 夜雨聆风
夜雨聆风拆解iOS应用逆向实战中的反调试与反篡改
目录
应用如何利用iOS侧信道 应用如何自检 应用如何在附加调试器时自毁 应用如何主动破坏自己的崩溃日志 应用如何借iOS之手终止自身 应用如何持续复检 结论
这次探索既出于好奇,也带着一点便利性考量。有人想把某款游戏再“推”一步,刷出更高分;同时在红队工作中,我们也想看清银行类应用在资金处理上的幕后逻辑。目标很简单:挂上调试器、观察行为、弄清实现细节。
但过程并不总是顺利。
有些应用一启动就退出;有些应用先跑一段时间,再在没有明显原因的情况下失败;还有一些场景里,连可用的崩溃信息都没有。虽然每个应用表现不同,但样本看多后,重复出现的模式非常明显。
这些应用开发者早已不再依赖单点检测。他们会叠加多种技术,让分析更难、让修改更不稳定,即便设备并未越狱也是如此。单项技术本身并不新鲜,真正值得关注的是它们如何组合,以及它们在多早的阶段就开始生效。问题逐渐不再是“某个保护点”,而是“整套联动机制”。
下面按实战中常见的几类手法展开,说明它们在iOS应用中如何落地、如何配合。
1 应用如何利用iOS侧信道
我们分析过一款应用,它在任何核心逻辑开始前就会失败。即便没有附加调试器,也没有做任何修改,应用仍会在启动后立即退出。
后来发现,这款应用在非常早期就开始做环境检测,而且主要依赖侧信道信号,而不是显式公开接口。它调用私有系统API,再根据返回行为推断设备上是否安装了某些应用。一旦命中可疑特征,就直接终止后续流程。
一个典型案例来自银行应用:它调用了私有APISBSLaunchApplicationWithIdentifierAndURLAndLaunchOptions。调用目的并非该API的官方用途,而是把返回日志当成侧信道。通过这种方式,它可以根据com.opa334.TrollStore、org.coolstar.SileoStore、com.tigisoftware.Filza等包标识符(bundle identifier)检测常见改机工具。如果检测命中,就把设备判定为不可信并拒绝继续。
这类具体行为后来在iOS18.5中被苹果修复(CVE-2025-31207),但这种模式本身仍然非常有参考价值。
技术要点:启动前环境检查
通过系统API(含未公开接口)获取间接信号 利用API返回日志等侧信道行为检测已安装应用 依据已知工具的bundle identifier进行命中判定
2 应用如何自检
有些应用会更进一步:在执行任何有效业务前,先校验“自身是否可信”。
一种常见做法(在游戏中尤其常见)是通过csops()查询代码签名状态。特别是读取CS_OPS_ENTITLEMENTS_BLOB,可以拿到自身entitlements。若出现异常entitlements,往往意味着运行环境已被修改或不符合预期。应用据此进一步推断是否处在越狱环境。
部分应用还会先做完整性校验,再决定是否继续运行。常见手段包括对应用数据计算CRC32或MD5,以及校验已安装IPA的签名证书。类似LC_ENCRYPTION_INFO_64这样的结构也会被用来判断应用是否被重签名或被篡改。
技术要点:启动前环境检查
结合 csops()与CS_OPS_ENTITLEMENTS_BLOB检查entitlements并推断越狱状态通过 CRC32与MD5进行文件完整性校验校验证书并借助 LC_ENCRYPTION_INFO64识别重签名
3 应用如何在附加调试器时自毁
另一类模式会在你尝试附加调试器时出现:应用会立刻退出。
多数情况下,这与ptrace()的PT_DENY_ATTACH有关。设置该标志后,一旦有调试器附加,进程就会终止,常见路径是abort()或exit()。
绕过时,通常不先处理“检测逻辑”,而是先处理“终止路径”。只要应用无法完成自杀,它就会继续运行。实操里,改写执行流并绕过abort()和exit()调用,往往就足够让进程存活,从而继续做运行时分析。
当PT_DENY_ATTACH被直接使用时,也有成熟方法可以修改或屏蔽其行为,让调试器能够附加。相关思路已有公开资料,例如Bryce Bostwick的文章:Undebuggable,其中详细说明了在iOS上处理ptrace()的过程。
技术要点:运行时反调试(ptrace())
调用 ptrace(PT_DENY_ATTACH)阻断调试器附加在检测到调试行为后触发进程终止
4 应用如何主动破坏自己的崩溃日志
有些应用不只会退出,还会确保你几乎无法从崩溃里学到任何东西。
我们遇到过一个样本:正常运行时看起来没问题,一旦开始调试,崩溃日志就失去价值。寄存器被写成同一个明显不可能的值,回溯也不再指向有效上下文。
进一步分析后发现,应用会在崩溃前主动向CPU寄存器写入垃圾值。某个案例里,所有寄存器都被设置为0x123456789a00。崩溃仍然会发生,但现场状态已不可信,几乎没有可提取信息。
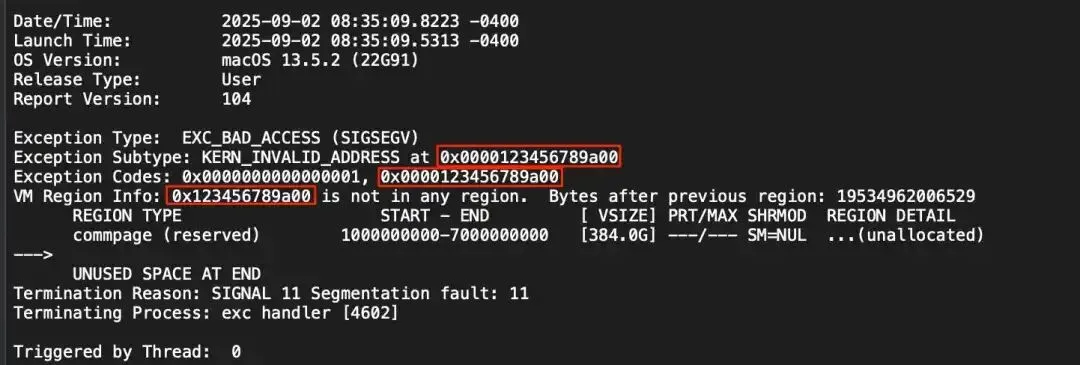
图注:该iOS应用在macOS上运行时,会在崩溃前污染寄存器。
这种做法会显著增加定位难度。即便你命中了正确代码路径,最终拿到的崩溃现场也已被污染。
它并不能彻底阻止调试,但会拖慢分析效率:你必须在崩溃前找到检测点,而不能再依赖崩溃现场反推。
技术要点:通过寄存器污染提升分析阻力
在崩溃前覆盖寄存器状态 让崩溃日志呈现无意义寄存器值 混淆检测逻辑触发源并破坏回溯可读性
5 应用如何借iOS之手终止自身
有一款游戏样本出现了我们见过最“奇怪”的崩溃形式:应用可以正常运行,但一旦开始调试就会被系统直接终止,而且没有常规崩溃日志。
原因是内存压力策略。它不通过abort()或越界访问直接崩溃,而是把内存占用推高到足以触发jetsam。对iOS来说,jetsam是内核层面的内存回收机制:系统内存紧张或进程超限时,内核会直接终止进程。
由于终止由系统执行,不会产生常规应用崩溃日志。你通常只能看到jetsam记录,而反调试检测逻辑不会出现在可用回溯中。
在该案例中,这一行为还与越狱检测、追踪检测等手段叠加,导致“沿着崩溃回溯定位检测点”这条常规路径几乎失效。
技术要点:通过资源耗尽触发jetsam
申请过量内存以强制触发系统级终止 避免生成应用层崩溃日志 仅留下系统层jetsam记录
6 应用如何持续复检
有些应用能通过初始检测,但仍会在后续阶段失败。
这类样本的共同点是:检测逻辑并未结束,而是在后台持续运行,并通过延迟机制执行惩罚。一次检测失败后,应用可能先记录状态,过一段时间再终止。这个延迟会切断“触发点和崩溃点”的直接关联。
通常还会有周期任务充当心跳。它按固定间隔唤醒并重复执行部分检测逻辑,因此“启动时通过一次”并不代表后续安全。
这种设计会让行为变得不稳定且难以预测。失败可能在很晚阶段才出现,而且很难从表象直接反推出触发原因。
技术要点:持续检测与延迟执行
记录篡改状态并在延迟后触发崩溃 通过定时器解耦检测与执行 使用周期心跳任务重复检查运行状态 即便通过初始检查,也可再次触发终止
结论
把这些样本放在一起看,变化趋势很清晰。过去常见的是单点检测,或一次ptrace()调用;现在更常见的是多层组合:早期做环境判断,运行时做调试器拦截,崩溃日志被主动破坏,甚至通过jetsam让日志彻底消失;再叠加完整性校验与延迟执行,整条保护链路会在应用启动后持续生效。
每个单项技术都不算特别复杂,真正的难点在组合方式。你面对的不是某一个机制,而是一套彼此补位的系统。
如果你熟悉Windows上的保护体系(反作弊、反调试、反篡改等),可能会问:为什么不直接采用更激进的内核驱动或代码注入方案?答案在于iOS的安全模型不同:它不允许内核扩展,也不允许未签名代码执行。
