 夜雨聆风
夜雨聆风OpenClaw 用起来有多爽,盯日志就有多折磨——会话跑没跑、哪个模型在烧 token、Claude / Gemini 的限额还剩多少、今天是不是又被某个子任务“自嗨式循环”拖到起飞……你明明只是想确认“它还活着吗”,结果变成了在 tail -f 里修行。尴尬了不是?
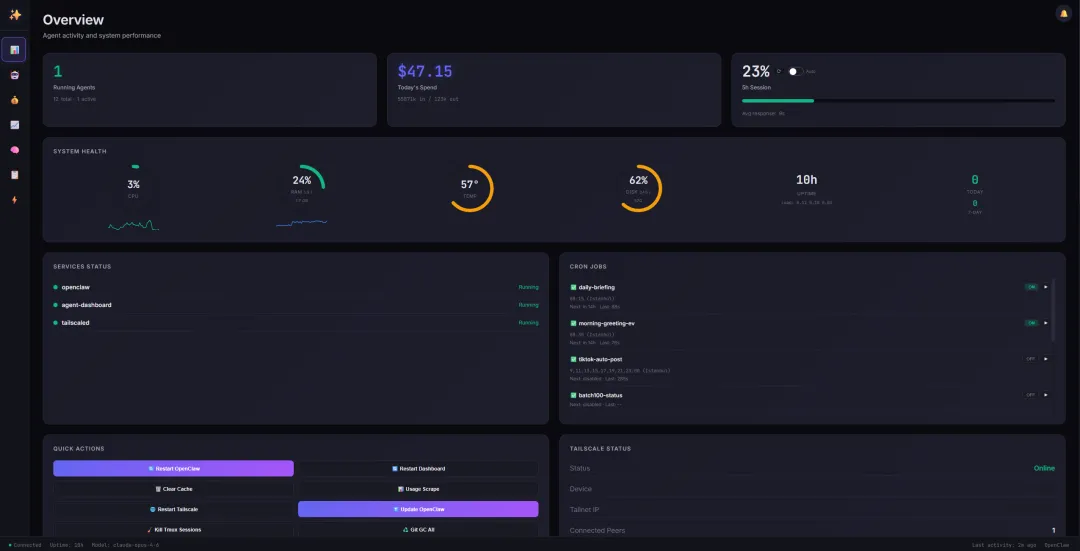
所以这个叫 OpenClaw Agent Dashboard 的开源项目火得挺合理:它把“监控”这件事做成了一个能看的网页,把你从日志地狱里拎出来。项目在 GitHub 上的自我定位很直白:面向 OpenClaw 智能体的安全、实时监控面板,主打会话追踪、用量/成本、实时消息流、内存与文件管理、系统健康等一页打通。

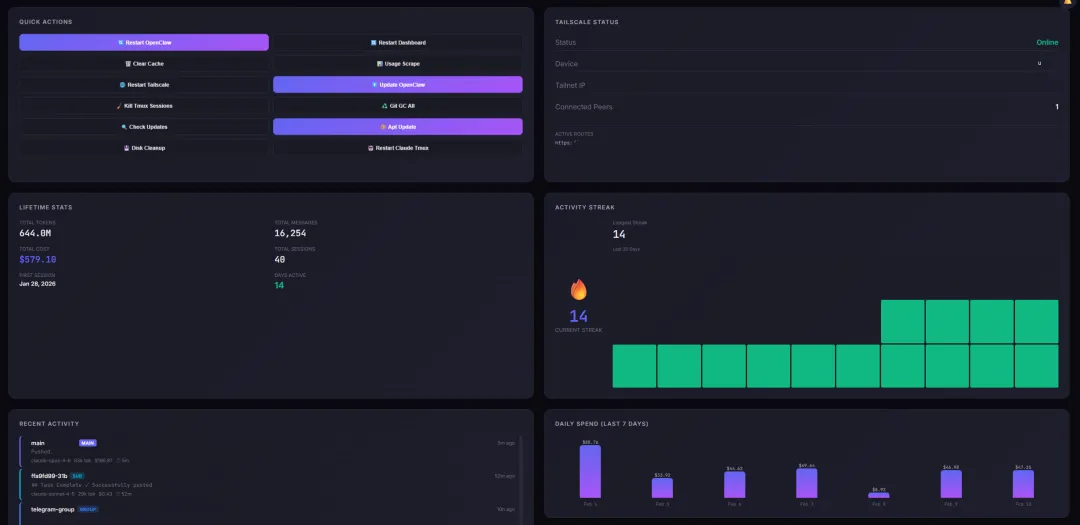
先说最戳痛点的:限额监控。它专门做了 Rate Limit Monitoring,能把 Claude 和 Gemini 的 API 使用情况按滚动窗口展示,你一眼就知道离“超限报错”还有多远——很多人跑 agent 最怕的不是慢,是跑着跑着突然被限额卡死,任务半截断电,这个页面就是救命的“仪表盘”。
再说“钱去哪了”。Dashboard 里有 成本分析(Cost Analysis),可以按模型、按会话、按时间段拆开看花费,配合 活动热力图(过去 30 天峰值时段) 和 连续活跃天数(streak),你能很快判断:到底是自己在高峰期疯狂调用,还是某个自动化/定时任务在背后“默默吞币”。
它还有个很讨喜的功能:Live Feed(实时消息流),把各个会话的消息像行情一样滚动出来。你不用再进不同目录翻来翻去,哪个 agent 正在说胡话、哪个工具调用突然开始报错,肉眼就能捕捉到异常。
如果你平时会用 OpenClaw 的记忆文件(比如 MEMORY.md、HEARTBEAT.md、daily notes),它也直接给了 Memory Viewer,甚至把工作区文件、skills、配置都做成了 Files Manager(可查看/编辑),而且 README 里明确强调做了“security hardening”——这个点很关键:能编辑文件的面板,一旦没防护,就是给自己家大门装了个“欢迎光临”。
安全机制方面,这个 Dashboard 的“用力”程度属于认真型: 它支持 用户名/密码登录,可选 TOTP 双因素认证(兼容 Google Authenticator 等),并且把 审计日志写到本地文件(例如 data/audit.log),连 HSTS、CSP、登录限速、timing-safe 对比、PBKDF2 哈希参数这些都在 README 里摊开讲。
到了 v3.0.0 还加了一个“Sys Security”页面:UFW 规则、开放端口、fail2ban、SSH 日志、OpenClaw 审计等,并且对这些敏感页面加了“重新验证(密码 + TOTP)”的门槛。
另外你说的 暗色/亮色主题也在 v3.0.0 的发布说明里明确写了:右上角一键切换,偏好用 localStorage 记住。
部署方式也挺“反潮流”:它强调 纯 Node.js、最小依赖、甚至不需要数据库和 npm 包(可选装 jq / tmux / python3 / docker 只是为了某些页面功能更完整)。
在 Linux 上它提供 install.sh,直接落成一个 systemd 服务(自动启动、崩溃恢复那套),日志就走 journalctl -u agent-dashboard -f。 同时 README 也写了 macOS 兼容,包括系统指标、服务、内存报告等。
说到底,这类项目解决的是一个很现实的“人性问题”:你可以接受 agent 偶尔犯错,但你很难接受它在后台“静悄悄地花钱、静悄悄地卡住、静悄悄地把你拖进限额墙”。OpenClaw 越像一个 24/7 的“数字同事”,你就越需要一个能随时看一眼的“工位监控”。而 OpenClaw Agent Dashboard 恰好把这件事做得够直接、够本地化、也够谨慎。
GitHub地址:tugcantopaloglu/openclaw-dashboard
