 夜雨聆风
夜雨聆风
作者 | OceanBase PowerMem 团队
全文共 3840 字,阅读约需 8 分钟
OpenClaw 默认把整份 MEMORY.md 每轮塞进 system_prompt ——不做检索、随使用无限增长。用得越多,Token 烧得越快,而其中大部分跟当前对话毫无关系。
memory-powermem 是我们为 OpenClaw 做的 OceanBase PowerMem 记忆插件。装上之后,OpenClaw 的记忆机制变成:会话前按需检索相关记忆注入上下文,会话后智能抽取关键事实落库。只把该用的放进去,该记的存下来。
实测效果:
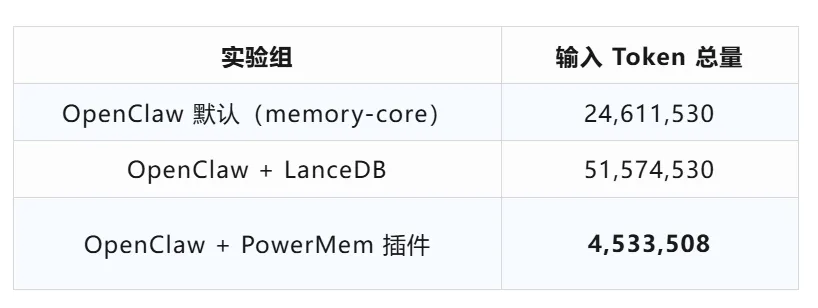
同等任务下,Token 消耗降至默认方案的 18%。
安装
一键安装(推荐)
通过 ClawHub Skill 安装,OpenClaw 自动完成插件下载、配置和槽位切换:
https://clawhub.ai/teingi/install-powermem-memory-minimal
# 1. 登录 ClawHub(首次使用)clawhub login# 2. 一键安装skillsclawhub install teingi/install-powermem-memory-minimal# 3. 查看已安装的技能clawhub list
有了 Skill 之后,你就可以指挥你的 OpenClaw 去自动安装 memory-powermem 插件了:
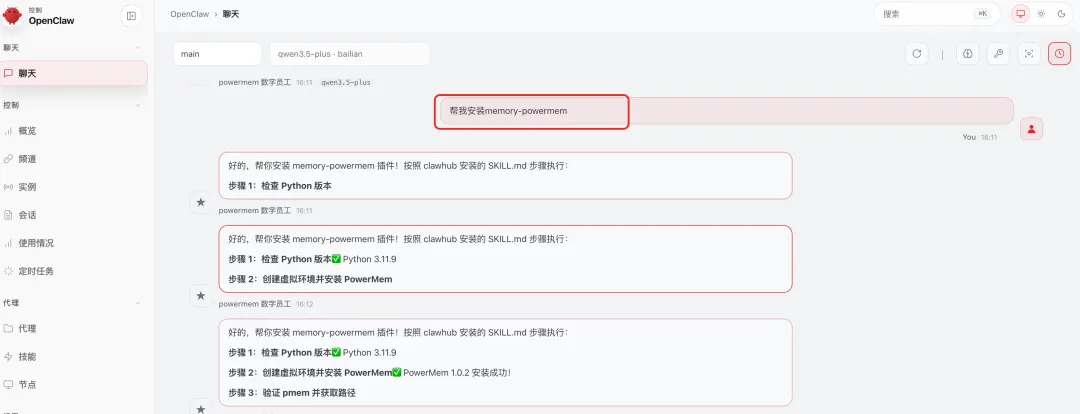
当然你如果你还想省事,你可以直接扔一个 Skill 链接,让小“龙虾”帮你搞定安装,此时你只需要喝着咖啡,稍等片刻即可:
参考这个链接: https://clawhub.ai/teingi/install-powermem-memory-minimal,帮我安装一下memory-powermem插件,并做一下记忆的测试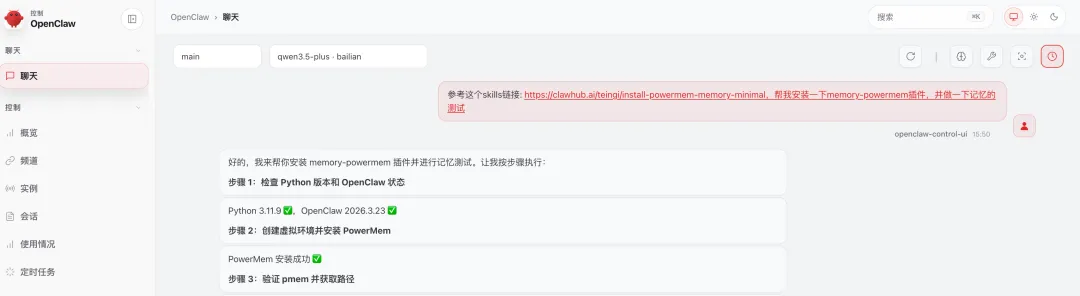
手动安装
前置条件:本机需要 Python 3.10+(python3 --version 确认)。如果还没装:macOS 用 brew install python,Linux 用系统包管理器,Windows 从 python.org 下载安装(安装时勾选 Add to PATH)。
1.确认 OpenClaw 已经能用终端执行 openclaw --version,并且你已经在 OpenClaw 里配好了平时对话用的模型(能正常回复即可)。
pip install之前必须先确认版本,否则后续容易装失败或运行异常:python3 --version输出应为 Python 3.10.x、3.11.x、3.12.x 等(次版本号 ≥ 10)。也可用下面命令做一次硬性校验(不通过会报错退出):
python3 -c "import sys; assert sys.version_info >= (3, 10), '需要 Python 3.10 或更高'; print(sys.version.split()[0], 'OK')"若版本不够:先升级本机 Python,或安装并使用 python3.11 / python3.12 等满足要求的解释器,并将下面步骤里的python3换成实际命令(例如 python3.12 -m venv ...)。
3.安装 PowerMem(Python):建议用虚拟环境,然后安装:
mkdir ~/.openclaw/powermempython3 -m venv ~/.openclaw/powermem/.venvsource ~/.openclaw/powermem/.venv/bin/activatepip install powermem
装好后执行 pmem --version,能输出版本就行。
在目录下~/.openclaw/powermem 新建.env,配置 LLM 和 Embedding(数据库开箱即用,无需额外配置):
mkdir -p ~/.openclaw/powermem && cd ~/.openclaw/powermemcat > .env << 'EOF'TIMEZONE=Asia/ShanghaiLLM_PROVIDER=qwenLLM_API_KEY=your_api_key_hereLLM_MODEL=qwen-plusEMBEDDING_PROVIDER=qwenEMBEDDING_API_KEY=your_api_key_hereEMBEDDING_MODEL=text-embedding-v4EMBEDDING_DIMS=1536EOF
将 your_api_key_here 替换为你的 API Key。
LLM 配置说明
OceanBase PowerMem 需要配置 LLM(用于智能抽取)和 Embedding(用于向量检索),两者可以用不同供应商。内置支持的 LLM Provider:
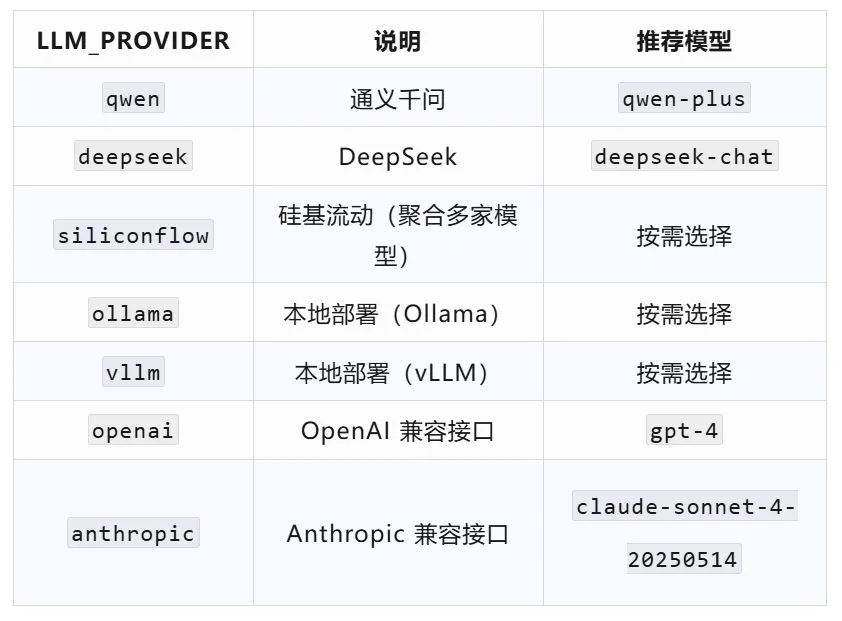
大量国内供应商提供 OpenAI 或 Anthropic 兼容 API,可以直接用 openai/ anthropic 作为 Provider,修改对应的 BASE_URL 指向实际服务地址即可。
OpenAI 兼容接入示例(适用于月之暗面、零一万物、百川等):
# 月之暗面 KimiLLM_PROVIDER=openaiLLM_API_KEY=your_moonshot_api_keyLLM_MODEL=moonshot-v1-8kOPENAI_LLM_BASE_URL=https://api.moonshot.cn/v1# 零一万物LLM_PROVIDER=openaiLLM_API_KEY=your_yi_api_keyLLM_MODEL=yi-largeOPENAI_LLM_BASE_URL=https://api.lingyiwanwu.com/v1
Anthropic 兼容接入示例(适用于智谱等):
# 智谱 GLMLLM_PROVIDER=anthropicLLM_API_KEY=your_zhipu_api_keyLLM_MODEL=glm-4-plusANTHROPIC_LLM_BASE_URL=https://open.bigmodel.cn/api/paas/v4
原理:只要该服务兼容 OpenAI 的/v1/chat/completions或 Anthropic 的 /v1/messages 接口,就可以用对应 Provider + 自定义 BASE_URL 接入。
Embedding 配置说明
内置支持的 Embedding Provider:
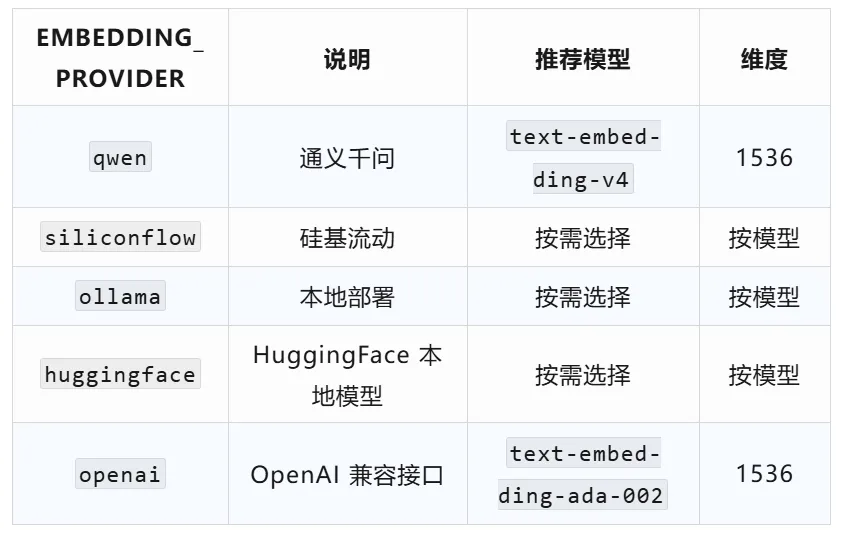
同理,兼容 OpenAI Embedding 接口的国内服务也可以用 openai + 自定义 OPENAI_EMBEDDING_BASE_URL 接入:
# 智谱 Embedding(OpenAI 兼容)EMBEDDING_PROVIDER=openaiEMBEDDING_API_KEY=your_zhipu_api_keyEMBEDDING_MODEL=embedding-3EMBEDDING_DIMS=2048OPENAI_EMBEDDING_BASE_URL=https://open.bigmodel.cn/api/paas/v4
注意: EMBEDDING_DIMS必须与模型实际输出维度一致,否则检索会出错。
完整配置参考 .env.example:
(https://github.com/oceanbase/powermem/blob/main/.env.example)
然后启动:
# 注意先切换目录回工作目录cd ~/.openclaw/powermemsource ~/.openclaw/powermem/.venv/bin/activatepowermem-server --host 0.0.0.0 --port 8000
验证:
curl -s http://localhost:8000/api/v1/system/health
5.安装插件 memory-powermem
openclaw plugins install memory-powermem安装后用openclaw plugins list 确认 memory-powermem 存在。
6.修改配置(可选)
插件安装后自带一份配置(HTTP 模式,连接 localhost:8000),如果你的 PowerMem 服务就跑在本机默认端口,这一步可以跳过。
只有以下情况需要手动编辑~/.openclaw/openclaw.json:
OceanBase PowerMem 服务不在
localhost:8000(改baseUrl)想用 CLI 模式替代 HTTP 模式(改 mode)
需要调整 autoRecall / autoCapture 等行为
配置生效优先级:
~/.openclaw/openclaw.json > 插件内置默认值。
HTTP 模式示例:
{"plugins": {"slots": { "memory": "memory-powermem" },"entries": {"memory-powermem": {"enabled": true,"config": {"mode": "http","baseUrl": "http://localhost:8000","autoCapture": true,"autoRecall": true,"inferOnAdd": true}}}}}
CLI 模式示例(不启 HTTP 服务,本机直接调用 pmem):
{"plugins": {"slots": { "memory": "memory-powermem" },"entries": {"memory-powermem": {"enabled": true,"config": {"mode": "http","envFile": "~/.openclaw/powermem/.env","pmemPath": "~/.openclaw/powermem/.venv/bin/pmem","autoCapture": true,"autoRecall": true,"inferOnAdd": true}}}}}
重启 OpenClaw gateway,执行:
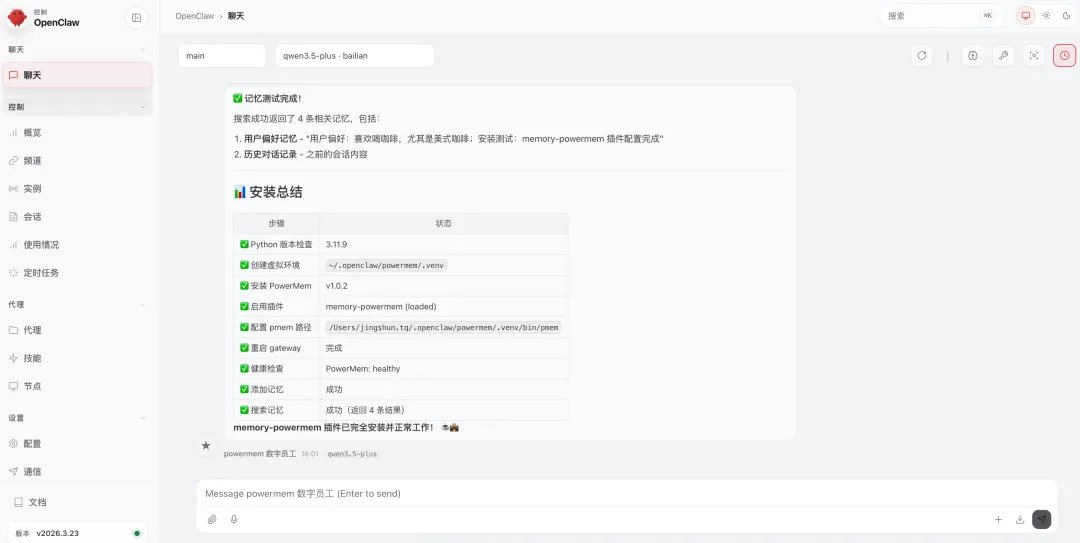
openclaw gateway restart检测 memory-powermem 记忆插件健康情况
openclaw ltm health无报错即表示插件已连通。可以再试一下写入和检索:
openclaw ltm add "一条测试记忆"openclaw ltm search "测试"
如果检索能返回刚写入的内容,说明完整链路(PowerMem → 插件 → OpenClaw)已经通了。
遇到问题?
openclaw ltm health连不上:确认 PowerMem 服务在运行,curl http://localhost:8000/api/v1/system/health能返回 JSON插件不在列表里:openclaw plugins list 检查,确认执行过 openclaw plugins install memory-powermem 记忆写入了但检索不到:检查 .env 里 Embedding 配置是否正确(API Key、模型名) 更多排查:openclaw plugins doctor 可以诊断插件加载和配置问题
装完之后发生了什么
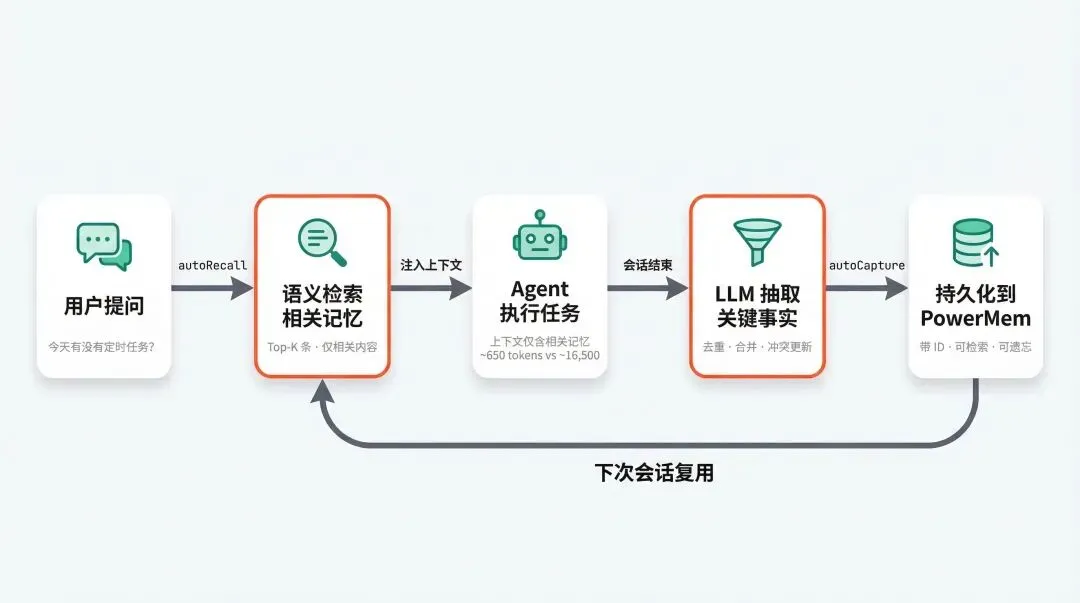
插件接管了 OpenClaw 的记忆读写,通过两条自动化链路工作:
自动召回(
autoRecall):每次会话开始前,插件用你发的第一条消息向 PowerMem 做语义检索,把 Top-K 条相关记忆格式化后注入上下文前部。Agent 从第一轮就能看到跟当前问题直接相关的历史事实,而不是把整份MEMORY.md丢进去。自动抓取( autoCapture):会话正常结束时,插件把本轮对话发给 PowerMem,PowerMem 用 LLM 从中抽取事实,去重、合并后落库。存下来的是提炼过的记忆单元,不是整段对话的拷贝。
两者形成闭环:会话前按需注入,会话后智能抽取。只把该用的放进上下文,该记的存进库。
插件还向 Agent 暴露了三个工具:
memory_recall:按自然语言查询检索长期记忆
memory_store:写入一条记忆(用户说「请记住……」时触发)
memory_forget:按 ID 或搜索条件删除记忆(也可用于合规删除场景)
此外,通过 OceanBase PowerMem 的 Dashboard(http://localhost:8000/dashboard/)可以在 Web 端浏览、筛选和统计所有记忆。
记忆不再是黑盒里的上下文——你能看到系统记住了什么、什么时候记的、被检索过几次。运维时也可以用openclaw ltm search直接在终端查询。
Token 到底省在哪
用两个例子直观感受。
假设 MEMORY.md 已经积累到 50KB(约 15,000 tokens),里面有 Agent 使用统计、Token 消耗记录、定时任务配置、诊断规范、各种零散笔记。
例一:「今天有没有要跑的定时任务?」
默认方案:
MEMORY.md整份进system_prompt(15,000 tokens 固定基线),再加上模型调用memory_search拉取的片段(约 1,500 tokens)。合计约 16,500 tokens/轮,其中绝大部分跟定时任务无关。
PowerMem 插件:autoRecall 用这句话做查询,只返回跟定时任务和今天相关的精炼记忆。合计约 650 tokens/轮。
省了 96%。
例二:「上次说的诊断规范里,第一步是什么?」
默认方案:
MEMORY.md15,000 tokens + 诊断规范整章 2,000 tokens。实际有用的就第一步:检查网关健康这一句。合计 17,000+ tokens/轮。PowerMem 插件:autoRecall 返回诊断相关记忆。合计约 680 tokens/轮。
省了 96%。
核心原因:插件不是少调一次 API,而是用按需检索替代了整份 MEMORY.md每轮必带。
算一笔账:假设上下文窗口 128K,输入单价约 2 美元 /1M tokens。每轮省 ~15,000 tokens,每天 50 轮对话,一个月仅记忆相关部分就能省约 45 美元。Agent 越多、MEMORY.md 越长、调用越频繁,节省越显著。
为什么这样设计
做这个插件之前,我们先看了 OpenClaw 的记忆机制到底是怎么工作的。
OpenClaw 把记忆存在 Markdown 文件里:MEMORY.md(精选长期记忆)和 memory/YYYY-MM-DD.md(按日追加的日志)。模型通过 memory_search 和memory_get两个工具做语义检索或按路径读取。要把内容写进 Markdown,主要靠两条机制:
一是对话快占满上下文、即将自动压缩前,系统会先插一轮「记忆落盘」,让模型把该留的信息追加到
memory/YYYY-MM-DD.md文件里;二是执行 /new 或 /reset 时,内置的会话记忆会把上一轮对话整理成一篇带日期和主题缩写的文件,也放在 memory 目录里。
这套设计在文件即真相和可检索之间做了平衡,但有几个结构性问题:
Token 膨胀难控制。
MEMORY.md整份进system_prompt,不做检索,写什么、写多少完全依赖模型判断。历史会话一旦被整段写入,就会在后续检索中反复以大块形式出现。记忆没有独立身份。记忆的存在形式是某段 Markdown 里的几行字,没有独立 ID、没有生命周期管理。你无法在系统层面回答这条记忆何时创建、被谁引用、是否过期。
只增不减。系统不会根据访问频率或时间自动清理,所有写入的内容在逻辑上都是永久的。
多 Agent 难复用。记忆绑在各自 workspace 的文件里,跨 Agent 共享只能靠复制文件。
OceanBase PowerMem 针对这些问题做了不同的选择:
智能抽取替代整段拷贝:写入的是 LLM 从对话中提炼的事实单元,不是原始对话
艾宾浩斯遗忘曲线:高价值、常访问的记忆被巩固,低价值的随时间衰减
混合检索:向量 + 全文 + 图检索,结合遗忘曲线排序,结果既相关又适龄
记忆有 ID 有生命周期:每条记忆可关联 user_id、agent_id,支持精确删除、跨 Agent 共享。
插件把这些能力接入 OpenClaw,在不改变使用方式的前提下替换底层记忆机制。槽位切换,零侵入——随时可以切回memory-core,原有文件不受影响。
配置项一览
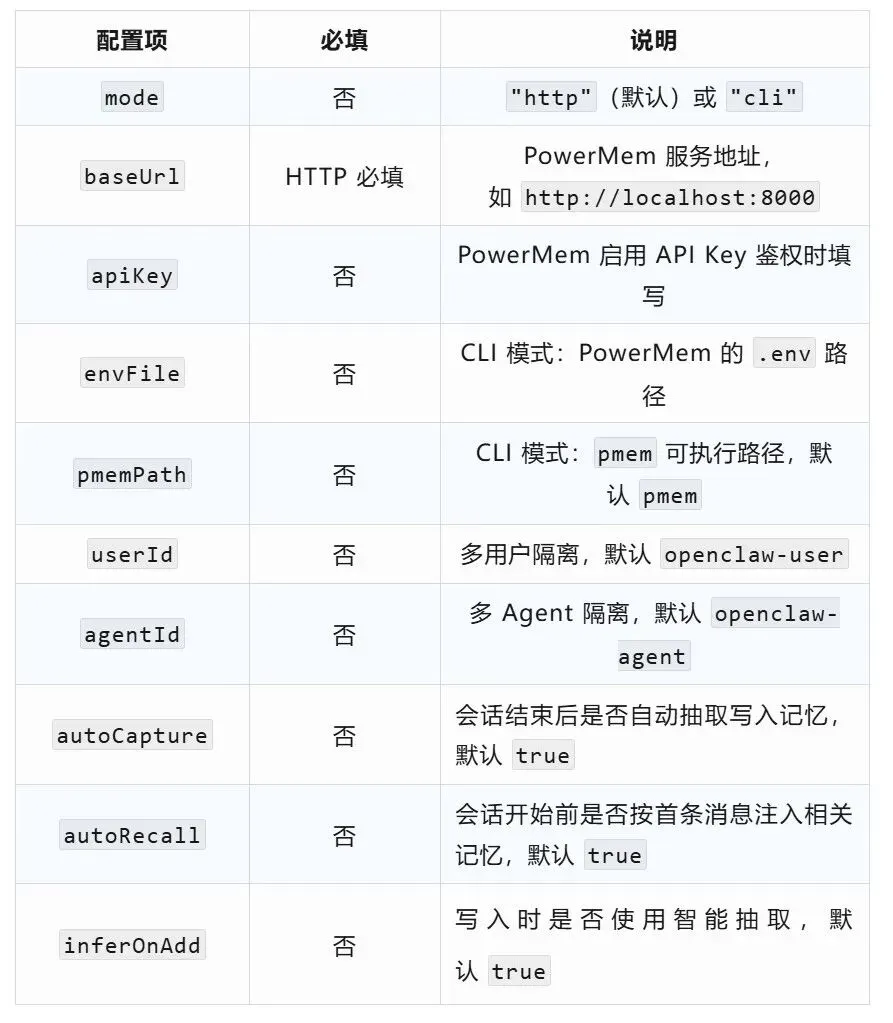
插件管理常用命令:

常见问题
1.装了插件后,原来的 MEMORY.md怎么办?
不受影响。插件通过 OpenClaw 的 memory 槽位机制接入,不修改也不删除原有文件。切回 memory-core 后,MEMORY.md 和 memory/*.md 依然可用。
2.可以随时切回默认 memory-core 吗?
openclaw.json 里的 slots.memory 改回 "memory-core",重启即可。零侵入,可逆。autoCapture 可以单独关闭吗?false。比如只想用手动的 memory_store/ memory_recall工具,关掉两个 auto 即可。userId 和 agentId 配置项做隔离,每个 Agent 有独立命名空间,同一 OceanBase PowerMem 实例可服务多个 Agent。
了解更多

在线咨询

优质资料下载




