 夜雨聆风
夜雨聆风最近 OpenClaw 的画风很有意思,一边是“这玩意儿太能干了”,一边是“先别装,容易出事”。连公开报道里都已经出现了因安全风险而劝工作人员不要在工作设备上安装的情况。这个反差不难理解,因为 OpenClaw 不是普通聊天机器人,它本质上是在把模型、聊天入口、工具调用、浏览器控制、文件系统和外部账号,硬生生拧成一个能下场办事的代理系统。能力一上来,攻击面也跟着上来。

把它翻成人话,OpenClaw 的核心做法其实很直接:先放一个长期运行的 Gateway 当总中枢,所有消息入口都先接到这里。官方文档写得很明白,一个 Gateway 会统一接管 WhatsApp、Telegram、Slack、Discord、Signal、iMessage 这些消息面;控制端客户端,比如 macOS app、CLI、Web UI、自动化模块,会通过 WebSocket 连到 Gateway,默认绑定在 127.0.0.1:18789;iOS、Android 或无头节点也会以 node 身份接进来,并声明自己的能力和允许执行的命令。说白了,Gateway 就像总机房,外面所有消息先汇进来,里面所有动作再从这里发出去。)
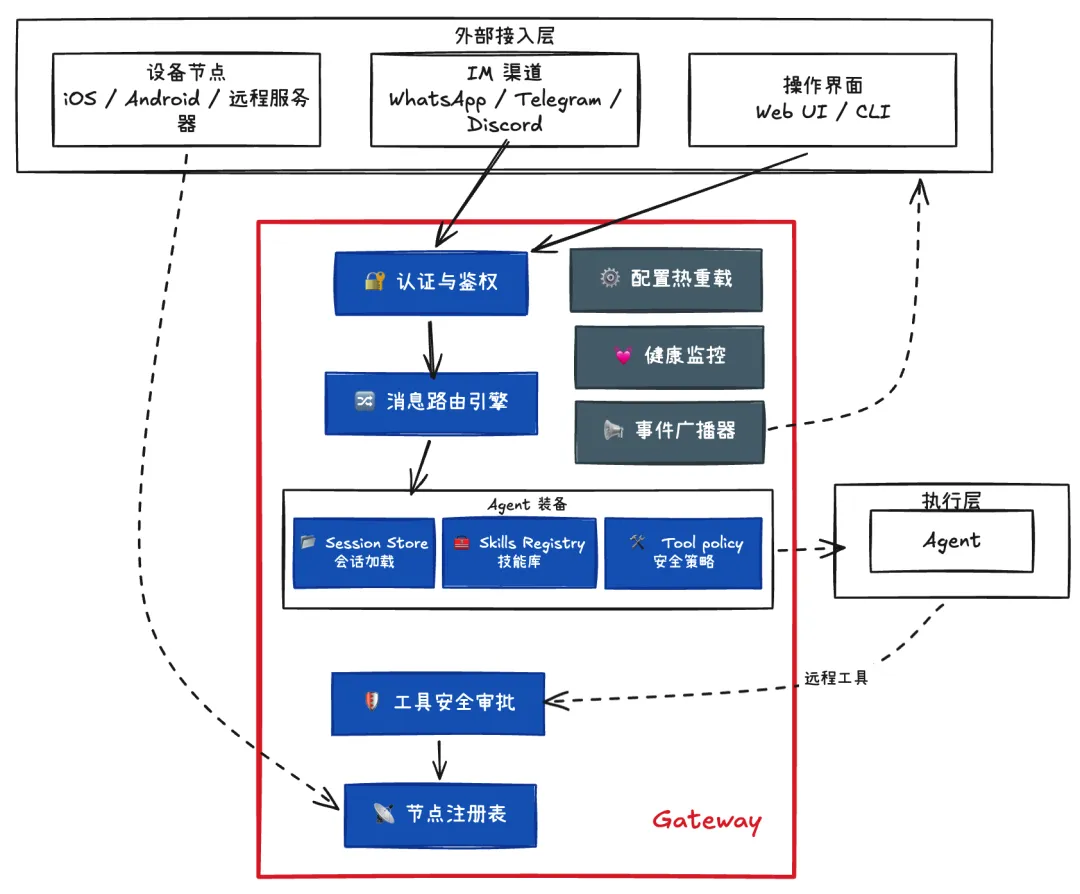
再往下一层,OpenClaw 不是把模型当成一个远程接口随便调一下就完了,它是把一个 AI agent 运行时直接嵌进自己的架构里。官方文档提到,它直接通过 pi SDK 去实例化 AgentSession,而不是简单起个子进程或者走 RPC。这么做的好处很现实:会话生命周期更好控,工具可以按它自己的体系注入,系统提示词可以按不同频道和场景定制,会话还能做持久化、压缩、分支,模型供应商也可以切换。你可以把这理解成,OpenClaw 不是“接了个大模型”,而是“围绕大模型搭了一个完整的执行壳”。
这个执行壳的第二个关键点,是 agent 不是一团抽象上下文,而是有工作目录、有状态目录、有会话存储的。官方文档里,一个 agent 会有自己的 workspace、自己的 agentDir、自己的会话存储路径;多 agent 可以并排跑,但凭据和状态默认不自动共享。记忆也是很朴素的思路,不是神神叨叨的“它天生会记住你”,而是写进 workspace 里的 Markdown 文件。这个设计很工程,也很危险:因为一旦 workspace、agentDir、auth profile 和工具权限绑在一起,agent 就不再只是“会说话”,而是开始拥有操作环境。
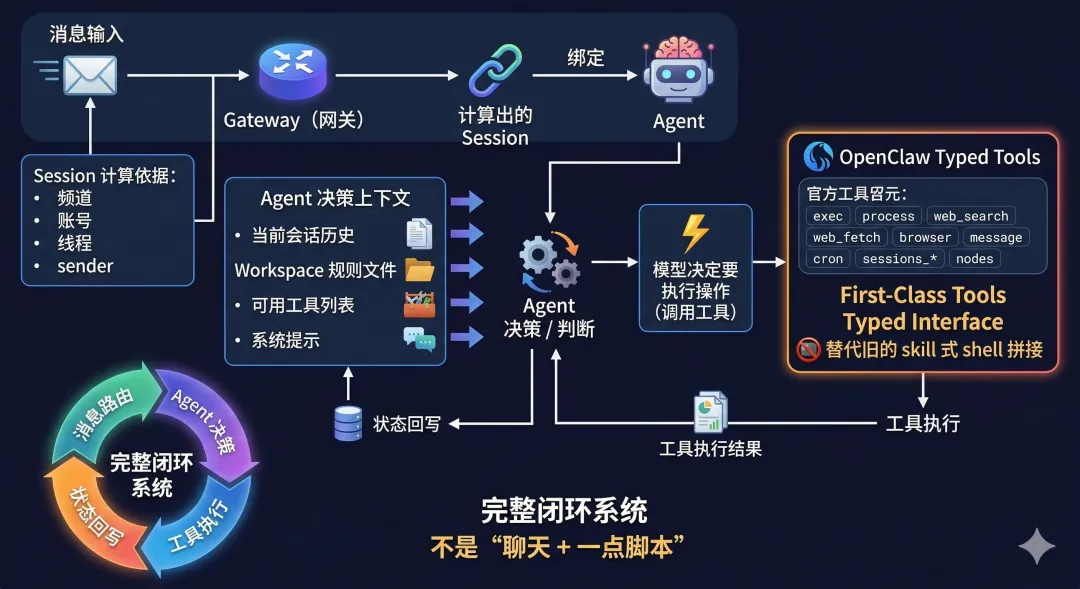
消息进来之后,大概会走这样一条链:先由 Gateway 根据频道、账号、线程和 sender 去算应该落到哪个 session;再把这个 session 绑定到某个 agent;然后 agent 拿着当前会话历史、workspace 里的规则文件、可用工具列表和系统提示开始做判断;如果模型决定要查网页、开浏览器、发消息、写文件、跑命令、调节点,它就不是乱输出一段文字,而是去调用 OpenClaw 的 typed tools。官方工具列表里直接包括 exec、process、web_search、web_fetch、browser、message、cron、sessions_*、nodes 这些。它甚至特地强调,新的工具是 first-class tools,用 typed interface 替代旧的 skill 式 shell 拼接。也就是说,这套系统不是“聊天 + 一点脚本”,而是“消息路由 + agent 决策 + 工具执行 + 状态回写”的闭环。
插件和技能系统又把这套架构往外扩了一层。OpenClaw 的插件是 manifest-first 的四层结构:先发现候选插件,再做启用和校验,再通过 jiti 进程内加载,最后把工具、频道、命令、HTTP 路由和服务暴露给整个平台。ClawHub 则是公开技能市场,技能的基本形态就是一个带 SKILL.md 的文件夹,用户可以搜索、下载、安装、更新、发布。这个设计的优点也很明显:扩展快,门槛低,社区生长极快。问题也很明显:门槛低到一定程度,供应链风险会像杂草一样冒出来。
它之所以让很多人上头,也就在这里。你发一句话给 Telegram 里的 bot,它背后不是只回一句“好的”,而是可能已经自己做了 session 路由、读了历史、看了 workspace 规则、挑了模型、调了网页搜索、开了浏览器、改了文件、再把结果发回你原来的聊天软件。这种体验很像请了个随叫随到的远程助理,甚至比助理还快。官方首页自己也把这个定位说得很直白:一个自托管、多频道、agent-native 的 personal AI assistant。
问题也正是从这里开始的。因为传统聊天模型最大的风险,很多时候只是“胡说八道”;而 OpenClaw 这种 agent 平台的风险,是“胡说八道以后真的去干了”。官方安全文档自己都写得很清楚:这个安全模型默认是假设一个受信任操作边界对应一个 Gateway,它不是给互相不信任的人共用一个 agent/gateway 当多租户安全边界的;如果多个人能给同一个有工具权限的 agent 发消息,那实际上他们共享的是同一套“被委托的工具权限”。这句话翻译一下就是:你以为你只是让更多人能跟 bot 聊天,实际上你是把同一把能开门、能发消息、能跑命令的钥匙交给更多人碰。
提示词注入在这种系统里也不是一个很抽象的论文词,而是实打实的攻击入口。官方 threat model 里直接把几条链路写出来了:一种是让 agent 通过 web_fetch 把敏感数据发到外部 URL;一种是诱导 agent 用消息工具把信息发给攻击者;还有一种是把恶意内容塞进外部网页或 API,等 agent 合法地去抓取,再把里面夹带的指令当正经命令执行。官方自己给的短期建议里就包括 URL allowlist、敏感动作输出校验、以及对新收件人的显式确认。换句话说,OpenClaw 自己已经承认,这类系统的风险不是“模型瞎想”,而是不可信内容进入执行闭环。
浏览器这块尤其典型。官方浏览器文档明写着,browser act kind=evaluate 和 wait --fn 会在页面上下文里执行任意 JavaScript,而且“prompt injection can steer this”,也就是提示词注入可以把它往危险方向带。如果这个浏览器 profile 里本来就有登录态,那风险就不是“帮你看个页面”这么简单了,而是“拿着你的会话去网页里做动作”。这也是为什么 agent 浏览器一旦和真实账号、真实 Cookie、真实支付或管理后台连起来,攻击面会瞬间陡增。
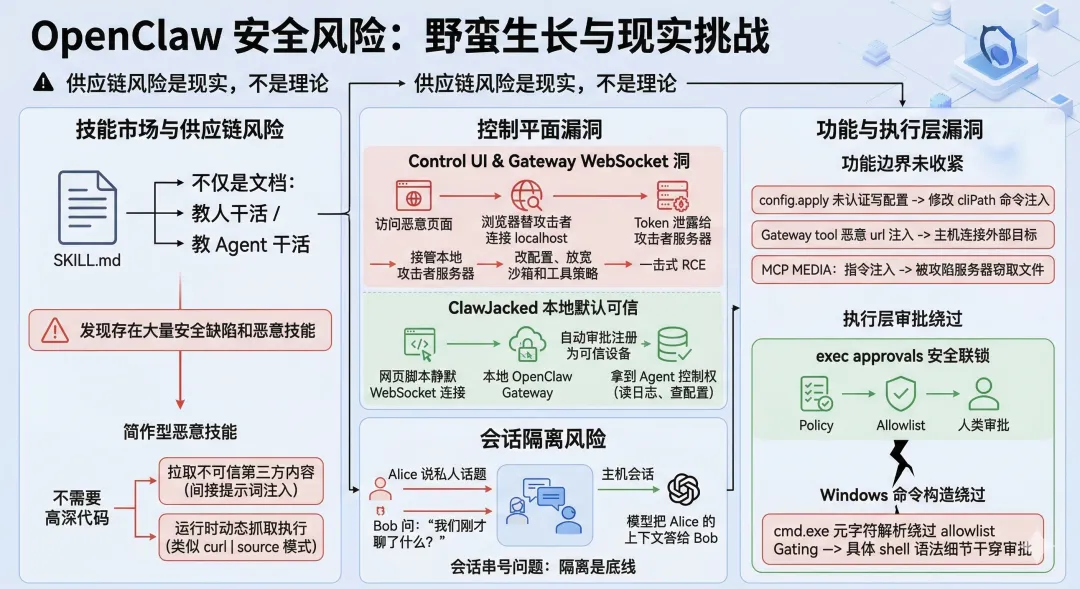
技能市场的风险则更像 AI 版的应用商店早期,但更野。因为在 agent 生态里,SKILL.md 不只是文档,它往往同时在教人和教 agent 怎么干活。Snyk 对 3,984 个技能样本的扫描发现,13.4% 存在 critical 级问题,36.82% 至少有一种安全缺陷,而且确认到了 76 个带有恶意载荷的样本;另一批研究则在 ClawHub 上发现了 341 个恶意技能,或者在 3,505 个技能里识别出 71 个恶意样本。不同团队、不同时间窗的数字不完全一致,但方向非常一致:这个技能生态的供应链风险不是理论风险,是已经长出来的现实风险。
更麻烦的是,很多恶意技能根本不需要“高深代码”。Snyk 的研究专门提到,17.7% 的 ClawHub 技能会拉取不可信第三方内容,这会形成间接提示词注入;2.9% 的技能会在运行时动态抓远端内容并执行,类似 curl https://... | source 这种模式。到了这里,问题已经不是“这个插件代码写得糟不糟”,而是“发布时看起来干净,运行时可以从外部把真正的攻击逻辑拉回来”。这就是 agent 世界里最恶心的一点:自然语言、远程内容和执行权限,是可以串起来的。
控制平面本身也出过一串很不体面的洞。比较出名的一类,是 Control UI 和 Gateway WebSocket 这一层。GitHub 安全公告里有过一个高危问题:Control UI 会信任 query string 里的 gatewayUrl 并自动连接,连接时还会把存储的 gateway token 发过去;结果就是,点一个特制链接或者访问一个恶意页面,token 就能被送去攻击者的服务器,后者再用这个 token 接管本地 gateway,改配置、放宽沙箱和工具策略、最后做到一击式 RCE。这个洞最扎心的地方在于,就算你的 gateway 只绑在 loopback,依旧挡不住,因为浏览器替攻击者完成了那次“从你机器往外打”的连接。
最近披露的 ClawJacked 也是同一路数,只是更像把“本地默认可信”这个假设狠狠干碎了。Oasis 的披露里写得很明白:浏览器本身允许网页脚本对 localhost 发起 WebSocket 连接,而旧版 OpenClaw 又存在本地配对自动批准之类的信任捷径,于是用户只要打开恶意网页,脚本就可能静默连上本地 OpenClaw gateway,注册成可信设备,随后拿到 agent 控制权,去读日志、查配置、枚举设备。官方给出的修复建议是升级到 2026.2.25 及以上。这个洞非常有代表性,因为它说明 OpenClaw 的很多风险并不是“黑客突破了什么高墙”,而是系统默认把 localhost 当自己人,但浏览器不这么想。
还有一些洞就更像典型的“功能长太快,边界没收紧”。比如 config.apply 曾经允许未认证的本地客户端通过 Gateway WebSocket 写配置,进一步把 cliPath 之类的东西改成危险值,最后做到命令注入;比如 Gateway tool 曾经允许工具侧提供任意 gatewayUrl,从而让 OpenClaw 主机去尝试连用户指定的 WebSocket 目标;再比如 MCP tool result 曾出现过 MEDIA: 指令注入,恶意或被攻陷的 MCP server 可以借此把本地任意文件带出去。你会发现,这些洞的共同点不是“模型突然变坏”,而是控制平面、工具层和外部扩展层之间,太多地方默认彼此信任。
执行层也没少出事。官方的 exec approvals 文档本来把这套东西描述成“安全联锁”,意思是 policy、allowlist 和可选的人类审批三者都同意,命令才能落到真实主机上。但 GitHub Advisory 里后来又披露了 Windows 节点的 cmd.exe 解析绕过问题:由于 allowlist/approval gating 没有真正建模 Windows cmd.exe 的元字符行为,构造过的命令字符串可以让 cmd.exe 额外解释出允许名单之外的操作。这个问题很说明本质:字符串级审批看起来很像安全,实际上很容易被具体 shell 的语法细节狠狠干穿。
甚至连“会不会串号”这种看起来很基础的事,OpenClaw 也得靠配置兜。官方 session 文档明确警告,默认 dmScope: "main" 时,所有私聊可能共享同一个主会话;它甚至举了 Alice 说私人话题,Bob 再来问“我们刚才聊了什么”,模型可能把 Alice 的上下文答给 Bob 的例子。后面虽然文档推荐多用户时改成 per-channel-peer,CLI onboarding 也会写这个值,但它依然暴露出一个事实:在 agent 系统里,会话隔离不是锦上添花,是底线。
如果把这套架构里最值得改的地方摆到桌面上,我觉得有六个点最关键。下面这个“难度”是按现有公开架构做的工程判断,不是官方承诺。
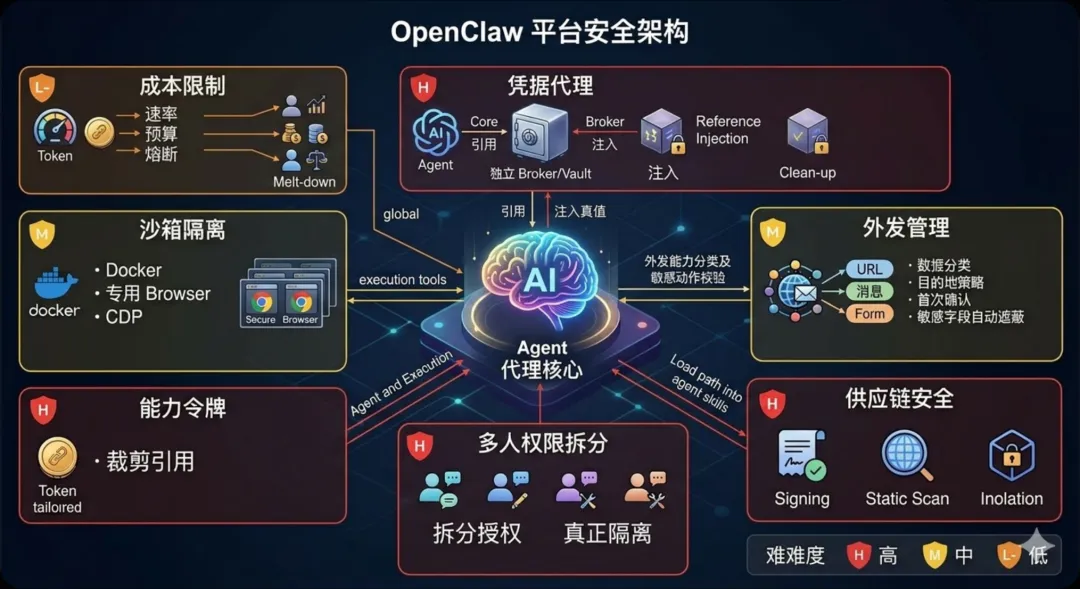
把沙箱从“可选项”改成真正的默认项。难度:中。官方 threat model 已经把“默认启用 sandbox、改进 exec approval UX”列进建议,文档也承认不启用 sandbox 时,host execution 的剩余风险是 critical。现在 OpenClaw 虽然支持 Docker sandbox、专用 browser network、CDP source range、短期 noVNC token 等机制,但默认模式仍然允许
off或non-main,而且安装链路里如果 sandbox setup 失败还可能回落为关闭。把默认改成更强隔离,收益很直接;难点主要在 Docker 依赖、浏览器调试、文件挂载和用户体验。做“agent 看不见秘密值”的凭据代理,也就是 credential broker。难度:高。这个方向其实官方社区已经有人提出 RFC (Request for Comments)了:让 agent 只知道凭据引用,不知道凭据明文,由独立 broker 在执行时注入真实值。RFC 里还明确写了当前问题:凭据以明文形式存在
auth-profiles.json,agent 会看到这些值,config.get、环境变量、shell 输出都可能让秘密进入 transcript (副本)。这个改动一旦做好,能极大缩小提示词注入和上下文泄露的爆炸半径;但它牵涉 tool schema、vault backend、运行时 broker、2FA、迁移旧配置,明显不是修个小 bug 能搞定的。把外发能力从“能发就发”改成“分类后再发”。难度:中。官方 threat model 已经分别把
web_fetch外传、消息工具外发和敏感动作校验列成问题和建议:web_fetch目前主要靠 SSRF block (服务器端请求伪造拦截器),外部 URL 仍然允许;消息外发的 gating 也被官方自己标成“可能被绕过”;对新收件人显式确认是建议项。我的判断是,真正该上的不是单一开关,而是“数据分类 + 目的地策略 + 首次外发确认 + 敏感字段自动遮蔽”这一整套。好处是收益大、模型无感;难点是要把 URL、消息、浏览器提交表单这些出口统一起来。把技能生态从“公开仓库”升级成“带签名和隔离的供应链”。难度:高。现在 ClawHub 是公开技能市场,技能本体又是一个
SKILL.md为中心的 bundle。Snyk 的研究说明,这类技能继承了 agent 的 shell、文件系统、凭据、消息和持久记忆权限;官方 threat model 也把 skill sandboxing 放进了 P0 建议。我的判断是,最合理的升级路径应该是:发布签名、可复现 bundle、静态扫描、远端内容抓取限制、风险分级、以及按技能粒度的执行隔离。问题在于,这会明显拉高技能发布和运行成本,和 OpenClaw 现在这套“门槛低、长得快”的社区节奏天然有冲突。把“多人可聊”与“多人共权”彻底拆开。难度:高。官方已经明确说了,它不是 hostile multi-tenant security boundary;共享 DM (私信) 时还要专门开 secure DM mode。不难看出,现阶段 OpenClaw 更像“单一信任边界下的个人代理”,不是“多人混用的安全总线”。所以真正的大改方向,不是继续用文档提醒用户小心,而是做真正的会话、工具、凭据、工作区和审计隔离,把“谁能聊天”和“谁能驱动工具”拆成两层授权。这个事技术上能做,但会把整个平台从个人助理架构推向更重的企业代理架构,代价很高。
加成本预算、频率限制和任务熔断。难度:低到中。这点反而最像“该早点补的课”。官方 threat model 里直接写了,针对资源耗尽这条,当前缓解是 none,建议是 per-sender rate limits 和 cost budgets。这个改动比前面几项小得多,但收益非常现实:既挡恶意刷,也挡“模型自己想多了把 token 烧穿”。对 agent 系统来说,稳定性预算和安全预算,本来就是一回事。
把 browser / exec 的“字符串权限”升级成“能力令牌”。难度:高。官方社区的安全加固路线图里已经提过 Browser Path Sanitization、Subagent Session Isolation (浏览器路径清理、子代理会话隔离)这些方向,本质就是不要让 agent 拿到原始路径和过宽的主机执行能力,而是拿到被裁剪过的能力引用。我的判断是,这才是长远上最对路的做法:不是问“这个命令像不像危险命令”,而是让 agent 根本没有机会接触太宽的资源地址空间。难点也显而易见,要改的不只是一个 tool,而是整套资源访问模型。
如果你问我,OpenClaw 真正的技术魅力在哪,我会说不是“它会自动化”,而是它把 agent 的几块关键积木真拼起来了:消息路由、状态持久化、工具调用、节点扩展、浏览器控制、技能生态、自托管入口,这些不是随便套个壳就能顺起来的。可如果你再问我,为什么它刚火就一路刷安全新闻,我也会说答案其实一模一样:正因为这些积木拼起来了,模型才真的拿到了“手、脚、眼睛、钱包和通讯录”。到这一步,提示词注入就不再只是把模型带偏一点点,而可能是把一个会动手的系统整条执行链路带偏。
所以对 OpenClaw 最准确的评价,可能不是“它安不安全”,而是“它已经把 agent 时代最核心的矛盾暴露得很完整了”:你越想让它像助理,它就越像一个高权限操作员;你越给它真实世界接口,安全边界就越不能靠“别乱来”这种朴素愿望来维持。OpenClaw 值得看,不是因为它完美,而是因为它把下一代智能系统最棘手的问题提前摆上了桌。
