 夜雨聆风
夜雨聆风开篇
上篇文章《我把 AI 助手"养"在笔记本上:3 个月实测,这 5 个坑别踩[1]》里,我写了段话:
"技能组合:1+1>2。单个技能没什么特别的,真正的威力在于组合使用。"
然后放了张流程图:
早上 7 点自动执行:
1. 读取昨晚的邮件 → 2. 提取待办事项
→ 3. 写入 Excel 表格 → 4. 生成 Word 日报
→ 5. 发送到我的 Telegram
文章发出去后,有读者留言:
"所以工作流怎么配?给个例子啊。"
上篇我确实提了"技能组合",但真没给具体怎么把技能串起来。
这 3 个月,我搭建了 5 个工作流,每天都在跑。其中AI 新闻推送这个工作流,从踩坑到稳定,跑了整整 2 天。
今天开始,用 7 篇连载,把后续的代码和使用全交出来。
这是第 1 篇:AI 新闻推送。
一、工作流目标
场景: 我每天想知道 AI 领域发生了什么,但手动刷太累。
之前: 早上花 30 分钟刷 36 氪、机器之心、arXiv、Twitter。
目标: 每天早上自动推送 10 条新闻,分类整理,来源多样。
约束:
新闻必须是最近 48 小时的 单一来源不超过 3 条 国际来源至少 40%
二、工作流设计
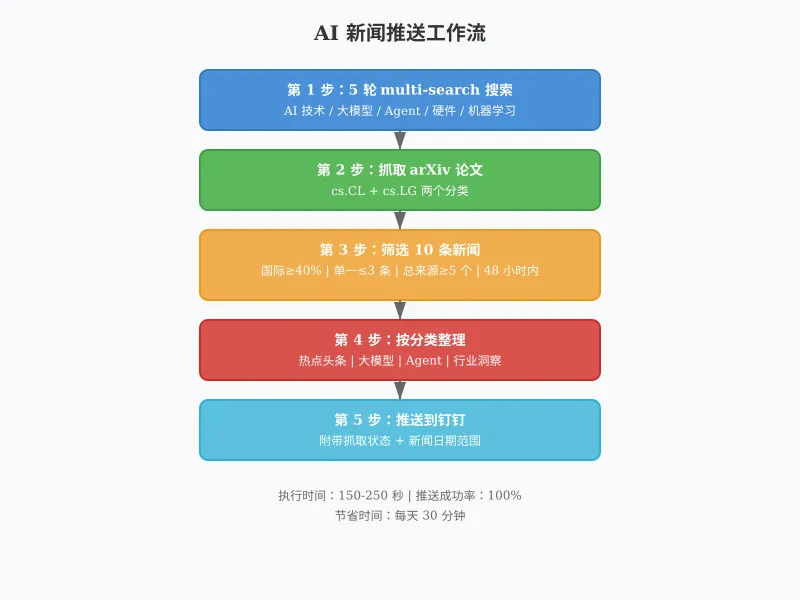
2.1 流程图
┌─────────────────────────────────────────────────┐
│ 每天早上自动触发 │
└─────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 第 1 步:5 轮 multi-search-engine 搜索 │
│ - AI 技术 最新进展 最近 2 天 │
│ - 大模型 LLM 发布 昨天 今天 │
│ - Agent 智能体 新框架 最新发布 │
│ - AI 硬件 芯片 端侧 2026 年 3 月 │
│ - 机器学习 算法 突破 本周 │
└─────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 第 2 步:抓取 arXiv 最新论文(2 个分类) │
│ - https://arxiv.org/list/cs.CL/recent │
│ - https://arxiv.org/list/cs.LG/recent │
└─────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 第 3 步:筛选 10 条新闻(严格规则) │
│ - 国际来源 ≥4 条(≥40%) │
│ - 单一来源 ≤3 条,总来源≥5 个 │
│ - 只选最近 48 小时内的新闻 │
└─────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 第 4 步:按分类整理 │
│ - 热点头条(1-2 条) │
│ - 大模型技术 │
│ - Agent 与智能体 │
│ - 行业洞察 + 趋势表格 │
└─────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 第 5 步:推送到钉钉 │
│ - 附带抓取状态 │
│ - 新闻日期范围 │
└─────────────────────────────────────────────────┘
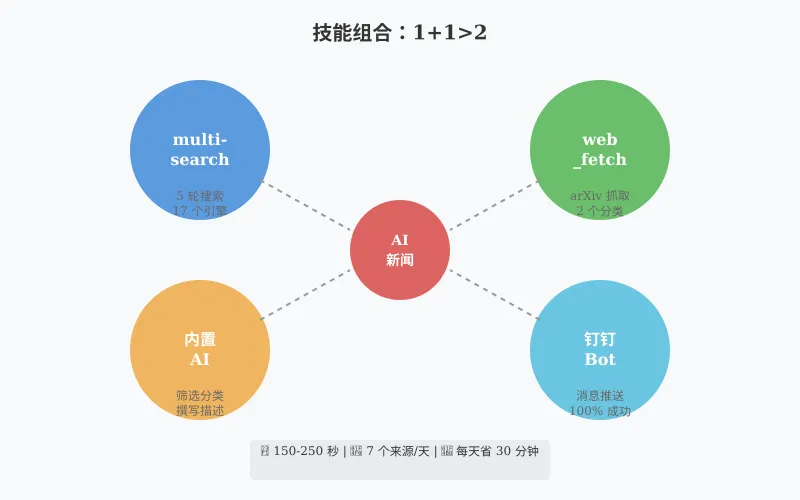
2.2 涉及技能
| 技能 | 用途 | 调用次数 |
|---|---|---|
| multi-search-engine | 5 轮中文搜索(17 个引擎) | 5 次 |
| web_fetch | 抓取 arXiv 论文 | 2 次 |
| 内置 AI | 筛选、分类、撰写描述 | 1 次 |
| 钉钉 Bot | 推送消息 | 1 次 |
2.3 工作流配置
// ~/.openclaw/cron/jobs.json
{
"id": "ai-tech-daily-search",
"name": "AI 技术新闻每日搜索",
"schedule": {
"kind": "cron",
"expr": "0 7 * * *",
"tz": "Asia/Shanghai"
},
"sessionTarget": "isolated",
"payload": {
"kind": "agentTurn",
"message": "【工作流】执行 AI 新闻推送:5 轮搜索→arXiv 抓取→筛选 10 条→分类→推送"
},
"delivery": {
"mode": "announce",
"channel": "ddingtalk",
"to": "ddingtalk:chat:xxx"
}
}
三、关键代码
3.1 搜索命令(5 轮)
# 第 1 轮:综合搜索(国内 + 全球引擎)
npx multi-search-engine "AI 技术 最新进展 最近 2 天" --num 20
# 第 2 轮:大模型
npx multi-search-engine "大模型 LLM 发布 昨天 今天" --num 20
# 第 3 轮:Agent
npx multi-search-engine "Agent 智能体 新框架 最新发布" --num 20
# 第 4 轮:AI 硬件
npx multi-search-engine "AI 硬件 芯片 端侧 2026 年 3 月" --num 20
# 第 5 轮:机器学习
npx multi-search-engine "机器学习 算法 突破 本周" --num 20
multi-search-engine 优势:
17 个引擎(8 国内 +9 全球) 无需 API 密钥 自动去重 支持时间过滤
3.2 arXiv 抓取
web_fetch({"url": "https://arxiv.org/list/cs.CL/recent", "extractMode": "text", "maxChars": 3000})
web_fetch({"url": "https://arxiv.org/list/cs.LG/recent", "extractMode": "text", "maxChars": 3000})
3.3 筛选规则(由 AI 自动执行)
说明: 实际实现中,筛选规则写在定时任务的提示词里,由 AI 自动执行,无需独立代码。为帮助理解,以下用伪代码展示逻辑:
def select_news(all_results):
selected = []
sources = {}
international_count = 0
for news in all_results:
# 检查日期(最近 48 小时)
if not is_recent_48h(news.date):
continue
# 检查来源多样性
if sources.get(news.source, 0) >= 3:
continue
# 优先 arXiv 论文
if is_arxiv(news):
international_count += 1
selected.append(news)
sources[news.source] = sources.get(news.source, 0) + 1
if len(selected) >= 10:
break
# 验证国际来源占比
if international_count < 4:
# 补充国际新闻
fill_international_news(selected)
return selected
实际提示词片段:
强制规则:
- 国际来源 ≥4 条(≥40%)
- 单一来源 ≤3 条,总来源≥5 个
- 只选最近 48 小时内的新闻
- arXiv 论文优先
四、输出示例
【AI 技术日报】
## 热点头条
1. XXX 发布新模型,参数 XXX
来源:[36 氪](链接)
描述:2-5 句话...
## 大模型技术
2. XXX 论文,arXiv:xxxx.xxxxx
来源:[arXiv](链接)
描述:...
## 趋势表格
| 技术领域 | 关键进展 | 代表产品 | 影响 |
【抓取状态】
arXiv CS.CL: ✅
arXiv CS.LG: ✅
国际来源共 X 条,占比 X%
五、踩的坑
坑 1:日期过滤不准
第一次运行时,抓到了旧闻——AI 以为"最新"就是最近的。
解决:
提示词明确写"最近 48 小时""昨天和前天" arXiv 论文用 ID 判断 看到日期超过 2 天的直接丢弃
坑 2:来源太单一
第一天推送的新闻,大部分来自同一家——我自己都看不下去了。
解决:
强制规则:单一来源≤3 条 总来源≥5 个 国际来源≥40%(arXiv 优先)
坑 3:执行时间太长
第一次跑了 9 分钟——等得太久。
解决:
优化搜索轮次(从 8 轮减到 5 轮) 用搜索引擎内置摘要(不抓取详情页) 现在稳定在 150-250 秒
六、成果

稳定运行后的数据:
| 指标 | 数值 |
|---|---|
| 执行时间 | 150-250 秒 |
| 推送成功率 | 100% |
| 新闻准确率 | 约 95% |
| 来源多样性 | 平均 7 个来源/天 |
| 国际来源占比 | 40-50% |
| 节省时间 | 每天 30 分钟 |
七、下篇预告
第 2 篇:邮件自动处理
上篇工作流示例的第 1 步:"读取昨晚的邮件 → 提取待办事项"
每天早上自动处理昨晚的邮件 常见问题自动回复(用我的语气) 敏感邮件转人工 从 60 分钟 → 10 分钟
你在搭建 AI 助手时踩过什么坑?欢迎留言交流。
关注我,不错过后续 6 篇实战连载。
引用链接
[1]我把 AI 助手"养"在笔记本上:3 个月实测,这 5 个坑别踩: https://mp.weixin.qq.com/s/lBGAaNHcWqTnHRCsTb5YxA
