 夜雨聆风
夜雨聆风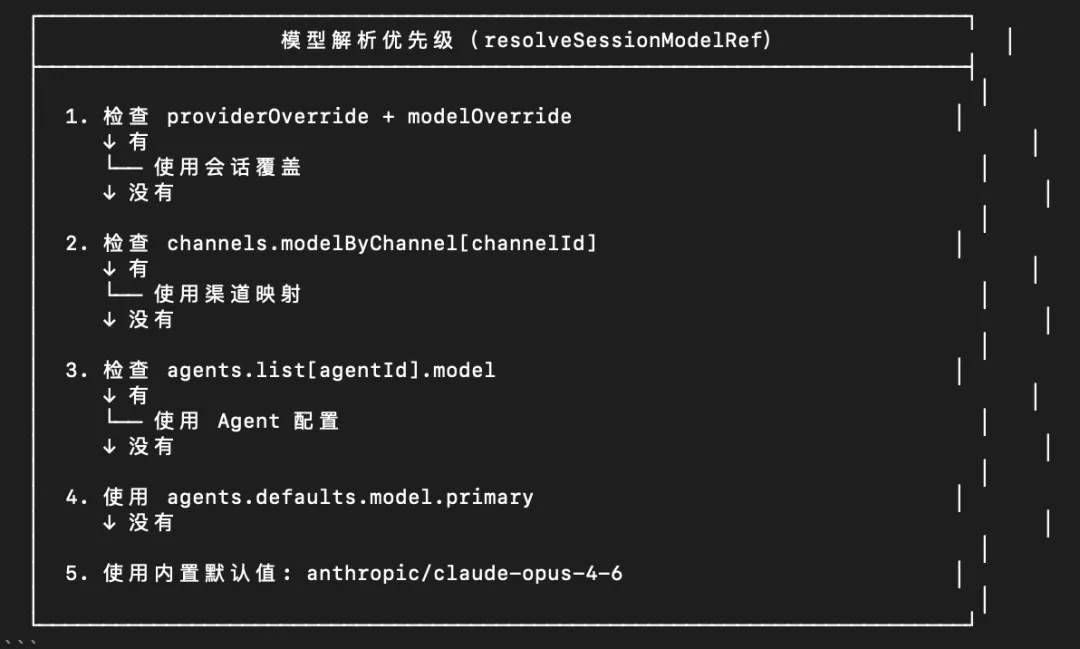
// ~/.openclaw/openclaw.json
{agents: {defaults: {model: {primary: "anthropic/claude-opus-4-6", // 主模型fallbacks: ["minimax/MiniMax-M2.7"], // 备用模型列表},models: {"anthropic/claude-opus-4-6": {alias: "opus", // 简称params: { temperature: 0.7 } // 模型参数},"minimax/MiniMax-M2.7": {alias: "minimax"},},},},}
{agents: {list: [{id: "coding-agent",model: "openai/gpt-5.4", // Agent 专属模型},{id: "creative-agent",model: {primary: "google/gemini-3.1-pro",fallbacks: ["anthropic/claude-sonnet-4-6"],},},],},}
{channels: {modelByChannel: {discord: {"123456789": "anthropic/claude-opus-4-6",},telegram: {"-1001234567890": "openai/gpt-5.4-mini",},},},}
type ModelCatalogEntry = {id: string; // 模型 ID,如 "claude-opus-4-6"name: string; // 显示名称provider: string; // 提供商,如 "anthropic"contextWindow?: number; // 上下文窗口大小reasoning?: boolean; // 是否支持推理input?: ("text" | "image" | "document")[]; // 支持的输入类型};
首先从OpenClaw的设计哲学出发,他的设计哲学有四点:
1.本地优先(Local-First),用户的数据留在本地,不依赖云服务
2.用户控制(User Control),每个决策都应该用户有意识的选择
3.透明可预测(Transparent & Predictable),行为应该可预测,不应该隐藏“魔法”
4.成本感知(Cost Aware),用户应该知道用什么模型、花多少钱
如果进行大模型自动选择,会出现这些问题:
1.不可预测性,用户不知道这次会用到什么模型
2.难以调试,当结果不好时,不知道是不是模型选择的问题
3.复杂度定义模糊,"复杂" vs "简单" 没有明确边界
4.错误成本高,用错模型的代价比用对大模型更高
5.上下文依赖,复杂度往往在对话过程中才显现
如果要实现有几种方法,一是基于启发式的规则,就是在代码里面写关键词检测,二是基于小模型的预分类,先用一个小模型进行任务预分类,将不同任务路由到不同大模型,三是基于历史反馈的强化,记录每次任务结果和模型选择,用户反馈的满意结果,再通过强化学习进行优化。
但这三种方法目前我来看都不可靠,且实现成本巨大。
OpenClaw目前做法无疑是认为,让机器做选择,比让机器自猜更高,这说明了大模型猜测任务复杂的不可靠性,引入复杂机器学习路由,将带来更多的不确定性和不可预测性。
