 夜雨聆风
夜雨聆风- 掌握优化器卸载机制:将内存密集的逐元素操作移至SmartSSD,释放HBM显存,提升大模型Batch Size,降低GPU成本。
- 理解异步检查点+CXL tiering:用内存级缓冲隔离I/O瓶颈,避免DRAM OOM,实现GPU MFU最大化,对行业TCO分析至关重要。
- 洞察精度压缩趋势:FP8计算+FP16状态存储,Checkpoint数据量减半,指导QLC SSD等高密度介质选型与耐久优化。
- 预见硬件翻身:存算一体绕过厚重软件栈(如POSIX/DAOS),为证券分析师提供并购与生态投资信号。
在万亿参数LLM训练时代,检查点机制已成为刚需:它不仅保障高可用性,还支持模型迭代,但海量参数与优化器状态(动量、方差)导致单次TB级I/O洪峰和高频写入,严重挤占GPU算力(MFU暴跌)。传统架构下,PCIe瓶颈、DRAM溢出风险让存储成“罪魁祸首”。SK Hynix的方案直击痛点:优化器卸载至存算一体SSD,实现“零开销”检查点;异步DRAM缓冲+CXL内存扩展,动态冷热分层;混合精度压缩对冲容量爆炸。你是否好奇,PCIe带宽真能支撑梯度双向传输?存算一体能否颠覆DAOS等并行文件系统?这些前沿解法,正重塑AI基础设施,值得存储从业者深挖。
👉 划线高亮 观点批注
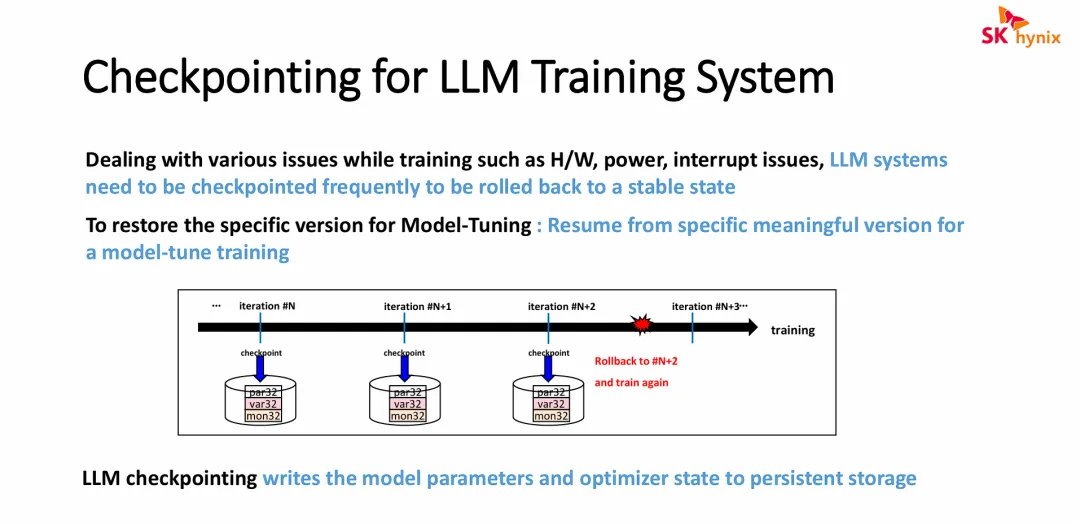
幻灯片的核心旨在阐述 大语言模型(LLM)训练过程中“检查点(Checkpointing)”机制的必要性、工作原理及其对底层存储的依赖。
高可用性与容灾需求:LLM 训练极其耗时且耗费资源,面临硬件故障或断电等风险。检查点机制通过定期保存训练状态,使得系统在崩溃后能迅速从最近的稳定点(如故障前的 iterationN+2)恢复训练,避免从头重头开始,极大减少了算力浪费。
支持模型迭代与微调:保存的检查点不仅用于故障恢复,还可以作为历史版本库,供研发人员提取特定阶段的模型进行微调(Fine-tuning)。
对持久化存储的重度依赖:系统需要将海量的“模型参数”和“优化器状态”(即图中的 par32, var32, mon32)定期、高频地写入持久化存储中,这直接凸显了在 LLM 基础架构中,高性能、大容量存储底座(这是SK海力士等存储厂商关注的核心场景)的关键作用。

幻灯片清晰地剖析了存储架构在支撑大语言模型(LLM)训练时面临的两座“大山”——“单次写入量极大”与“写入频率极高”:
海量单次 I/O 压力(容量与带宽挑战):随着模型迈入千亿甚至万亿参数时代,由于不仅需要保存模型本身的权重,还要保存庞大的优化器状态,单次生成的检查点数据量已达数 TB 甚至十数 TB 级别。这会产生极大的瞬间 I/O 洪峰,极易造成网络和存储底座的拥塞。
极高频的系统开销(性能与容量挑战):由于 AI 算力集群(特别是大规模 GPU 集群)的不稳定性,为了防止训练中断导致前功尽弃,系统被迫提高检查点的保存频率(甚至达到每次迭代都保存)。这种高频的 TB 级数据转储会严重挤占实际用于计算的时间,导致整体训练性能(Goodput)下降,并快速消耗存储空间。
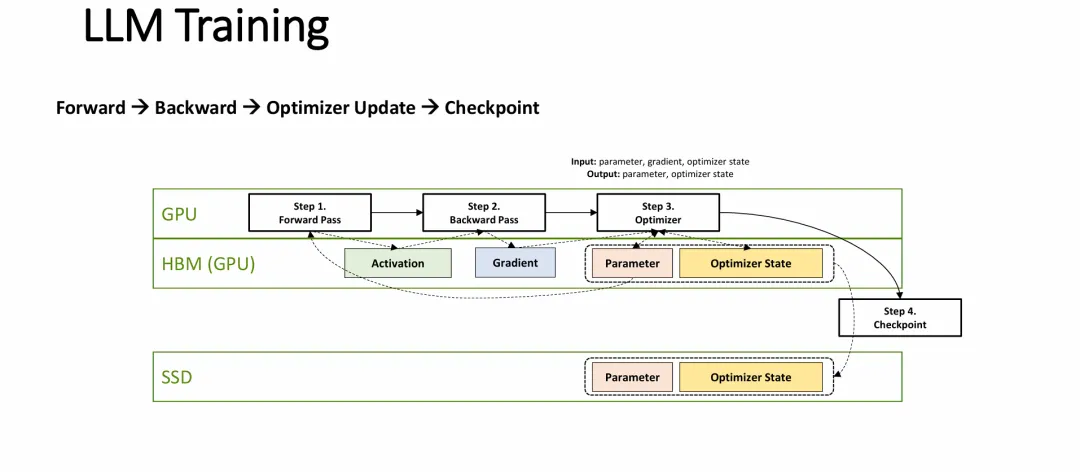
幻灯片的核心目的是从存储和数据流的视角拆解大语言模型的训练生命周期,清晰地界定了哪些数据是“易失性”的,哪些数据是需要“持久化”的。
数据分级与存储位置:在 GPU 进行高强度计算(前向/反向传播、优化)时,产生的所有数据(激活值、梯度、参数、优化器状态)都驻留在速度极快但容量有限且易失的 HBM(GPU显存)中。
检查点(Checkpoint)的物理实质:图表清晰地指出,保存检查点(Step 4)的实质动作,就是将 HBM 中的
Parameter(模型参数)和Optimizer State(优化器状态)这两类核心数据,跨越硬件总线,完整地搬移并写入到底层的持久化存储设备(SSD)中。I/O 边界的界定:训练过程中的中间变量(如
Activation和Gradient)仅参与 GPU 和 HBM 之间的内部循环,并不写入 SSD;而真正给底层存储介质(如 SSD)带来巨大 I/O 压力的,正是定期发生的Parameter与Optimizer State的下盘操作。这为理解存储系统在 LLM 训练中的具体作用和瓶颈提供了技术依据。
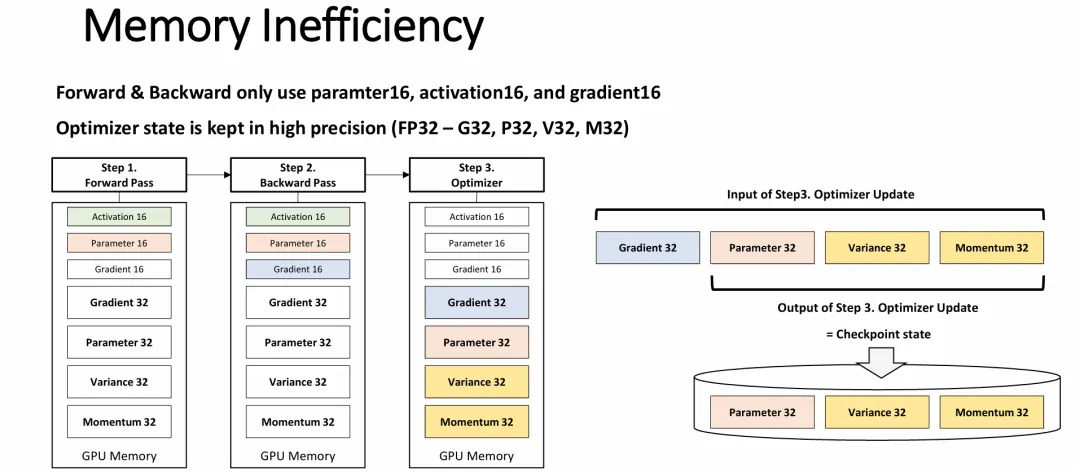
图片从技术底层揭示了大语言模型(LLM)训练中采用混合精度训练(Mixed Precision Training)带来的“内存/存储低效”现象,并解释了为什么检查点文件会如此庞大。
计算与存储的精度错位:为了提升计算速度并节省部分显存带宽,现代 LLM 训练在前向/反向传播计算时采用 16位低精度(FP16/BF16)。然而,为了保证模型收敛的精度,优化器阶段(如 Adam 优化器)必须保留 32位(FP32)的参数副本以及动量、方差等完整的优化器状态。
庞大的高精度“静默”开销:在整个计算周期的大部分时间(Step 1 和 Step 2)里,这些庞大的 32位高精度数据块在 GPU 显存中处于闲置状态,造成了极大的内存占用(Memory Inefficiency)。
检查点落盘的实质负担:图片右侧明确界定,最终需要作为 Checkpoint 落盘保存到持久化存储中的,正是这些体积庞大、未经压缩的 32位高精度数据(参数、方差、动量)。这从根本上解释了存储系统在应对 LLM 检查点时,面临的极端容量压力和 I/O 带宽挑战的技术成因。
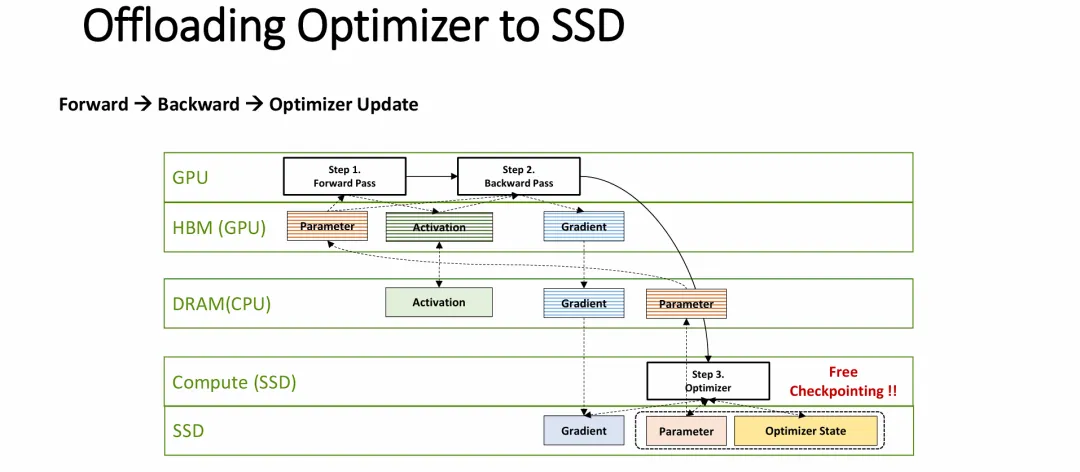
图片展示的是一种极其前沿的 “存算一体(Computational Storage)”或“近数据计算(Near-Data Processing)”在 AI 训练场景中的架构级应用,旨在彻底解决 LLM 训练中的显存墙和 I/O 瓶颈问题。
优化器卸载(Optimizer Offloading):该架构将消耗大量内存且计算模式相对固定(如逐元素操作)的“优化器更新”步骤,从昂贵的 GPU 转移到了具备计算能力的 SSD(如 SmartSSD)上。GPU 被完全解放,仅需专注处理计算密集型的前向和反向传播矩阵运算。
消除 PCIe I/O 洪峰:在传统架构中,保存检查点需要将庞大的参数和优化器状态从 GPU HBM 经过 PCIe 总线倾泻到 SSD,造成严重的网络和系统拥塞。
实现“零开销”检查点(Free Checkpointing):这是该架构最大的亮点。因为优化器本身就在 SSD 内部的计算单元上运行,计算完成时,高精度的参数和优化器状态(P32, V32, M32)自然而然地就已经驻留在持久化存储介质中了。因此,系统不再需要专门停止训练去执行耗时的“保存检查点”动作(I/O开销降为零),完美应对了极大且高频的 LLM 检查点保存需求。
留意这里提及的优化器卸载到SSD,让我想起前几天整理的Cerabras 片上大SRAM的硬件设计方案,Cerabras 提出指令流的概念,旨在将片上系统的计算后的参数,通过指令流卸载到解耦的Memory X上做隔离,降低片上高带宽显存的需求,其设计理念和SK Hynix在此处提出的smart SSD是非常类似的,核心都是把模型训练分模块进行卸载
===
经典的 PCIe 带宽(如 PCIe Gen4 甚至 Gen5)很难直接、无缝地满足这种高频传输的极高带宽需求,这正是该架构面临的最大物理瓶颈。
可以对比一下数据:
带宽鸿沟:现代 GPU 的内部 HBM 带宽极高(例如 NVIDIA H100 的 HBM3 带宽高达 3 TB/s 以上),优化器如果在 GPU 内执行,读写都是 TB 级别的极速。而经典的 PCIe 4.0 x16 双向带宽仅为 ~64 GB/s,PCIe 5.0 x16 约为 ~128 GB/s。两者之间存在 1 到 2 个数量级的巨大性能鸿沟。
时间延迟:假设一个大模型单次迭代产生 100 GB 的梯度数据,通过 PCIe Gen4 传到 SSD 需要近 3 秒,SSD 算完再把参数传回 GPU 又需要几秒。如果让昂贵的 GPU 停下来干等这个 I/O 过程,整体训练的利用率(MFU)会暴跌,这是无法接受的。
行业如何缓解这个 PCIe 带宽瓶颈?
为了让这种“卸载到 SSD”的方案具有现实可行性,业内(如微软的 DeepSpeed ZeRO-Offload 及其后续衍生技术)通常会采用以下策略来“掩盖” PCIe 带宽的不足:
计算与通信重叠(Pipelining / Overlapping):这是最核心的手段。系统不会等整个反向传播全部做完才开始传数据。当 GPU 算出第 层的梯度时,立刻启动 DMA 通过 PCIe 将其异步发送给 SSD;同时,GPU 不停机,继续计算第 层的梯度。通过流水线设计,把 PCIe 传输的延迟“隐藏”在 GPU 的计算时间里。
降低传输精度:确保在 PCIe 上传输的永远是 16位(甚至 8位压缩后)的梯度和参数,绝对不把 32位的高精度状态(如方差、动量)搬上 PCIe,让它们永远“烂机在 SSD 肚子里”。
拥抱新一代互联总线(如 CXL):相比传统 PCIe,CXL(Compute Express Link)提供了更好的内存一致性(Cache Coherency)和更低的延迟,更适合这种 CPU/GPU 与存储设备之间细粒度的高频数据交换。
GPUDirect Storage (GDS):尝试绕过 CPU DRAM 这个中间商,让 GPU 的显存直接与 SSD 的 NVMe 控制器进行点对点的数据搬移,减少数据拷贝带来的延迟和 CPU 占用。
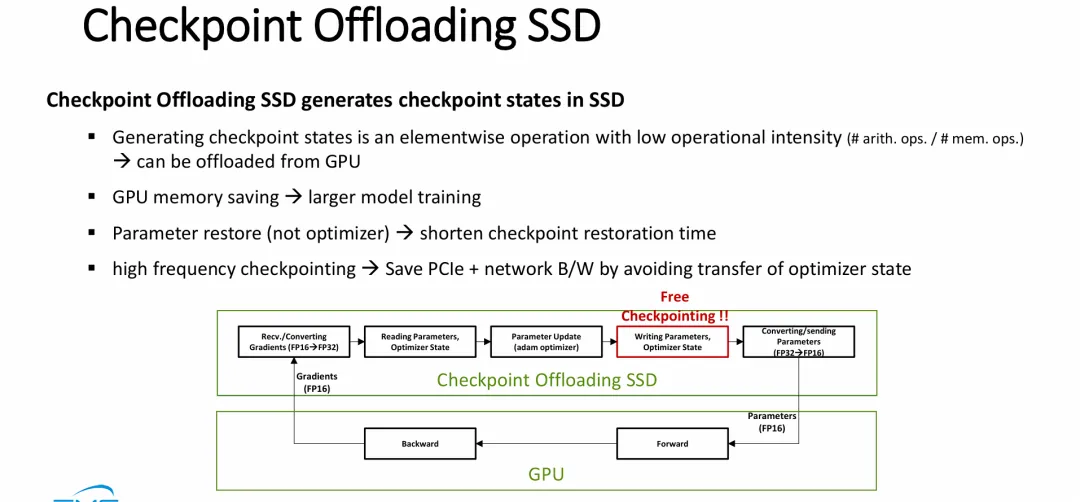
图片作为前序技术架构的深度展开,从底层数据流和算力特性的角度,完美解答了“存算一体/优化器卸载”架构如何克服传统物理瓶颈的技术细节。
理论自洽(为何能卸载):幻灯片一针见血地指出,优化器更新属于“内存密集型、低算力要求”的逐元素操作(Elementwise operation)。这种特性在 GPU 上运行是大材小用且低效的,反而完美契合具有高内部并发带宽的固态硬盘(SSD)内部控制器或近数据计算单元。
精妙的精度隔离(解决 PCIe 瓶颈的终极答案):流程图清晰地界定了传输界限——PCIe 总线上流动的永远是体积较小的 FP16(16位)数据(即 GPU 传给 SSD 的梯度,以及 SSD 传回 GPU 的参数)。而极其庞大的 FP32(32位)数据(转换过程、优化器状态计算、最终持久化落盘)全部被严格封闭在 SSD 内部完成。这从根本上规避了经典 PCIe 带宽无法支撑高频海量状态传输的致命弱点。
“零开销”的闭环:通过让高精度的参数和优化器状态在 SSD 内部完成计算并直接写入闪存介质,彻底消除了传统架构中“暂停训练、等待显存数据通过总线倾泻到硬盘”的漫长 I/O 停顿,真正实现了不影响训练性能的高频、甚至无感的“Free Checkpointing”。
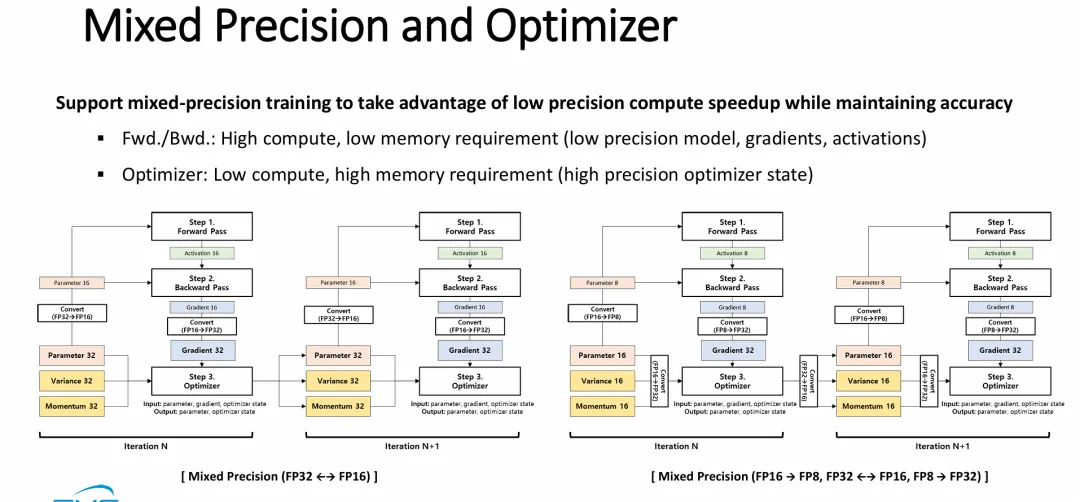
幻灯片从数据精度的视角,深入剖析了 LLM 训练中“计算”与“存储/内存”之间的妥协与优化艺术。
算力与内存的解耦优化:明确指出了前向/反向传播是“算力瓶颈”(需低精度加速),而优化器是“内存/存储瓶颈”(需高精度保收敛)。混合精度训练本质上就是在这两者之间不断进行数据格式的转换。
极致的内存与存储压缩趋势:右侧的激进混合精度方案(FP8计算 + FP16状态存储)代表了行业的最新趋势。通过将庞大的优化器状态(方差、动量)从 32位(FP32)压缩至 16位(FP16),这不仅直接将 GPU 显存占用砍半,更意味着在执行 Checkpoint(保存检查点)时,向底层固态硬盘(SSD)倾泻的数据量也直接减少了 50%。
存储分析师视角:这种精度的演进对存储系统是利好消息。虽然 LLM 模型参数量在指数级增长,但软件层面的量化和混合精度技术(如将高频读写的 Checkpoint 状态从 FP32 降至 FP16)在一定程度上对冲了单次 I/O 写入量的爆炸,使得存储带宽瓶颈得到了一定缓解。
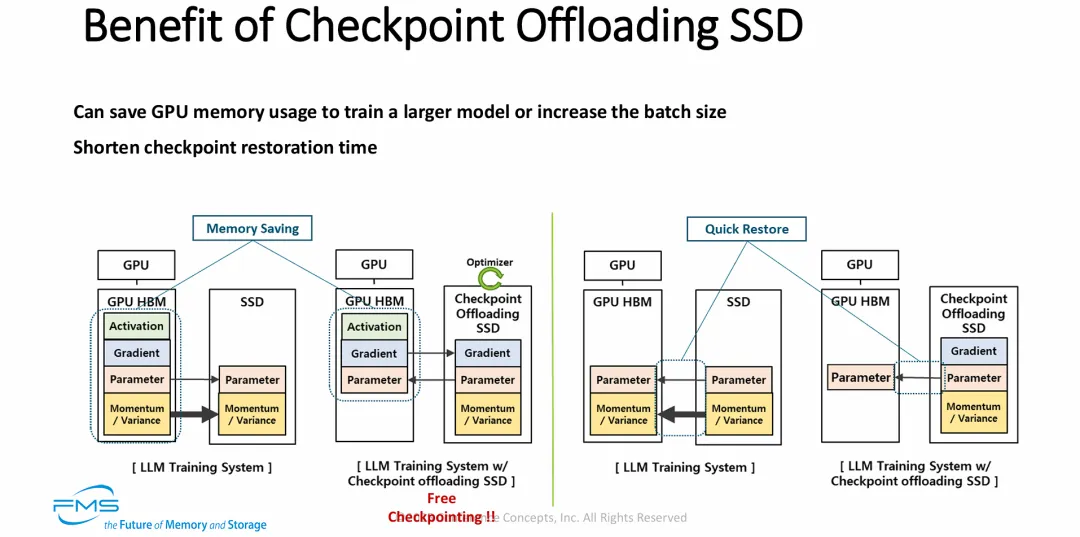
图片精准地切中了 AI 算力集群的痛点,展示了“存算一体/优化器卸载”架构带来的双重革命性红利:
突破“内存墙”,提升算力性价比(Memory Saving):通过将最占地方的优化器状态(占总状态数据量的大头)直接下沉到具备计算能力的 SSD 中,GPU 宝贵的 HBM 显存被大量释放。这不仅解决了内存不足的问题,更使得企业可以在不增加昂贵 GPU 数量的情况下,训练参数规模更大的模型,或者通过增加 Batch Size 来提升计算资源的吞吐率。
打破“I/O 瓶颈”,实现极速容灾(Quick Restore):在传统架构中,一旦训练中断,将几十TB的检查点数据(尤其是优化器状态)重新拉回显存是一个漫长的噩梦。新架构下,因为优化器状态“生于斯长于斯(始终在 SSD 内)”,系统恢复时只需加载体积小得多的模型参数。这种“非对称传输”(写少读少)彻底改变了 AI 存储的 I/O 模式,将故障恢复的时间开销降至最低。
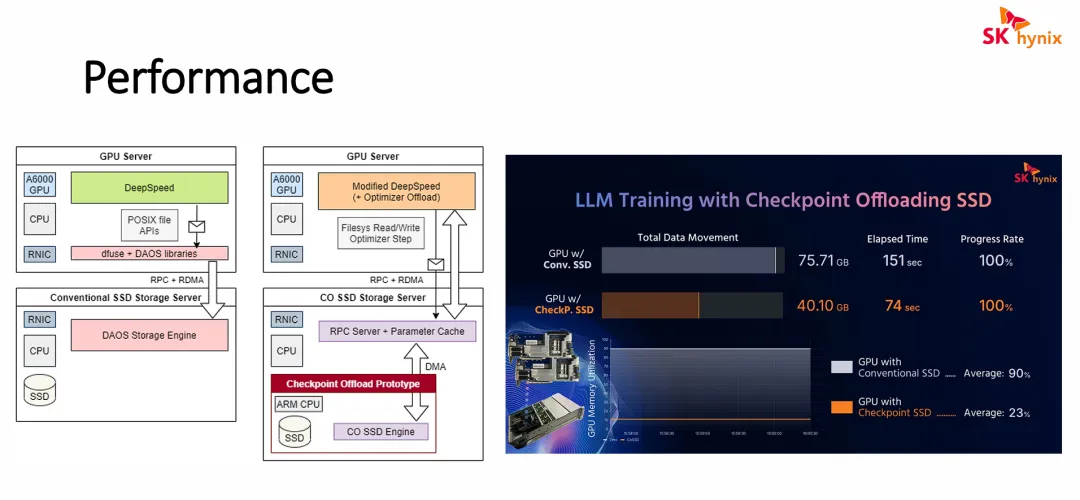
数据IO 路径
- 传统架构 (Conventional SSD Storage Server)
数据 I/O 流转路径(厚重且冗长): 数据从 GPU 显存出发,需要经过极其深厚的软件栈:GPU -> DeepSpeed 框架 -> POSIX 标准文件系统 API -> dfuse 与 DAOS 客户端存储库 -> RNIC (RDMA网卡) -> 网络 -> 存储端 RNIC -> 存储端 CPU -> DAOS 存储引擎 -> 最终落盘到普通 SSD。
- 新型存算一体架构 (CO SSD Storage Server)
数据 I/O 流转路径(扁平且极简): 数据流转绕过了传统文件系统的繁文缛节:GPU -> 定制版 DeepSpeed (Modified DeepSpeed) -> 轻量级文件系统读写 -> RNIC -> 网络 -> 存储端 RNIC -> RPC Server 与参数缓存 -> DMA (直接内存访问) -> Checkpoint Offload Prototype (存算一体 SSD 内的 ARM CPU 及介质)。
| I/O 流转阶段 | 传统架构方案 (Conventional SSD Storage Server) | 存算一体架构方案 (CO SSD Storage Server) | 架构差异分析与核心优势 |
|---|---|---|---|
| 1. AI 训练框架层 | 运行标准版 DeepSpeed | 运行定制版 Modified DeepSpeed (+ Optimizer Offload) | 新方案在框架层即完成任务剥离,明确哪些操作被卸载。 |
| 2. 主机端接口层 | 经过厚重的 POSIX file APIs,并调用繁杂的 dfuse + DAOS libraries | 使用轻量级的 Filesys Read/Write Optimizer Step (直接读写优化器步骤) | 新方案砍掉了传统的 POSIX 和复杂的客户端库,大幅降低 CPU 开销与软件栈延迟。 |
| 3. 网络传输层 | 通过 RNIC 使用 RPC + RDMA 传输大体积的高精度状态数据 | 通过 RNIC 使用 RPC + RDMA 传输体积较小的低精度梯度数据 | 物理链路相同,但新方案传输的数据量实现了级数级下降,缓解网络拥塞。 |
| 4. 存储端接收层 | 由存储服务器的主机 CPU 运行庞大的 DAOS Storage Engine (分布式存储引擎) | 由存储服务器的主机 CPU 运行轻量级的 RPC Server + Parameter Cache (参数缓存) | 新方案不再依赖厚重的主机端存储引擎进行数据路由,释放了存储服务器的 CPU 算力。 |
| 5. 底层落盘与计算 | 纯粹的写数据操作,数据最终写入普通的 SSD 介质 | 数据通过 DMA 直接打入 Checkpoint Offload Prototype (存算一体原型盘) | 新方案的核心: 绕过存储端 CPU,直接由硬盘内部的 ARM CPU 和 CO SSD Engine 完成复杂的优化器计算并就地落盘。 |
新型架构的优势:
极致的性能与带宽释放:正如右侧数据所示,由于大幅削减了无效的数据搬移(总数据量从 75.71 GB 降至 40.10 GB),I/O 耗时缩减了一半。
实现“Free Checkpointing”:把最耗时的 I/O 操作封装到了存储设备内部,GPU 服务器只需发送轻量级指令和少量数据即可继续下一轮训练,几乎感受不到 Checkpoint 带来的停顿,从而最大化了昂贵 GPU 的计算利用率(MFU)。
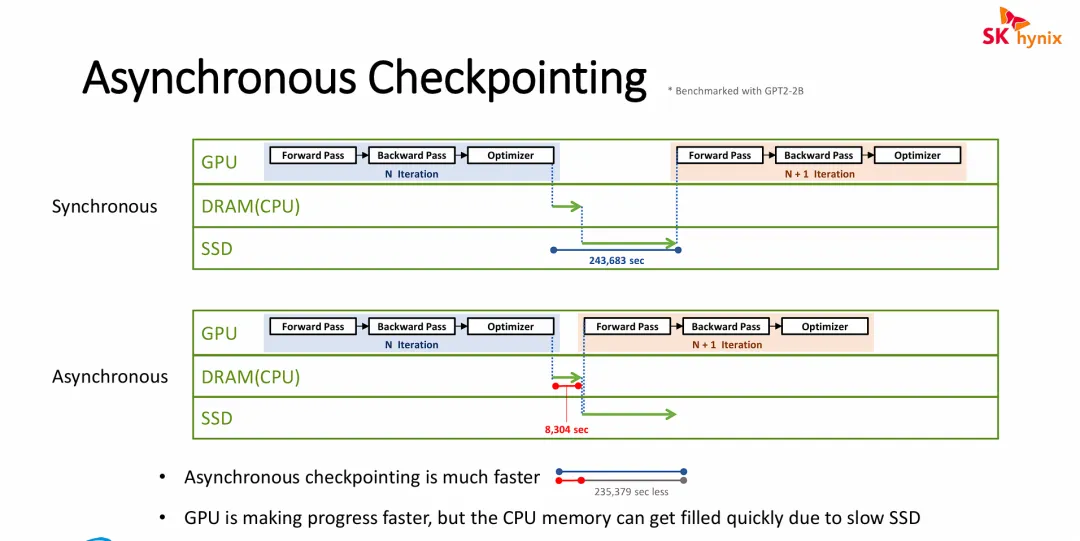
图片深刻地揭示了在应对 LLM 训练的海量 I/O 压力时,纯软件层面的“异步策略”所带来的收益与不可避免的物理局限。
“空间换时间”的性能狂飙:异步检查点策略通过引入主机端的 DRAM 作为巨大的高速缓冲池,将最慢的“SSD 物理落盘”动作从 GPU 的关键训练路径(Critical Path)中剥离。这完美掩盖了底层存储的延迟,让昂贵的 GPU 算力不再被 I/O 停顿所浪费,极大提升了模型迭代的整体速度。
转移瓶颈而非消灭瓶颈(内存溢出风险):图片底部直击了该策略的软肋。异步机制并没有真正提高整体系统的 I/O 吞吐能力。如果 GPU 训练速度极快,高频产生庞大的 Checkpoint 文件,而底层的普通 SSD 写入带宽拉垮(消化不良),那么未落盘的数据就会在主板的 DRAM 中疯狂堆积。一旦 DRAM 被撑爆(OOM),整个训练任务依然会崩溃。
对底层存储的呼唤:这正是 SK hynix 作为存储大厂想要传递的潜台词——纯靠软件异步调度只能“治标”,要真正解决 DRAM 被快速撑爆的风险,依然需要底层具备极高持续写入带宽的高性能存储介质(或者如之前幻灯片提到的存算一体/卸载架构)来“治本”。
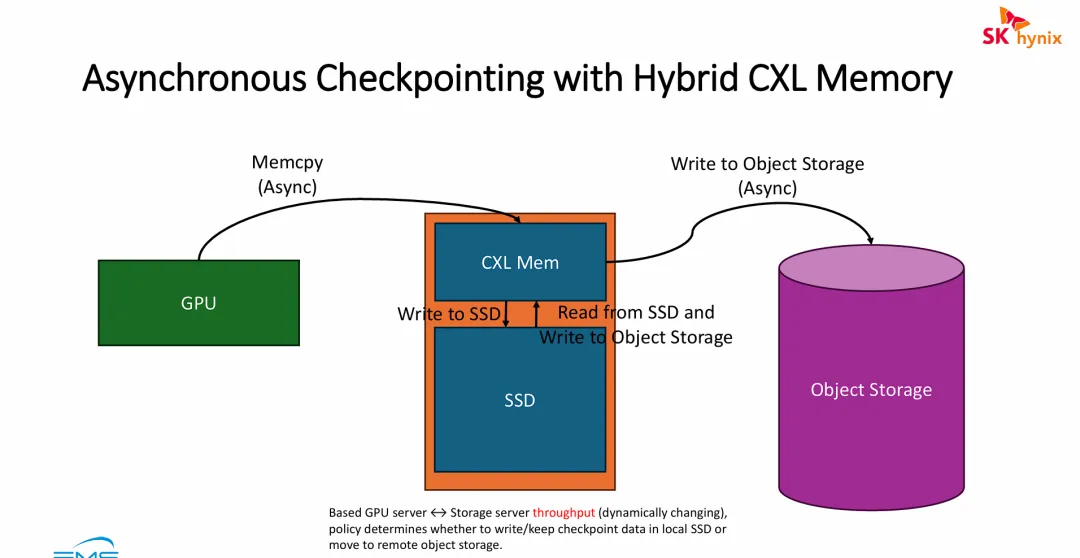
图片展示的是针对上一张幻灯片中“CPU DRAM 容易被慢速 SSD 撑爆(OOM 风险)”这一痛点,所提出的终极硬件解法:基于 CXL 内存的智能多级异步存储架构。
引入 CXL 内存打破容量墙:传统 CPU DRAM 容量有限且扩展昂贵。引入 CXL Mem(Compute Express Link 内存)后,系统获得了一个兼具“内存级极低延迟/高带宽”和“类似硬盘的可无限扩展容量”的超级缓冲池 。GPU 可以毫无顾忌地将海量 Checkpoint 数据瞬间卸载(Async Memcpy)到 CXL 内存中,彻底消除了显存阻塞和主机内存溢出的风险。
动态感知的数据冷热分层(Tiering):该架构将后端存储化静为动。它不再是死板地向硬盘写数据,而是加入了一个智能调度策略。当网络拥塞或远端对象存储响应慢时,数据从 CXL 内存下沉到本地 SSD 充当大容量二缓;当网络带宽充裕时,数据再从本地层级异步抽离,长久归档到廉价的远端对象存储中。
极致的 I/O 隔离:通过
GPU -> CXL Mem -> 本地 SSD <-> 远端 Object Storage的三级流水线设计,极快的前端计算与极慢的后端持久化物理动作被完美地解耦与隔离。GPU 的算力利用率(MFU)被保护到了极致。
一直认为并行文件系统是模型训练场景的必备基础设施,但从SKHynix 这篇文章的方案来看,未来基于硬件强化的模型训练方案、文件系统(哪怕是DAOS)因软件层大量消耗,最终可能被极致的硬件优化所替代,这是底层硬件厂商的一场翻身仗。
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 存算一体SSD的优化器卸载,在PCIe Gen5时代能否真正消除I/O停顿,还是需CXL等新总线补位?
- 混合精度下,Checkpoint数据虽压缩,但高频写入对QLC SSD的WAF和耐久性有何挑战?如何软件优化?
- 未来AI训练存储,将是纯硬件强化(如SmartSSD)取代并行文件系统,还是两者融合?你的预测?
原文标题:
Efficient LLM Checkpointing with Memory and Storage[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro

👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250805_COMP-102-1_Kim-2025-08-04-21.00.46.pdf ↩
