 夜雨聆风
夜雨聆风凉拌,现在用OpenClaw无论如何是要花一些钱的。
至少要消耗Tokens,要买AI套餐或者API服务,如果不买Tokens,那就要买硬件自己部署模型,都要花钱。
但是,OpenClaw实在太消耗Tokens了,换了谁都希望省一点。

先说方案——用QMD!立减80%!
优化的关键,是抓住大头,在细枝末节上节省收效甚微。
OpenClaw这只小龙虾🦞之所以这么能吃Tokens,大头是啥?
大头就是OpenClaw的Memory管理实在差点意思,倒不是想法有问题,而是实现有问题,倒是Context里塞了太多Memory。
OpenClaw的基本想法是:
使用Markdown文本来记录所有对话内容,作为Memory 对Memory做索引(OpenClaw用的SqlLite,我认为是最大的败笔) 每轮对话,搜索相关的Memory放在Context里 必要的时候,压缩Memory
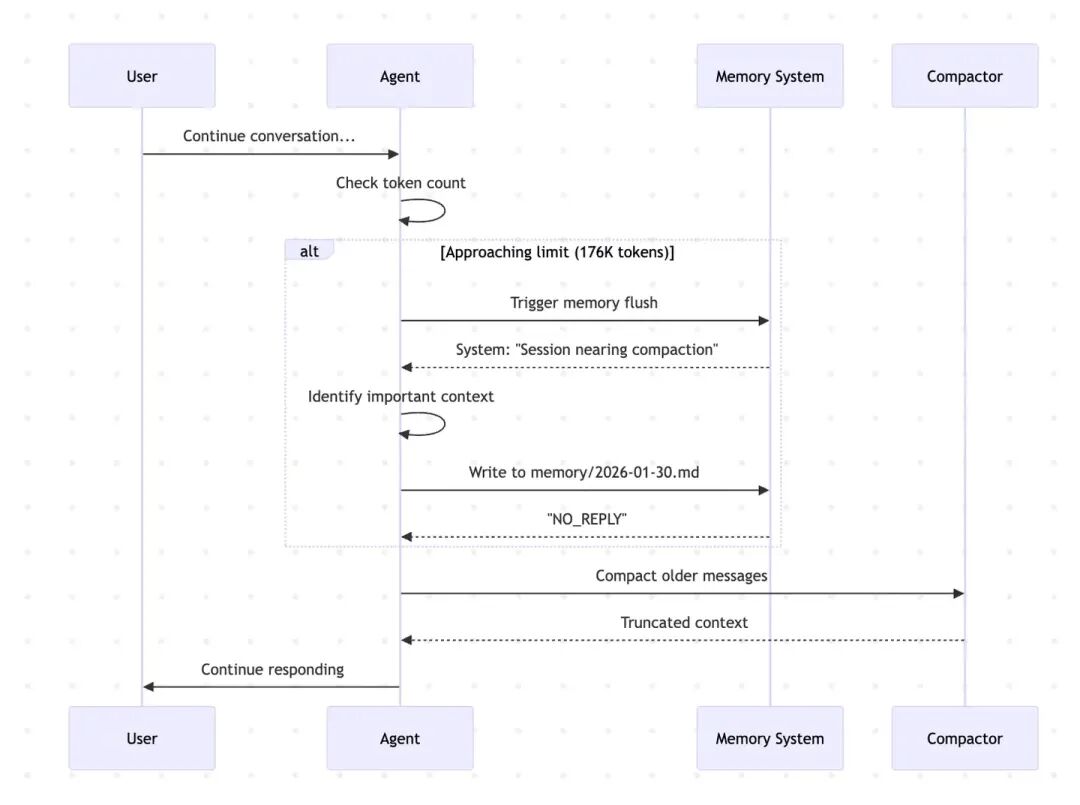
这想法其实不错,但是OpenClaw到目前实现的不行。
解决方法很简单,用QMD。
我是前阵子用Claude Code来管理Obsidian笔记的时候注意到了qmd,其实用CC来管理Obsidian笔记这事,和管理OpenClaw的Memory一回事。
你看我Obsidian上笔记已经写了几兆markdown了,如果要CC去总结一个东西,把这几兆markdown全发给AI模型,那一个回合就消耗几百万个Tokens,那真的根本花不起啊!
所以需要安装一个QMD,QMD是Query Markup Documents,是电商平台Shopify创始人 Tobi开发的一个本地语义搜索引擎,可以说是专为AI Agent量身定制。
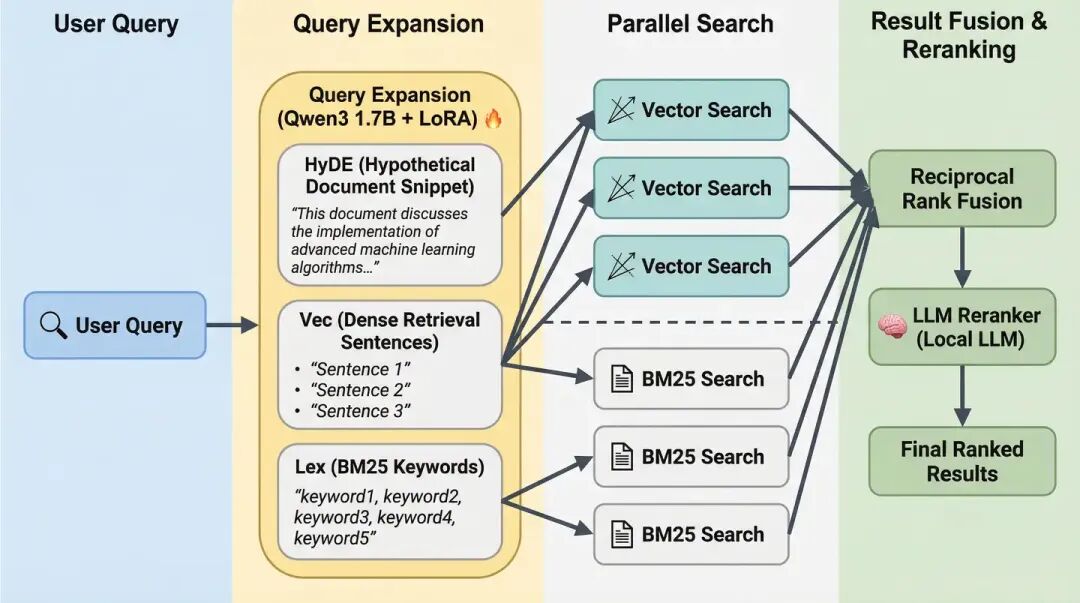
让CC先去利用qmd去搜索Obsidian的文档,得到的相关结果可能也就几K,只把这几K文档发给AI模型去总结,就非常节省Tokens了。
因为QMD 不是傻瓜式切字符,它会根据 Markdown 结构(标题、列表、代码块)智能分块,保证语义完整,所以特别适合Obsidian文档,当然,也适合OpenClaw的Memory。
所以,为了省OpenClaw的Tokens消耗,就让它把QMD用起来就OK了。
步骤:
先用npm或者bun安装上qmd
npm install -g @tobilu/qmd# orbun install -g @tobilu/qmd然后修改OpenClaw的配置文件~/.openclaw/config.yaml ,加上这些下面这些内容:
memory: backend:"qmd" citations:"auto" qmd: includeDefaultMemory:true update: interval:"5m" debounceMs:15000 limits: maxResults:7 timeoutMs:4000 scope: default:"deny" rules: - action:"allow" match: chatType:"direct" paths: - name:"memory" path:"~/.openclaw/workspace/memory/" pattern:"**/*.md" - name:"notes" path:"~/obsidian/" pattern:"**/*.md"最关键的几个配置:
backend,必须是qmd,这就是让qmd成为OpenClaw的memory来源 maxResults,不要太大,这就是qmd搜索结果排在前面多少个结果放到Context,我选择7,因为我喜欢7这个数字 paths,列上所有希望成为需要参考的文件
一切就搞定了。
用了QMD,Tokens消耗量可以减少80%。
当然,我事后诸葛亮地想,可能省Tokens主要是因为maxResults这个配置,但是QMD又快又准地搜对内容,也是功不可没。
最后,还是友情提醒一下,OpenClaw是给专业人士的工具,如果你都不明白我上面的教程说些什么,那你可能不适合使用OpenClaw。
不要因为看别人跟风所以养小龙虾,工信部都认定OpenClaw存在安全风险。
不要被Web4.0概念忽悠去养小龙虾,这玩意币圈都下场了,可见割韭菜的刀已经磨亮了。
Claw只是一种形态,何必单恋OpenClaw一枝花。
大家静待更加安全、更加易用的Claw就好,我相信,各个大厂很快就会推出很棒的Claw产品的。
