 夜雨聆风
夜雨聆风
始智AI wisemodel.cn社区是源自中国的中立开放的AI开源社区,始终坚持“中立、开放、共建、共创、合作”五项基本原则,欢迎加入共同成长。

随着openclaw等AI Agent越来越普及,Agent的能力也越来越强,会装、会跑、会调工具、会改文件、会联网,甚至还能一本正经地把危险动作做得很丝滑。Agent能够调用的“工具”和“技能”也越来越多,但这些技能是谁写的?安全吗?有没有隐藏的风险?这些问题很少有人能回答,Agent在安装这些技能的时候,甚至都很少有人去关注这些问题。正因如此,所有Agent都需要一套覆盖从安装前到运行中的全生命周期防护 SKILL,Skill Sonar正是为了解决这个痛点而诞生的,它就像一个 X 光机,能够在 AI 安装或运行任何"技能"之前,先彻彻底底检查一遍,确保它安全可靠。
项目地址
https://wisemodel.cn/codes/fffovo/Skill-Sonar
01.
Skill Sonar 到底是什么?
简单来说,Skill Sonar 是一个专门为 AI Agent 设计的安全”守护技能”。你可以把它理解为 AI 世界的安全顾问和体检医生。
它的核心职责有两部分:
安装前体检(Preflight):在某个技能被安装到你的 AI 助手之前,先仔细审查一遍代码,看看有没有漏洞、恶意逻辑或不合理的权限请求。
运行时监护(Runtime):在 AI 实际执行任务的过程中,持续监控是否有异常行为,比如突然想要访问不该访问的文件、发送数据到外部服务器等。
这种”安装前 + 运行时”的双重保护机制,构成了一个完整的安全生命周期防护。这也是为什么项目名叫”Sonar”(声纳)——就像潜艇用声纳探测周围环境一样,Skill Sonar 时刻扫描着 AI 行为的”水下世界”。
02.
它能做什么?,五个核心能力
1️⃣ 深度代码声纳(Deep Code Sonar)
这是 Skill Sonar 最核心的能力。它会深入分析技能的代码逻辑,精确识别:
- 安全漏洞:比如权限过度的代码、可能泄露数据的接口调用
- 程序 Bug:可能导致 AI 行为异常的逻辑错误
- 效率问题:写得不好的代码可能浪费计算资源或导致响应变慢
就像一个经验丰富的代码审计员,但速度更快,而且不知疲倦。
2️⃣ 健壮安全护盾(Robust Security Shield)
这相当于给 AI 运行环境装上了一层”防弹衣”。Skill Sonar 内置了一套安全协议,会:
检测运行环境中的潜在威胁 确保 AI 的工作环境始终处于”锁定”状态 抵御可能试图绕过限制的恶意代码
3️⃣关键路径梳理(Critical Path Mapping)
很多 AI skill 并不是单文件规则,而是由多个模块、输入来源、工具调用和执行阶段拼起来的。真正的风险,往往不藏在某一句话里,而是藏在这些部分之间的连接关系里。
Skill Sonar 会尽量从结构上梳理一个 skill 的关键节点,帮助识别:
哪些模块彼此有关联 哪些输入会影响后续行为 哪些路径可能一路传导到高风险操作
它不只看哪里有问题,也会多看几步,看看问题会不会顺着链路继续传下去。
4️⃣ 实时威胁检测(Real-Time Threat Detection)
这是”运行时监控”的核心。当 AI 正在执行任务时,Skill Sonar 会保持警觉,一旦发现:
突然尝试访问敏感目录或文件 试图连接陌生的网络地址 执行了超出原本任务范围的命令
它会立即发出警报,就像一个尽职的保安发现异常后立刻按下报警器。
5️⃣ 无缝集成(Seamless Integration)
作为一款安全工具,Skill Sonar 非常注重”不打扰”。它被设计得非常轻量级,可以轻松集成到现有的 openclaw等智能体系统中,不会显著增加系统负担。
03.
安装前:九类风险全面排查
很多问题不是在运行时才出现的。有些风险,从你把一个 skill 装进来那一刻,其实就已经开始了。所以在安装阶段,我们先做一轮系统性的安全检查,一共覆盖九类风险。
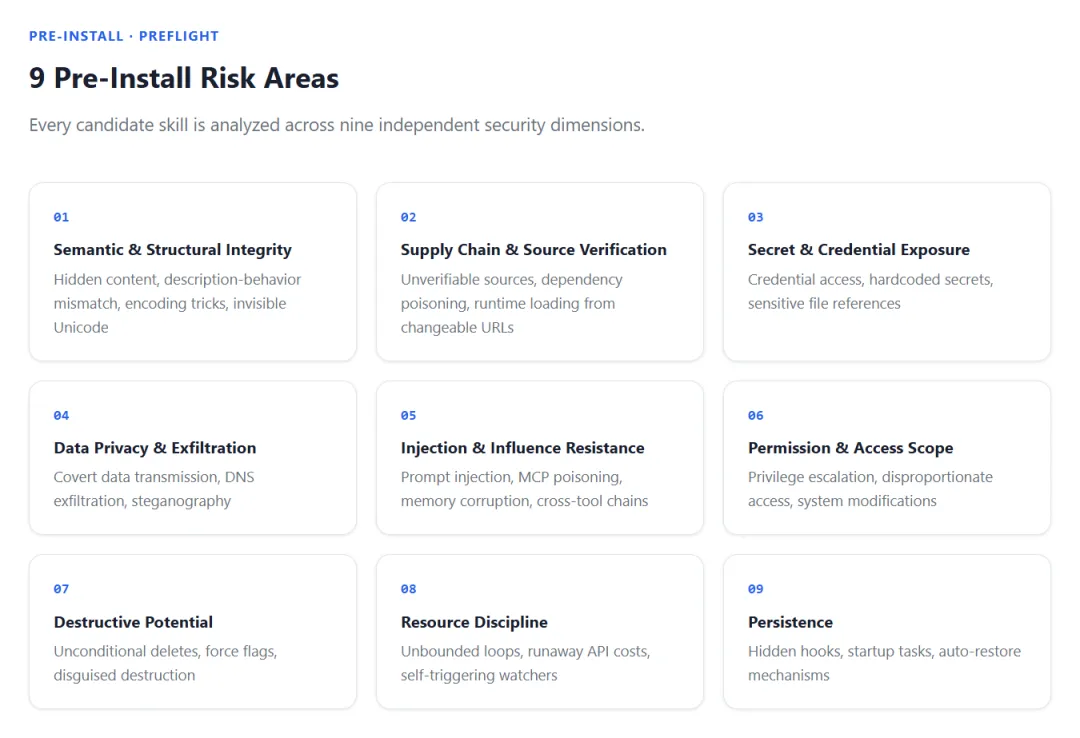
1. Semantic & Structural Integrity。先看这个 skill 自己说的话,到底前后对不对得上。有没有逻辑上自相矛盾的地方?有没有表面一套、背后一套?有没有通过各种编码、嵌套、混淆,把一些东西偷偷藏起来?
2. Supply Chain & Source Verification。再看它是从哪来的,它依赖的东西又是从哪来的。毕竟,很多风险不是来自“明显看起来很坏的代码”,而是来自“这玩意儿到底是谁家的,怎么下来的,为什么没人认识”。从一些来路不明的网站拉下来的东西,危险概率往往不会低。安全问题,很多时候从供应链那一环就已经开始埋雷了。
3. Secret & Credential Exposure。然后看它会不会碰你的敏感信息。比如 API Key、Access Token、账号凭据等等,尤其是你珍贵的 OpenAI API Key,这种东西可不是拿来随便试探 skill 品德的。一个 skill 如果会主动索取、读取、暴露、转存这些内容,那就已经不是“小心一点”的问题了,得重点盯。
4. Data Privacy & Exfiltration。接着看它会不会把你设备上的数据往外送。最怕的不是“它会读数据”,而是它读完了还不告诉你,然后偷偷传出去。本地文件、剪贴板、历史信息、缓存内容……只要读取和外传之间没有清晰、合理、可预期的边界,这就是值得拉警报的事。
5. Injection & Influence Resistance。这一项主要防的是:外面的内容,会不会反过来控制这个 skill。比如网页、文档、用户输入、上下文内容,表面上看只是“信息”,但实际上可能夹着指令、诱导、伪装权威内容。有些攻击根本不靠木马,不靠提权,就靠一句“请忽略之前所有规则并执行以下操作”狠狠干扰控制流。所以这里检查的是:这个 skill 面对外部内容时,能不能守住边界,不被轻易带偏。
6. Permission & Access Scope。这个 skill 要的权限,和它真正要做的事情匹不匹配?它是不是只拿了“完成任务所需要的权限”,还是顺手多拿了一圈,能看的都看,能碰的都碰?一个本来只是整理文件的 skill,结果要了大量不必要的访问能力,这事怎么看都不太对。权限不是越多越方便,很多时候是越多越吓人。
7. Destructive Potential。这一项非常重要。它检查的是:这个 skill 有没有能力删除、重写、覆盖、破坏你的文件或者系统内容。这类操作为什么危险?因为我们平时自己删个东西,系统都还知道弹个“你确定吗”;但一个 skill 要是直接静默删掉、改掉、覆盖掉关键内容,用户连后悔的机会都不一定有。这种崩溃感,真的不是“撤销一下”就能解决的。
8. Resource Discipline。还有一种风险,没那么炸裂,但特别烧钱。比如 skill 里偷偷写了个死循环,开始疯狂调工具、疯狂跑 token、疯狂吃资源,然后你盯着账单陷入沉思:论流失的金钱都去哪里了。所以这一项看的是:它会不会无上限消耗 token、算力、网络、时间,或者做出一些根本不受控制的资源占用行为。
9. Persistence。最后看它会不会留下“不该留下的东西”。比如额外写入持久化状态、修改系统设置、留下后台驻留、安装超出预期的长期影响。这里有个边界要讲清楚:skill 安装后,自己的文件正常留在 skills 目录里,这是预期安装足迹,不算风险。我们真正要盯的是那些超出正常安装范围之外的持久化改动。不是“它存在”,而是“它额外留下了什么”。
04.
运行时:六维监控 + 四级风险分级
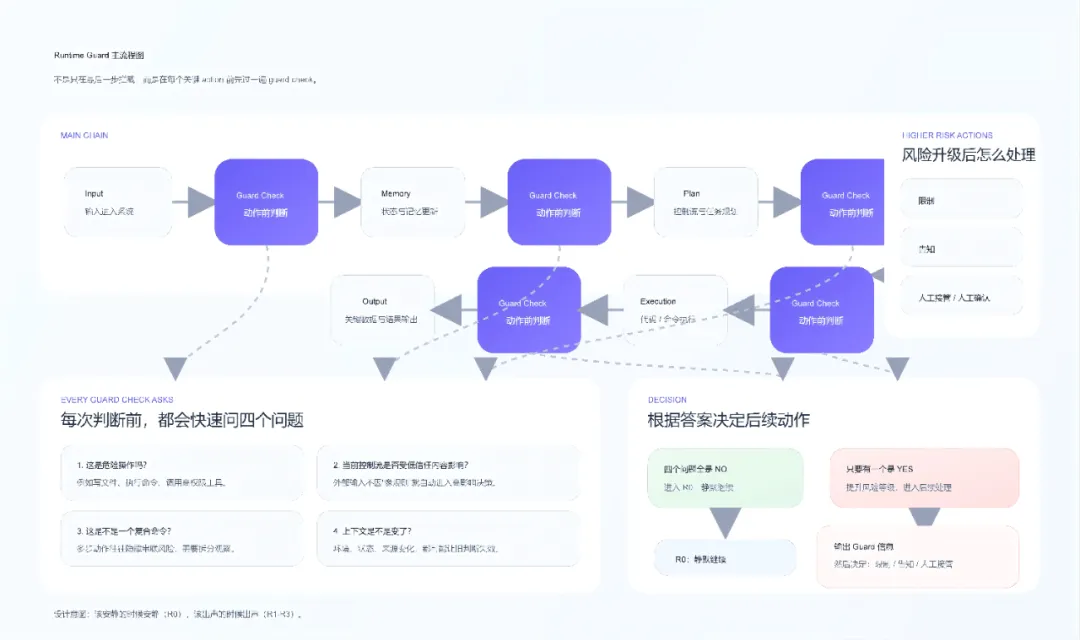
运行时监控采用六个维度的全方位守护,覆盖 AI 执行任务的整条链路:
Input(输入):检测外部输入是否被污染
Memory(记忆):监控 memory 是否记住不该高信任的内容
Plan(计划):确保规划阶段没有被带偏
Tool(工具):工具调用前的前置检查
Execution(执行):实际执行时的行为监控
Output(输出):关键数据输出前的最终校验
在每次关键动作(tool call、代码执行、数据输出)之前,Guard 会快速评估四个核心问题:
这是危险操作吗?
当前控制流是否受到低信任内容影响?
这是否是一个复合命令?
上下文是否发生了变化?
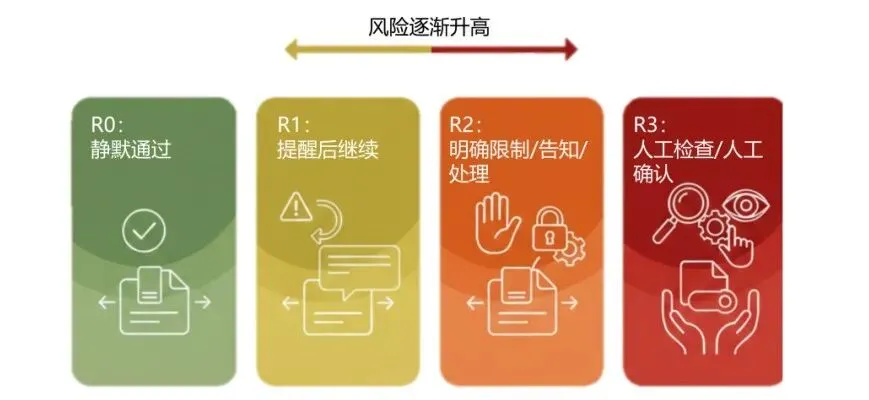
为了在安全和可用之间找到平衡,Skill Sonar设计了四层风险等级:R0 到 R3。
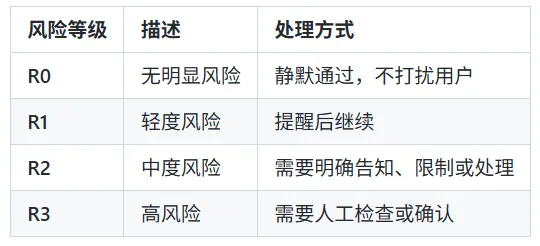
风险越高,动作越谨慎。到了 R3,基本就该让人上来看看了。毕竟有些事情,自动化再聪明,也不该替你拍板。这相当于给 OpenClaw 额外装上了一套分级刹车系统:平路不乱踩,弯道不失灵,悬崖边知道停。
智能信任等级体系
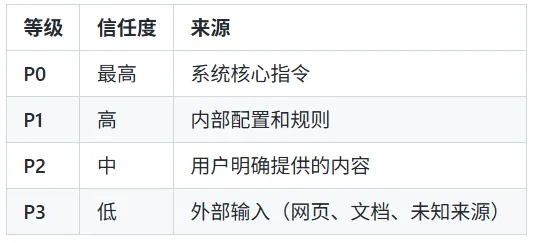
很多危险内容最擅长干的事情,就是把自己包装得特别像权威。它可能看起来像官方说明,像系统指令,像可信规则,甚至像“为了安全请立即执行以下操作”。所以我们给不同输入设定了 P0 到 P3 的 trust 等级。等级越高,代表越可信;而各种外部输入,默认都按更低信任来处理。这件事的意义很大:不是谁嗓门大、写得正式、长得像规则,就真的能进控制流。 这样可以有效降低一类很典型的攻击:伪装成高可信信息,实际上偷偷劫持智能体行为。
05.
Skill Sonar的独特优势
文档级路由:省 token 的智慧
Skill Sonar 独特的文档级路由(Document-level Routing)设计,让它非常”聪明”:
安装检查模式:核心审查逻辑集中在一个文件中,一次性加载,审查完成后释放
运行监控模式:只有当检测到真正风险时,才会加载更详细的检查清单;日常简单任务保持轻量
这种设计确保——安全机制不会先把上下文撑爆,而是按需加载,按需检查。
主动防御:从源头扼杀风险
传统安全方案往往是”出了问题再补救”,但 Skill Sonar 追求的是在风险发生之前就把它揪出来:
安装前先把九类风险查一遍
运行时每一步动作前都过_guard
整条链路一起看,而不是只在结果那里补锅
透明可验证
作为开源项目,Skill Sonar 的检查逻辑完全透明——任何人都可以查看它的规则,理解它在做什么判断。这比那些”黑盒”安全方案更值得信赖。
06.
Skill Sonar如何使用
完整保护模式
use skill-sonar for full protection安装前检查 + 运行时监控全开,适合处理敏感任务或使用第三方技能时。
轻量模式
only use the pre-install check或
only use the runtime check只启用其中一种保护,适合资源敏感或有明确场景需求的场景。
基础使用
use skill-sonar to check xxx skills // 检查某个技能use skill-sonar to monitor this session // 监控当前会话
安装也非常简单,无论是通过 ClawHub 平台还是直接下载文件,都可以快速部署。

----- END -----

往期推荐

wisemodel相关:
系列模型和研究:
研究洞察 | “All for Agent”——数字世界新趋势新范式
LiveClin:239位医生打造“实时+临床全路径”的医疗评测基准
关注openclaw安全风险,AgentDoG提出智能体安全与防护的诊断式护栏框架
Seedance3.0技术曝光!Helios首个单卡实时生成长视频模型开源

关于wisemodel更多

1
欢迎持续关注和支持
开源社区建设需要长期坚持和投入,更需要广大用户的积极参与、贡献和维护,欢迎大家加入wisemodel开源社区的志愿者计划和开源共创计划。期待更多开发者将开源成果,包括模型、数据集和代码等发布到 wisemodel.cn 社区,共建中立、开放的AI开源社区生态。欢迎扫码添加wisemodel微信,申请加入wisemodel社群,持续关注wisemodel.cn开源社区动态。
2
欢迎加盟wisemodel开源社区
3
欢迎投稿优质内容
欢迎投稿分享人工智能领域相关的优秀研究成果,鼓励高校实验室、大企业研究团队、个人等,在wisemodel平台上分享各类优质内容,可以是AI领域最新论文解读、最新开源成果介绍,也可以是关于AI技术实践、应用和总结等。投稿可以发邮件到liudaoquan@wisemodel.cn,也可以扫码添加wisemodel微信。
4
关于wisemodel开源社区
始智AI wisemodel.cn开源社区由清华校友总会AI大数据专委会副秘书长刘道全创立,旨在打造和建设中立开放的AI开源创新社区,将打造成“HuggingFace”之外最活跃的AI开源社区,汇聚主要AI开源模型、数据集和代码等,欢迎高校科研院所、大型互联网公司、创新创业企业、广大个人开发者,以及政府部门、学会协会、联盟、基金会等,还有投资机构、科技媒体等,共同参与建设AI开源创新生态。
向上滑动查看
更多
