 夜雨聆风
夜雨聆风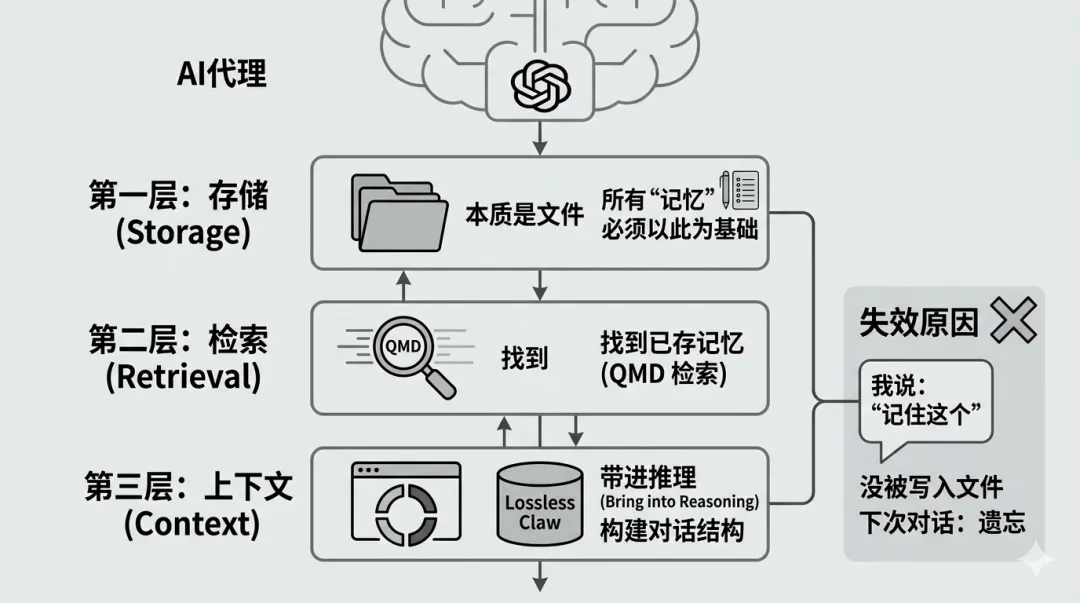
最近一个月,我给 OpenClaw 定了几十条规范。它每次都说:记住了。可是下次还是依旧照犯。一开始我以为是模型问题,结果不是。在 OpenClaw里,"记住"这件事,本身就不是默认行为。
AI 不会自动记住任何信息。只有两类信息会被保留:被写入文件,或被重新注入上下文。否则,每一轮对话,本质上都是一次新的推理。
01
问题不在"忘了",而在"从来没记住"
在 OpenClaw 里,有件事跟很多人想的不太一样:
AI 不会自动记住任何信息。
只有两类信息会被保留:
被写入文件(如 MEMORY.md) 被重新注入上下文(context)
否则:
每一轮对话,本质上都是一次新的推理。
这就是为什么你会遇到这些问题:
"记住这个" → 下次完全不记得 "这个错误别再犯" → 继续犯 "存到文件" → 实际什么都没发生
本质原因只有一个:"说过"不等于"记住"。
02
OpenClaw 的 memory,本质是三层结构
很多人把 QMD、Lossless Claw 当成"记忆系统",其实是误解。
OpenClaw 的 memory,本质可以拆成三层:
storage(存储) retrieval(检索) context(上下文)
这是整套系统最关键的认知。
1)storage:你有没有真的"写下来"
默认的 memory 其实挺朴素:就是 MEMORY.md 和各类 .md 文件。
也就是说:memory 的本质就是文件。
如果信息没有被写入这些文件,后续 100% 不会被用到。
2)retrieval:能不能"找到这些记忆"(QMD 在这里)
当 memory 变多后,问题变成:找不找得到?
默认是简单检索,而 QMD 做的是:
BM25 + 向量检索 rerank 排序
它解决的是:"有记忆,但能不能被命中"。
关键点:QMD 不是 memory,是 retrieval 引擎。
3)context:能不能"带进当前推理"(Lossless Claw 在这里)
模型有上下文窗口限制。
Lossless Claw 做的事情是:
持久化对话(SQLite) 摘要压缩 构建 DAG 结构 动态拼接上下文
它解决的是:"上下文装不下"的问题。
但关键是:它不是 memory 系统,是 context 管理系统。
一句话总结:
- QMD:帮你找到记忆
- Lossless Claw:帮你装下对话
03
为什么"答应了却没做"
很多看起来"很蠢"的行为,其实都可以用这套结构解释。
比如:
"记住这个" → 没写入 storage "下次别犯" → 没进入 retrieval "说了要存" → 根本没有执行写文件动作
在 OpenClaw 中,只有写入文件的内容,才有资格成为"记忆"。这是最重要的一条工程事实。
04
一个最小实验:三种配置到底差在哪
我做了一个很简单的实验,只验证一件事:memory 能不能被再次用到。
测试配置:
默认 memory files memory files + QMD memory files + QMD + Lossless Claw
测试方法:
第一天:写入明确规则(命名规范 + 错误约束)
第二天:新任务中观察是否遵守
结果:
最终结论:
QMD:改善"能不能找到" Lossless Claw:改善"当前对话别丢",为长期情景记忆打基础
05
一个真正可用的 memory 方案
如果你只想让 OpenClaw 稳定可用,搞复杂系统没必要:
我当前的推荐配置是:memory files + QMD
为什么是这个组合?
memory files 解决"存不存" QMD 解决"找不找得到"
已经覆盖 80% 场景。
是否需要 Lossless Claw?
暂时不需要(大多数场景)。 除非你有超长对话、多轮复杂推理链,否则它不会提升 memory 效果。
06
最重要的事
无论你用不用 QMD,都必须遵守三条规则:
- 重要信息必须写入文件
- 不要依赖"AI自己记住"
- memory 只存高价值信息
否则,再强的检索也没有意义。
OpenClaw 最大的误解在于:很多人以为它"自带记忆系统"。
它没有。它只有存储能力,没有默认的记忆能力。
如果你不主动设计 memory,Agent 是不会记住任何东西的。
从工程角度,一个可用的最小方案其实很简单:memory files + QMD,已经足够覆盖大多数真实使用场景。
至于 Lossless Claw,在绝大多数情况下,它是优化,是可选项。
AI 不会记住你说过的话,只会记住你写下来的结构。
