 夜雨聆风
夜雨聆风本周正式开启了 AI 全栈工程师的新征程。这段时间深度沉浸在 OpenClaw 的生态构建中,从多平台(飞书、微信、Telegram)的工程化落地,到 Token 优化方案的设计,再到 Skills 配置与多 Agent 协同的实战演练。
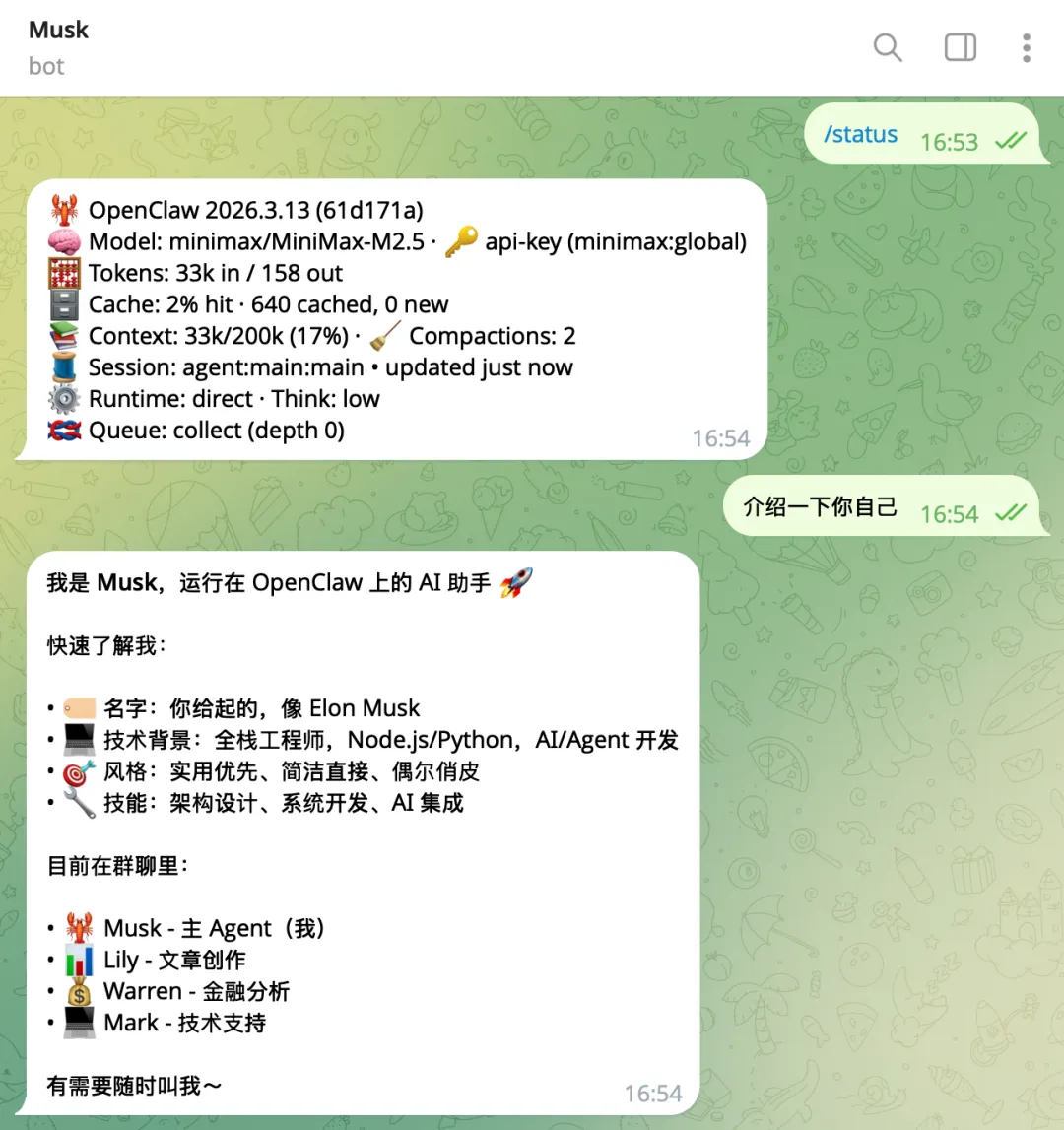
整体使用下来,感觉最实用的就两个东西:Skills 和多 Agent。Skills 是 AI 的“手脚”,而多 Agent 是 AI 的“组织架构”。这两个概念看似是技术配置,本质上是在解决同一个核心矛盾:如何让大模型从“模拟人类对话”转向“模拟人类工作”。
其实 Skills 与多 Agent 的核心逻辑在于如何将大模型的“通用逻辑”转化为“工程生产力”。Skills 本质上是给 AI 装上了五官和肢体,让它不再只是一个能写代码、写诗的黑盒,而是能够通过 API 或函数去感知外部世界、操作实际业务的工具集。这种能力的确定性补偿了模型生成的随机性,让 AI 的输出变得可控且具备功能性。

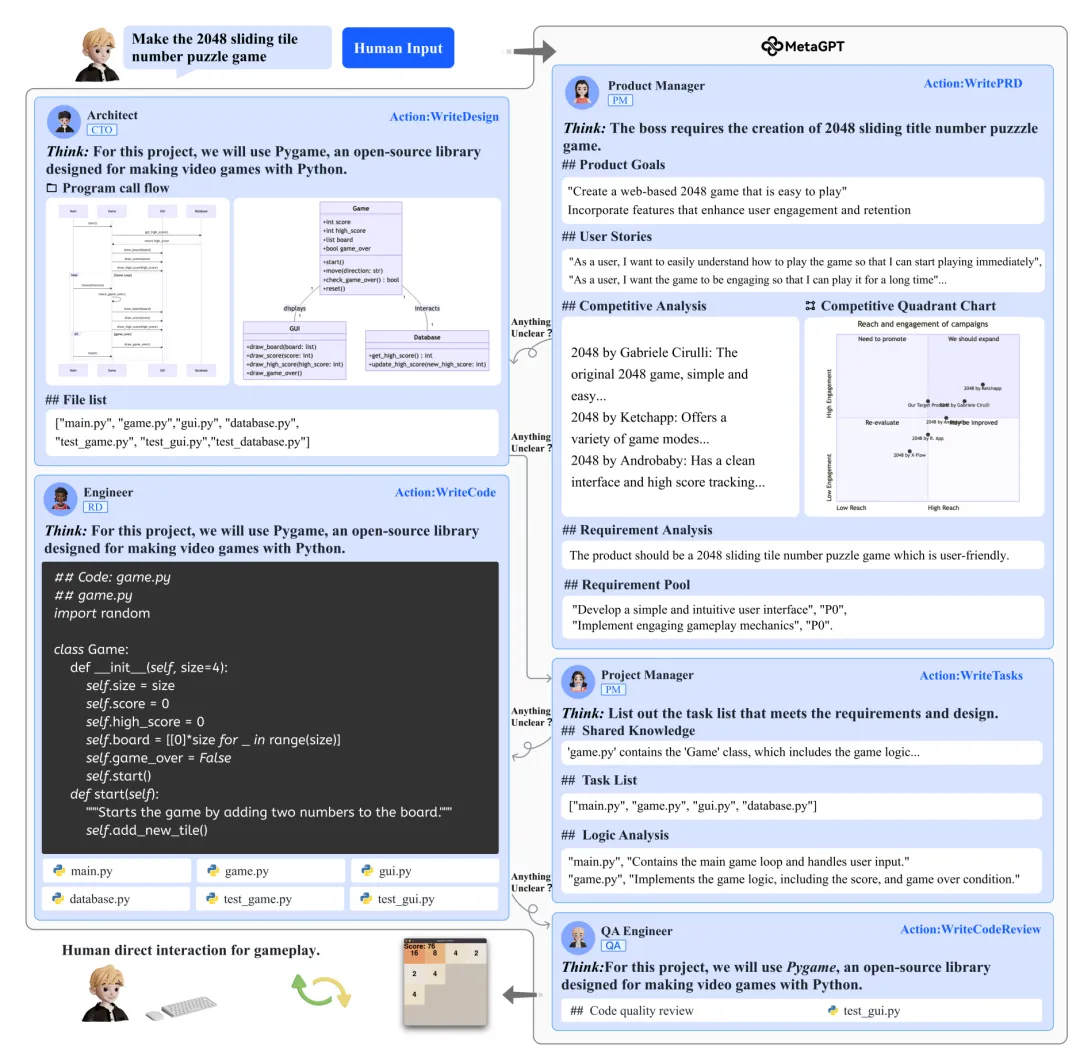
当任务的复杂度跨越了单一工具的覆盖范围,多 Agent 协作就成了必然的选择。这种架构类似于人类社会的组织管理,将大任务拆解为细分的专业领域。每一个 Agent 都可以看作是一个带有特定 Skills 的“专家”,它们通过状态机或预设的工作流进行对话与接力。这种分工不仅能降低单一 Agent 因挂载过多工具而产生的意图识别混乱,还能通过角色博弈和互相校验,大幅度压低大模型的幻觉率。
这种多Agent协同操作体系会朝着更加自主和动态的方向演进。我们不再需要硬编码每一个执行步骤,顶层的调度智能体会根据实时需求,自主地去寻找、编排甚至在线学习新的 Skills。这种从“人工编排”到“自主演进”的跨越,才是多 Agent 系统真正释放潜力的时刻。
但在实际落地的过程中,开发者面临的最大痛点或许是执行成本与效率的平衡。在多 Agent 频繁交互的场景下,上下文的冗余会导致 Token 消耗呈指数级增长。因此,现在的技术前沿会有很多关于研究如何进行精细化的内存管理和 Token 节省策略。通过优化长短期记忆的存储,或者在 Agent 之间传递更精简的结构化状态,才能让复杂的智能体系统在商业上变得真正可持续。
这一周还有个更深的感受:之前总觉得 AI 嘛,不就是调个 API 玩一玩,但真把一套系统跑起来之后,视角完全变了。OpenClaw 让我看到的不是某个功能有多酷,而是“平台化”这件事本身的价值。一个好的平台不是把所有功能都堆在一起,而是让生态里的每个人都能够根据自己的需求去扩展、去定制。Skills 机制就是最好的例子——它不告诉我该怎么做,它给我工具,让我自己决定怎么搭。这个思路和我之前做项目的方式不太一样,以前是想着“怎么完成功能”,现在变成了“怎么搭建一个让大家能自己完成功能的框架”。这个转变挺有意思的。
综合而言,这一周学到最多的不是某个具体怎么配,而是学会从系统角度想问题。技术选型要会做取舍,OpenClaw 这套体系不是单一工具,而是一个生态,技能化、平台化的思路对我启发挺大的。在 AI 这个赛道,技术迭代快得让人窒息,今天刚掌握的配置方案,可能两个月后就过时了。但这种从系统角度看问题、在实战中做取舍的能力,以及这种不断折腾、不断推翻重来的学习方法,才是真正能留下的东西。具体的工具会变,但这种对技术的敏锐和对系统的掌控感,才是不贬值的护城河。
