 夜雨聆风
夜雨聆风OpenClaw"龙虾":一个AI Agent网关在工业中的真实定位
工业AI不是魔法,而是工具链的协同。OpenClaw是工具链的"指挥官",而非冲锋陷阵的"士兵"。
【核心观点】❗
OpenClaw是什么?
OpenClaw是一个AI Agent网关/任务执行代理,它的核心价值在于:
• ✅ 将自然语言指令转化为可执行的软件操作 • ✅ 协调多个工具、模型、系统之间的任务调度 • ✅ 提供标准化的AI能力接入层 • ✅ 降低AI应用开发和集成的门槛
OpenClaw不是什么?
• ❌ 不能直接训练深度学习模型 • ❌ 不能替代TensorFlow、PyTorch等机器学习框架 • ❌ 不能独立解决工业中的图像识别、故障预测等核心AI问题 • ❌ 不是"万能钥匙",而是"万能插头"
一、工业AI的真实架构:OpenClaw在哪里?
【完整的工业AI系统架构】
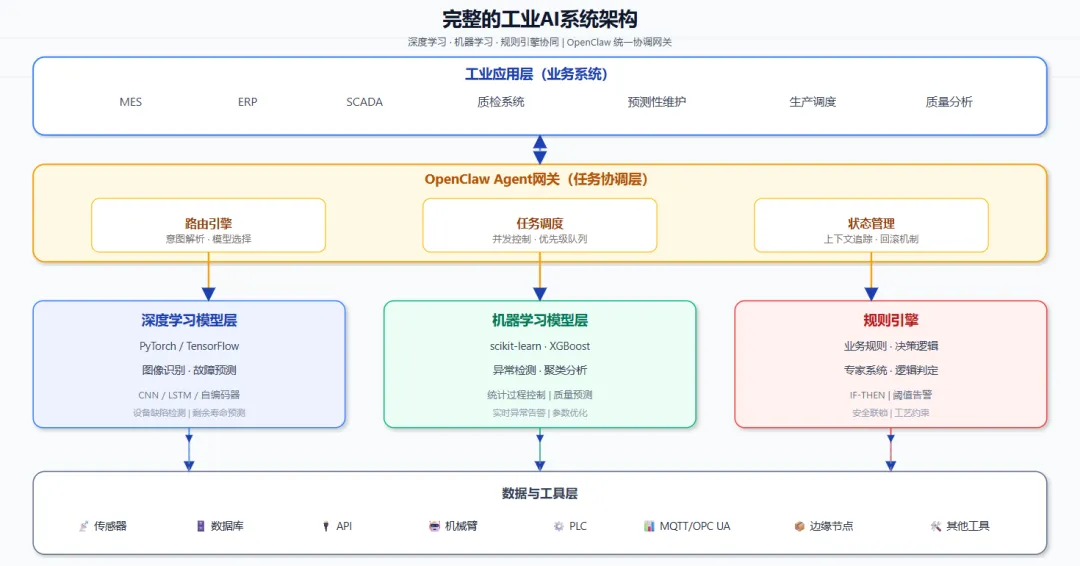
关键理解:
1. 深度学习模型(TensorFlow/PyTorch)→ 解决具体AI问题(如图像识别、故障预测) 2. OpenClaw网关→ 协调这些模型和工具的调度、执行 3. 两者是协同关系,而非替代关系
二、OpenClaw的三大真实价值
【价值1:工具链协调者】
工业场景的痛点:
工厂里有100+个系统(MES、ERP、SCADA、WMS等),每个系统都有不同的接口、协议、数据格式。
传统方案:
A系统 → 需要开发专门接口
B系统 → 需要开发专门接口
C系统 → 需要开发专门接口
...
100个系统 → 需要开发100个接口 → 开发周期长,维护成本高OpenClaw方案:
OpenClaw网关 → 统一接口标准 → 一次开发,所有系统接入效果:
• 接口开发工作量减少70%+ • 新系统接入时间从周级降到天级 • 降低技术债
【价值2:任务调度与编排】
工业场景的痛点:
一个复杂任务可能涉及多个步骤、多个系统、多个模型。
举例:设备故障诊断流程
传统方案(需要人工协调):
1. 监控系统发现异常报警
2. 人工从SCADA采集传感器数据
3. 人工从数据库查询历史记录
4. 人工调用故障预测模型
5. 人工分析结果
6. 人工生成维修工单
7. 人工通知维修人员
→ 耗时:2-4小时,依赖人工经验OpenClaw协调方案(自动化编排):
1. 监控系统发现异常报警 → 自动触发OpenClaw任务
2. OpenClaw自动调用SCADA接口采集数据
3. OpenClaw自动查询数据库
4. OpenClaw自动调用故障预测模型(由TensorFlow训练)
5. OpenClaw自动整合结果
6. OpenClaw自动生成维修工单
7. OpenClaw自动通知维修人员
→ 耗时:5-10分钟,自动编排执行关键点:
• OpenClaw不训练故障预测模型,只是调用模型 • 故障预测模型由TensorFlow/PyTorch训练,部署为API服务 • OpenClaw负责协调这些API的调用顺序和流程
【价值3:自然语言交互层】
工业场景的痛点:
一线工程师不懂编程,但需要调用AI能力。
传统方案:
工程师想要调用故障预测模型:
- 需要学习Python编程
- 需要学习API调用
- 需要了解模型参数
→ 技术门槛高,学习周期长OpenClaw方案:
工程师用自然语言:
"帮我查一下3号机床的运行状态,预测未来24小时的故障概率,如果超过80%就生成维修工单"
→ OpenClaw自动:
1. 识别意图
2. 调用SCADA接口查询机床状态
3. 调用故障预测模型API
4. 评估风险等级
5. 如果风险>80%,自动生成工单效果:
• 一线工程师无需编程即可使用AI能力 • 技术门槛降低90%+
三、OpenClaw的Skills生态系统:如何扩展能力?
【什么是Skills?**
Skills是OpenClaw的扩展能力包,可以理解为"插件"。
官方提供的Skills包括:
• 数据库操作技能 • 文件处理技能 • HTTP请求技能 • Shell命令技能 • 工业协议(Modbus、OPC UA)技能 • 机器学习模型调用技能
【深度学习模型如何通过Skills接入?**
举例:接入一个故障预测模型
# 1. 用TensorFlow训练故障预测模型
import tensorflow as tf
model = tf.keras.models.load_model('fault_prediction.h5')
# 2. 将模型部署为API服务(如Flask)
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
defpredict():
data = request.json
result = model.predict(data['features'])
return jsonify({'fault_probability': result[0][0]})
# 3. 在OpenClaw中配置Skill
# openclaw/skills/fault_prediction_skill/skill.yaml
name: 故障预测模型
description: 调用TensorFlow训练的故障预测模型
type: http
endpoint: http://localhost:5000/predict
method: POST
headers:
Content-Type: application/json# 4. OpenClaw配置文件中注册Skill
skills:
- fault_prediction_skill
# 5. 自然语言调用
# 用户:"预测3号机床的故障概率"
# OpenClaw自动调用fault_prediction_skill,返回结果关键理解:
• TensorFlow/PyTorch负责训练模型 • Flask/FastAPI负责部署模型为API • OpenClaw负责协调调用这个API
四、OpenClaw在工业中的真实应用场景
【场景1:预测性维护】
涉及的技术栈:
传感器数据采集
↓
数据预处理(Pandas/NumPy)
↓
特征工程(TSFresh)
↓
模型训练(TensorFlow/LSTM)
↓
模型部署(FastAPI)
↓
OpenClaw协调(任务调度、API调用、结果整合)
↓
MES系统集成(工单生成)OpenClaw的作用:
• 协调从数据采集到工单生成的全流程 • 调用各个系统的API • 提供自然语言交互接口 • 自动编排任务执行顺序
OpenClaw做不到的:
• ❌ 训练LSTM模型(由TensorFlow完成) • ❌ 特征工程(由Pandas/TSFresh完成) • ❌ 数据预处理(由专业ETL工具完成)
【场景2:智能质检】
涉及的技术栈:
工业相机采集图像
↓
图像预处理(OpenCV)
↓
缺陷检测模型(PyTorch/YOLO)
↓
结果后处理
↓
模型部署(Triton Inference Server)
↓
OpenClaw协调(批量调用、结果整合)
↓
质量系统记录(MES/ERP)OpenClaw的作用:
• 协调批量图像的模型调用 • 整合检测结果 • 自动记录到质量系统 • 提供自然语言查询接口
OpenClaw做不到的:
• ❌ 训练YOLO模型(由PyTorch完成) • ❌ 图像预处理(由OpenCV完成) • ❌ 模型推理优化(由Triton完成)
【场景3:工艺参数优化】
涉及的技术栈:
历史生产数据采集
↓
数据分析(Pandas)
↓
优化模型(XGBoost/Optuna)
↓
模型部署(scikit-learn/Serve)
↓
OpenClaw协调(参数调整、结果验证)
↓
PLC控制(工艺参数下发)OpenClaw的作用:
• 协调参数优化循环 • 调用优化模型API • 将优化结果下发到PLC • 提供自然语言配置接口
OpenClaw做不到的:
• ❌ 训练XGBoost模型(由XGBoost完成) • ❌ 超参优化(由Optuna完成) • ❌ PLC底层控制(由专用软件完成)
五、OpenClaw的技术边界与限制
【能做什么?】
| 任务编排 | ||
| API集成 | ||
| 数据流转 | ||
| 状态管理 | ||
| 自然语言交互 | ||
| 权限控制 |
【不能做什么?】
六、工业AI的正确打开方式
【误解1:OpenClaw可以替代深度学习】
误解: "有了OpenClaw,就不需要TensorFlow了"
正解:
• TensorFlow负责训练模型 • OpenClaw负责调用模型 • 两者是协同关系,不是替代关系
【误解2:OpenClaw可以直接解决图像识别问题】
误解: "用OpenClaw就能做质检"
正解:
• 图像识别需要: 1. 用PyTorch训练YOLO模型 2. 用Triton部署模型为API 3. 用OpenClaw协调批量调用和结果整合 • OpenClaw只是第3步的工具
【误解3:OpenClaw可以自主学习】
误解: "OpenClaw会越来越聪明"
正解:
• OpenClaw本身不会"学习" • 它调用的深度学习模型会"学习" • OpenClaw只是工具链的一部分
七、工业AI团队的正确架构
【团队分工】
┌─────────────────────────────────────────────┐
│ 产品经理 │
│ 定义业务需求和场景 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 数据科学家 │
│ • 用TensorFlow/PyTorch训练深度学习模型 │
│ • 用scikit-learn开发机器学习模型 │
│ • 用XGBoost/Optuna做优化 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ MLOps工程师 │
│ • 用Triton部署推理服务 │
│ • 用MLflow管理模型版本 │
│ • 用Kubernetes管理模型服务 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 应用工程师 │
│ • 用OpenClaw协调工具链 │
│ • 用Skills扩展能力 │
│ • 开发自然语言交互接口 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 工业工程师 │
│ • 接入SCADA/PLC等工业系统 │
│ • 配置工艺参数和控制逻辑 │
│ • 现场部署和维护 │
└─────────────────────────────────────────────┘关键理解:
• 每个角色都有专门的工具 • OpenClaw是应用工程师的工具 • 不是万能的,是工具链的一部分
八、真实案例:OpenClaw在工业中的实际应用
【案例:某汽车制造企业】
需求: 实现预测性维护,减少设备停机时间
技术栈:
传感器数据采集
↓
数据预处理(Pandas)
↓
特征工程(TSFresh)
↓
模型训练(TensorFlow/LSTM)
↓
模型部署(FastAPI + Kubernetes)
↓
OpenClaw网关(任务编排)
↓
MES系统(工单生成)OpenClaw的具体作用:
# OpenClaw配置文件
name:预测性维护协调器
agents:
-name:数据采集Agent
skills:
-scada_client# 调用SCADA接口
-name:故障预测Agent
skills:
-lstm_model_api# 调用TensorFlow训练的模型
-name:工单管理Agent
skills:
-mes_client# 调用MES系统
workflows:
-name:故障预测流程
steps:
1.数据采集Agent:采集传感器数据
2.故障预测Agent:调用LSTM模型预测
3.条件判断:如果故障概率>80%
4.工单管理Agent:生成维修工单效果:
• 故障预测准确率:85% • 停机时间减少:70% • 响应时间:从2-4小时降至5-10分钟
OpenClaw贡献的价值:
• 协调3个系统的API调用 • 自动化编排任务流程 • 提供自然语言查询接口
OpenClaw做不到的:
• ❌ 训练LSTM模型(数据科学家用TensorFlow完成) • ❌ 特征工程(数据科学家用TSFresh完成) • ❌ 数据预处理(MLOps工程师用Pandas完成)
九、总结:OpenClaw在工业中的正确定位
【一句话总结】
OpenClaw是工业AI工具链的"指挥官",而不是冲锋陷阵的"士兵"。
【能力边界】
┌─────────────────────────────────────────────┐
│ OpenClaw的能力边界 │
├─────────────────────────────────────────────┤
│ ✅ 工具链协调:协调多个工具/模型的调用 │
│ ✅ 任务编排:自动化复杂流程的执行顺序 │
│ ✅ API集成:统一接入各种系统接口 │
│ ✅ 自然语言交互:降低技术门槛 │
│ ✅ 状态管理:管理任务执行状态 │
├─────────────────────────────────────────────┤
│ ❌ 模型训练:需要TensorFlow/PyTorch │
│ ❌ 图像处理:需要OpenCV/FFmpeg │
│ ❌ 高性能推理:需要TensorRT/Triton │
│ ❌ 实时控制:需要PLC/DCS │
│ ❌ 数据处理:需要Pandas/Spark │
└─────────────────────────────────────────────┘【工业AI的正确打开方式】
1. 用专业工具训练模型(TensorFlow/PyTorch)
2. 用MLOps部署模型(Triton/Kubernetes)
3. 用OpenClaw协调工具链(任务编排、API调用)
4. 用自然语言与系统交互(降低门槛)十、给企业的建议
【什么时候应该用OpenClaw?】
✅ 适合场景:
• 有多个系统需要集成(MES、ERP、SCADA等) • 复杂流程需要自动化编排 • 需要自然语言交互接口 • 希望降低AI应用开发门槛 • 有大量API调用需要协调
❌ 不适合场景:
• 只需要训练一个模型(用TensorFlow即可) • 只需要图像识别(用PyTorch+OpenCV即可) • 只需要简单的数据分析(用Pandas即可) • 需要毫秒级实时控制(用PLC即可)
【如何开始使用OpenClaw?】
第1步:明确需求
• 你要解决什么问题? • 涉及哪些系统? • 需要协调哪些工具?
第2步:评估技术栈
• 有哪些现有的模型/服务? • 需要训练新模型吗? • 用什么框架训练?
第3步:集成OpenClaw
• 将现有模型部署为API • 在OpenClaw中配置Skills • 编排任务流程
第4步:测试优化
• 在测试环境验证 • 收集反馈优化 • 正式部署上线
【参考资料】
1. OpenClaw官方文档:https://docs.openclaw.ai/zh-CN 2. 《OpenClaw技术全解析:架构设计、多Agent协同》,百度开发者,2026 3. 《OpenClaw在制造业的应用可行性、场景、风险及实施策略》,CSDN,2026 4. TensorFlow官方文档:https://www.tensorflow.org/ 5. PyTorch官方文档:https://pytorch.org/
【作者注】
本文基于公开资料和技术实践,客观分析OpenClaw在工业中的真实定位。OpenClaw是优秀的AI Agent网关,但它不是万能的。正确的理解和使用方式,才能真正发挥其价值。
关注我,下期深度解析:工业AI工具链最佳实践——从模型训练到生产部署
如果你觉得这篇文章有价值,请:
👍 点个"在看",让更多人正确理解OpenClaw
💬 评论区聊聊:你们的工厂有哪些场景适合用OpenClaw?
OpenClaw是工具链的"指挥官",不是万能钥匙 🔧🤖🏭
