 夜雨聆风
夜雨聆风💡 一个能记住你喜好的 AI 助手,是怎么做到的?
一、先说结论:像 RAG,但不完全是
很多人第一次接触 OpenClaw 的记忆功能时,都会产生一个疑问:这不就是 RAG 吗?
严格来说,是,也不是。
OpenClaw 的记忆机制确实借鉴了 RAG(检索增强生成)的核心思想,但它的实现方式更像是一个双引擎数据库系统:
• 短期记忆 → 相当于 SQLite,记录每一次对话的原始细节 • 长期记忆 → 相当于 Elasticsearch,存储提炼后的关键信息
当你和 OpenClaw 聊天时,它会在两个"数据库"之间智能切换,既不忘掉刚才说的话,也能记起你三个月前提过的需求。
二、记忆的两大层次
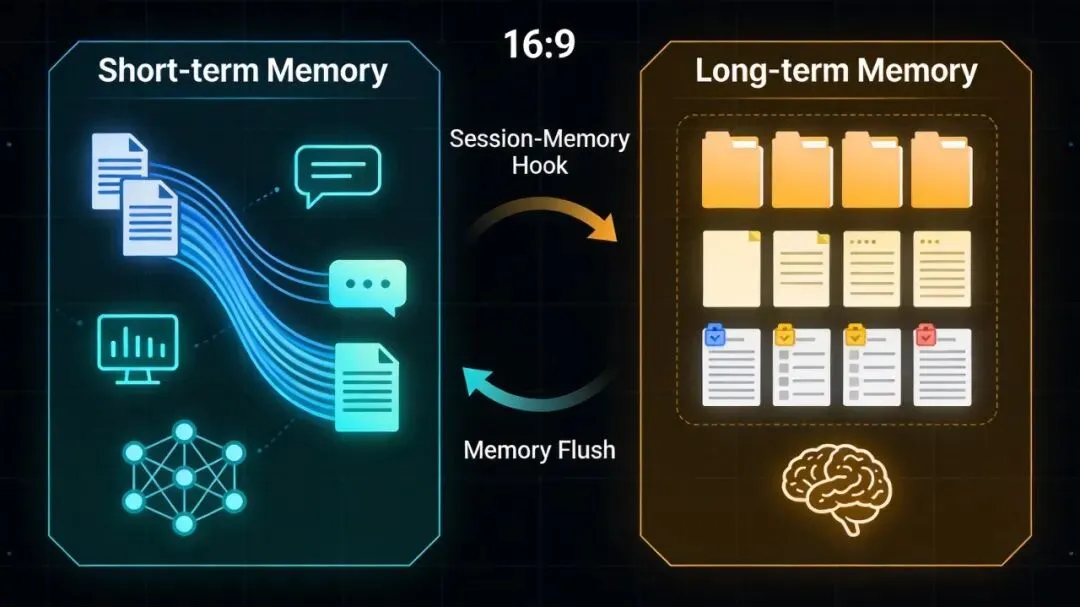
OpenClaw 的记忆系统分为两个层级,赋予 Agent 真正的"记性":
1. 短期记忆(Session Level)
存储位置:~/.openclaw/agents/{agentid}/sessions/
文件格式:JSONL(每行一条记录)
存什么:
• 你和 AI 的每一次原始对话 • 调用的工具记录 • 系统的元数据(时间、会话 ID 等)
特点:
• 自动记录,无需干预 • 像飞机黑匣子一样保存完整上下文 • 会话结束后仍可追溯
会话文件示例:sessions/├── 2026-03-21_001.jsonl ← 今天的对话├── 2026-03-20_003.jsonl ← 昨天的对话└── ...2. 长期记忆(Memory Level)
存储位置:工作区内的 MEMORY.md 或 memory/*.md
文件格式:Markdown(结构化文本)
存什么:
• 你的身份特征("他是后端工程师,喜欢用 Go") • 技术偏好("偏好本地部署,重视隐私") • 重要决策记录 • 项目上下文
特点:
• 人工 + AI 共同维护 • 跨会话持久化 • 下次对话时自动加载
记忆文件示例:memory/├── MEMORY.md ← 核心长期记忆├── 2026-03-21.md ← 今日提炼├── 2026-03-20.md ← 昨日提炼└── ...三、短期记忆如何变成长期记忆?
关键在于两个自动化机制:
机制一:Session-Memory Hook
触发时机:当你执行 /new 命令结束会话时
工作流程:
1. 系统读取当前会话的 JSONL 文件 2. AI 分析对话内容,提取关键事实 3. 将提炼结果写入 memory/YYYY-MM-DD.md4. 重要信息更新到 MEMORY.md
举例:
原始对话(JSONL):- 用户:"我最近在学 Rust,帮我写个爬虫"- AI:写了一个示例代码- 用户:"不错,但我更习惯用 Go"- AI:用 Go 重写了一个版本提炼后(Memory):- 用户技术栈:Go(偏好)、Rust(学习中)- 项目需求:需要爬虫工具机制二:Memory Flush(内存刷新)
触发时机:当会话上下文(Context)接近上限时
工作流程:
1. OpenClaw 检测到上下文窗口即将耗尽 2. 启动 Compaction(压缩) 机制 3. 提取当前会话的核心摘要 4. 写入长期记忆,释放上下文空间 5. 继续对话,但"轻装上阵"
技术细节:
• 上下文上限由模型决定(如 Claude 200K tokens) • Compaction 会保留关键决策,舍弃闲聊内容 • 用户无感知,对话流畅不中断
四、检索机制:比 RAG 更聪明的混合搜索
OpenClaw 在唤起记忆时,使用的不是简单的向量检索,而是混合检索策略:
1. BM25 关键词搜索
原理:基于词频和逆文档频率的传统搜索算法
优势:
• 精准匹配关键词(如 "OpenClaw"、"RAG") • 不需要向量嵌入,速度快 • 对技术术语特别有效
2. Rerank(重排序)
原理:第一轮召回大量候选,第二轮用语义模型精排
优势:
• 结合关键词精准性和语义相关性 • 避免"关键词匹配但语义无关"的干扰 • 类似 Elasticsearch 的 BM25 + 机器学习的混合打分
3. 记忆索引
核心问题:有成百上千个 Markdown 文件,怎么快速找到相关片段?
OpenClaw 的解决方案:
• 对长期记忆文件建立语义索引 • 对话开始前自动加载最相关的记忆 • 根据用户提问动态检索,不加载无关内容
工作流程:
用户提问 → 分析意图 → 检索记忆 → 混合排序 → 注入 Prompt → 生成回复 ↑ BM25 + Rerank五、与典型 RAG 项目的对比
| 数据流 | ||
| 更新频率 | ||
| 存储介质 | ||
| 检索方式 | ||
| 人工干预 | ||
| 适用场景 |
六、技术实现要点
1. 为什么用 JSONL 存短期记忆?
• 追加写入快:每条对话一行,无需读取整个文件 • 容错性强:即使文件损坏,也只丢失最后一行 • 易于解析:标准格式,各种语言都支持
2. 为什么用 Markdown 存长期记忆?
• 人类可读:用户可以直接打开查看和编辑 • 版本友好:适合 Git 管理,可追溯变更 • 结构灵活:支持 YAML frontmatter、列表、表格等
3. Compaction 算法如何选择保留内容?
优先级排序:
1. 用户明确要求的"记住这个"(显式指令) 2. 涉及身份、偏好的信息(个性化数据) 3. 技术决策和代码选择(项目上下文) 4. 待办事项和约定(Action items) 5. 闲聊和过渡语句(可丢弃)
七、给开发者的启示
OpenClaw 的记忆机制设计,体现了几个重要的工程思想:
1. 分层存储
不要把所有数据都塞到一个库里。原始数据用高效格式,提炼数据用可读格式,各司其职。
2. 混合检索
单一检索策略都有局限。BM25 保精准,向量保语义,rerank 保质量,组合拳效果最好。
3. 人机协作
完全自动化的记忆容易出错,完全手动的又太麻烦。OpenClaw 选择自动提炼 + 人工可编辑,是务实的折中。
4. 本地优先
记忆文件存在本地,用户拥有完全的控制权。想备份、想迁移、想删除,都由用户决定。
八、结语
OpenClaw 的记忆机制,本质上是一套"原始对话 → 智能提炼 → 混合检索"的完整流水线。
它不是简单的 RAG,而是为个人 Agent 场景专门优化的记忆架构。
理解这套机制,能帮助你更好地使用 OpenClaw,也能为你设计自己的 AI 系统提供参考。
毕竟,一个能记住你喜好的 AI,才是真正有用的 AI。
💬 技术讨论
你用过 OpenClaw 的记忆功能吗?有没有遇到过"它居然还记得这件事"的惊喜瞬间?
欢迎在评论区分享你的使用体验,或者提出你对记忆机制的改进建议!
参考来源:
• OpenClaw 官方文档 • OpenClaw 源码:Session 管理与 Memory 模块 • RAG 架构最佳实践
