夜雨聆风
夜雨聆风





以下文章来源于微信公众号:魔方AI空间
作者:猫先生M
链接:https://mp.weixin.qq.com/s/EzBxFmgELHlQ41d_f9gxLg
本文仅用于学术分享,如有侵权,请联系后台作删文处理

本文将从底层原理、架构设计、部署方案、技能系统到实战应用全面解析OpenClaw,帮助你从理论到实践全面掌握这一强大的本地AI执行中枢。

OpenClaw 的横空出世标志着 AI 技术从 "对话工具" 向 "执行引擎" 的重大范式转变。与传统的聊天机器人不同,OpenClaw 定义为 "连接大语言模型与本地系统的执行中枢" ,打破了传统 AI"只思考、不行动" 的局限,让 AI 真正具备了操作电脑、浏览器、API 的能力,实现"思考→行动→完成"的闭环。这种"本地优先(Local-First)" 的架构设计,使得所有数据解析、任务规划、文件操作均在本地环境完成,甚至支持离线运行,为 AI 应用带来了前所未有的隐私保护和自主控制能力。
本文将从技术原理、架构设计、扩展能力、部署方案等多个维度,为开发者、技术管理者和 AI 爱好者全面解析 OpenClaw 的核心机制和应用价值。
❝核心洞察:
OpenClaw的核心价值在于将自然语言变成了新的"操作系统交互方式" ,用户只需说"帮我做",AI就会自动完成整个任务流程。
一、初识 OpenClaw
1.1 项目起源与发展历程
OpenClaw 的诞生颇具传奇色彩。Peter Steinberger 在 2021 年出售 PSPDFKit 公司获得约1.16 亿美元后,经历了 "压倒性的虚无感",为了填补内心空白,他重新投入编程创作。2025 年 11 月,Steinberger 对现有 AI 助手的功能限制和数据隐私问题感到不满,决定开发一个完全属于自己的 AI 助手。令人惊讶的是,Clawdbot 的初始原型仅用 1 小时就完成了开发,最初只是一个简单的 WhatsApp 与 Anthropic Claude 连接的转发程序。
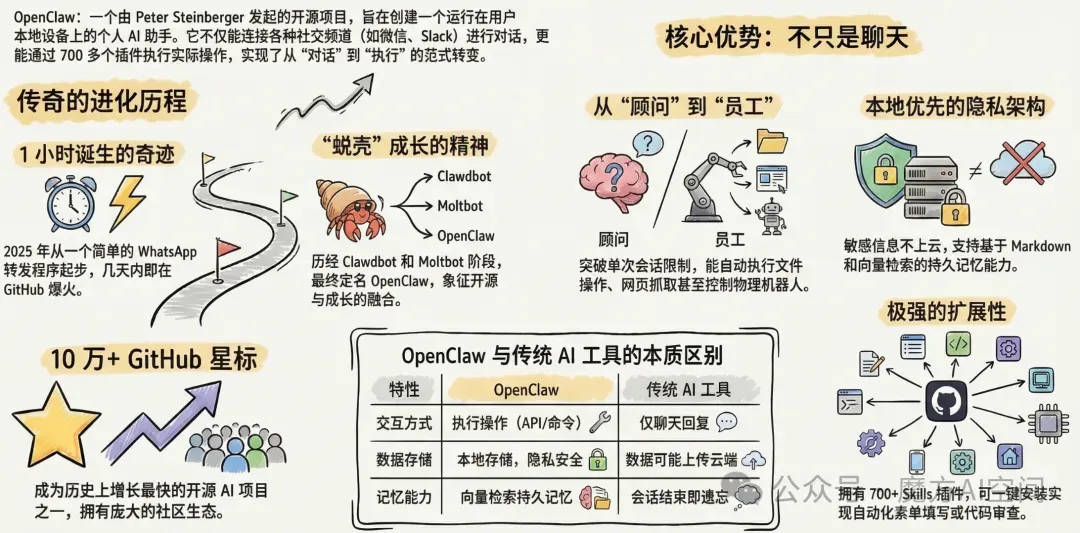
项目的发展经历了三个关键阶段:
Clawdbot 时代(2025 年 11 月):Steinberger 在一个周末开发的 "WhatsApp Relay" 小项目迅速演变成 Clawdbot,这个名称是 Claude 和 Claw 的谐音梗。项目在几天内就在 GitHub 上爆火,收获了数万颗星标。
Moltbot 阶段(2026 年 1 月 27 日):由于 Anthropic 法务团队对 "Clawdbot" 名称提出商标异议,Steinberger 在一次凌晨 5 点的 Discord 头脑风暴中将项目改名为 Moltbot。"Molting"(蜕壳)象征着成长 —— 龙虾蜕掉旧壳才能长得更大,吉祥物太空龙虾 "Molty" 也在这个阶段诞生。
OpenClaw 时代(2026 年 1 月 30 日):改名仅三天后,项目再次蜕变为 OpenClaw。这个名字完美诠释了项目精神:Open 代表开源,Claw 致敬龙虾传统。如今 OpenClaw 已拥有超过 10 万 GitHub 星标,成为历史上增长最快的开源 AI 项目之一。
1.2 核心定义与技术定位
OpenClaw 的官方定义是 "一个在用户自己设备上运行的个人 AI 助手" ,它能够在用户已使用的各种渠道(WhatsApp、Telegram、Slack、Discord、Google Chat、Signal、iMessage、微信、飞书、QQ 等)上回答用户问题,支持 macOS/iOS/Android 的语音交互,并能渲染用户控制的实时 Canvas。

从技术架构角度看,OpenClaw 采用 "网关- 节点 - 渠道" 三层架构设计,实现了智能推理、任务编排与交互渠道的解耦,形成了 "本地优先" 的 AI 代理运行环境。其核心架构可以概括为四层模型:交互层、网关层、智能体层、执行层。
与传统 AI 框架相比,OpenClaw 具有本质区别和核心优势:
| 特性 | ||
|---|---|---|
| 交互方式 | ||
| 运行模式 | ||
| 数据存储 | ||
| 记忆能力 | ||
| 扩展性 | ||
| 安全机制 |
OpenClaw 定位为 "开源个人 AI 助手与自主代理"。它不仅是一个简单的 AI 工具,更是一个完整的智能体操作系统,能够连接大语言模型与各种消息渠道,实现真正的 "智能 + 执行" 一体化。
❝核心洞察:
传统AI工具更像是一个"顾问",只提供信息或建议,而OpenClaw则是一个真正的"员工" ,能够根据你的指示自动完成各种操作任务。这种从"对话"到"执行"的转变,使得AI真正成为了生产力工具。
1.3 目标用户群体与应用场景
OpenClaw 的目标用户群体极其广泛,从初级开发者到经验丰富的 AI 工程师都能找到适合自己的使用场景。
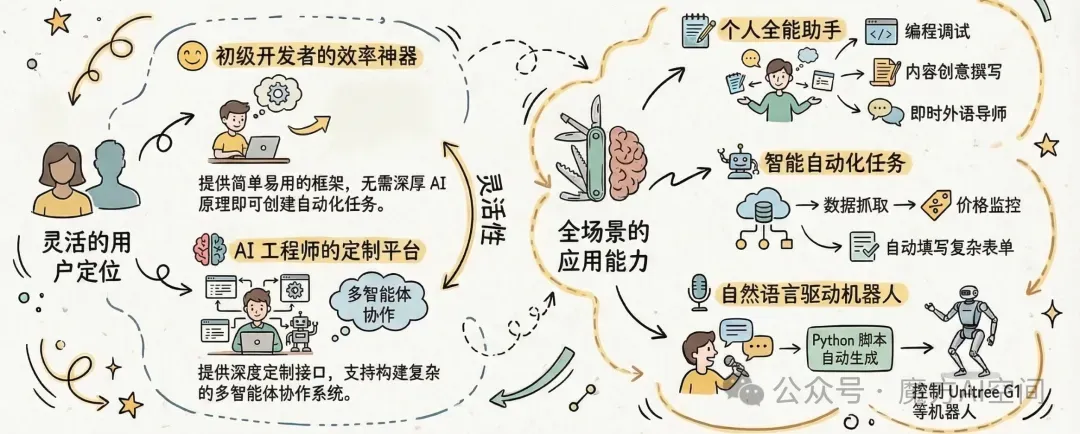
对于初级开发者而言,OpenClaw 提供了简单易用的技能开发框架,无需深入了解复杂的 AI 模型原理即可创建自动化任务。
对于有经验的 AI 工程师,OpenClaw 则提供了强大的扩展能力和深度定制接口,可以构建复杂的多智能体协作系统。
在 AI 助手开发领域,OpenClaw 展现出了强大的潜力。开发者可以将 OpenClaw 实例部署为个人编程助手,用于编写函数、调试错误、解释算法或审查代码。作家、营销人员和创作者可以使用 OpenClaw 进行内容创意和草稿撰写,而语言学习者则可以将其作为语言导师,帮助练习外语对话、获得语法修正和即时翻译。
在自动化任务场景中,OpenClaw 的应用更加广泛。浏览器自动化功能可以实现数据抓取,自动登录电商网站监控特定商品价格波动,并在降价时发送通知;表单填写功能可以自动填写复杂的报名表格、抢票脚本或每日健康打卡;信息聚合功能可以自动打开多个新闻网站,抓取头条新闻并汇总成简报。
机器人控制是 OpenClaw 的另一个重要应用领域。开源社区已经发布了针对 OpenClaw 的 Unitree G1 机器人技能包,开发者可以直接通过即时通讯软件控制机器人的运动。用户只需用自然语言描述期望的运动,OpenClaw 便会自动编写、生成并执行相应的 Python 控制脚本,完全省去了手动编写运动学代码的繁琐过程。
二、OpenClaw 核心架构与工作原理
2.1 整体架构概览
OpenClaw 的架构设计核心贴合 "本地自主、无限扩展" 的需求,采用模块化分层架构,核心基于 TypeScript 开发,同时提供 Swift 实现以支持 macOS 原生应用,跨平台适配 Windows、Linux、macOS 及树莓派、NAS等终端设备。
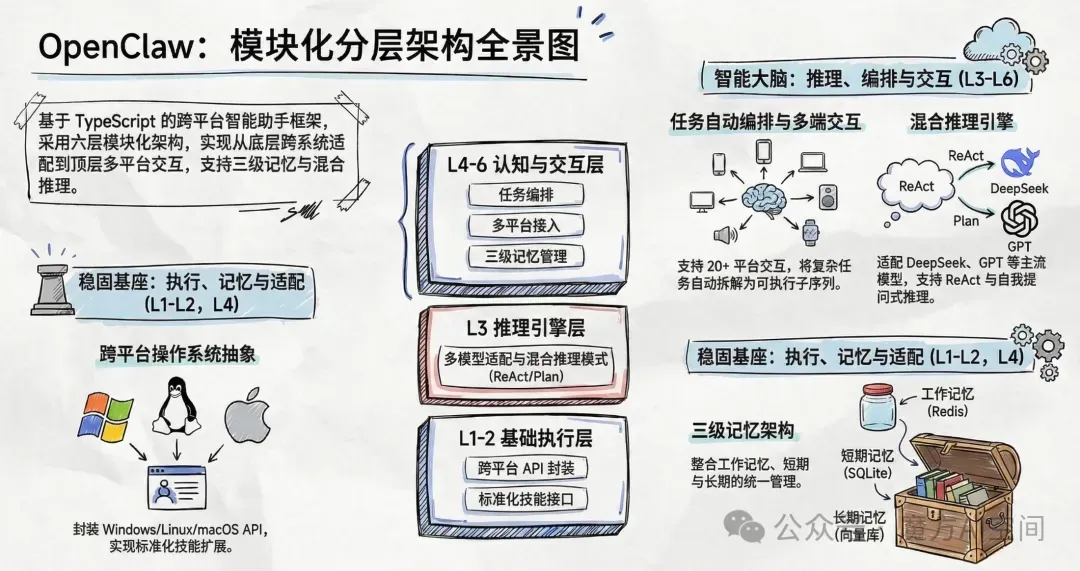
交互层(Layer 6):提供多样化的交互接口,包括 API、WebUI、即时通讯接口、语音交互等,支持 20 + 种通讯平台的无缝接入。 任务编排层(Layer 5):负责任务规划、分解和依赖管理,能够将复杂任务自动拆解为可执行的子任务序列。 记忆层(Layer 4):实现短期对话记忆和长期向量记忆的统一管理,采用三级记忆架构:工作记忆(存储在 Redis,TTL=1 小时)、短期记忆(存储在本地 SQLite)、长期记忆(存储在向量数据库)。 推理引擎层(Layer 3):支持 OpenAI、Anthropic、Google Gemini、DeepSeek、通义千问、智谱等主流模型的多模型适配器,采用混合推理模式,包括 ReAct 模式(推理 + 行动交替进行)、Plan-and-Execute(先规划再执行)、Self-Ask(自我提问式推理)。 技能执行层(Layer 2):提供原子操作、组合技能和工作流支持,通过标准化的技能接口实现功能扩展。 操作系统抽象层(Layer 1):封装 Windows、Linux、macOS 的系统 API,实现跨平台的统一接口。
2.2 核心算法架构与推理机制
OpenClaw 的核心算法架构基于"观察 - 思考 - 行动 - 检查"(Observe-Thought-Act-Check)智能体循环范式,这是其实现自主决策和执行的基础机制。整个系统的工作流程可以概括为:input→ context → model → tools → repeat → reply(输入→上下文→模型→工具→重复→回复)。
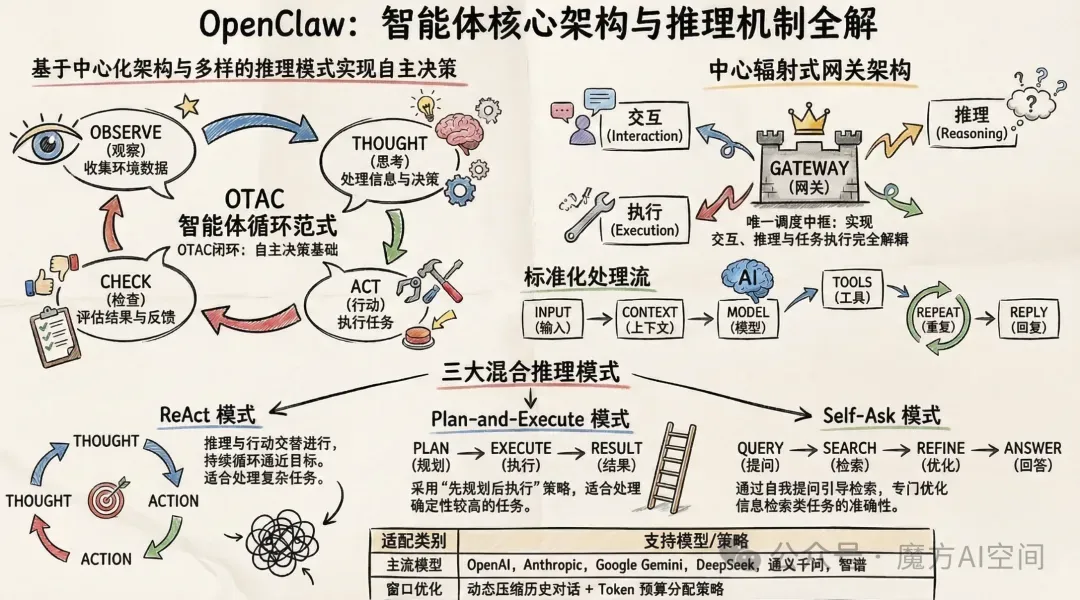
OpenClaw 采用中心辐射式架构设计,以Gateway网关为核心中枢,所有子系统均通过标准化接口与网关通信,实现了交互渠道、AI 推理、任务执行、能力扩展的完全解耦。Gateway 作为整个 OpenClaw 系统的唯一中枢和调度中心,采用单进程多线程设计,保障高并发下的低延迟与高稳定性。
在推理机制方面,OpenClaw 实现了多模型适配器,支持 OpenAI、Anthropic、Google Gemini、DeepSeek、通义千问、智谱等主流模型的统一接口调用。系统采用三种混合推理模式:
ReAct模式:推理 + 行动交替进行,适合处理复杂任务,通过不断的 "思考 - 行动 - 观察" 循环来逼近目标。 Plan-and-Execute 模式:先进行完整的任务规划,再按照规划依次执行,适合处理确定性较高的任务。 Self-Ask 模式:自我提问式推理,通过不断提出问题来引导信息检索和推理过程,特别适合信息检索类任务。
系统还实现了上下文窗口优化,采用动态压缩历史对话和 Token 预算分配策略,确保长任务不会出现上下文溢出问题。
2.3 与大语言模型的集成机制
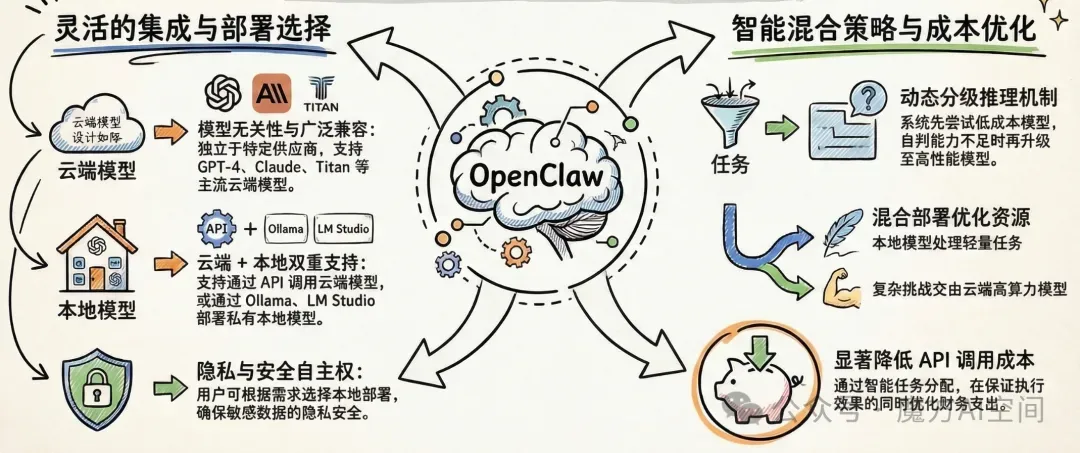
OpenClaw 的一个重要技术优势是其模型无关性,不绑定任何特定的大语言模型提供商。系统可以配置调用多种 LLM API,包括 OpenAI 的 GPT-4、Anthropic 的 Claude、Amazon 的 Titan 等。这种设计理念体现了 "让用户自主选择 AI 能力提供商" 的开放精神。
在实际运行中,OpenClaw 的推理与认知层作为智能体的 "大脑中枢" ,既支持通过 API 接入阿里云百炼、Anthropic Claude、OpenAI GPT 等云端模型,也可通过 Ollama、LM Studio 等工具接入本地模型。这种灵活的集成方式为用户提供了极大的选择自由度,既可以使用云端的高性能模型,也可以在本地部署私有模型以满足隐私和安全需求。
OpenClaw 还支持混合模型部署策略:本地模型处理轻量任务,云模型处理复杂任务,通过动态分级推理机制优化资源分配和成本控制。先用低成本模型处理任务,若自判能力不足,再升级到更强的模型,这种策略能够在保证效果的同时显著降低 API 调用成本。
2.4 工作流程详解
OpenClaw 的完整工作流程是一个精密的智能体循环(Agent Loop),包含六个核心步骤:接收→上下文组装→模型推理→工具执行→流式回复→持久化。
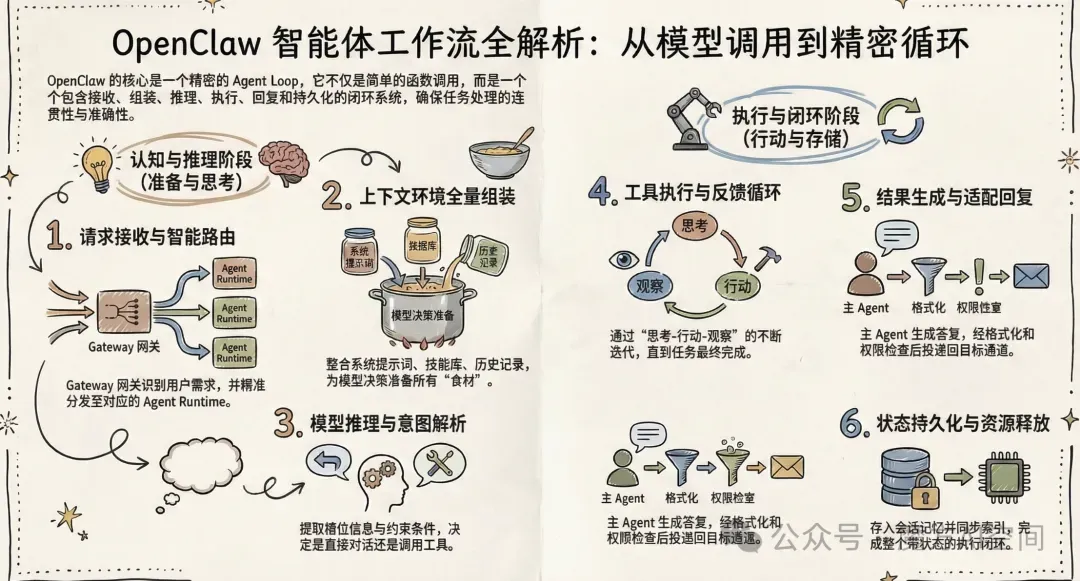
第一步:请求接收与路由
当用户发送一个请求时,首先由 Gateway 网关承接。网关就像一个智能的前台接待员,迅速识别用户需求,并准确地将需求分发给对应的 Agent Runtime,这是整个执行链条的起点。
第二步:上下文组装
系统会组装完整的上下文环境,包括系统提示词、Bootstrap 文件、Skills、历史记录和当前消息。这个过程就像厨师在烹饪前准备所有食材和工具。上下文组装的质量直接影响模型的理解和决策质量。
第三步:模型推理
大模型在技能描述和规则约束下开始推理。如果模型发现纯聊天无法解决问题,就会发出指令,调用工具来执行任务。这个过程涉及用户意图解析,OpenClaw 会提取槽位信息、约束条件和目标,并进行技能匹配与路由决策。
第四步:工具执行与反馈循环
工具执行结果返回给模型,模型继续决策下一步操作,形成循环执行过程,直到任务完成。这个循环机制是 OpenClaw 实现复杂任务处理的关键,通过不断的 "思考 - 行动 - 观察" 迭代来逼近最终目标。
第五步:结果生成与回复
主 Agent 生成最终答复,回复分发器将结果投递回目标通道。这个过程包括结果的格式化、权限检查和渠道适配。
第六步:状态持久化
会话和转录被持久化存储,记忆被更新,索引同步,资源释放,完成整个执行闭环。
整个流程体现了 OpenClaw 设计的核心价值:把 "LLM 推理" 从一次简单的函数调用,升级成了带状态、可中断、可观察、可恢复的复杂运行流程。
2.5 核心组件详解
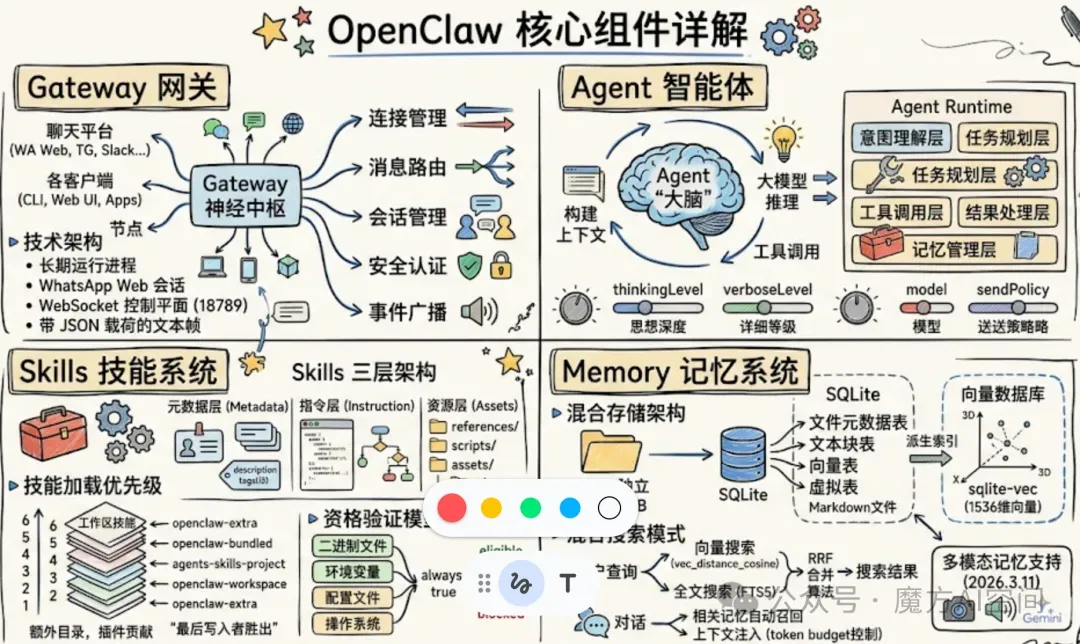
1、Gateway网关
Gateway是 OpenClaw 的神经中枢,不仅连接着各类聊天平台,更打通了智能体与外部世界交互的通道,确保指令与反馈能被实时传递。从技术角度看,Gateway 是一个长期运行的进程,负责维护单一的 WhatsApp Web 会话和其他渠道连接,提供 WebSocket 控制平面(默认端口 18789),并支持节点通过 WebSocket 连接进行通信。
Gateway采用了创新的 WebSocket 协议设计,所有客户端(CLI、Web UI、macOS 应用、iOS/Android 节点、无头节点)都通过 WebSocket 连接,并在握手时声明其角色和作用域。传输协议使用带 JSON 载荷的文本帧,第一帧必须是 connect 请求。
在功能特性上,Gateway实现了以下关键功能:
连接管理:维护与所有 Channel 和 Provider 的持久连接,确保系统的高可用性。当连接出现问题时,Gateway 会自动进行重连尝试。
消息路由:根据消息的来源、类型和目标,将消息准确路由到相应的处理模块。路由机制支持基于规则的智能路由,可以根据消息内容、发送者身份等条件进行灵活配置。
会话管理:负责创建、维护和销毁会话,确保每个用户的交互都有独立的上下文环境。会话数据包括对话历史、当前状态、配置信息等。
安全认证:实现了多层次的安全认证机制,包括客户端认证、消息签名验证、访问权限控制等。通过OPENCLAW_GATEWAY_TOKEN环境变量或命令行参数可以设置网关认证令牌。
事件广播:作为系统的事件中心,Gateway 负责广播各种系统事件,如agent、chat、presence、health、heartbeat、cron等。这些事件可以被各种客户端订阅,实现实时监控和响应。
2、Agent智能体
Agent 是 OpenClaw 的 "大脑",负责理解用户意图并协调各个组件完成任务。Agent 的核心工作流程围绕上下文构建 - 大模型推理 - 工具调用展开,所有分发的任务都在 Agent Runtime 中完成解析、推理和执行。
在技术实现上,Agent 采用了分层的架构设计:
意图理解层:负责解析用户输入的自然语言指令,识别用户的真实需求。这一层使用大语言模型进行语义理解,可以识别各种复杂的指令模式。
任务规划层:根据意图理解的结果,制定详细的执行计划。任务规划考虑了可用的工具、当前的系统状态、历史执行记录等因素,生成最优的执行路径。
工具调用层:负责调用各种工具执行具体的操作。工具调用支持同步和异步两种模式,可以处理各种复杂的操作请求。
结果处理层:处理工具执行的结果,对结果进行解析、格式化和汇总。如果执行过程中出现错误,结果处理层会进行错误分析和处理。
记忆管理层:负责维护和管理 Agent 的记忆系统。记忆包括短期记忆(当前会话的上下文)和长期记忆(历史对话、用户偏好、经验知识等)。记忆系统基于 SQLite 和向量数据库实现,支持高效的查询和检索。
Agent 还实现了灵活的配置机制,可以通过配置文件或运行时参数调整其行为。例如,可以设置思考的深度(thinkingLevel)、详细程度(verboseLevel)、使用的模型(model)、发送策略(sendPolicy)等参数。这些参数会影响 Agent 的推理过程和输出结果。
3、Skills 技能系统
Skills 是 OpenClaw 赋予智能体可重用操作知识的机制,避免了将操作知识硬编码到核心运行时逻辑中。从产品层面看,一个技能是一个能力指导单元(SKILL.md文件),教导智能体如何执行特定工作;同时也是一个门控的就绪单元,只有在所需的二进制文件、环境配置和操作系统满足条件时才可用。
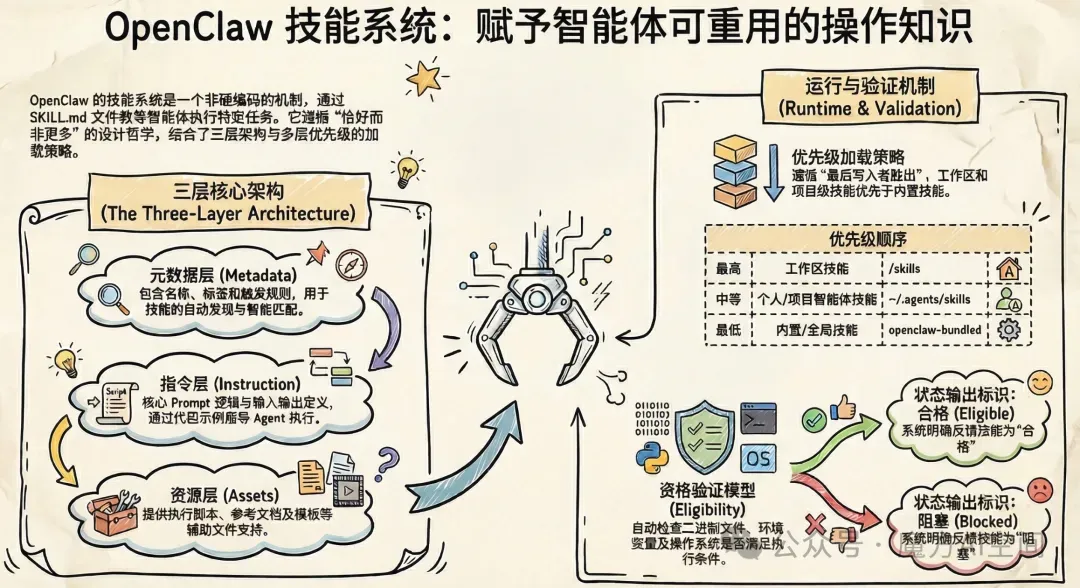
OpenClaw 的技能系统遵循 "恰好而非更多" 的设计哲学,采用三层架构:
(1)元数据层(Metadata):包含技能名称、描述、标签、触发条件与匹配规则等信息。这些元数据用于技能的发现、分类和匹配。
(2)指令层(Instruction):包含核心的 Prompt 逻辑和输入输出格式定义。这一层定义了技能的具体执行逻辑,通过自然语言描述和代码示例指导 Agent 如何执行任务。
(3)资源层(Assets):包含参考文档(references/)、执行脚本(scripts/)、模板资源(assets/)等辅助文件。这些资源为技能的执行提供必要的支持。
技能的加载机制采用了多层次的优先级策略,从低到高依次为:
skills.load.extraDirs和插件贡献的技能目录(来源:openclaw-extra)内置技能(openclaw-bundled) 管理的 / 全局本地技能(~/.openclaw/skills,来源:openclaw-managed) 个人智能体技能(~/.agents/skills,来源:agents-skills-personal) 项目智能体技能(/.agents/skills,来源:agents-skills-project) 工作区技能(/skills,来源:openclaw-workspace)
名称冲突通过 "最后写入者胜出" 的原则解决。这种设计既保证了系统的灵活性,又确保了用户自定义技能的优先级。
技能的资格验证模型不仅检查技能是否已安装,还会在每次加载时计算以下条件:
技能级别的禁用状态( skills.entries.<skillKey>.enabled === false)内置技能的允许列表( skills.allowBundled)运行时要求:包括必需的二进制文件( requires.bins)、可选的二进制文件(requires.anyBins)、环境变量(requires.env)、配置文件(requires.config)、操作系统要求(os)always: true标记可以短路需求检查
状态输出会携带eligible(合格)或blocked(阻塞)状态,以及结构化的missing原因和配置检查结果。
4、Memory 记忆系统
Memory 是 OpenClaw 的记忆管理系统,负责将所有对话与偏好以真实文件的形式持久化保存。记忆系统采用了创新的混合存储架构,结合了关系型数据库和向量数据库的优势。
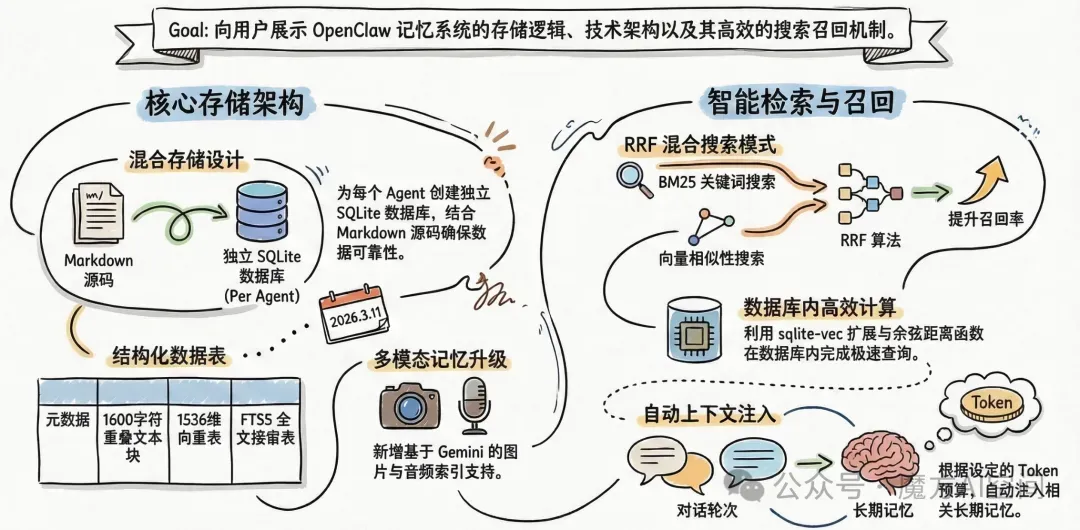
在存储架构设计上,OpenClaw 为每个 Agent 创建独立的 SQLite 数据库,位于~/.openclaw/memory/{agentId}.sqlite。
数据库包含以下核心表:
文件元数据表:记录文件的基本信息,包括 ID、修改时间(用于增量索引)等 文本块表:存储从 Markdown 文件切分后的文本块,每个块约 1600 字符,相邻块之间有 320 字符的重叠,防止语义被截断 向量表:使用 sqlite-vec 扩展存储文本块的向量表示,向量维度为 1536 虚拟表:用于全文搜索(FTS5),支持关键词索引
这种设计的核心优势在于:Markdown 文件作为真实数据源,SQLite 作为派生索引,确保了数据的可靠性和可维护性。
记忆系统支持混合搜索模式,结合了 BM25 关键词搜索和向量相似性搜索的优势。查询时,系统会同时使用两种索引,通过 RRF(Reciprocal Rank Fusion)算法合并结果,提高搜索的准确性和召回率。
在技术实现上,OpenClaw 使用 sqlite-vec 扩展进行数据库内向量相似性查询。查询语句被嵌入为向量后,通过vec_distance_cosine()函数在数据库内计算余弦距离,大大提高了查询效率。
记忆系统还实现了自动召回功能,可以在每个对话轮次自动将相关记忆注入到上下文中。注入的记忆数量可以通过配置参数(token budget)进行控制,确保不会超出模型的上下文限制。
在 OpenClaw(2026.3.11)版本中开始支持多模态记忆,新增了基于 Gemini 的图片、音频索引支持。这意味着记忆系统不再只关注文字,而是向 "更像真正长期记忆" 的方向升级。
三、Skills 技能系统深度剖析
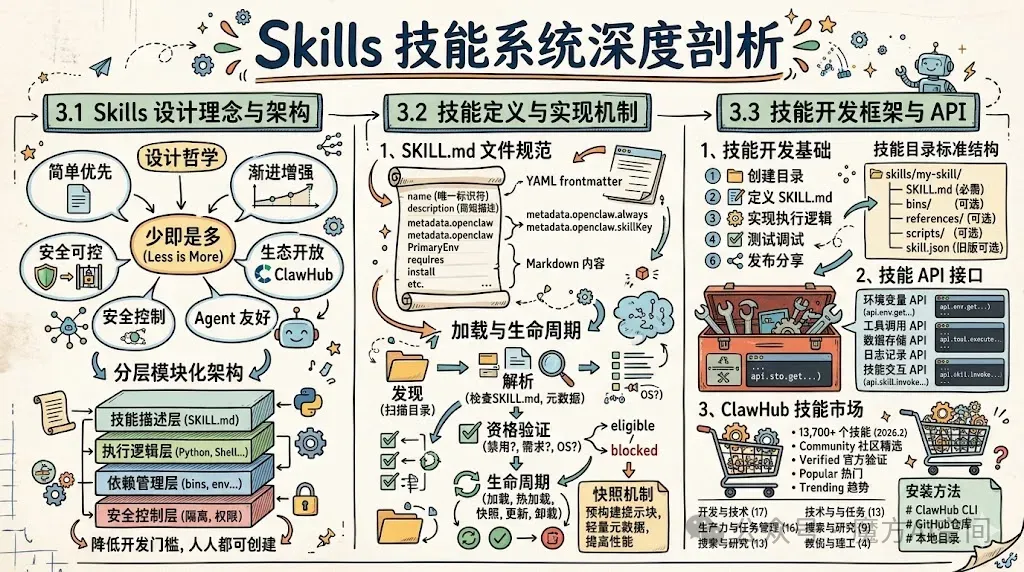
3.1 Skills 设计理念与架构
OpenClaw 的 Skills 系统体现了 "少即是多"(Less is More)的设计哲学。系统设计遵循五个核心原则:简单优先(一个文件就是一个技能)、渐进增强(从最简单的开始,需要时再加 metadata)、安全可控(gating 机制防止无效加载)、生态开放(ClawHub 让技能可共享、可版本化)、Agent 友好(description 帮助 Agent 正确判断何时使用)。
这种设计理念的核心在于降低技能开发的门槛,让任何人都能轻松创建和分享技能。技能的基本单位是一个包含 SKILL.md 文件的目录,这种简单的结构既保持了灵活性,又确保了可扩展性。
在架构设计上,Skills 系统采用了分层模块化的设计:
技能描述层:通过 SKILL.md 文件定义技能的基本信息、触发条件、执行逻辑等。这一层使用简单的 Markdown 格式,既易于人类阅读,又方便机器解析。
执行逻辑层:包含实际的执行代码,可以是 Python 脚本、Shell 脚本、Node.js 模块等。执行逻辑与描述层分离,提高了代码的可重用性和可维护性。
依赖管理层:处理技能的各种依赖关系,包括二进制文件、环境变量、配置文件等。依赖管理确保技能在不同的环境中都能正确运行。
安全控制层:实现了严格的安全控制机制,包括执行环境隔离、权限控制、输入验证等,确保技能执行的安全性。
3.2 技能定义与实现机制
1、SKILL.md文件规范
SKILL.md 是技能的核心定义文件,采用 YAML 前置元数据(frontmatter)加 Markdown 内容的格式。最低要求的元数据包括:
name:技能的唯一标识符,必须与技能目录名一致 description:技能的简短描述,帮助 Agent 理解技能的用途
OpenClaw 扩展的重要可选字段包括:
metadata.openclaw.always:设置为 true 可以短路需求检查,始终认为技能可用 metadata.openclaw.skillKey:技能的键名,用于在配置中引用 metadata.openclaw.primaryEnv:主环境变量名,用于 API 密钥配置 metadata.openclaw.os:支持的操作系统列表 metadata.openclaw.requires:运行时需求,包括 bins(必需的二进制文件)、anyBins(至少一个二进制文件)、env(环境变量)、config(配置文件) metadata.openclaw.install:安装步骤列表 user-invocable:是否允许用户直接调用 disable-model-invocation:是否禁用模型调用 command-dispatch、command-tool、command-arg-mode:命令调度相关配置
在运行时,这些定义会被解析为标准化的SkillEntry对象,包含原始技能信息、解析后的前置元数据、解析后的 OpenClaw 元数据、调用策略标志等。
以下是一个简单的天气查询技能示例:
name:weatherdescription:查询指定城市的天气信息metadata:openclaw:emoji:"⛅"requires:env:["OPENWEATHERMAP_API_KEY"]primaryEnv:"OPENWEATHERMAP_API_KEY"user-invocable:true2、技能加载与生命周期
技能的加载过程涉及多个阶段和复杂的优先级处理机制:
发现阶段:系统会扫描所有配置的技能目录,包括:
全局技能目录(~/.openclaw/skills) 工作区技能目录(/skills) 个人智能体技能目录(~/.agents/skills) 项目智能体技能目录(/.agents/skills) 插件贡献的技能目录 内置技能目录
解析阶段:对发现的每个技能目录,系统会:
检查是否存在 SKILL.md 文件 解析 YAML 前置元数据 验证元数据的完整性和正确性 解析 OpenClaw 扩展的元数据 计算技能的资格状态
资格验证阶段:技能的资格验证不仅检查是否已安装,还会动态计算:
技能是否被禁用 运行时需求是否满足 操作系统兼容性 依赖的二进制文件是否存在 环境变量是否配置
资格验证的结果会包含在技能的状态信息中,包括eligible(合格)或blocked(阻塞)状态,以及结构化的missing原因。
生命周期管理包括:
加载:技能在启动时加载,支持热加载(通过文件监听实现) 快照:技能会被快照到会话状态中,避免每次轮次都重新扫描 更新:当技能文件发生变化时,会触发重新加载 卸载:可以通过配置禁用或删除技能
技能的快照包含预构建的提示块、轻量级技能元数据(名称、主环境变量、必需的环境变量名)、标准化的技能过滤器、解析后的技能列表和版本信息。快照机制大大提高了系统的性能,避免了重复的扫描和解析操作。
3.3 技能开发框架与 API
OpenClaw 提供了完整的技能开发框架,支持多种编程语言和开发模式。
1、技能开发基础
技能开发的基本步骤包括:
创建技能目录:在合适的技能目录下创建新目录,目录名必须与技能名一致
mkdir -p ~/.openclaw/workspace/skills/hello-world定义 SKILL.md文件:在技能目录中创建SKILL.md文件,定义技能的基本信息和执行逻辑实现执行逻辑:根据技能类型,编写相应的执行代码 测试与调试:使用 OpenClaw CLI 或 API 测试技能功能 发布与分享:将技能发布到 ClawHub 或 GitHub 供他人使用
技能目录的标准结构如下:
skills/└── my-awesome-skill/ ├── SKILL.md # 必需:YAML元数据 + Markdown操作指南 ├── bins/ # 可选:可执行文件(自动加入PATH) ├── references/ # 可选:参考文档(PDF、TXT等) ├── scripts/ # 可选:辅助脚本(Python、Bash、JS等) └── skill.json # 可选:旧版元数据格式(兼容用)2、技能 API 接口
OpenClaw 为技能开发提供了丰富的 API 接口:
环境变量 API:
api.env.get(key):获取环境变量值api.env.set(key, value):设置环境变量值api.env.has(key):检查环境变量是否存在
工具调用 API:
api.tool.execute(command, args, options):执行系统命令api.tool.browser(url, options):控制浏览器访问指定 URLapi.tool.http(method, url, options):发送 HTTP 请求api.tool.file.read(path):读取文件内容api.tool.file.write(path, content):写入文件内容
数据存储 API:
api.storage.get(key):获取存储的值api.storage.set(key, value):设置存储的值api.storage.delete(key):删除存储的值api.storage.list():列出所有存储的键
日志记录 API:
api.log.debug(message):记录调试信息api.log.info``(message):记录一般信息api.log.warn(message):记录警告信息api.log.error(message):记录错误信息
技能交互 API:
api.skill.invoke(skillName, params):调用其他技能api.skill.get(skillName):获取技能信息api.skill.list():列出所有技能
以下是一个使用 API 的完整技能示例(天气查询):
// 技能入口文件(通常是index.js或skill.js)module.exports = {name: "weather",description: "查询指定城市的天气信息",async execute(params) {const city = params.city || "Beijing";const apiKey = this.env.get("OPENWEATHERMAP_API_KEY");if (!apiKey) {thrownewError("OpenWeatherMap API key is required"); }const url = `https://api.openweathermap.org/data/2.5/weather?q=${city}&appid=${apiKey}&units=metric`;try {const response = awaitthis.http.get(url);const weatherData = response.data;return`当前 ${city}的天气:${weatherData.weather[0].description},温度:${weatherData.main.temp}°C`; } catch (error) {this.log.error(`天气查询失败:${error.message}`);throw error; } }};3、ClawHub 技能市场
ClawHub[1] 是 OpenClaw 官方的技能市场,被社区戏称为 "数字劳动力超市"。截至 2026 年 2 月,ClawHub 已收录超过 13,700 个社区贡献的技能,其中社区精选列表中的高质量 Skill 约 6000 多个,覆盖从日常办公到专业创作的各个领域。
ClawHub 的技能分类体系包括:
开发与技术(17 个技能):代码审查、Git 操作、API 测试等 生产力与任务管理(16 个技能):待办事项、日程安排、文件管理等 搜索与研究(13 个技能):网页搜索、学术搜索、信息聚合等 内容创作:文章撰写、翻译、设计辅助等 数据分析:数据提取、报表生成、可视化等 社交媒体:Twitter、LinkedIn、小红书等平台操作
技能的质量评级体系:
Community(社区精选):高下载量 + 高评分,社区认可,约占比 15% Verified(官方验证):经过 OpenClaw 团队审核的技能 Popular(热门):下载量高的技能 Trending(趋势):近期增长快速的技能
用户可以通过以下方式安装技能:
# 使用ClawHub CLI安装clawhub install weather# 从GitHub仓库安装openclaw skill install https://github.com/openclaw/skills.git#weather# 从本地目录安装openclaw skill install /path/to/skill/directory四、OpenClaw的部署方案
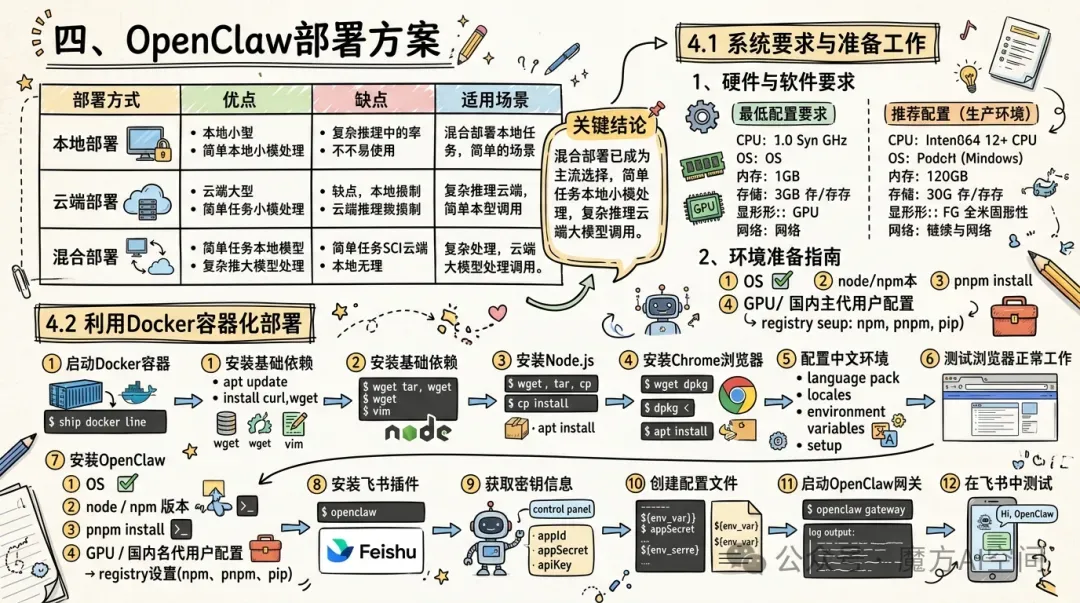
OpenClaw提供多种部署方式,主要分为三类:
| 部署方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 本地部署 | |||
| 云端部署 | |||
| 混合部署 |
❝关键结论 (Key Takeaway)
混合部署已成为主流选择,简单任务由本地小模型处理,保护隐私;复杂推理调用云端大模型,保证能力。
4.1 系统要求与准备工作
1、硬件与软件要求
最低配置要求:
操作系统:Windows 10 21H2+(64 位)、macOS 12+、Linux(Ubuntu 20.04+/Debian 11+/CentOS 8+) 处理器:Intel i3 或 AMD 同等性能处理器 内存:最低 2GB,推荐 4GB 以上 存储空间:500MB 以上,推荐 100GB+ SSD 网络:稳定的互联网连接(用于云模型)
推荐配置(生产环境):
操作系统:Windows 11 22H2 + 或 Ubuntu 22.04+ 处理器:Intel i5/Ryzen 5 及以上 内存:建议≥16GB 显卡(可选但强烈推荐):NVIDIA 显卡(显存≥8GB 可流畅运行 7B~14B 模型) 网络:高速稳定的互联网连接
软件依赖:
Node.js:必须版本≥22.0.0,推荐 v24 LTS 版本 Python:部分技能需要 Python 3.9-3.11 版本 Docker:容器化部署需要 Docker≥20.10.0 其他依赖:根据具体技能需求可能需要额外的系统工具
2、环境准备指南
在开始部署前,需要完成以下准备工作:
系统环境检查:
(1)检查操作系统版本:确保满足最低要求
(2)验证 Node.js:
node --versionnpm --version包管理工具配置:
OpenClaw 支持 npm、pnpm 和 bun 三种包管理工具。推荐使用 pnpm,因为它在处理依赖和构建方面更高效:
npm install -g pnpm硬件加速配置(可选):
如果有 NVIDIA 显卡,可以配置硬件加速以提高模型推理速度:
(1)安装 NVIDIA 驱动
(2)安装 CUDA Toolkit
(3)安装 cuDNN
(4)配置环境变量
国内用户特殊配置:
由于网络原因,国内用户可能需要配置镜像:
# 设置npm镜像npm config set registry https://registry.npmmirror.com# 设置pnpm镜像pnpm config set registry https://registry.npmmirror.com# 设置Python pip镜像pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple4.2 利用Docker容器化部署
❝通过Docker部署可以快速搭建环境并运行,同时保证宿主机的安全和干净。
一键快速部署,请参考:
https://github.com/AI-mzq/From-Zero-to-AGI/tree/master/10_项目实战/From-Zero-to-OpenClaw
1、启动Docker容器
docker run -dit --name openclaw_dev --net=host --tmpfs /tmp --tmpfs /run --tmpfs /run/lock -v /sys/fs/cgroup:/sys/fs/cgroup:rw -v $PWD:/home -w /home --cgroupns=host -e container=docker -e DEBIAN_FRONTEND=noninteractive -e TZ=Asia/Shanghai ubuntu:24.042、安装基础依赖
# 进入容器终端docker exec -ti openclaw_docker bash# 更新软件源并安装常用工具apt updateapt install curl wget vim -yapt install xz-utils -y3、安装Node.js
# 下载并解压Node.jswget -O node-v24.13.0-linux-x64.tar.xz https://nodejs.org/dist/v24.13.0/node-v24.13.0-linux-x64.tar.xztar -xf node-v24.13.0-linux-x64.tar.xzcp node-v24.13.0-linux-x64/* /usr/local/ -rf# 验证安装node --version4、安装Chrome浏览器
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.debdpkg -i google-chrome-stable_current_amd64.debapt --fix-broken install -y # 修复可能的依赖问题5、配置中文环境
# 安装中文字体和语言包apt-get install -y locales fonts-wqy-zenhei language-pack-zh-hans -y# 生成中文locale并设置环境变量locale-gen zh_CN.UTF-8locale-gen zh_CN.GBKecho"export LANG=zh_CN.UTF-8" >> ~/.bashrcecho"export LANGUAGE=zh_CN:zh" >> ~/.bashrcsource ~/.bashrc6、测试浏览器是否正常工作
/usr/bin/google-chrome-stable --headless --disable-gpu --no-sandbox --screenshot="screenshot.png" --window-size=1920,1080 https://www.baidu.com如果运行成功,当前目录下会生成 screenshot.png 图片。
7、安装OpenClaw
curl -fsSL https://openclaw.bot/install.sh | bash当看到 “Starting setup…” 提示时,按 Ctrl+C 取消初始配置向导,将会手动创建配置文件。
8、安装飞书插件
openclaw plugins install @openclaw/feishu || true9、获取必要的密钥信息
飞书机器人:参考 如何接入飞书[2] 创建机器人,获取 appId和appSecret。火山引擎API Key:进入 火山引擎控制台[3] 开通Doubao模型权限并获取API Key。
10、创建配置文件
将以下命令中的 feishu_appId、feishu_appSecret、doubao_apiKey 替换为你自己的值,然后执行:
# 设置环境变量(请替换为你的实际密钥)export feishu_appId="<你的飞书appId>"export feishu_appSecret="<你的飞书appSecret>"export doubao_apiKey="<你的火山引擎API Key>"# 生成OpenClaw配置文件cat > ~/.openclaw/openclaw.json << EOF{"meta": {"lastTouchedVersion": "2026.3.1-3","lastTouchedAt": "2026-03-01T07:21:25.150Z" },"wizard": {"lastRunAt": "2026-03-01T07:21:25.140Z","lastRunVersion": "2026.3.1-3","lastRunCommand": "configure","lastRunMode": "local" },"browser": {"enabled": true,"executablePath": "/usr/bin/google-chrome-stable","headless": true,"noSandbox": true,"defaultProfile": "desktop","profiles": {"desktop": { "cdpUrl": "http://127.0.0.1:9222", "color": "#00AA00" }} },"auth": {"profiles": {"doubao:default": { "provider": "doubao", "mode": "api_key" } } },"models": {"providers": {"doubao": {"baseUrl": "https://ark.cn-beijing.volces.com/api/v3","apiKey": "${DOUBAO_API_KEY}","api": "openai-completions","models": [ {"id": "doubao-seed-1-8-251228","name": "doubao-seed-1-8-251228","reasoning": false,"input": ["text"],"cost": {"input": 0,"output": 0,"cacheRead": 0,"cacheWrite": 0},"contextWindow": 128000,"maxTokens": 8192 } ] } } },"agents": {"defaults": {"model": {"primary": "doubao/doubao-seed-1-8-251228" },"models": {"doubao/doubao-seed-1-8-251228": { "alias": "doubao" } },"workspace": "/root/.openclaw/workspace","compaction": {"mode": "safeguard" },"maxConcurrent": 4,"subagents": {"maxConcurrent": 8} } },"messages": {"ackReactionScope": "group-mentions" },"commands": {"native": "auto","nativeSkills": "auto","restart": true },"channels": {"feishu": {"enabled": true,"appId": "${FEISHU_APP_ID}","appSecret": "${FEISHU_APP_SECRET}","domain": "feishu","groupPolicy": "open","dmPolicy": "open","allowFrom": ["*"] } },"gateway": {"port": 18789,"mode": "local","bind": "loopback","controlUi": {"allowInsecureAuth": true},"auth": {"mode": "token","token": "${GATEWAY_TOKEN}" },"tailscale": {"mode": "off","resetOnExit": false } },"plugins": {"entries": {"feishu": {"enabled": true } },"installs": {"feishu": {"source": "npm","spec": "@openclaw/feishu","installPath": "/root/.openclaw/extensions/feishu","version": "0.1.7","installedAt": "2026-03-08T06:22:56.392Z" } } }}EOF11、启动OpenClaw网关
openclaw gateway如果一切正常,你会看到网关启动成功的日志信息。
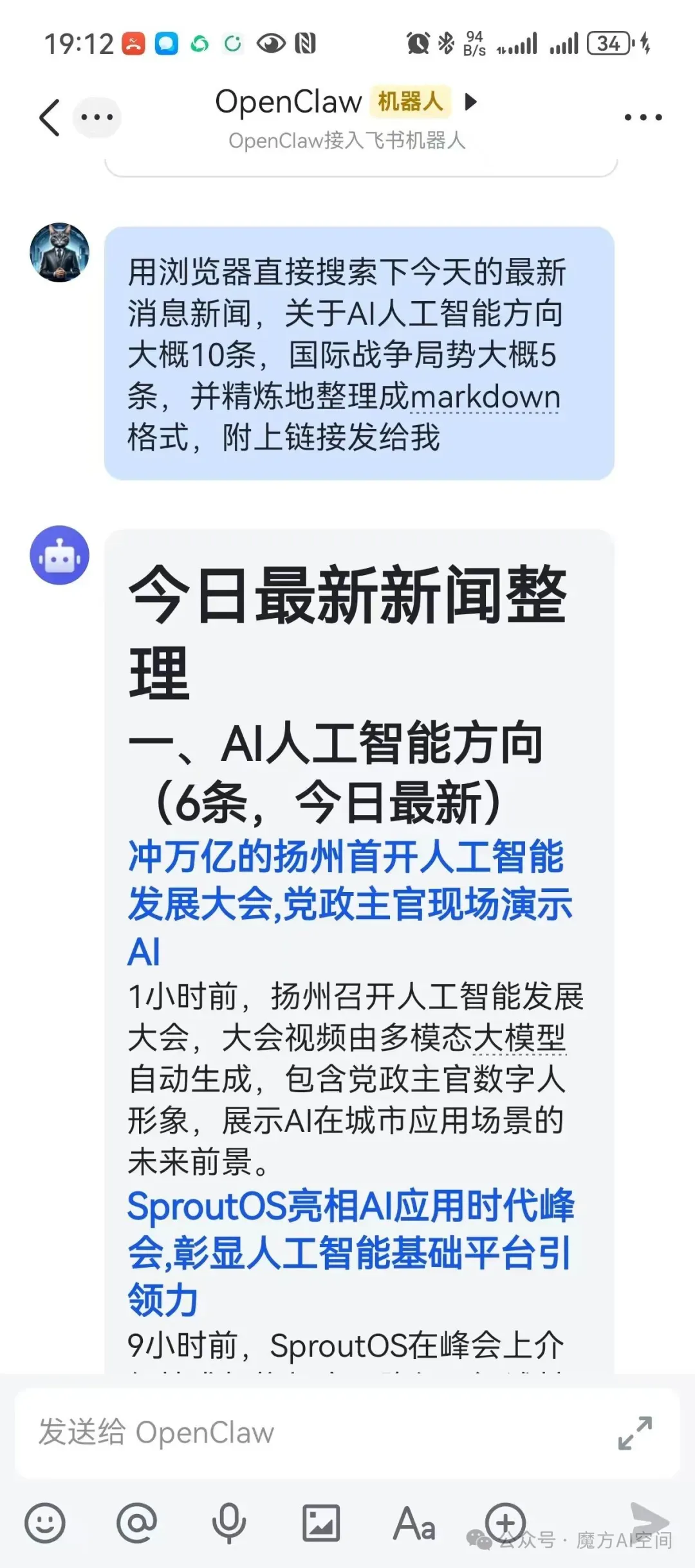
12、在飞书中测试
打开手机飞书APP,找到你创建的机器人,开始对话。
五、局限性分析与未来展望
OpenClaw 虽然在 AI 智能体领域取得了巨大成功,但仍面临诸多技术约束和挑战。
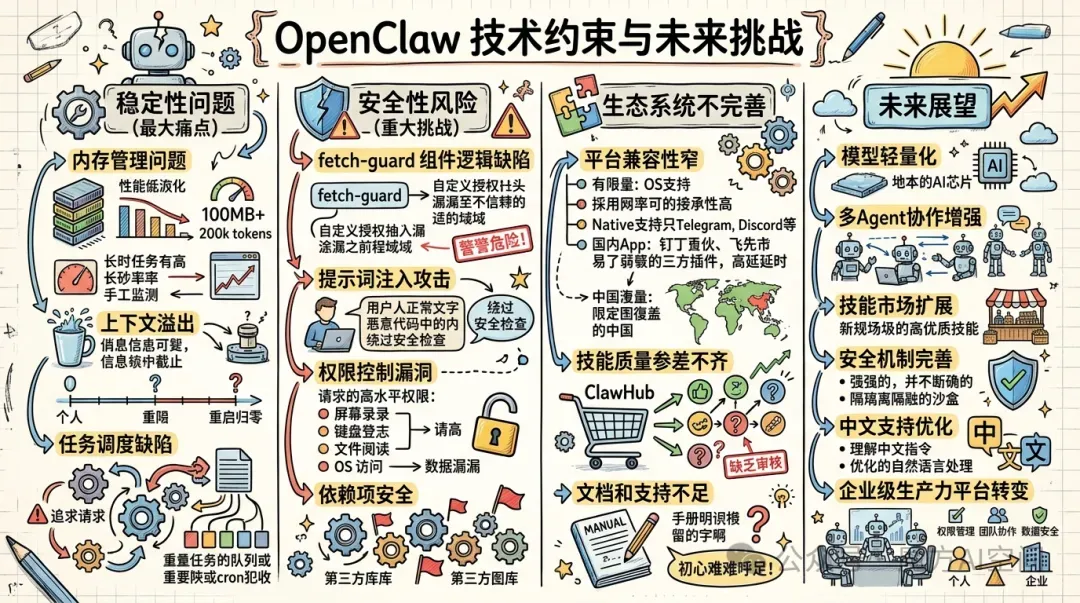
稳定性问题是 OpenClaw 面临的最大痛点之一。根据用户反馈,系统在处理长任务和复杂任务时崩盘率极高,根本无法实现 "无需人工干预" 的目标,反而需要全程监控和手动干预,有时甚至比自己动手还累。这种不稳定性主要源于以下几个方面:
内存管理问题:原始 Node.js 版本在规模化后暴露了严重的性能瓶颈,典型实例内存占用 100MB 以上,启动时间约 6 秒,且在处理 20 万 token 后性能急剧衰减,难以在低成本硬件上稳定运行。 上下文溢出:长期运行(24/7)会导致上下文溢出、早期信息截断、性能衰减及重启归零等问题。这严重影响了需要长期记忆的复杂任务执行。 任务调度缺陷:系统在任务调度方面存在明显不足,长运行任务可能阻塞或减慢请求处理,对重试、退避策略和故障恢复的控制有限,延迟作业和基于 cron 的任务没有通过专用队列系统管理。
安全性风险是另一个重大挑战。OpenClaw 的 fetch-guard 组件存在逻辑缺陷,在跨域重定向过程中,会将自定义的授权请求头直接转发至重定向目标地址,导致授权凭证泄露至非可信域名。此外,系统还面临以下安全威胁:
提示词注入攻击:攻击者可以通过精心构造的输入绕过安全检查,执行恶意代码。开发者 Peter Steinberger 本人也承认,当前系统仍无法完全防御 " 提示注入攻击"。 权限控制漏洞:由于 OpenClaw 需要获取用户设备的高权限,包括接管屏幕录制、键盘记录、文件读取甚至底层操作系统权限,一旦被恶意利用,可能导致严重的数据泄露和系统损害。 依赖项安全:系统依赖大量第三方库和工具,这些依赖项可能存在安全漏洞,增加了整体系统的安全风险。
生态系统不完善也制约了 OpenClaw 的发展:
平台兼容性:目前 OpenClaw 的系统适配范围较窄,存在明显的平台壁垒,适配情况不均衡,严重制约了用户覆盖范围与规模化应用。特别是在国内市场,原生只支持 Telegram、Discord 等海外软件,对接钉钉、飞书全靠第三方插件,不仅延迟高、容易掉线,还可能存在账号安全风险。 技能质量参差不齐:虽然 ClawHub 上有超过 13,700 个技能,但质量良莠不齐,缺乏统一的质量标准和审核机制。用户很难快速找到可靠、高效的技能。 文档和支持不足:尽管有官方文档,但对于复杂场景的指导仍然不够详细,新手用户往往需要花费大量时间摸索。
成本控制困难:
模型调用费用:OpenClaw 本身是 "空壳",需要接入付费大模型,且默认的 "心跳机制" 即使无任务也会消耗费用,导致使用成本难以控制。 硬件要求高:要流畅运行 OpenClaw,特别是使用大型模型时,需要较高配置的硬件,这增加了部署成本。 维护成本:系统更新频繁,常有不兼容更新,维护成本极高。
未来展望
OpenClaw的未来发展可能集中在以下几个方向:
模型轻量化:开发本地运行的轻量级模型,减少对云端API的依赖 多Agent协作增强:改进Agent间的通信和协作机制,支持更复杂的团队任务 技能市场扩展:增加更多高质量的Skill插件,覆盖更广泛的应用场景 安全机制完善:进一步强化权限管理和沙箱隔离,提高系统安全性 中文支持优化:针对中文语境进行专门优化,提高对中文指令的理解能力
OpenClaw的定位正在从个人效率工具向企业级生产力平台转变,未来可能会看到更多针对企业场景的优化和扩展,如更完善的权限管理、团队协作功能和数据安全机制。
写在最后
OpenClaw作为2026年最热门的AI智能体执行引擎之一,代表着AI从"对话"到"执行"的重要转变。它通过三层架构设计(网关层、Agent层、节点层)实现了自然语言到实际操作的闭环,支持多种部署方式(本地、云端、混合)以满足不同用户需求,并通过庞大的Skills系统不断扩展能力边界。
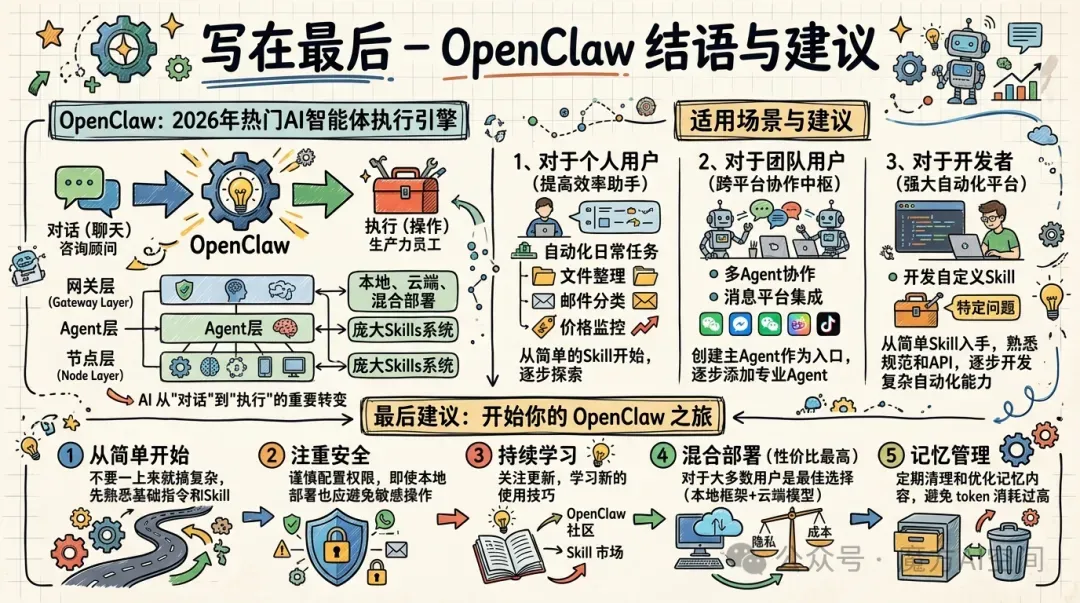
(1)对于个人用户,OpenClaw可以成为提高工作效率的得力助手,通过自动化处理日常任务(如文件整理、邮件分类、价格监控)节省大量时间。建议从简单的Skill开始,逐步探索更复杂的自动化流程。
(2)对于团队用户,OpenClaw可以作为跨平台协作的智能中枢,通过多Agent协作和消息平台集成,提高团队协作效率。建议首先创建主Agent作为入口,然后根据团队需求逐步添加专业Agent。
(3)对于开发者,OpenClaw提供了一个强大的自动化平台,可以开发自定义Skill解决特定问题。建议从简单Skill入手,熟悉开发规范和API,然后逐步开发更复杂的自动化能力。
最后建议:
从简单开始:不要一开始就尝试复杂的自动化流程,先熟悉基础指令和Skill 注重安全:即使使用本地部署,也应谨慎配置权限,避免敏感操作 持续学习:关注OpenClaw社区和Skill市场更新,不断学习新的使用技巧 混合部署:对于大多数用户,混合部署(本地框架+云端模型)是性价比最高的选择 记忆管理:定期清理和优化记忆内容,避免token消耗过高
江大白,安生智联(无锡)联合创始人。
深耕企业安全管理+AI领域,通过“技术+商业+内容”的融合视角,深度参与AI产业化落地。
全网20W+粉丝AI知识博主,人工智能技术文章超1000W+阅读,《30天入门人工智能》课程,全网2000+名学员。
主导构建的AI知识平台www.jiangdabai.com累计访问已超800万次;
思想阵地(深度洞察):知乎、CSDN @江大白
内容阵地(视频解读):抖音、快手、小红书 @江大白讲AI
实战阵地(产品纪实):抖音、快手、小红书 @安生江大白 | 记录“1年10个AI产品100个项目应用”的极限挑战

大家一起加油!