明:
• -x(或--extract-audio):只提取音频• --audio-format mp3:转换为 MP3 格式(还支持 aac、m4a、opus、vorbis、flac、wav)• --audio-quality 0:最高音质(0-10,0 是最好,9 是最差)• --embed-thumbnail:把视频封面嵌入为音频封面• --embed-metadata:写入标题、艺术家等元数据
4.3 场景三:字幕提取与翻译
看外语视频时,字幕是刚需。yt-dlp 支持下载视频的各种字幕:
# 下载所有可用字幕(包括自动生成)yt-dlp --write-subs --write-auto-subs --sub-langs "en,zh-CN" \ --convert-subs srt \ "VIDEO_URL"如果你希望字幕直接嵌入到视频文件中(而不是单独的字幕文件),可以加上 --embed-subs 参数。这样下载的视频在任何播放器中打开都会自动显示字幕,无需额外操作。
4.4 场景四:批量备份社交媒体内容
对于内容创作者来说,备份自己在各平台发布的内容是个明智之举。平台的政策随时可能变化,账号也可能因为各种原因被封禁,提前备份能避免多年的心血付诸东流。
# 下载整个 YouTube 频道的所有视频(慎用,可能很大)yt-dlp -f "bestvideo[height<=720]+bestaudio/best" \ -o "%(upload_date)s - %(title)s.%(ext)s" \ --download-archive archive.txt \ "CHANNEL_URL"--download-archive archive.txt 参数会记录已经下载过的视频 ID,下次运行时自动跳过,避免重复下载。
4.5 场景五:代理与网络环境
在某些网络环境下(比如公司内网),直接访问外部视频平台可能会受限。yt-dlp 支持通过代理连接,具体配置方式如下:
# 使用 HTTP 代理yt-dlp --proxy http://代理地址:端口 "URL"# 使用 SOCKS5 代理yt-dlp --proxy socks5://代理地址:端口 "URL"此外,yt-dlp 还提供了一些处理地理限制内容的参数,具体可参考官方文档。
第五章:yt-dlp vs youtube-dl:为什么要"背叛"经典
虽然 youtube-dl 是 yt-dlp 的"父辈",但在 2026 年的今天,选择 yt-dlp 几乎是毫无悬念的决定。以下是关键差异的详细对比:
5.1 维护状态:活人与僵尸的区别
youtube-dl 的最后一次实质性更新停留在 2021 年底。虽然项目没有被正式放弃,但维护者几乎不再合并社区提交的修复补丁。这意味着当 YouTube、TikTok 等平台调整页面结构或 API 时,youtube-dl 无法及时响应,用户只能面对各种报错信息干瞪眼。
相比之下,yt-dlp 保持着每周甚至每天更新的节奏。开发团队和社区贡献者们时刻关注着各大视频平台的变化,一旦发现网站改版导致提取器失效,通常几小时内就会有修复版本发布。
5.2 功能对比:麻雀与凤凰
5.3 默认行为的优化
yt-dlp 不仅在功能上更丰富,默认设置也更加合理:
• 格式选择策略:yt-dlp 默认优先选择更高分辨率和更先进编码格式(如 AV1、VP9)的视频,而 youtube-dl 只看码率 • 文件名模板:yt-dlp 默认在文件名中包含视频 ID( [%(id)s]),方便追溯来源;youtube-dl 不包含• 缩略图嵌入:yt-dlp 使用 mutagen 库处理 MP4 文件的缩略图嵌入,速度更快且无需额外依赖;youtube-dl 依赖 AtomicParsley • 错误处理:yt-dlp 默认开启 --no-abort-on-error,遇到错误会继续处理列表中的其他视频;youtube-dl 默认遇到错误就终止
5.4 Python 版本要求
yt-dlp 要求 Python 3.9 或更高版本(Python 3.8 已于 2024 年 11 月结束支持)。这让它可以使用 Python 的现代特性,代码更简洁高效。
youtube-dl 为了兼容性,至今仍支持 Python 2.6+,这意味着大量过时的代码包袱和无法使用新特性。
5.5 迁移成本
好消息是,从 youtube-dl 迁移到 yt-dlp 几乎没有学习成本。两者命令行参数高度兼容,绝大多数 youtube-dl 的命令可以直接在 yt-dlp 中使用。如果确实有某些行为差异,yt-dlp 还提供了 --compat-options 参数来模拟 youtube-dl 的特定行为。
第六章:上手教程——从零开始驯服这头野兽
6.1 安装
macOS(推荐用 Homebrew):
brew install yt-dlp ffmpegWindows(用 winget):
winget install yt-dlpLinux(各种发行版):
# Ubuntu/Debiansudo apt install yt-dlp ffmpeg# Arch Linuxsudo pacman -S yt-dlp ffmpeg# 或者用 pippip install -U yt-dlp注意:强烈建议同时安装 FFmpeg,它是处理视频合并、格式转换、元数据嵌入的必备工具。
6.2 第一条命令
最简单的用法,只需要提供视频 URL:
yt-dlp "https://www.youtube.com/watch?v=..."yt-dlp 会自动选择最佳格式,下载到当前目录,文件名为"视频标题 [视频ID].webm/mp4"。
6.3 常用参数速查表
-F | yt-dlp -F "URL" | |
-f | yt-dlp -f 22 "URL" | |
-o | yt-dlp -o "%(title)s.%(ext)s" "URL" | |
-P | yt-dlp -P ~/Downloads "URL" | |
-x | yt-dlp -x "URL" | |
--audio-format | yt-dlp -x --audio-format mp3 "URL" | |
--write-subs | yt-dlp --write-subs "URL" | |
--embed-subs | yt-dlp --embed-subs "URL" | |
--write-thumbnail | yt-dlp --write-thumbnail "URL" | |
--cookies-from-browser | yt-dlp --cookies-from-browser chrome "URL" | |
--proxy | yt-dlp --proxy http://127.0.0.1:7890 "URL" | |
-N | yt-dlp -N 4 "URL" | |
-v | yt-dlp -v "URL" | |
-U | yt-dlp -U |
6.4 配置文件的妙用
如果你有一些每次都要用的参数(比如总是想嵌入元数据、总是限制 1080p 分辨率),可以把它们写到配置文件中,避免每次手动输入。
配置文件位置:
• Linux/macOS: ~/.config/yt-dlp/config• Windows: %APPDATA%/yt-dlp/config
示例配置内容:
# 总是限制最高 1080p-f bestvideo[height<=1080]+bestaudio/best# 嵌入元数据和缩略图--embed-metadata--embed-thumbnail# 下载字幕--write-subs--sub-langs en,zh-CN--embed-subs# 输出文件名模板-o ~/Downloads/%(uploader)s/%(title)s.%(ext)s有了配置文件,日常使用时只需要输入最简短的命令:
yt-dlp "URL"所有预设的参数会自动生效。
第七章:进阶玩法——成为 yt-dlp 高手
7.1 脚本自动化
yt-dlp 的真正威力在于可以嵌入到自动化脚本中。以下是一些实用示例:
批量下载多个视频:
#!/bin/bashwhile read url; do yt-dlp "$url"done < video_list.txt监控频道自动下载新视频(配合 cron):
#!/bin/bash# 每天检查一次频道更新yt-dlp --download-archive ~/archive.txt \ -o "~/Videos/%(uploader)s/%(title)s.%(ext)s" \ "CHANNEL_URL"提取视频信息(不下载):
# 获取标题yt-dlp --get-title "URL"# 获取时长yt-dlp --get-duration "URL"# 获取所有信息(JSON 格式)yt-dlp -j "URL" | jq .7.2 Python API 调用
yt-dlp 不仅是命令行工具,还是一个 Python 库。你可以在 Python 脚本中调用它:
import yt_dlpydl_opts = { 'format': 'bestaudio/best', 'postprocessors': [{ 'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3', 'preferredquality': '192', }], 'outtmpl': '%(title)s.%(ext)s',}with yt_dlp.YoutubeDL(ydl_opts) as ydl: ydl.download(['https://www.youtube.com/watch?v=...'])这种方式特别适合集成到更大的应用程序中,或者进行更复杂的流程控制。
7.3 与 FFmpeg 的深度配合
yt-dlp 和 FFmpeg 的组合可以完成很多复杂的视频处理任务。
仅下载特定时间段(精确裁剪):
# 下载视频的 30 秒到 90 秒部分yt-dlp --external-downloader ffmpeg \ --external-downloader-args "ffmpeg_i:-ss 00:00:30 -to 00:01:30" \ "URL"下载后自动压缩视频:
yt-dlp --postprocessor-args "FFmpegVideoConvertor:-c:v libx264 -crf 23 -preset fast" \ "URL"7.4 插件系统
yt-dlp 支持加载外部的提取器和后处理器插件。这意味着即使官方版本不支持某个网站,你也可以自己编写或使用社区提供的插件来扩展功能。
插件通常放在特定的目录中:
• Linux/macOS: ~config/yt-dlp/plugins• Windows: %APPDATA%/yt-dlp/plugins
第八章:从 yt-dlp 到 OpenClaw Skill——能力的工程化
如果你已经读到这里,应该对 yt-dlp 的强大功能有了充分的认识。但接下来的问题是:如何把这样一个强大的 CLI 工具,变成 OpenClaw 能够稳定调用的能力模块?
这不仅仅是"套个壳"那么简单。真正的 Skill 化,是把命令提炼成稳定、可交付、可运营的能力。
8.1 为什么要 Skill 化?
yt-dlp 的参数很多,高手向明显。-f、--format-sort、--cookies-from-browser、--download-archive……新人一看很容易懵掉。
更重要的是:
• 输出并不天然适合自动化消费(有时视频、有时音频,stdout 一大坨日志) • 失败信息混在一起(登录态、限流、网络问题、格式问题),难以诊断 • 调用方式不稳定,换个环境就忘了参数含义
OpenClaw 的目标不是让你手搓命令,而是让 Agent、其他实例、未来的自己,都能用低心智负担反复完成同一类任务。
8.2 Skill 化的九个阶段
把 yt-dlp 封装成 yt-dlp-media Skill 的过程,大致经历了这九个阶段:
重要提示:你并不需要手动完成后面的步骤,因此这里仅总结了大致的步骤和阶段。你可以跟🦞说:
请深刻理解yt-dlp项目的repo:https://github.com/yt-dlp/yt-dlp 然后请按照这篇文章中的方法(这篇文章的链接)将yt-dlp封装为skill
第一阶段:MVP 先行不追求大全,只抓住最高频的动作:下载视频、提取音频、下载字幕、获取元数据、批量处理。先闭环,不先完美。
第二阶段:统一入口别让脚本散落各处。建立 scripts/yt_dlp.sh 作为稳定 facade:
scripts/yt_dlp.sh video --url 'https://...'scripts/yt_dlp.sh audio --url 'https://...'scripts/yt_dlp.sh subtitles --url 'https://...'外部只认这个入口,内部怎么重构都不影响调用方。
第三阶段:预设替代参数海不要暴露底层参数,而是提供 preset:
• 视频: best/balanced/mobile• 音频: audio_only
让默认行为就能跑出大多数人满意的结果。
第四阶段:把失败当成一等公民媒体下载的失败是主流程,不是边缘情况。建立错误分类:
• ERR_NO_YTDLP/ERR_NO_FFMPEG—— 环境缺失• ERR_UNSUPPORTED_URL—— URL 不支持• ERR_AUTH_REQUIRED—— 需要登录• ERR_RATE_LIMITED—— 被限流• ERR_EXTRACTOR_BROKEN—— 提取器失效
这样 Agent 才能决定下一步:重试、加 cookies、还是提示更新 yt-dlp。
第五阶段:结果结构化不只是"下载完成",而是明确产出:
RESULT:file=...RESULT:info_json=...RESULT:thumbnail=...RESULT:result_json=...让下游脚本和 Agent 都能稳定消费。
第六阶段:轻量 Job 系统下载可能持续很久,transcript 可能更久。引入基于目录状态机的 job 模型:
scripts/yt_dlp.sh job submit probe --url URLscripts/yt_dlp.sh job status <job_id>scripts/yt_dlp.sh job tail <job_id>不依赖数据库或消息队列,简单、易排障、适合 Agent 场景。
第七阶段:轻量站点画像不同站点行为不同,但不要写第二套 extractor。用 site profile 做"默认值偏置":
• YouTube / Bilibili 偏 balanced• 小红书 / X 偏 mobile• 某些站点更可能需要 cookies
第八阶段:打通完整任务链不只是"多一个参数",而是端到端的工作流。比如 transcript 流程:
1. 下载源视频(保留!) 2. 抽取音频 → mono 16kHz wav 3. 送到 ASR 服务 4. 生成 raw transcript → cleaned transcript
输出完整产物链,让用户可以回看、校对、二次整理。
第九阶段:文档即交付物真正的 Skill 不只是代码,而是 代码 + 约定 + 文档:
• SKILL.md—— 核心规则、推荐入口• setup-and-runtime.md—— 安装、依赖、环境变量• end-to-end-examples.md—— 可复制的用例• troubleshooting.md—— 典型问题排查
8.3 核心方法论
整个过程可以压缩成 8 句话:
1. 保留内核,不要重造轮子 —— yt-dlp 的 extractor 能力很强,Skill 只负责包装 2. 先做高频闭环,不先做大全 —— 解决 80% 的真实需求 3. 尽快建立统一入口 —— 外部只认稳定 facade 4. 用预设替代参数海 —— 降低使用门槛 5. 失败要分类 —— 否则无法维护和运营 6. 输出要结构化 —— 否则自动化很脆 7. 长任务要有 Job 模型 —— 别全靠前台命令 8. 文档和代码同等重要 —— 别人能不能复用,不看功能多少
8.4 OpenClaw Skill 的本质
不是把命令搬进 Agent,而是把命令提炼成能力。
OpenClaw Skill 真正有价值的地方,不是"我会调工具",而是:
• 能把复杂工具收敛成稳定入口 • 能把易碎命令变成结果清晰的能力 • 能把一次性脚本变成别人也能接手的工作流
yt-dlp 本体负责"下载能力",yt-dlp-media Skill 负责"交付能力"。这两者缺一不可。
8.5 一些真实case
• 将小某书的视频链接发给OpenClaw🦞 • 让🦞下载这条视频 • 让🦞抽取音频 • 让🦞抽取音频中的文字(需要多模态大模型,性价比最高的可能是"google/gemini-3.1-flash-lite-preview",可以通过OpenRouter调用,需要配置OpenRouter的API Key) • 要求🦞对文本进行清洗,然后进行二次加工,例如:生成思维导图、生成PPT、风格化改写、等等 • 以上所有内容通过企微“智能表格”来管理和中转 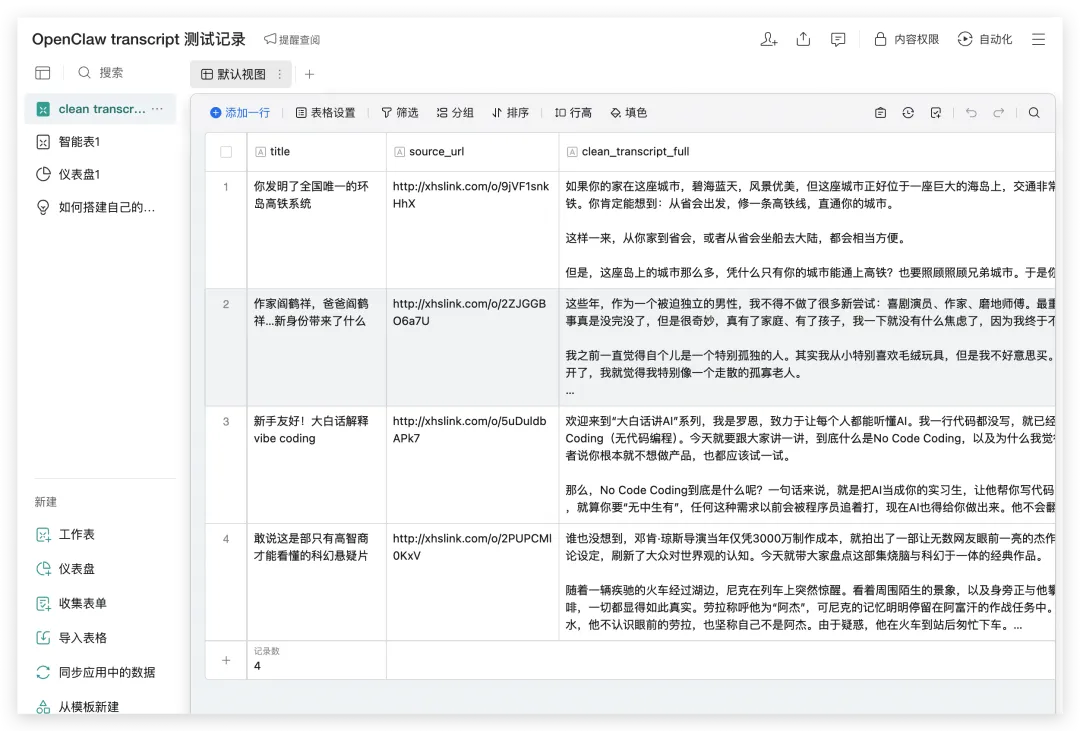
第九章:安全与合法性——使用前必须知道的事
9.1 法律风险
下载视频的合法性因国家和地区而异,也因用途而异。一般来说:
• 个人学习、研究用途:大多数国家的版权法允许为个人使用而复制受版权保护的作品 • 再次分发、商业用途:通常需要获得版权持有者的授权 • DRM 破解:绕过数字版权管理(DRM)保护在很多国家是违法的,yt-dlp 也不支持下载 DRM 保护的内容
重要原则:yt-dlp 只下载网站公开提供的内容。如果一个视频在浏览器里无需登录就能观看,yt-dlp 通常也能下载;如果需要付费订阅或特殊权限,yt-dlp 也无法绕过。
9.2 安全风险
作为一个命令行工具,yt-dlp 本身没有广告软件或恶意代码。它是开源的,代码托管在 GitHub 上,任何人都可以审计。
但需要注意以下几点:
1. 只从官方渠道下载
• 官方网站:https://github.com/yt-dlp/yt-dlp • 官方发布的可执行文件在 GitHub Releases 页面 • 不要使用来路不明的第三方下载站点
2. Cookie 安全使用 --cookies-from-browser 时,yt-dlp 会读取浏览器的 Cookie 数据。虽然 yt-dlp 不会上传或泄露这些数据,但建议只在个人电脑上使用此功能,不要在公共或共享电脑上使用。
3. 命令注入风险在极少数情况下,如果在参数中使用了不受信任的输入(比如从网页直接复制视频标题作为文件名),可能存在命令注入风险。建议对动态输入进行适当的转义或过滤。
9.3 道德准则
即使法律允许,下载视频也应该遵循一些基本的道德准则:
• 尊重创作者的劳动成果:下载的视频仅供个人使用,不要未经授权再次上传到其他地方 • 支持你喜欢的创作者:如果某个创作者的内容对你有价值,考虑通过点赞、订阅、打赏等方式支持他们 • 不要滥用:不要大规模爬取网站内容,这可能会给服务器带来负担,甚至导致 IP 被封禁
附录:相关资源
• 官方仓库:github.com/yt-dlp/yt-dlp • 官方 Wiki:github.com/yt-dlp/yt-dlp/wiki • FFmpeg 官网:ffmpeg.org • SponsorBlock:sponsor.ajay.app • 支持的网站列表:运行 yt-dlp --list-extractors查看完整列表
